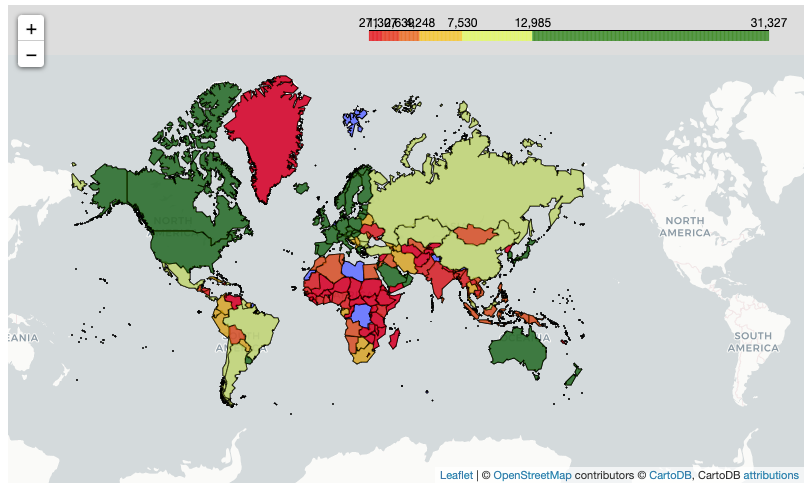
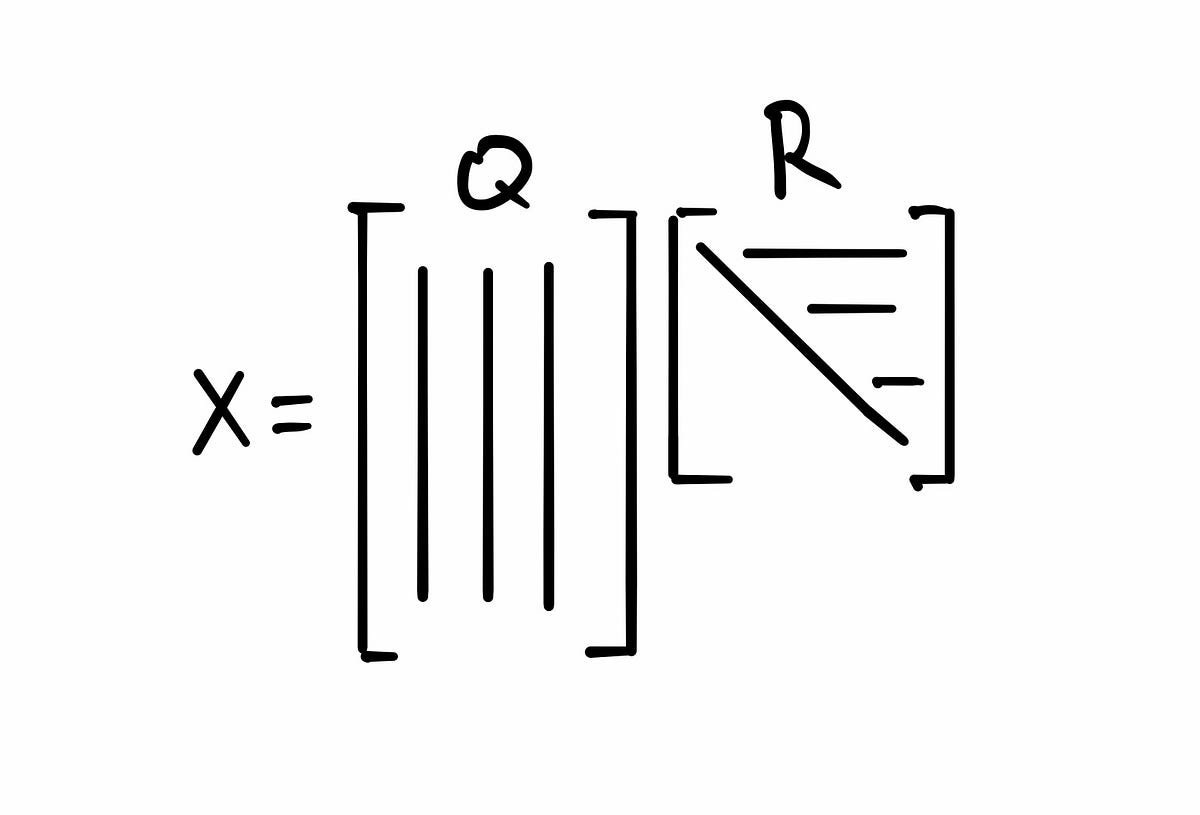In this article, we’ll explore 10 Python libraries that every machine learning professional should know in 2025.
In this article, we’ll explore 10 Python libraries that every machine learning professional should know in 2025.

All you need to know about Machine Learning in a hundred pages. Supervised and unsupervised learning, support vector machines, neural networks, ensemble methods, gradient descent, cluster analysis and dimensionality reduction, autoencoders and transfer learning, feature engineering and hyperparameter tuning! Math, intuition, illustrations, all in just a hundred pages!
Neural Networks learn to predict by backpropagation. This article aims to help you, build a solid intuition about the concept using a simple example. The ideas we learn here can be expanded for bigger nerual network. I assume that you already know how feed forward neural network works. Before reading the article further, take a pen and paper. The calculation used in this article can be done in the head. But I still want you to do by hand.
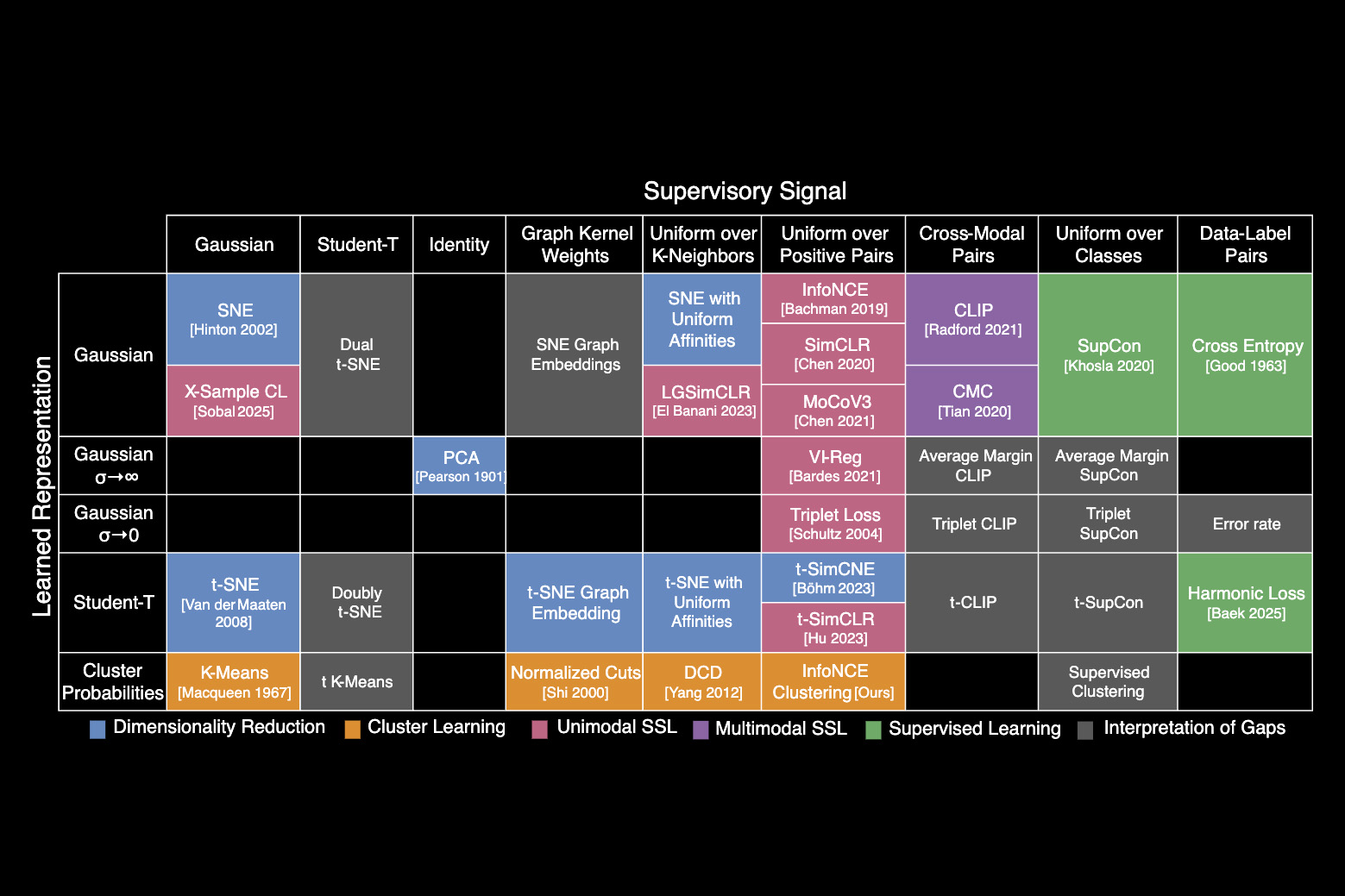
After uncovering a unifying algorithm that links more than 20 common machine-learning approaches, MIT researchers organized them into a “periodic table of machine learning” that can help scientists combine elements of different methods to improve algorithms or create new ones.
Ever heard of Tsetlin Machines ??

In this guide, you will learn how to deploy a machine learning model as an API using FastAPI. We will create an API that predicts the species of a penguin based on its bill length and flipper length. Prerequisites Step 1: Set Up Your Environment Step 2: Prepare Your Machine Learning Model Step 3: Create […]
Support Vector Machines (SVM) are supervised learning algorithms used for classification and regression by finding optimal decision boundaries between data classes.
Triplet loss is a machine learning function that minimizes distances between similar data points while maximizing distances between dissimilar ones.

In this article, I'll take you through a list of 50+ Data Analysis Projects you should try to learn Data Analysis.

In this article, I will introduce you to 10 little-known Python libraries every data scientist should know.

In this article, I'll take you through a list of 80+ hands-on Data Science projects you should try to learn everything in Data Science.

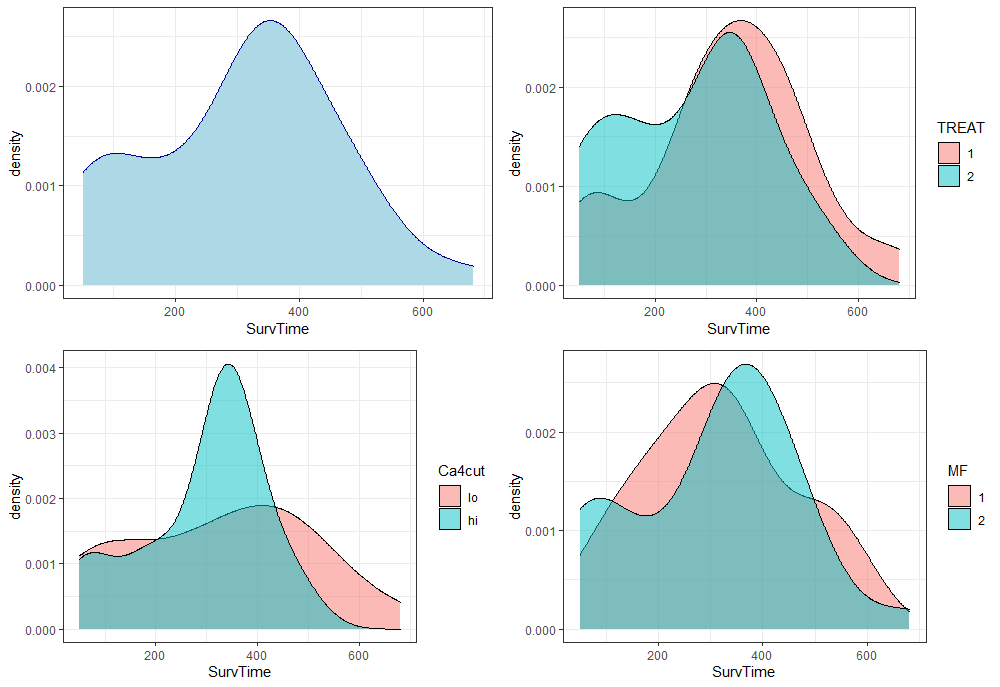
Survival analysis consists of statistical methods that help us understand and predict how long it takes for an event to occur.

How a Key-Value (KV) cache reduces Transformer inference time by trading memory for computation

In this article, I'll take you through a list of 50+ AI & ML projects solved & explained with Python that you should try.
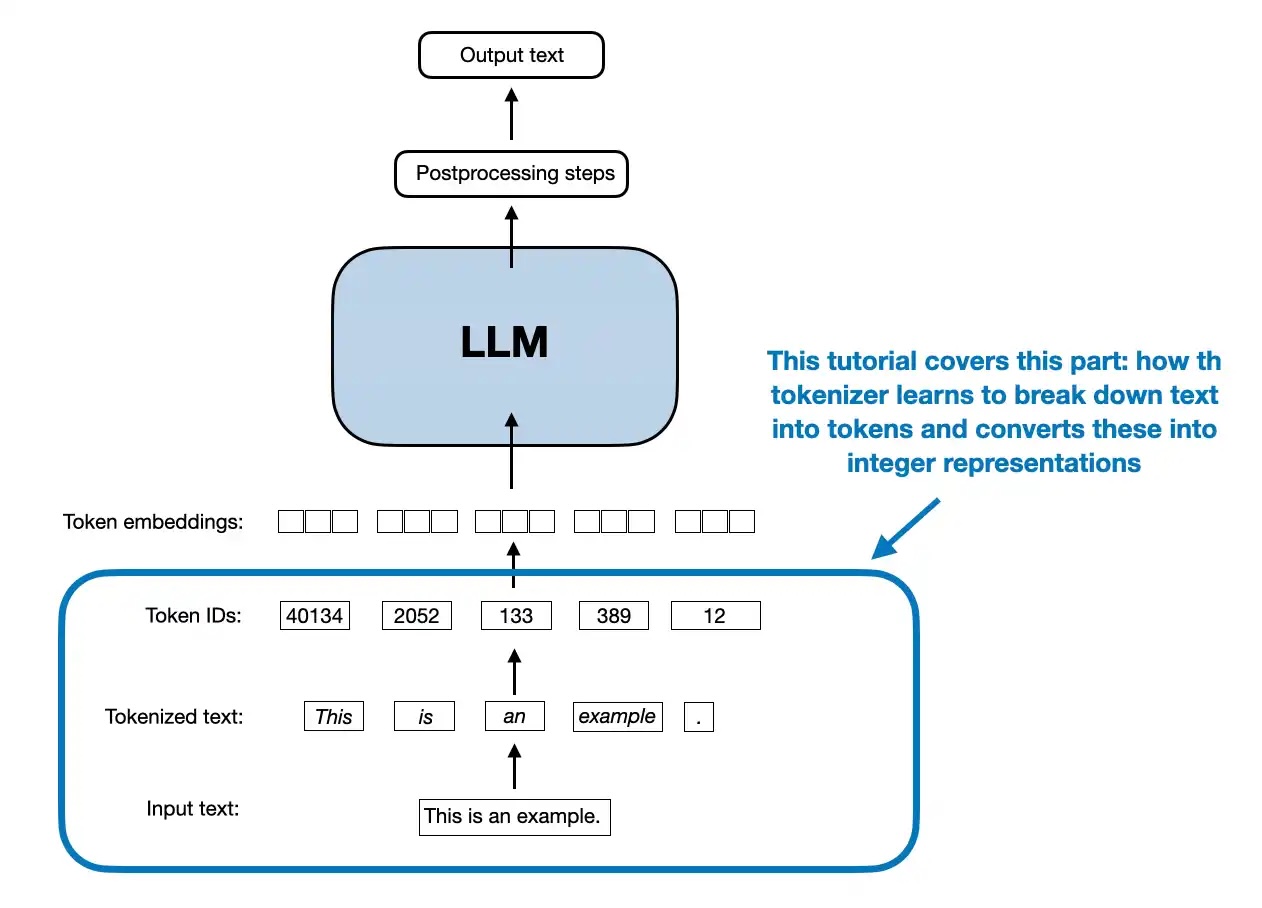
This is a standalone notebook implementing the popular byte pair encoding (BPE) tokenization algorithm, which is used in models like GPT-2 to GPT-4, Llama 3,...

Cosine similarity - the duct tape of AI. Convenient but often misused. Let's find out how to use it better.

Dramatically Speed-Up your Learning Algorithm, with Stochastic Thinning. Includes use case, Python code, regression and neural network illustrations.

Popular MLOps Python tools that will make machine learning model deployment a piece of cake.

Your ultimate Paper Club Starter Kit, from your friends at the Latent Space Paper Club, where we have now read 100 papers. Also: Announcing Latent Space Paper Club LIVE! at Neurips 2024! Join us!

In today’s world, you’ve probably heard the term “Machine Learning” more than once. It’s a big topic, and if you’re new to it, all the technical words might feel confusing. Let’s start with the basics and make it easy to understand. Machine Learning, a subset of Artificial Intelligence, has emerged as a transformative force, empowering machines to learn from data and make intelligent decisions without explicit programming. At its core, machine learning algorithms seek to identify patterns within data, enabling computers to learn and adapt to new information. Think about how a child learns to recognize a cat. At first,

A combination of classical search and machine learning may be the way forward
How Airbnb leverages machine learning and reinforcement learning techniques to solve a unique information retrieval task in order to…

Stochastic gradient descent is a learning algorithm that has a number of hyperparameters. Two hyperparameters that often confuse beginners are the batch size and number of epochs. They are both integer values and seem to do the same thing. In this post, you will discover the difference between batches and epochs in stochastic gradient descent. After reading this post, you…

Learn which variables you should and should not take into account in your model.

Where can you find projects dealing with advanced ML topics? GitHub is a perfect source with its many repositories. I’ve selected ten to talk about in this article.

A couple of days ago, in our lab session, we discussed random forrests, and, since it was based on the example in ISLR, we had a quick discussion about the random choice of features, and the “” rule Interestingly, on that one, we can play a bit, and try all choices, and do it again, on a different train/test split, library(randomForest) library(ISLR2) set.seed(123) sim = function(t){ train = sample(nrow(Boston), size = nrow(Boston)*.7) subsim = function(i){ rf.boston
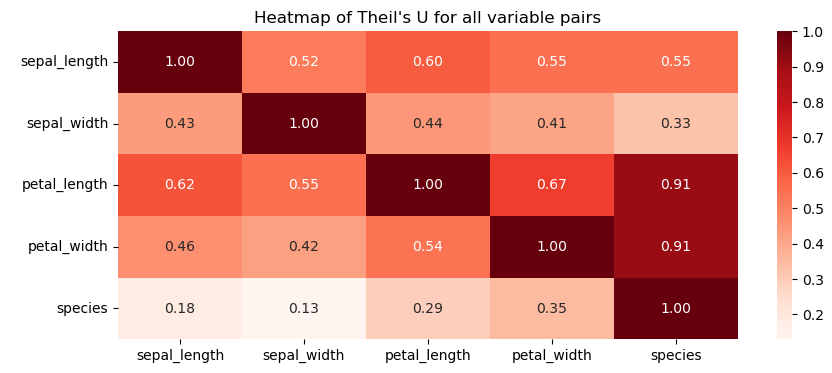
A measure of correlation between discrete (categorical) variables

A couple of days ago, in our lab session, we discussed random forrests, and, since it was based on the example in ISLR, we had a quick discussion about the random choice of features, and the “” rule Interestingly, on that one, we can play a bit, and try all choices, and do it again, … Continue reading The m=√p rule for random forests →

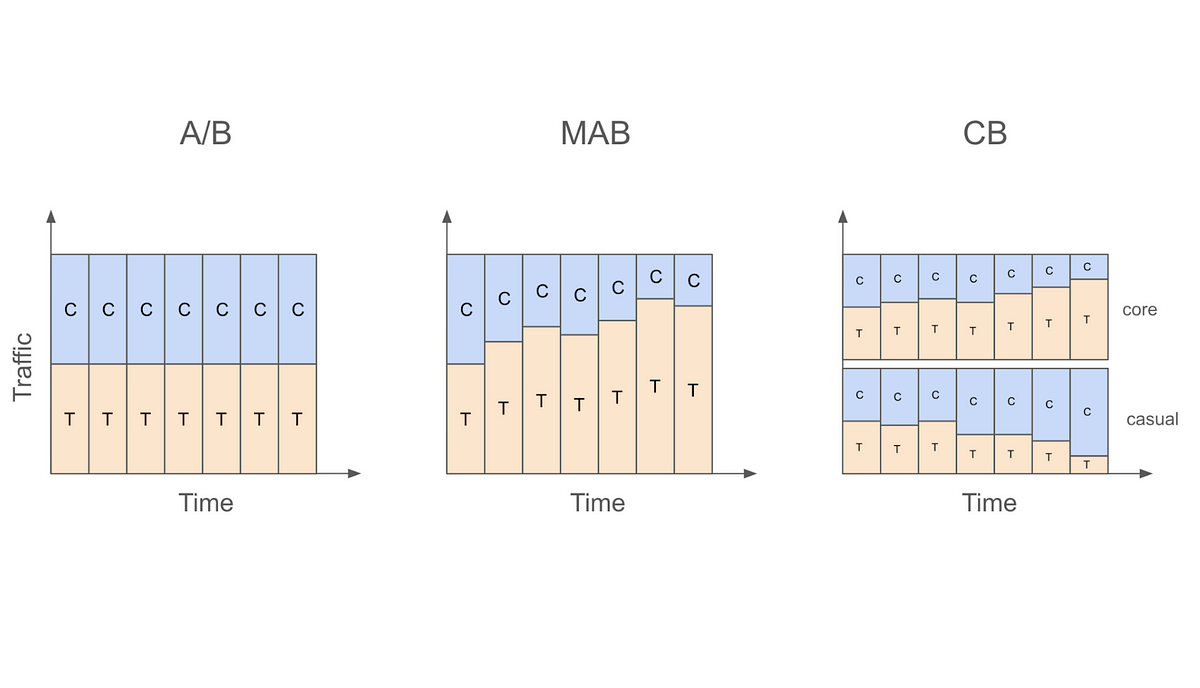
Experimentation is widely used at tech startups to make decisions on whether to roll out new product features, UI design changes, marketing campaigns and more, usually with the goal of improving…
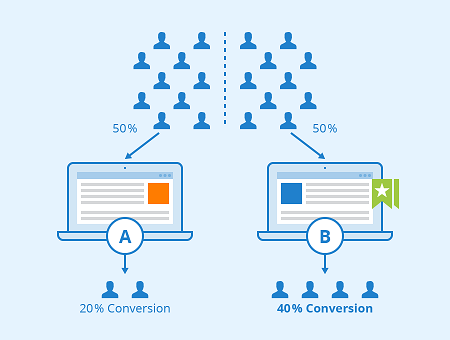
Making the most out of your experiments and observational data

In this article, I'll take you through a list of guided projects to master AI & ML with Python. AI & ML Projects with Python.

Discover the fundamentals of contrastive learning, including key techniques like SimCLR, MoCo, and CLIP. Learn how contrastive learning improves unsupervised learning and its practical applications.
An interpretable outlier detector based on multi-dimensional histograms.

Types of Functions > Basis functions (called derived features in machine learning) are building blocks for creating more complex functions. In other

Cosine similarity can measure the proximity between two documents by transforming words into vectors within a vector space.
Cool LLM and GenAI tech questions covering many modern concepts, including fast vector search, contextual tokens, and augmented structures
Understanding the importance of permutations in the field of explainable AI

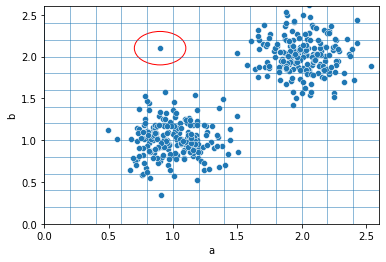
Imagine you're at a party separating people who love pizza (yum!) from those who...well, have...

Platforms like Kickstarter and Indiegogo have not only broadened access to funding to companies that might struggle in the capital markets but have also transformed the way companies connect with consumers during product development, replacing focus groups with real customers who have a stake in the final product. Despite crowdfunding’s many benefits, numerous campaigns still fail. To understand why, the authorse embarked on an empirical analysis of 18,173 campaigns for physical products in the technology and design categories on Kickstarter. They found that many companies often present initial products that are so fully developed that customers don’t feel that their input will materially change the product and are reluctant to contribute as a result.

#CatBoost - state-of-the-art open-source gradient boosting library with categorical features support,

A Schur decomposition of a matrix $latex A\in\mathbb{C}^{n\times n}$ is a factorization $LATEX A = QTQ^*$, where $LATEX Q$ is unitary and $LATEX T$ is upper triangular. The diagonal entries of $LAT…
Data comes in different shapes and forms. One of those shapes and forms is known as categorical data.

This article aims to take away the entry barriers to get started with time series analysis in a hands-on tutorial using Prophet

Why is Adam the most popular optimizer in Deep Learning? Let’s understand it by diving into its math, and recreating the algorithm.
How should we choose between label, one-hot, and target encoding?
LDA explained with a dog pedigree model

Which measure of correlation should you use for your task? Learn all you need to know about Pearson and Spearman correlations.

Insanely fast and reliable smoothing and interpolation with the Whittaker-Eilers method.
This year has felt distinctly different. I've been working in, on, and with machine learning and AI for over a decade, yet I can't recall a time when these fields were as popular and rapidly evolving as they have been this year. To conclude an eventful 2023 in machine learning and AI research, I'm excited to share 10 noteworthy papers I've read this year. My personal focus has been more on large language models, so you'll find a heavier emphasis on large language model (LLM) papers than computer vision papers this year.
Understanding the logic behind AdaBoost and implementing it using Python

This tutorial offers a bridge between the abstract mathematics of manifolds and computational practice.

In this article, I'll take you through the task of Market Basket Analysis using Python. Market Basket Analysis using Python.
Independent component analysis (ICA) is a powerful data-driven tool capable of separating linear contributions in the data

It is possible to design and deploy advanced machine learning algorithms that are essentially math-free and stats-free. People working on that are typically professional mathematicians. These algorithms are not necessarily simpler. See for instance a math-free regression technique with prediction intervals, here. Or supervised classification and alternative to t-SNE, here. Interestingly, this latter math-free machine
An alternative of logistic regression in special conditions

Or "that time I built Excel for Uber and they ditched it like a week after launch"

BookCorpus has helped train at least thirty influential language models (including Google’s BERT, OpenAI’s GPT, and Amazon’s Bort), according to HuggingFace. This is the research question that…

Learn how to compute the Pearson, Spearman and Kendall correlation coefficients by hand to evaluate the relationship between two variables

In the era of hyper-sophisticated machine learning models like ChatGPT, it is surprising how effective the classic decision tree model remains, especially when used in conjunction with other techniques, such as bagging, boosting and random forests. In this blog post we demonstrate how to build an effective decision tree model, and train this model on some sample data.
Applying Reinforcement Learning strategies to real-world use cases, especially in dynamic pricing, can reveal many surprises

Standardization, Normalization, Robust Scaling, Mean Normalization, Maximum Absolute Scaling and Vector Unit Length Scaling
Understanding the purpose and functionality of common metrics in ML packages
Learn how Self-Organizing Maps work and why they are a useful unsupervised learning algorithm

Discover the concepts of Zero-Shot, One-Shot, and Few-Shot Learning, which enable machine learning models to classify and recognize objects or patterns with a limited number of examples.
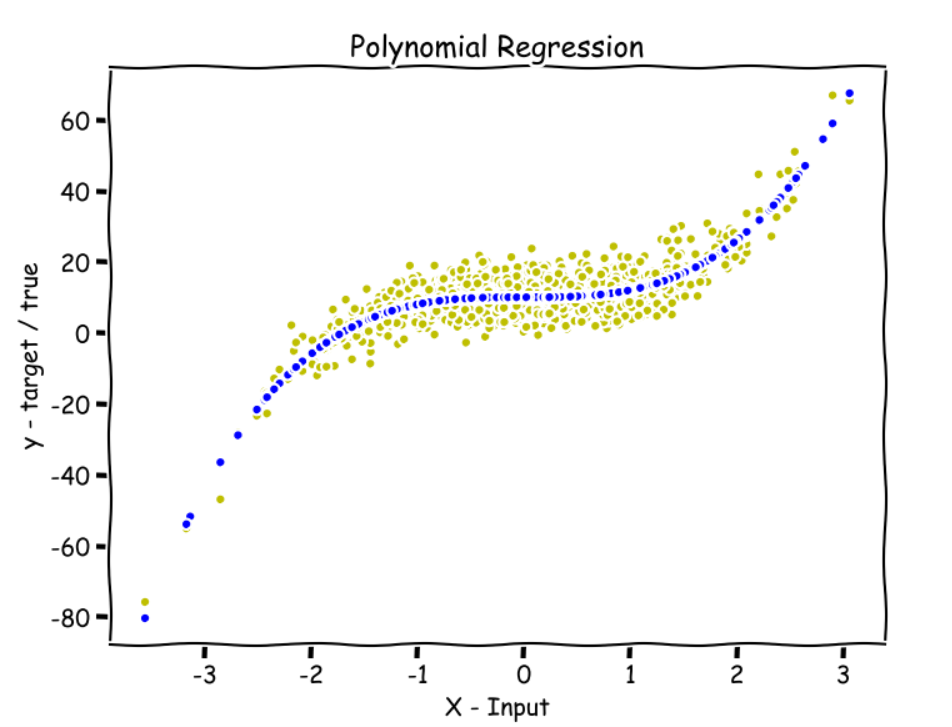
Learn to build a Polynomial Regression model to predict the values for a non-linear dataset.
How to explore geographic data with HDBSCAN, H3, graph theory, and OSM.

How a Scientist Playing Solitaire Forever Changed the Game of Statistics

This tutorial explores the LightGBM library in Python to build a classification model using the LGBMClassifier class.

Hierarchical Navigable Small World (HNSW) is a state-of-the-art algorithm used for an approximate search of nearest neighbours. Under the…
In the first two parts of this series we have discussed two fundamental algorithms in information retrieval: inverted file index and…
Hierarchical Navigable Small World graphs (HNSW) is an algorithm that allows for efficient nearest neighbor search, and the Sentence…
Similarity search is a popular problem where given a query Q we need to find the most similar documents to it among all the documents D.
Learn a powerful technique to effectively compress large data
Explore how similarity information can be incorporated into hash function
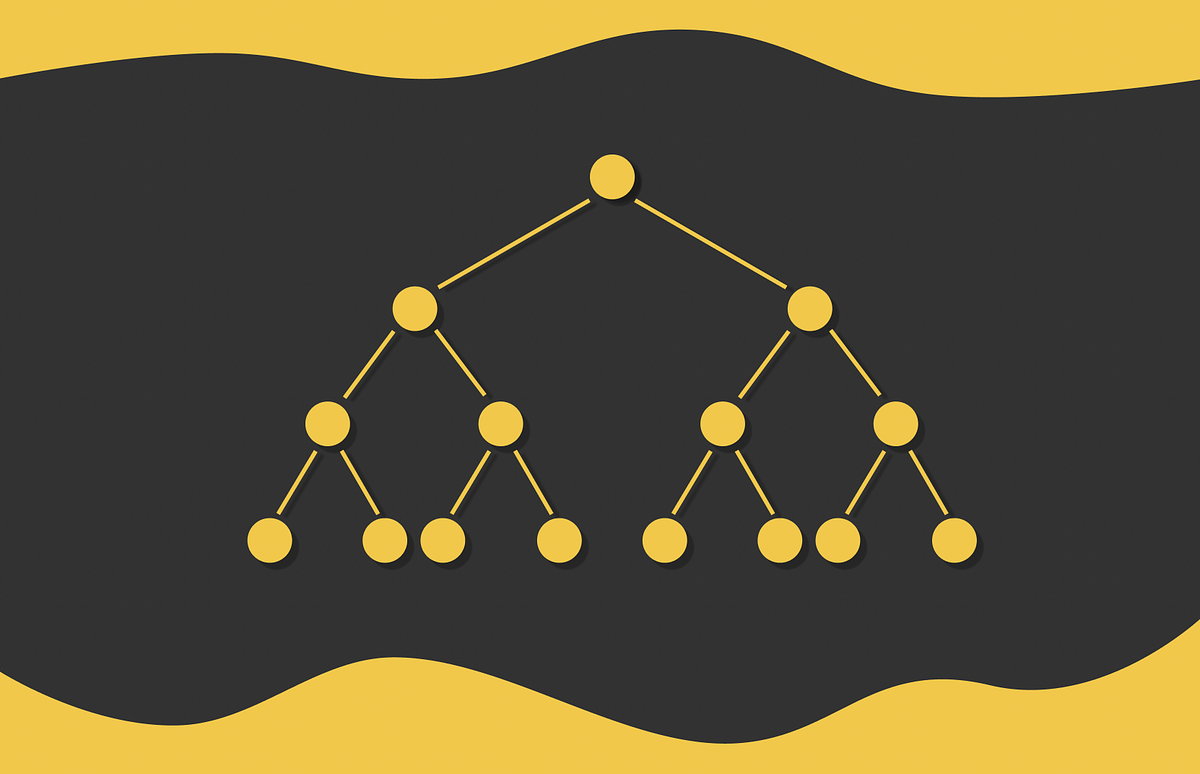
Understand how to hash data and reflect its similarity by constructing random hyperplanes
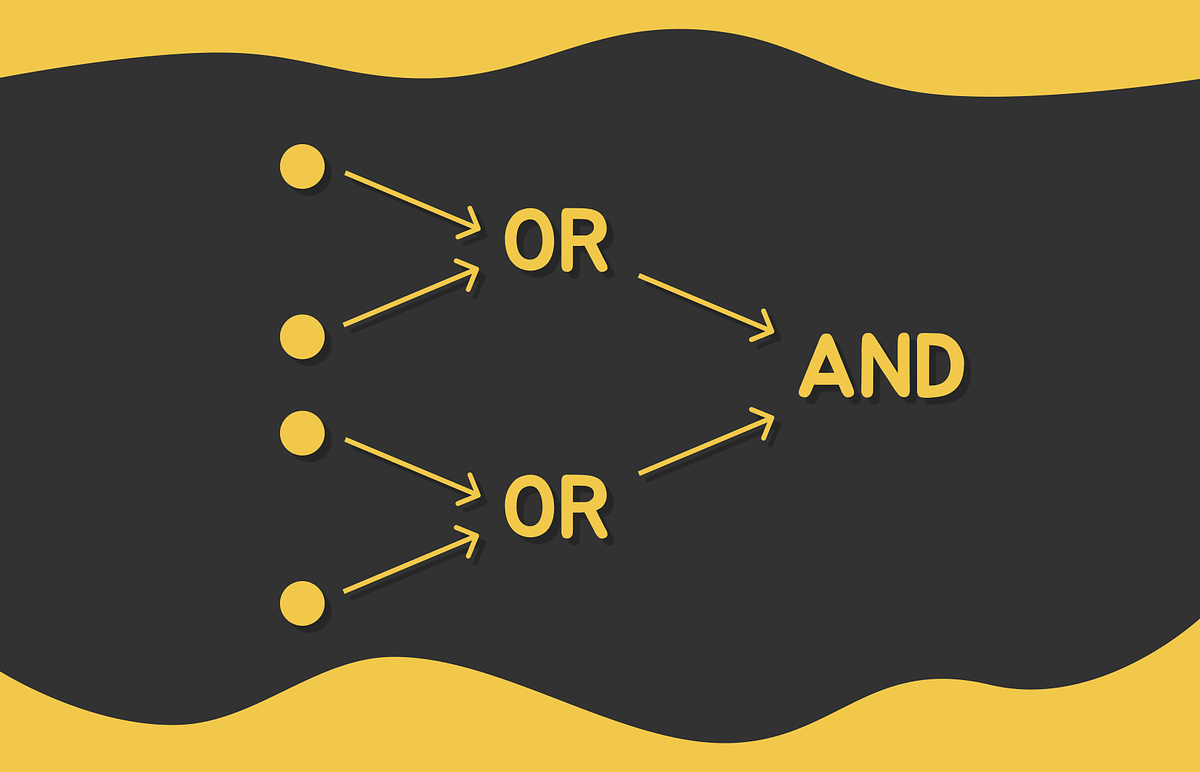
Dive into combinations of LSH functions to guarantee a more reliable search
Understand survival analysis, its use in the industry, and how to apply it in Python
How do hazards and maximum likelihood estimates predict event rankings?

An in-depth exploration of autoencoders and dimensionality reduction
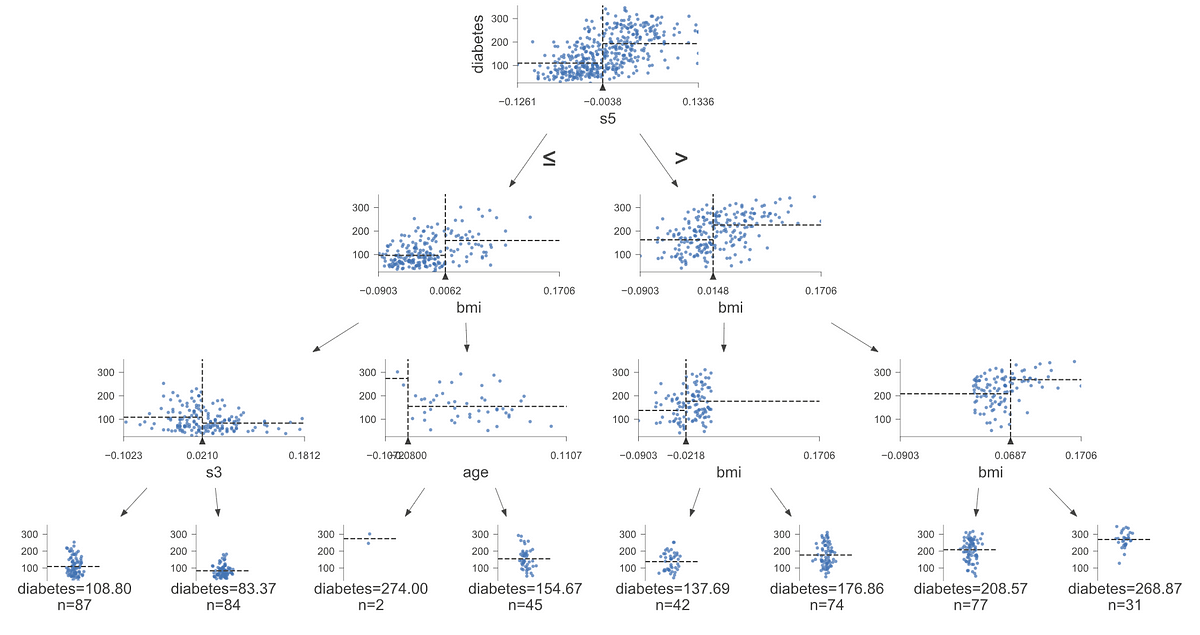
How to visualize decision tree models with this useful library
Let’s explore how hierarchical clustering works and how it builds clusters based on pairwise distances.

A guide to understanding support vector machines for classification: from theory to scikit-learn implementation.

Reducing the dimension of a dataset using methods such as PCA

Applying causal machine learning to trim the campaign target audience

Learn what vector search is and the metrics pertinent to decide the distance (or similarity) between objects.
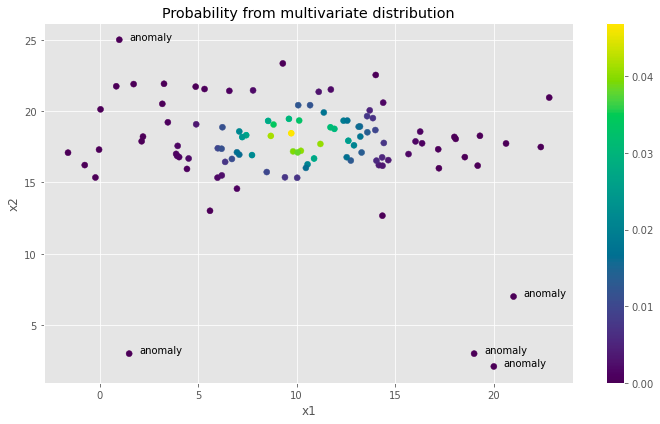
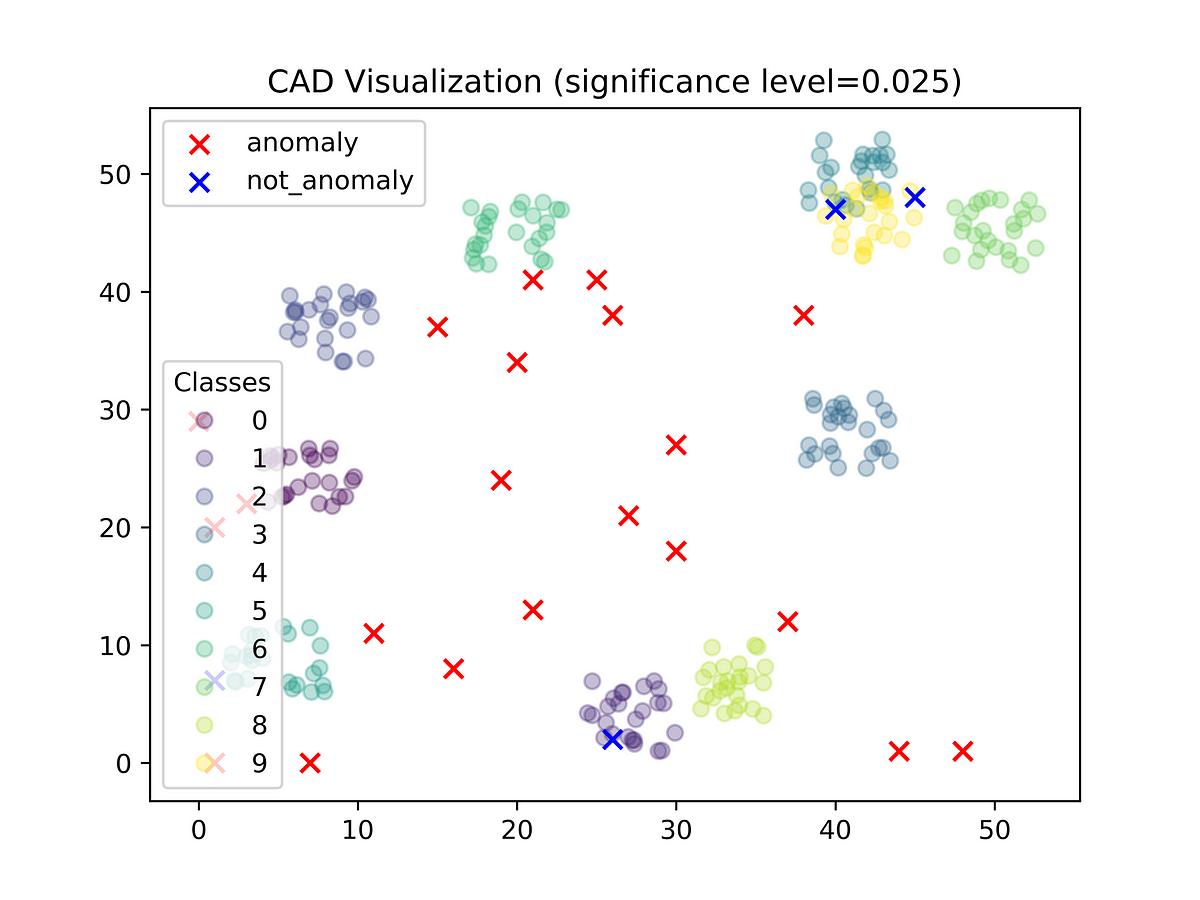
Basics of anomaly detection, its use-cases, and an implementation of simple yet powerful algorithm in Python
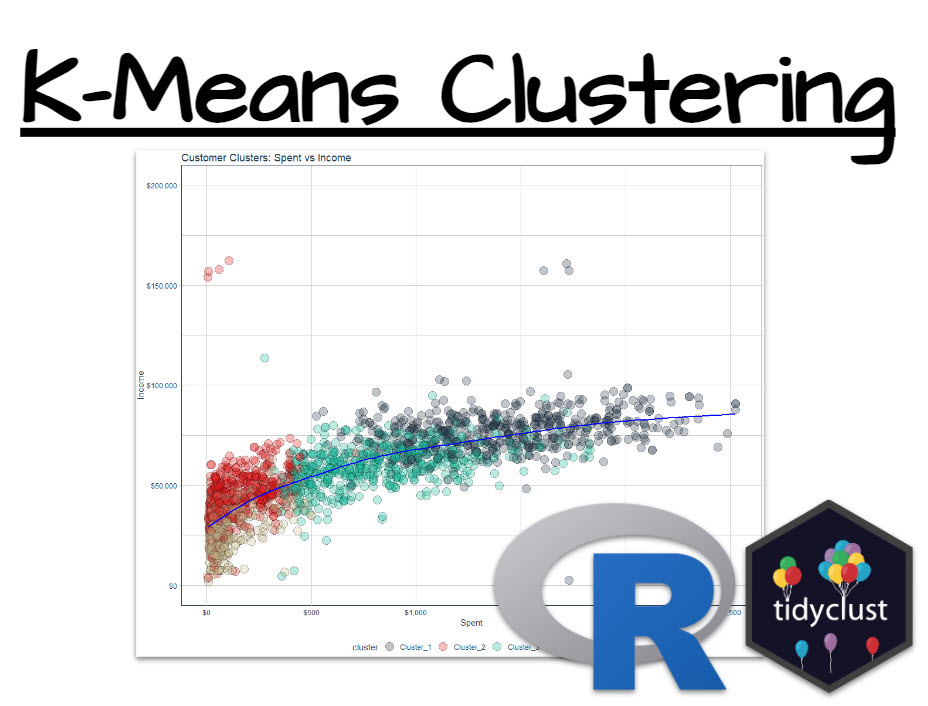
To be successful as a Data Scientist, you’re often put in positions where you need to find groups within your data. One key business use-case is finding clusters of customers that behave similarly. And that’s a powerful skill that I’m going to help you...

Spectral clustering is a method of clustering data points based on their similarity or affinity,...

Master Sklearn pipelines for effortless and efficient machine learning. Discover the art of building, optimizing, and scaling models with ease. Level up your data preprocessing skills and supercharge your ML workflow today

Make stronger and simpler models by leveraging natural order

The Similarity Engine's use cases include item-to-item similarity for text and image modality and user-to-item personalized recommendations based on a user’s historical behavior data.

The most important LightGBM parameters, what they do, and how to tune them
Create insights from frequent patterns using market basket analysis with Python

Recursive queries are a straightforward solution to querying hierarchical trees. However, one loop in the relationship references results in a failing or never ending query when cycle detection is not used.
Dive into an end-to-end demo of a high-performance semantic search engine leveraging GPU acceleration, efficient indexing techniques, and…

These curated papers would step up your machine-learning knowledge.
Exploring the Latest Enhancements and Features of PyCaret 3.0

Understanding the most underrated trick in applied Machine Learning
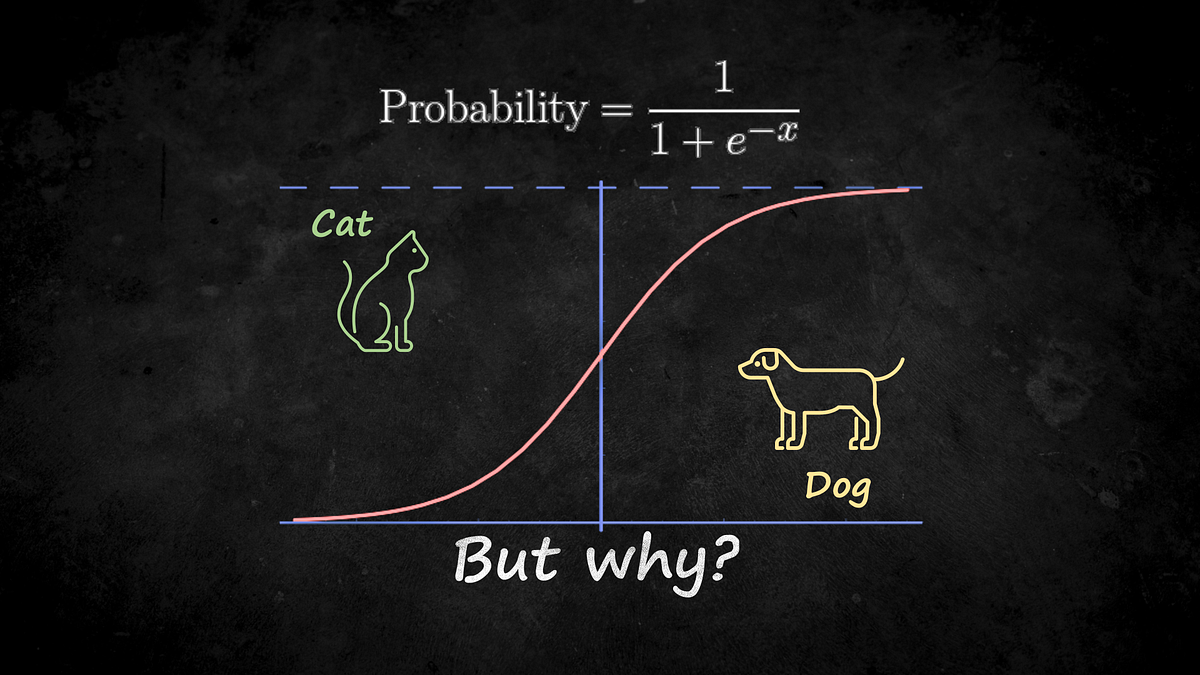
Why do we use the logistic and softmax functions? Thermal physics may have an answer.
Unsupervised learning has always been fascinating to me. It is a way to learn about data without manual labeling effort and allows for the…
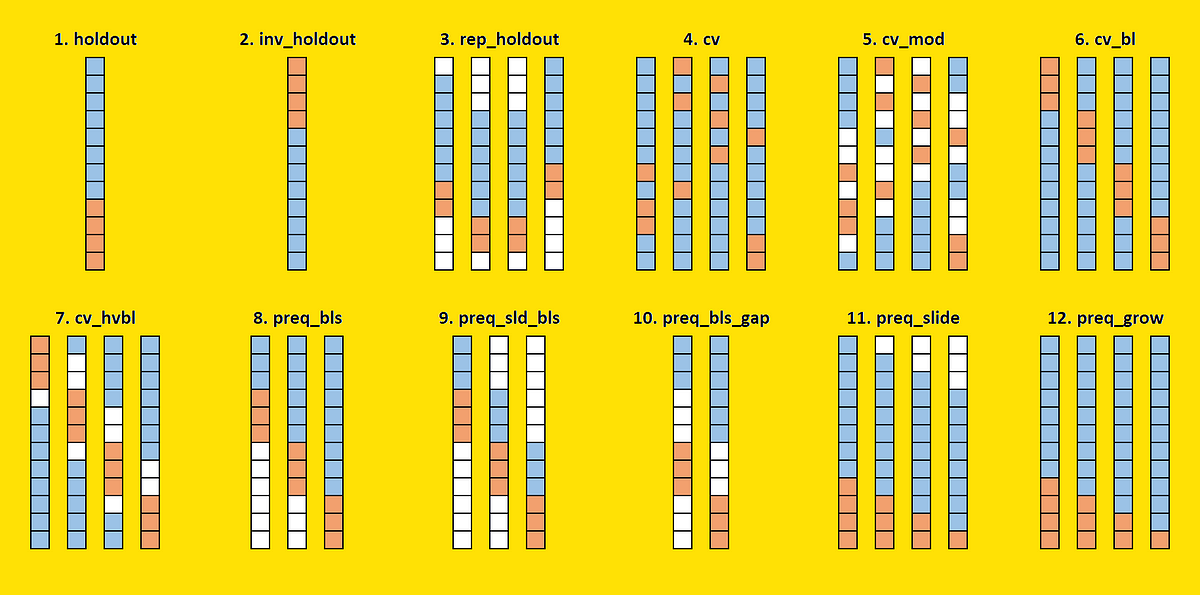
How to find the best performance estimation approach for time-series forecasts among 12 strategies proposed in the literature. With Python…

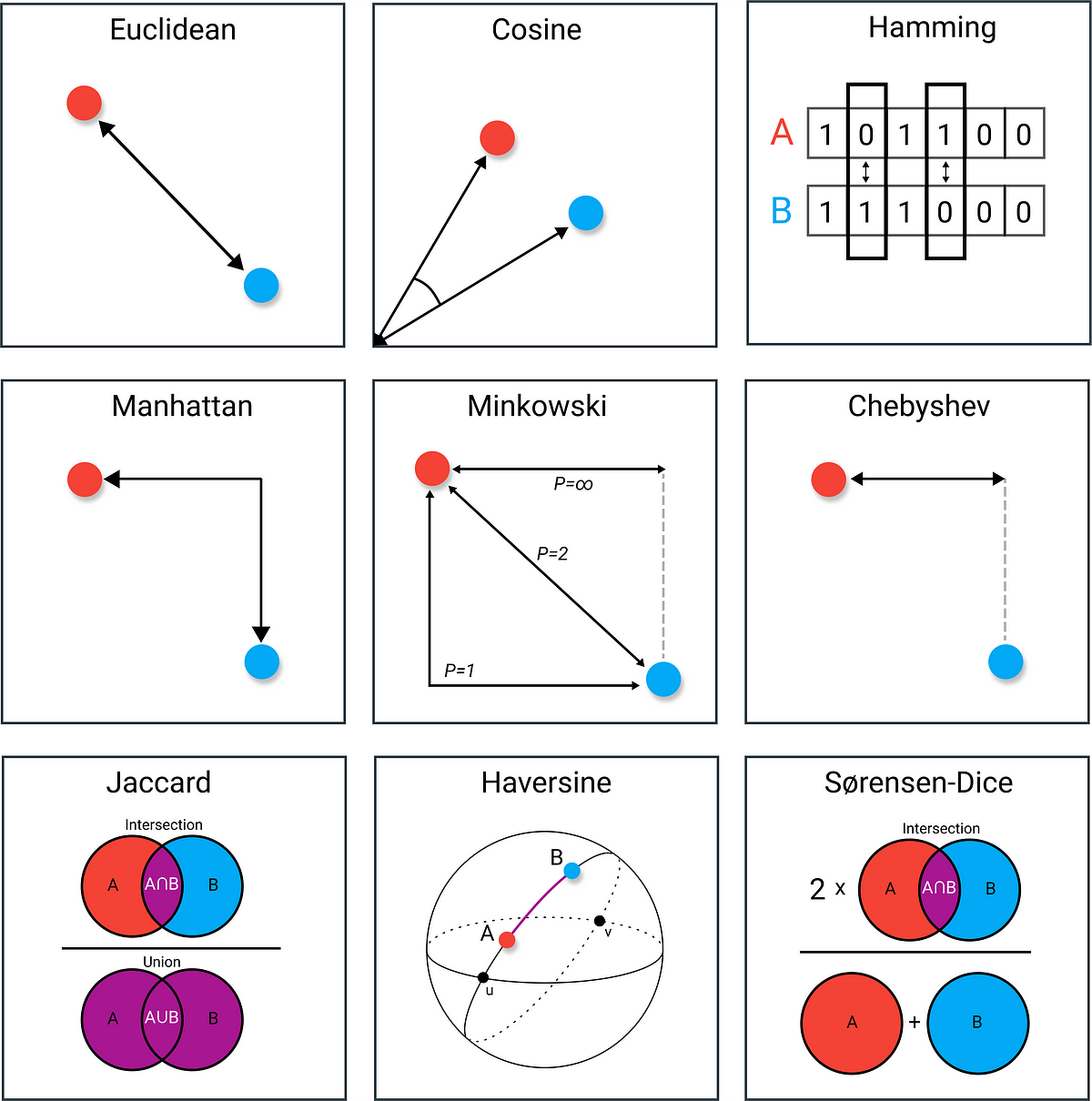
The Jaccard index, also known as the Jaccard similarity coefficient, is a statistic used for gauging the similarity and diversity of sample sets. It is defined in general taking the ratio of two sizes, the intersection size divided by the union size, also called intersection over union (IoU).
A quick guide on how to make clean-looking, interactive Python plots to validate your data and model
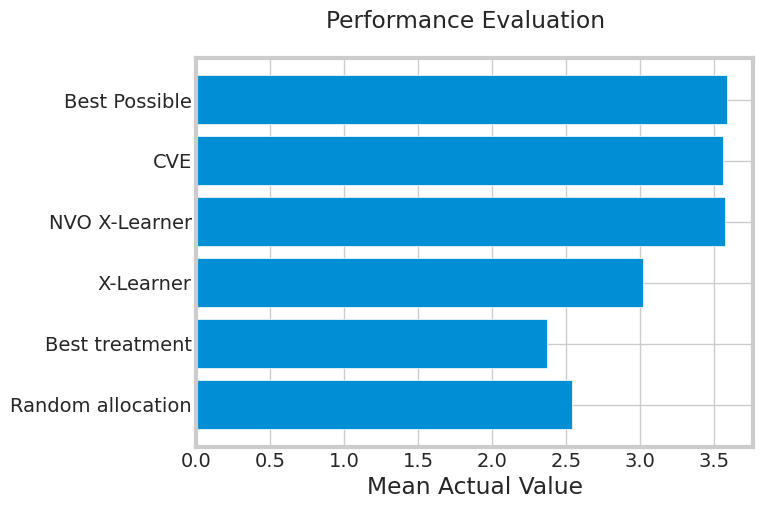
How to adjust CATE to consider costs associated with your treatments
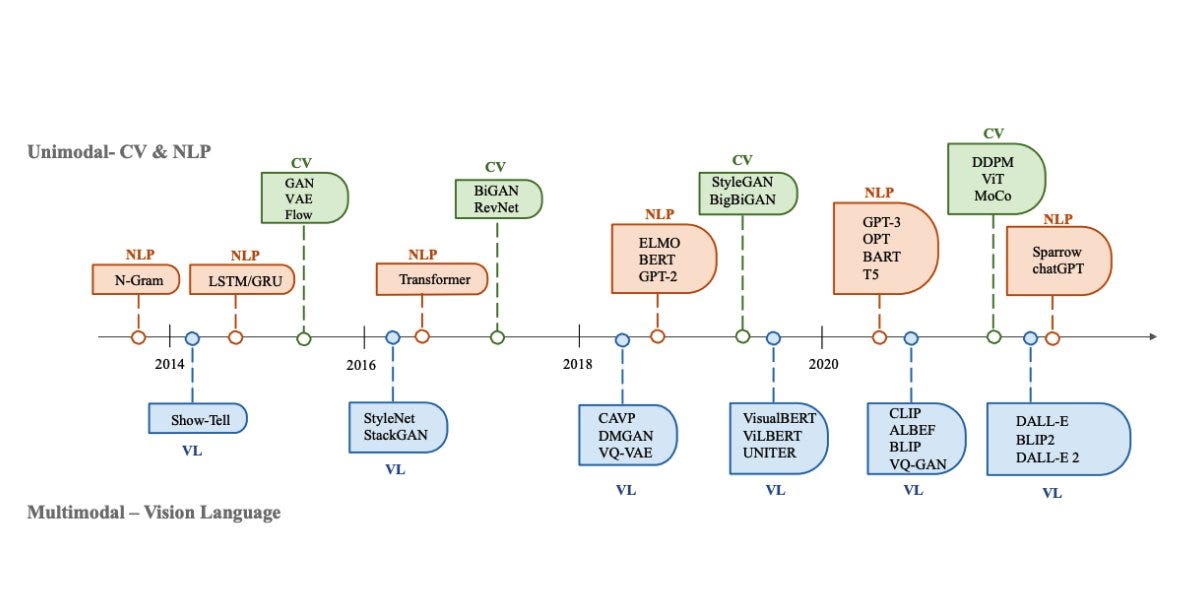
The top ML Papers of the Week (Mar 6 - Mar 12)

Patterns, backed by Y Combinator, is building a platform that allows customers to piece together components to build an AI-powered app.
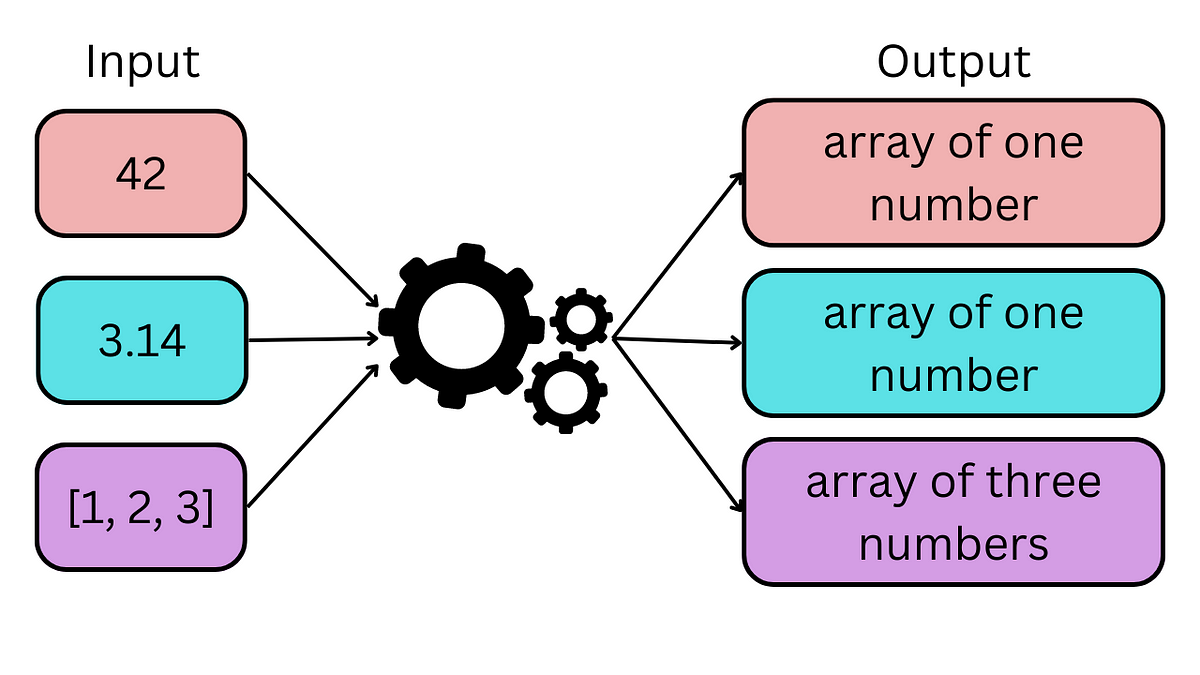
Use natural language to test the behavior of your ML models

A primer on the math, logic, and pragmatic application of JS Divergence — including how it is best used in drift monitoring
Covers how to choose the similarity measure when item embeddings are available

A gentle dive into this unusual feature selection technique

A more advanced clustering technique for real world data

Discover how to effectively detect multivariate outliers in machine learning with PyOD in Python. Learn to convert anomaly scores to probability confidence, choose the best outlier classifier and determine the right probability threshold for improved model accuracy.
Part 4: A comprehensive step-by-step guide to solving a linear system with LU Decomposition
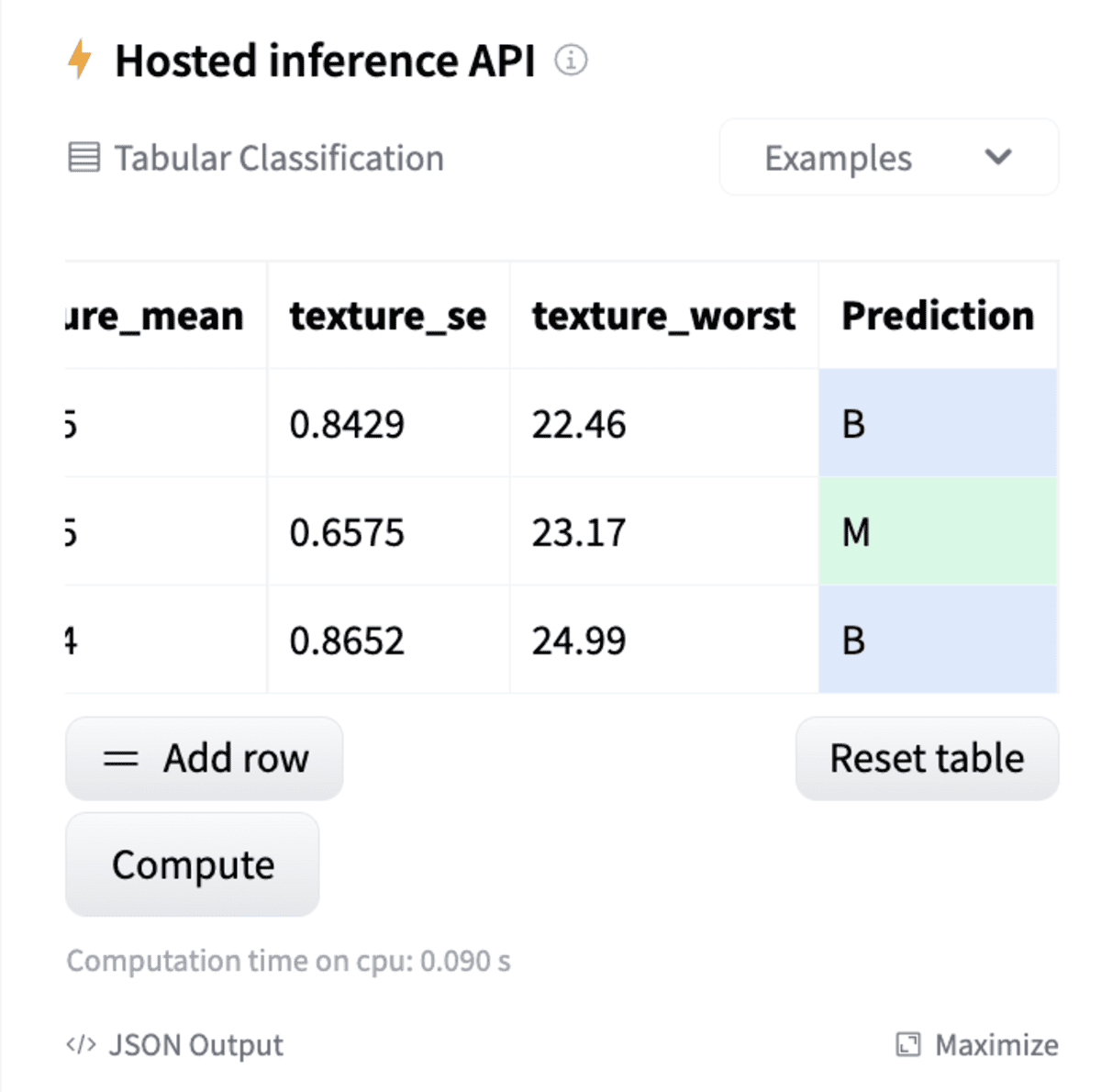
There are various challenges in MLOps and model sharing, including, security and reproducibility. To tackle these for scikit-learn models, we've developed a new open-source library: skops. In this article, I will walk you through how it works and how to use it with an end-to-end example.
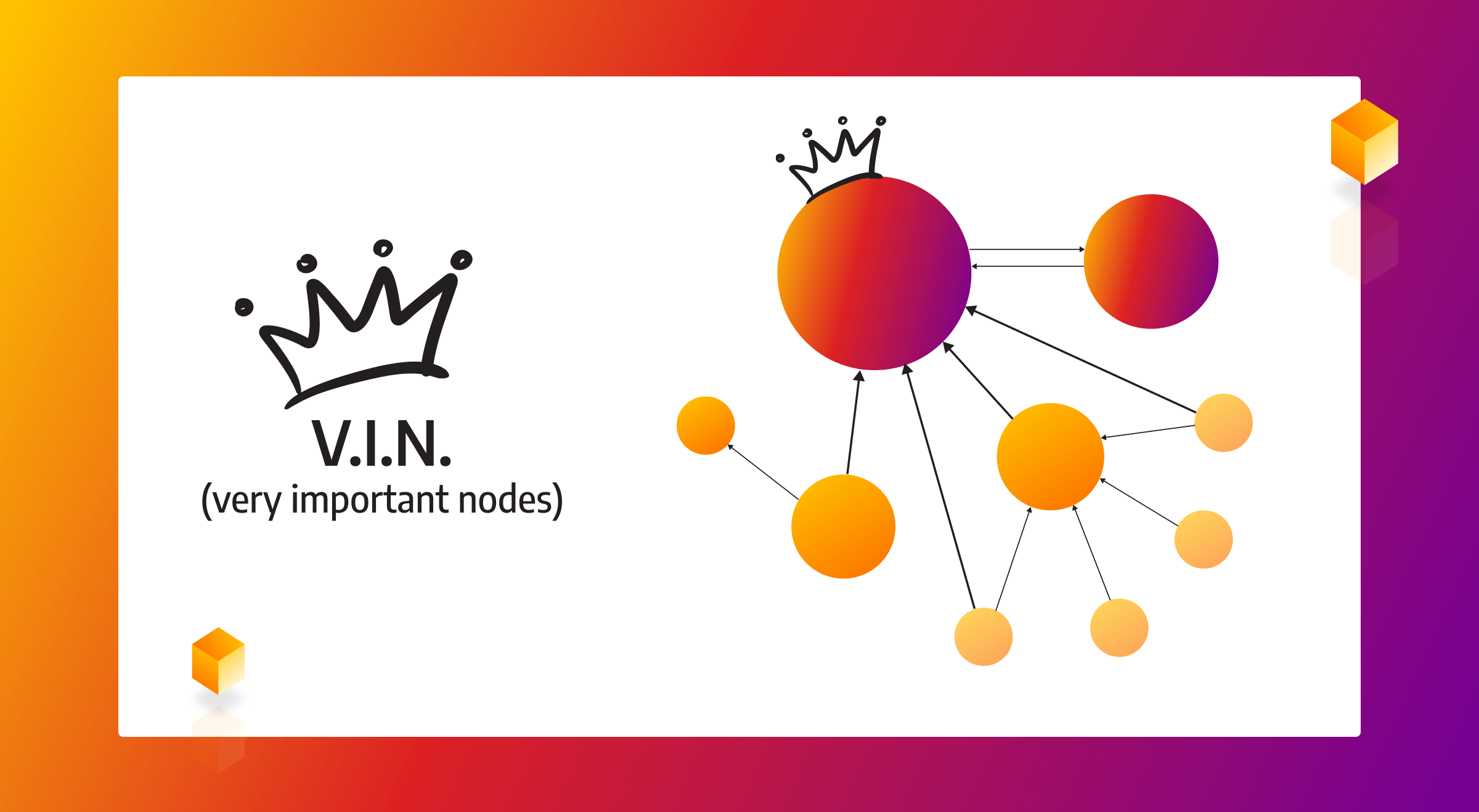
What is PageRank algorithm? How can it be used in various graph database use cases? How to use it in Memgraph? If these questions are keeping you up at night, here is a blog post that will finally put your mind at ease.
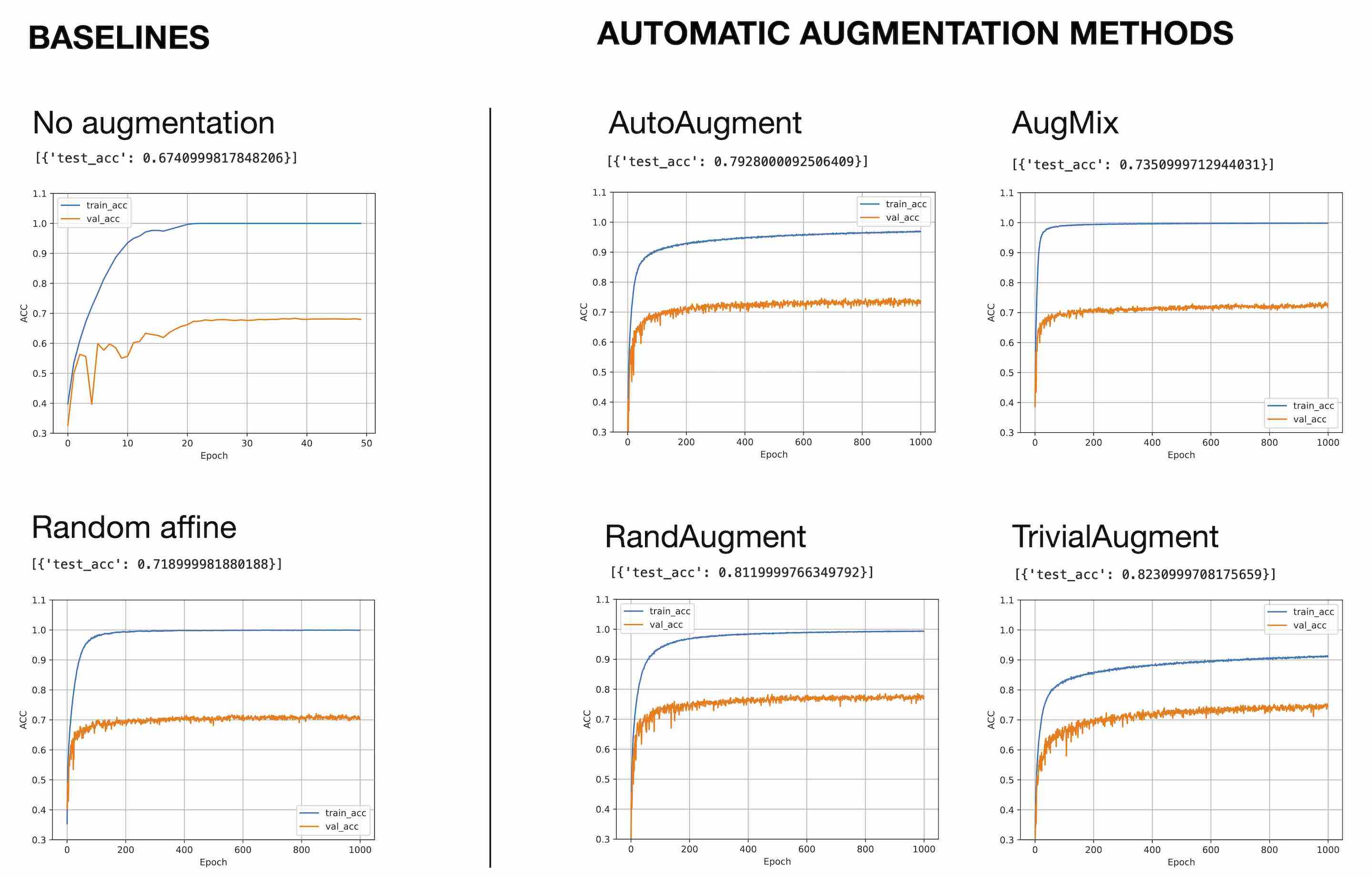
Data augmentation is a key tool in reducing overfitting, whether it's for images or text. This article compares three Auto Image Data Augmentation techniques...
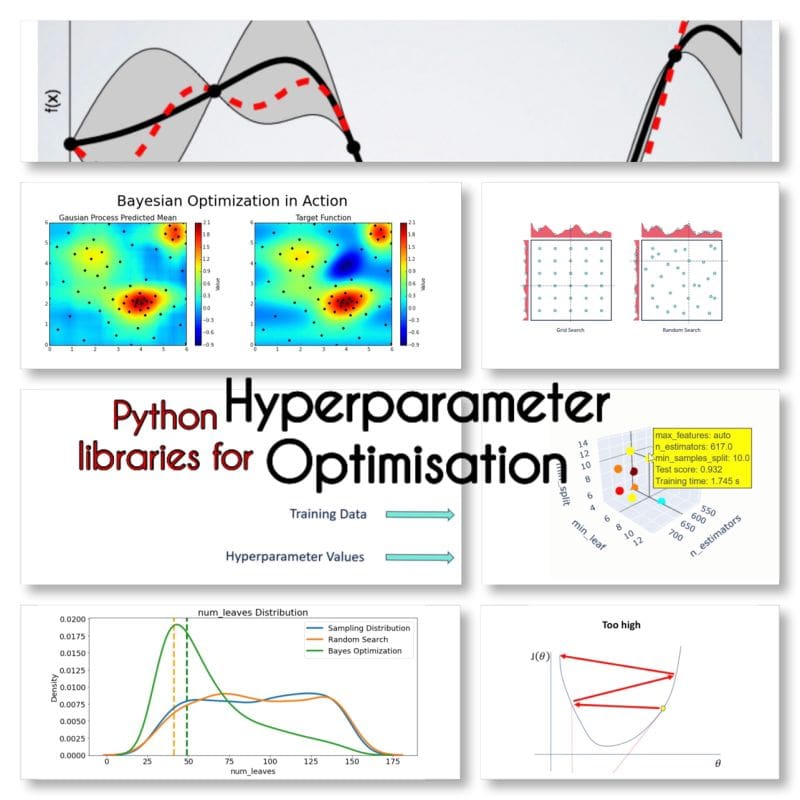
Become familiar with some of the most popular Python libraries available for hyperparameter optimization.
Circular data can present unique challenges when it comes to analysis and modeling

Entropy can be thought of as the probability of seeing certain patterns in data. Here’s how it works.

Learn the basic steps to run a Multiple Correspondence Analysis in R
Tips for taking full advantage of this machine learning package
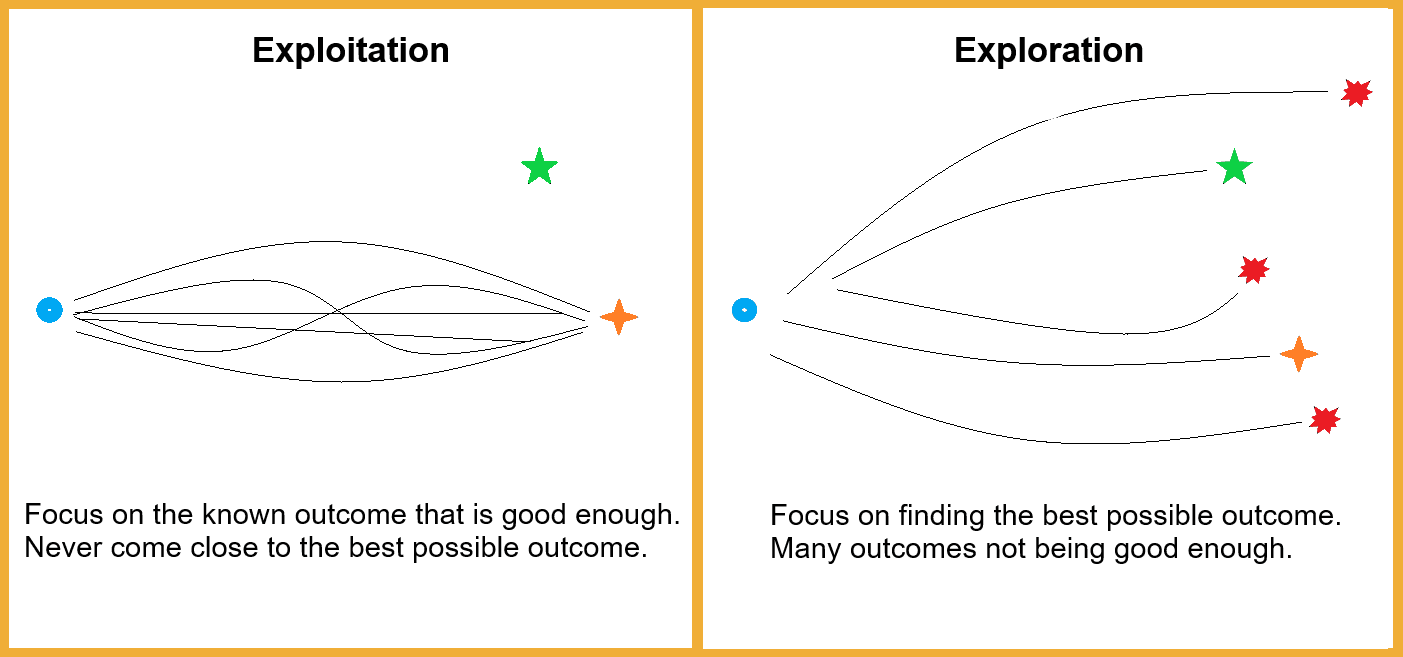
Delve deeper into the concept of multi-armed bandits, reinforcement learning, and exploration vs. exploitation dilemma.

A cross-framework package for kernels and Gaussian processes on manifolds, graphs, and meshes

Open-source vector database built for GenAI applications. Install with pip, perform high-speed searches, and scale to tens of billions of vectors.
Python Feature Engineering Cookbook Second Edition, published by Packt - PacktPublishing/Python-Feature-Engineering-Cookbook-Second-Edition
Learn more about survival analysis (also called time-to-event analysis) and how it is used, and how to apply it by hand and in R

How you can train a model to learn and predict unseen data?

The wave of enthusiasm around generative networks feels like another Imagenet moment - a step change in what ‘AI’ can do that could generalise far beyond the cool demos. What can it create, and where are the humans in the loop?
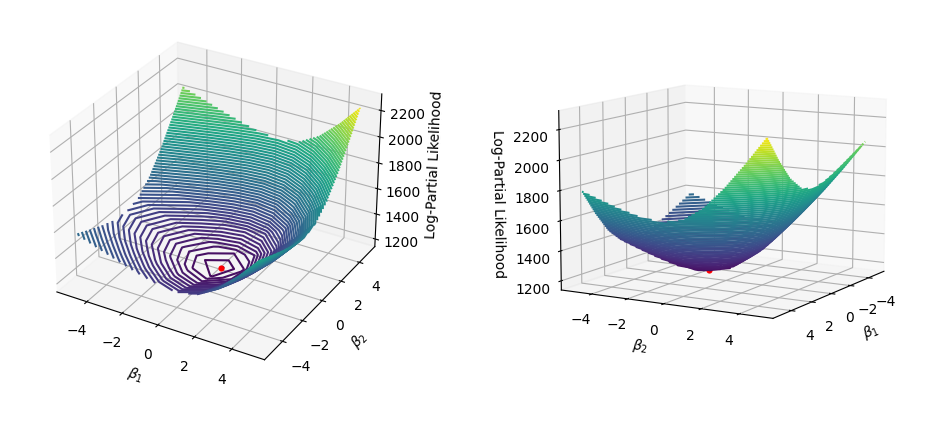
Finding the coefficients that maximize the log-partial likelihood in Python

Today Google announced a beta release of Simple ML for Sheets, which allows users without ML experience to try ML out on their spreadsheets.
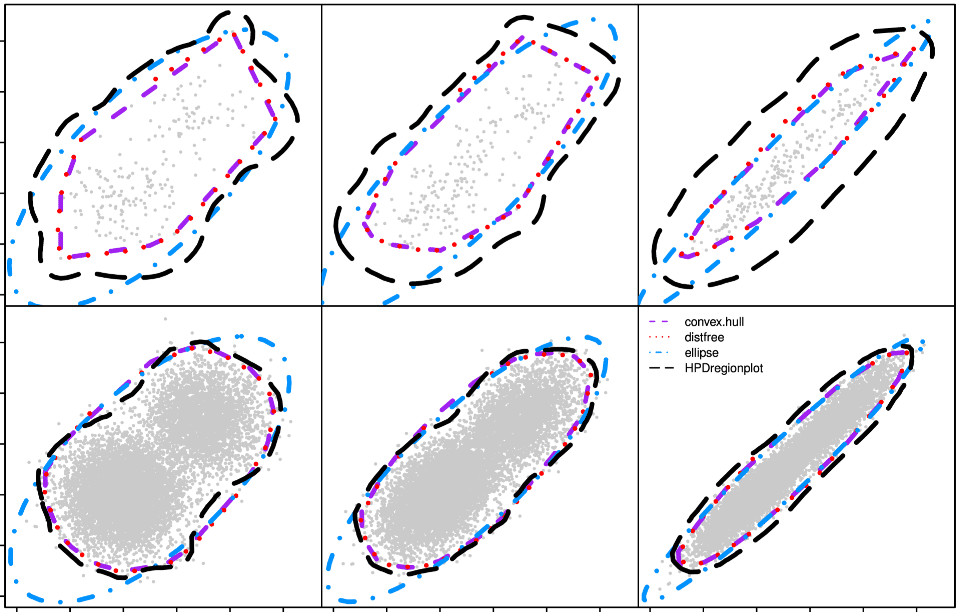
Simulated confidence regions for machine learning professionals and non-statisticians. Introducing a new concept: dual confidence region.

Top entries are in bold, and sub-entries are in italics. This dictionary is from my new book "Intuitive Machine Learning and Explainable AI", available here and used as reference material for the course with the same name (see here). These entries are cross-referenced in the book to facilitate navigation, with backlinks to the pages where
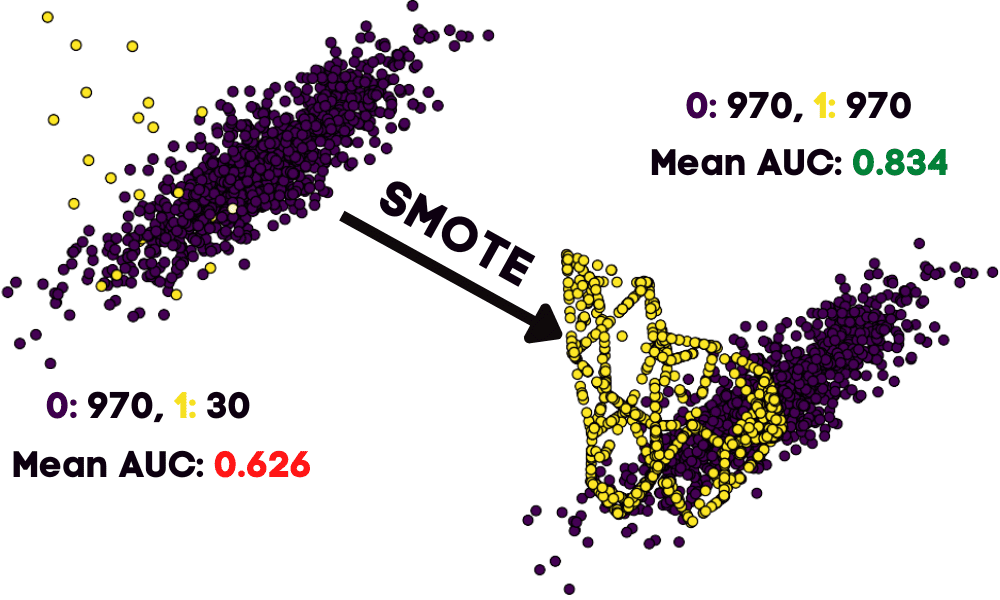
Improve the model performance by balancing the dataset using the synthetic minority oversampling technique.
How to Choose the Best Machine Learning Technique: Comparison Table

An eigenvalue of a square matrix $LATEX A$ is a scalar $latex \lambda$ such that $latex Ax = \lambda x$ for some nonzero vector $latex x$. The vector $latex x$ is an eigenvector of $LATEX A$ and it…
Mathematical Modeling, Solution, and Visualization Using PuLP and VeRoViz
How you can (and why you should) create custom transformers

Utilize Anomalib from Intel OpenVinoToolkit to benchmark, develop, and deploy deep learning based image anomaly detection

This self-published book is dated July 2020 according to Amazon. But it appears to be an ongoing project. Like many new books, the material is on GitHub, here. The most recent version, dated June 2021, is available in PDF format, here. This is not a traditional book. It feels like a repository of Python code,
Ensuring your business is proactive and risk-proof.
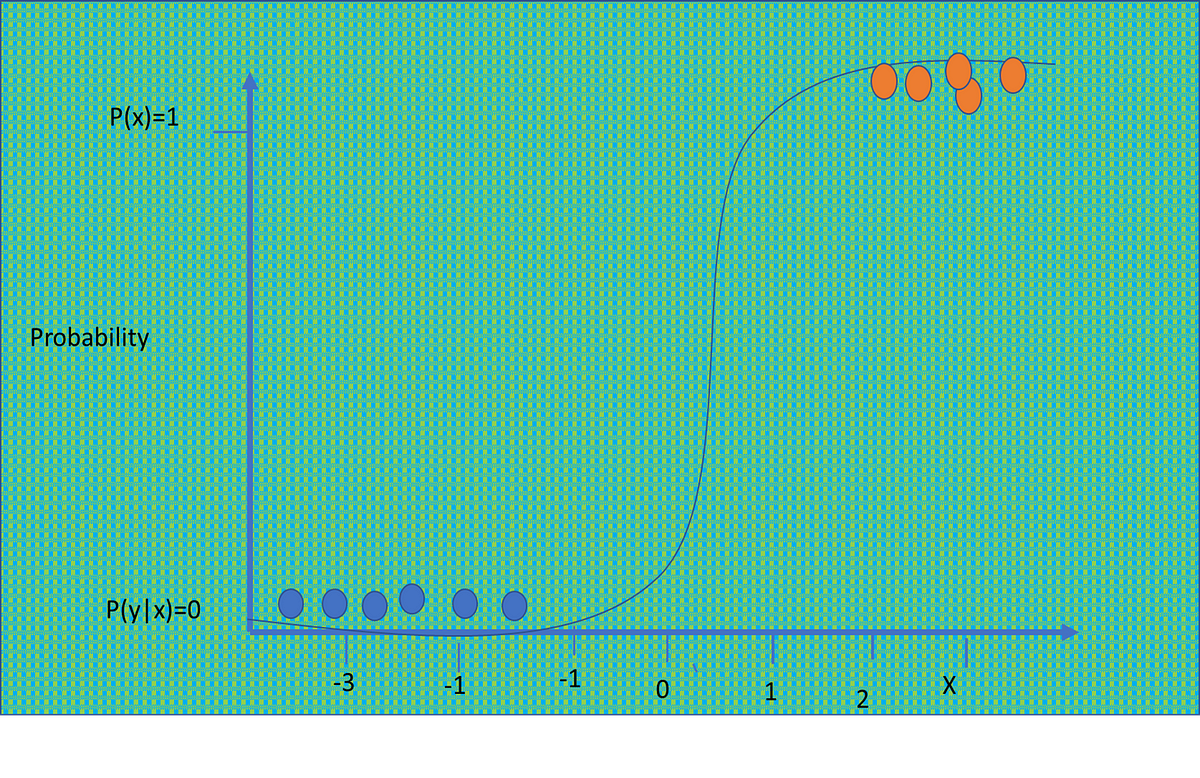
Logistic regression is one of the most frequently used machine learning techniques for classification. However, though seemingly simple…

An introduction to the field, its applications, and current issues

A review of popular techniques and remaining challenges

Statistics in R Series: Deviance, Log-likelihood Ratio, Pseudo R² and AIC/BIC

The algorithm scans electronic records and may reduce sepsis deaths, but widespread adoption could be a challenge.

Mix and match plots to get more information from a scatter plot
Use a cocktail of 13 modern regularization techniques! () [1/9] — Sebastian Raschka (@rasbt)
An explanation of reference categories and picking the right one
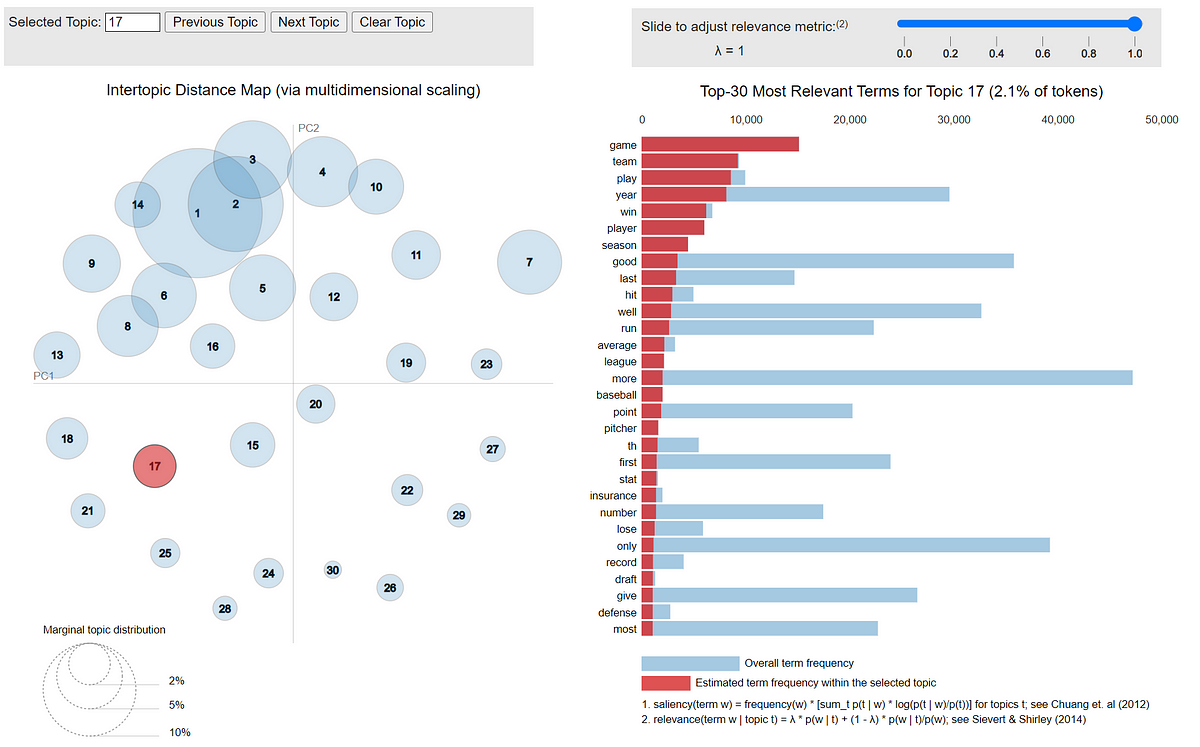
A comparison between different topic modeling strategies including practical Python examples
How to compress and fit a humongous set of vectors in memory for similarity search with asymmetric distance computation (ADC)
Learn how to build MMMs for different countries the right way
The best indexing approach for billion-sized vector datasets
Efficient vector quantization for machine learning optimizations (eps. vector quantized variational autoencoders), better than straight…
Overview of how object detection works, and where to get started
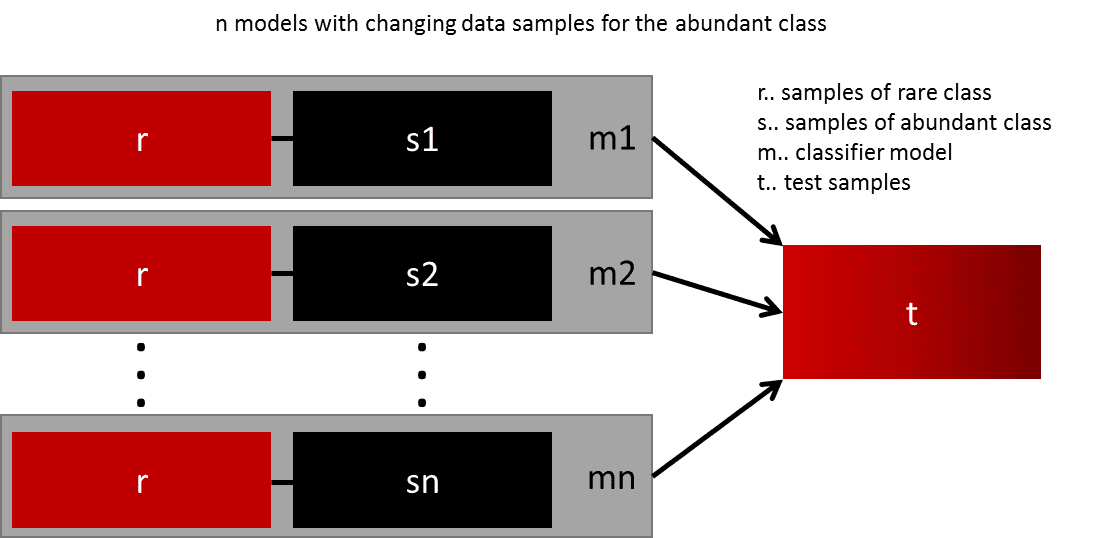
This blog post introduces seven techniques that are commonly applied in domains like intrusion detection or real-time bidding, because the datasets are often extremely imbalanced.
Complete Guideline to Find Dependencies among Categorical Variables with Chi-Square Test
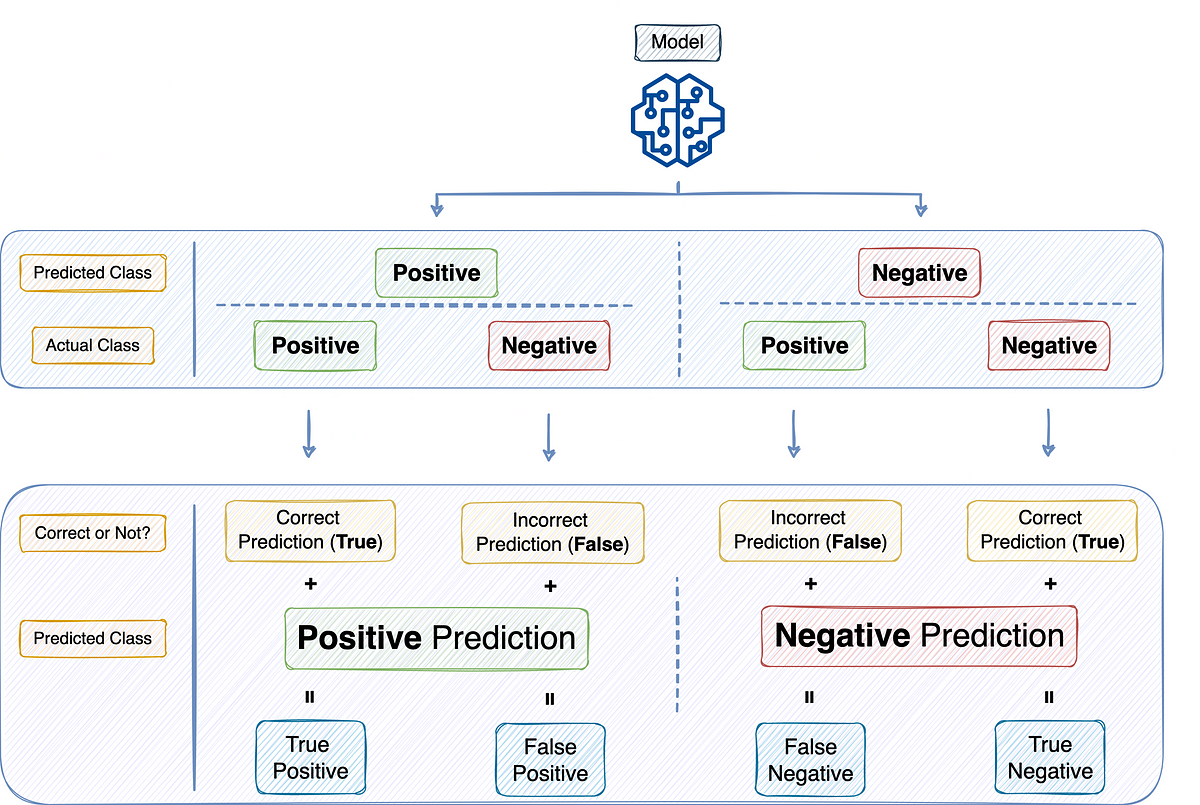
Precision and Recall elaborated with sample situations
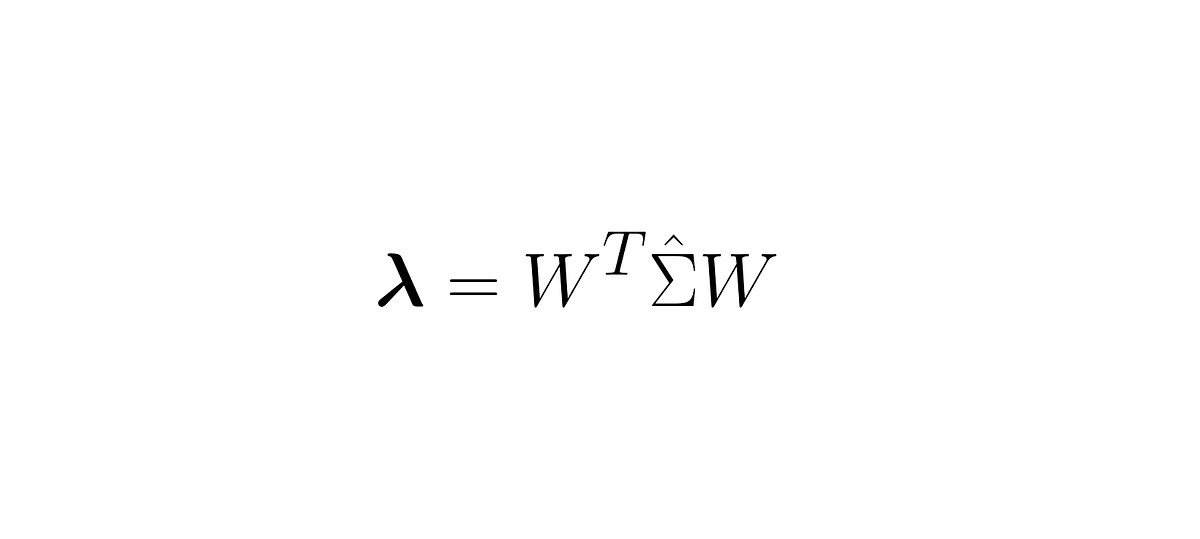
Covariance, eigenvalues, variance and everything …
530 votes, 63 comments. My co-founder and I, a senior Amazon research scientist and AWS SDE respectively, launched Marqo a little over a week ago - a…
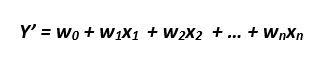
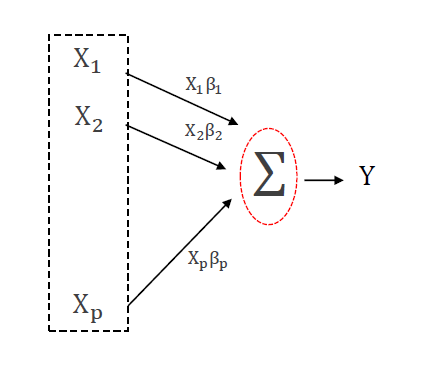
Who should read this blog: Someone who is new to linear regression. Someone who wants to understand the jargon around Linear Regression Code Repository: https://github.com/DhruvilKarani/Linear-Regression-Experiments Linear regression is generally the first step into anyone’s Data Science journey. When you hear the words Linear and Regression, something like this pops up in your mind: X1, X2,… Read More »Linear Regression Analysis – Part 1
Introduction to key elements of ML and Autoencoders: Embedding, Clustering, and Similarity.
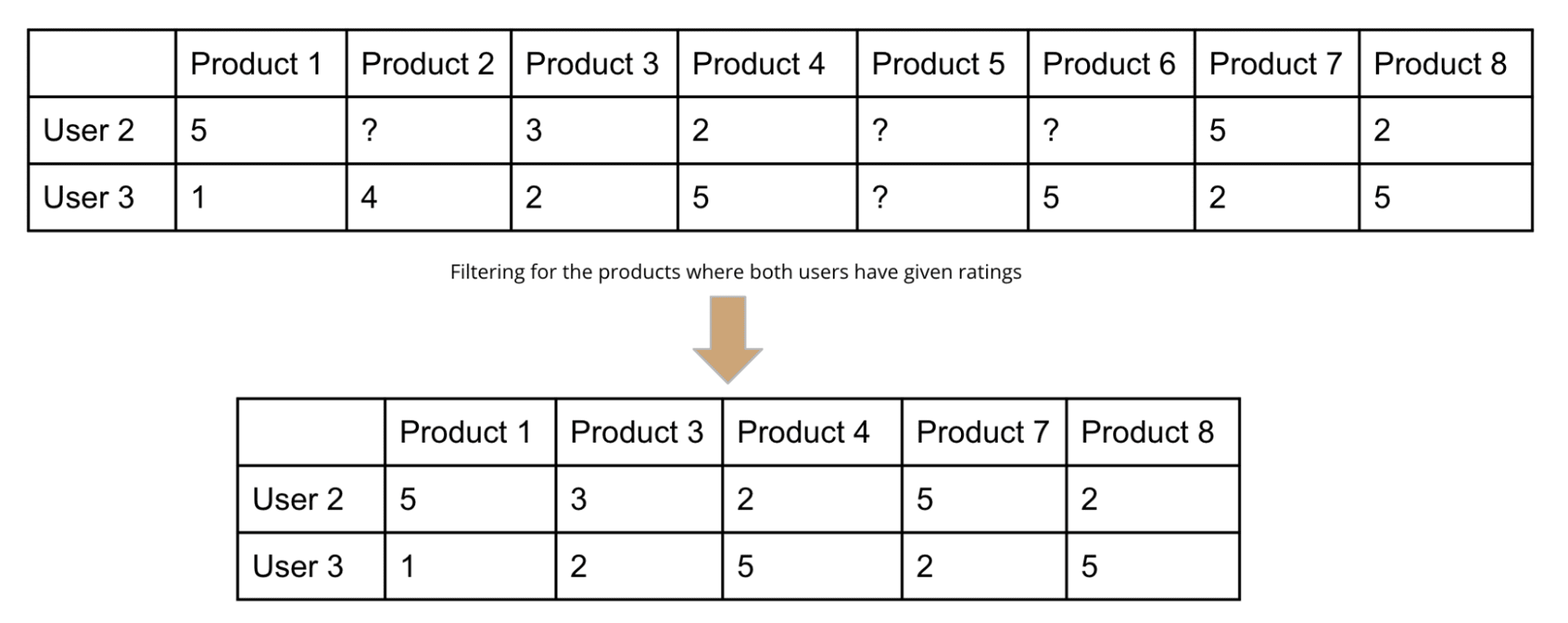
The post introduces one of the most popular recommendation algorithms, i.e., collaborative filtering. It focuses on building an intuitive understanding of the algorithm illustrated with the help of an example.

Let’s catch those high-dimensional outliers

Determining which promoted auction items to display in a merchandising placement is a multi-sided customer challenge that presents opportunities to both surface amazing auction inventory to buyers and help sellers boost visibility on their auction listings.

this post is explaining how permutation importance works and how we can code it using ELI5

In this article, we will specifically take a look at motion detection using a webcam of a laptop or computer and will create a code script to work on our computer and see its real-time example.
Avoid post-processing the SHAP values of categorical features

Creating eye-catching graphs with Python to use instead of bar charts.
Use the recently-released Transformers model to generate JSON representations of your document data
Graph partitioning has been a long-lasting problem and has a wide range of applications. This post shares the methodology for graph…

Reduce time in your data science workflow with these libraries.
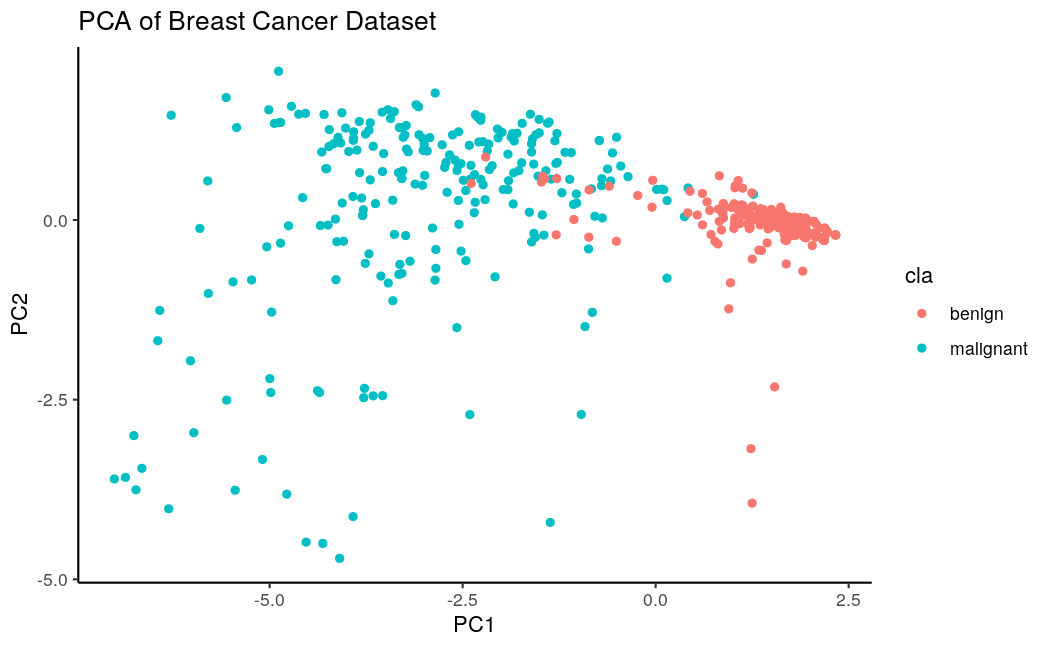
An algorithmic approach to clean up your dataset and sharpen class assignments.
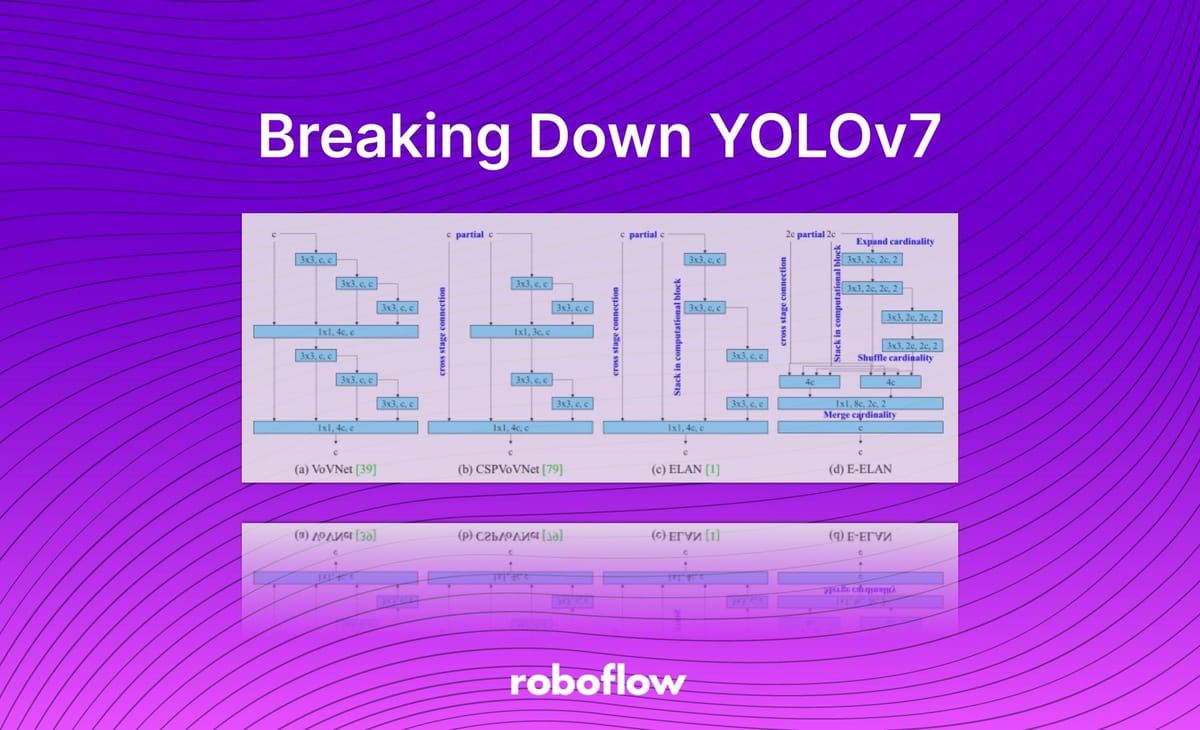
In this guide, we discuss what YOLOv7 is, how the model works, and the novel model architecture changes in YOLOv7.
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30...

Capturing non-linear advertising saturation and diminishing returns without explicitly transforming media variables
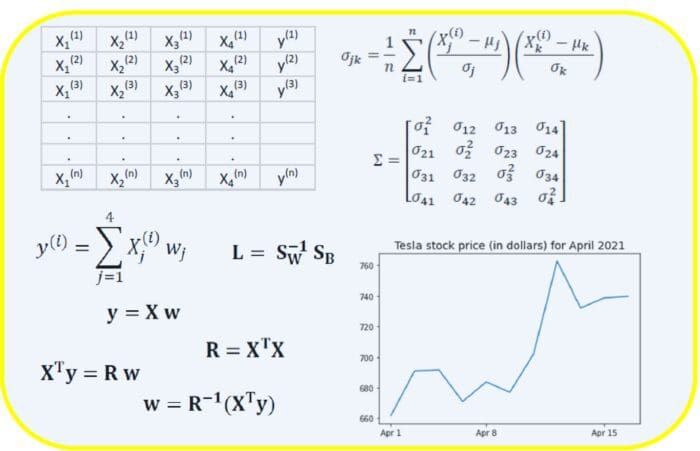
In this article, we discuss the importance of linear algebra in data science and machine learning.
How to forecast with scikit-learn and XGBoost models with sktime
The final goal of all industrial machine learning (ML) projects is to develop ML products and rapidly bring them into production. However, it is highly challenging to automate and operationalize...
Brain-inspired unsupervised machine learning through competition, cooperation and adaptation

Use linear programming to minimize the difference between required and scheduled resources
Want to know what is discriminant analysis & how does it help in analyzing data? Read this complete guide on Discriminant analysis now.
Quantifying Uncertainty in Computation.
A curated list of practical financial machine learning tools and applications. - firmai/financial-machine-learning
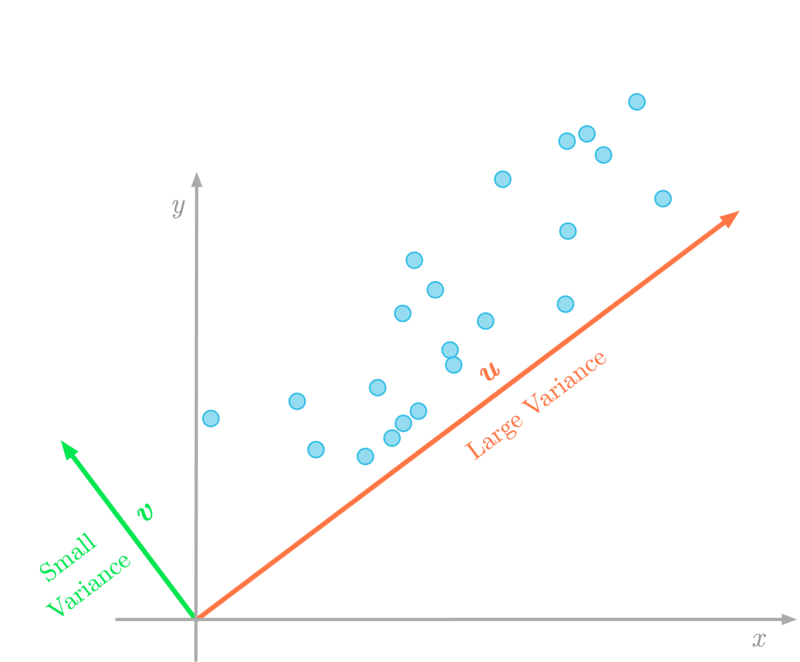
In this article, you’ll learn about the eigendecomposition of a matrix.
A List of Recommender Systems and Resources.
How we applied qualitative learning, human labeling and machine learning to iteratively develop Airbnb’s Community Support Taxonomy.
Which metric should be used to evaluate the clustering results if the ground truth labels are not available? In this post, I’m introducing…

Buyers reveal a whole range of behaviors and interests when they browse our pages, so we decided to incorporate these additional purchase intent signals into our machine learning model to improve the relevance of our recommended items.
No need to worry about getting stuck in local minima anymore
Manual Calculation From a Confusion Matrix and the Syntax of sklearn Library
Illustrated study guides ideal for visual learners.

How to use Python libraries like Open3D, PyVista, and Vedo for neighborhood analysis of point clouds and meshes through KD-Trees/Octrees

In this article, I will take you through the task of Time Series Forecasting with ARIMA using the Python programming language.
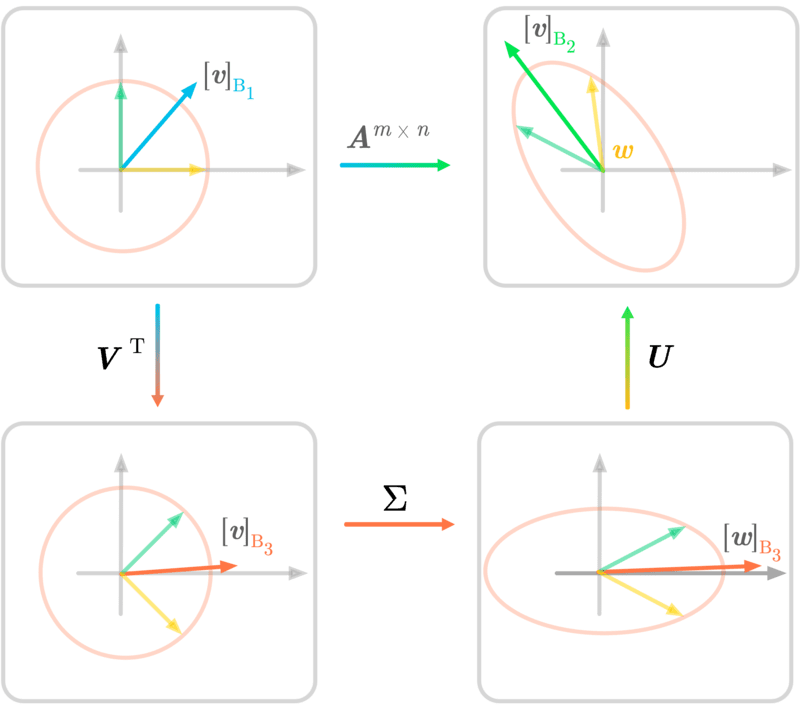
This article will cover singular value decomposition (SVD), which is a major topic of linear algebra, data science, and machine learning.

A preview into one of the most prominent data science applications
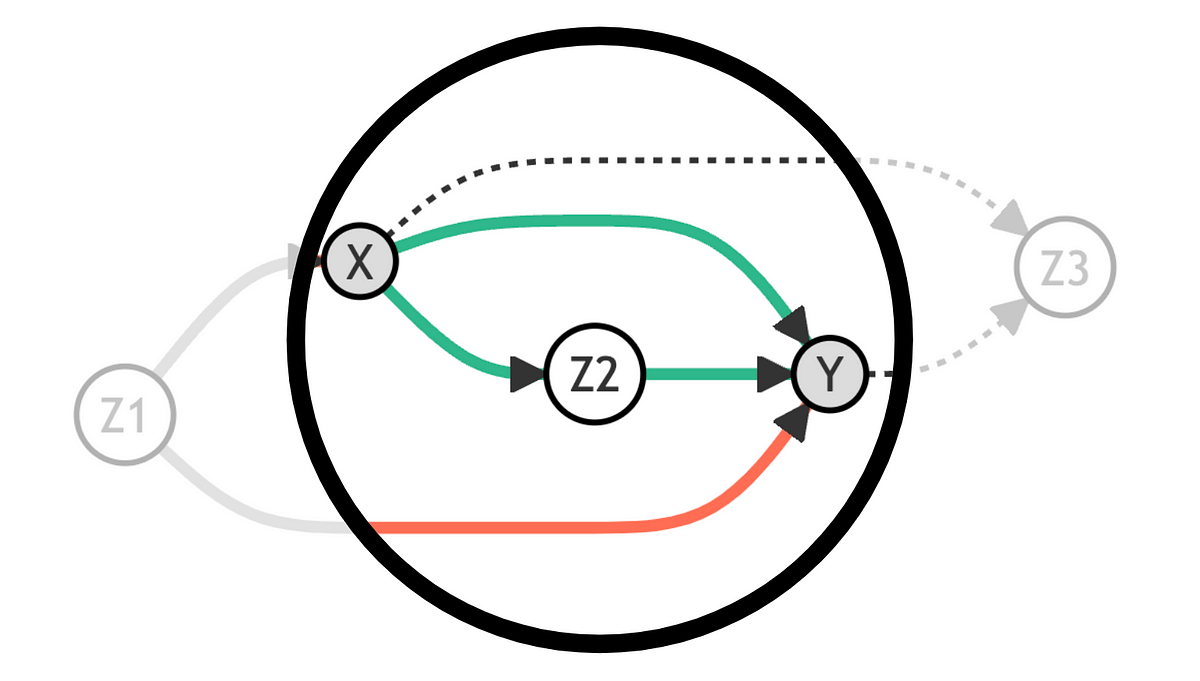
How to select control variables for causal inference using Directed Acyclic Graphs

We’ll show how to use the DID model to estimate the effect of hurricanes on house prices

Understanding the model’s output plays a major role in business-driven projects, and Sobol can help

Reproducibility is critical for robust data science — after all, it is a science.

The curse of dimensionality comes into play when we deal with a lot of data having many dimensions or features.
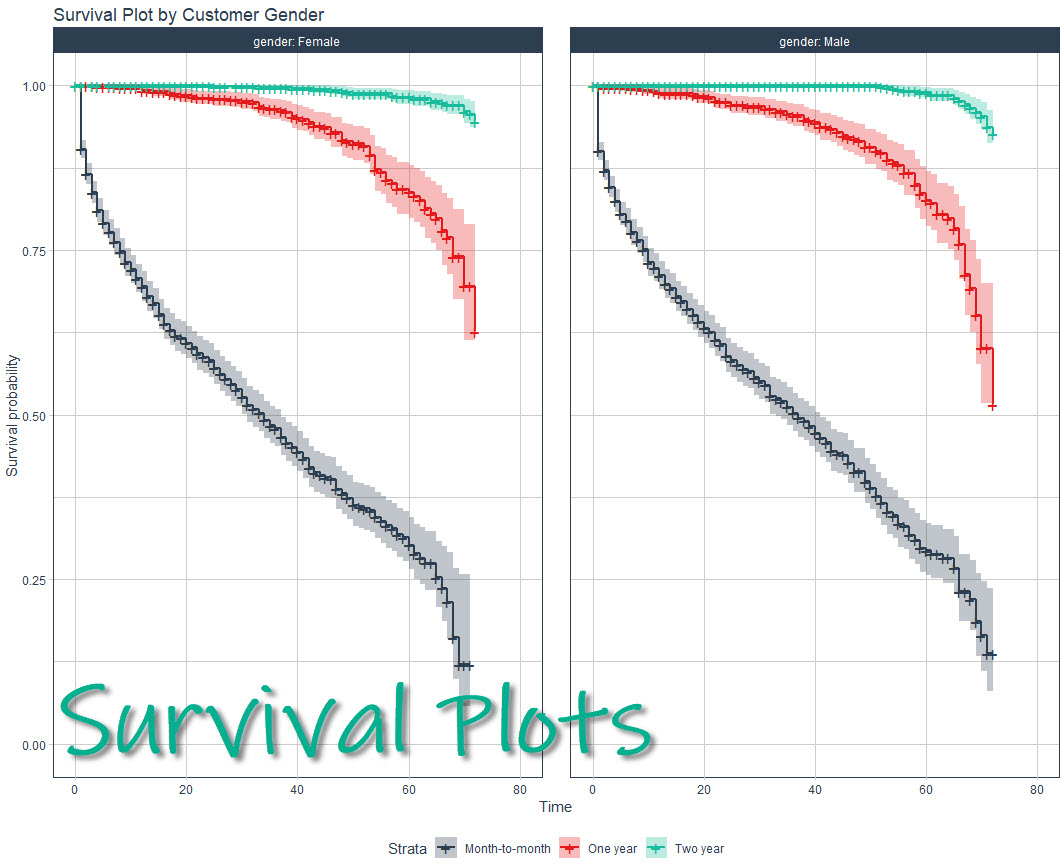
Making a survival analysis can be a challenge even for experienced R users, but the good news is I’ll help you make beautiful, publication-quality survival plots in under 10-minutes. Here’s what WE are going to do: Make your first survival model an...
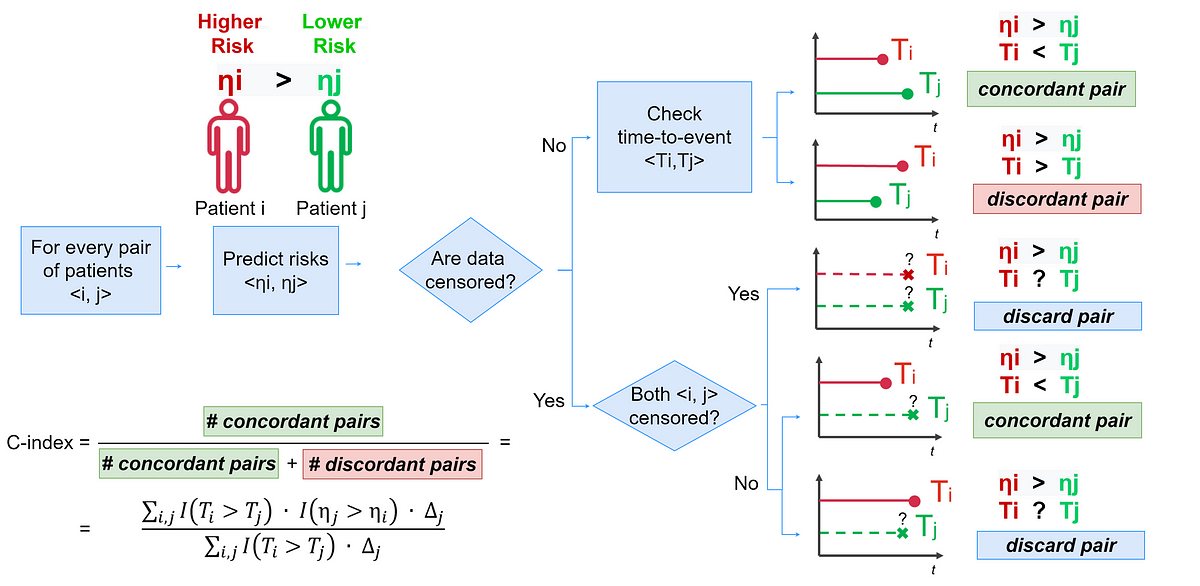
Introduction to the most popular performance evaluation metrics for survival analysis along with practical Python examples

Evaluating similarity of visual art from both human perceptual & quantitative judgments

I show toy implementations of Python decorator patterns that may be useful for Data Scientists.

The introduction of the intel sklearn extension. Make your Random Forest even faster than XGBoost.
Six matrix factorizations dominate in numerical linear algebra and matrix analysis: for most purposes one of them is sufficient for the task at hand. We summarize them here. For each factorization …

How you can pull one of a few dozen example political, sporting, education, and other frames on-the-fly.
An initial look into the method best suited for examining time-to-event data
Focal loss is said to perform better than Cross-Entropy loss in many cases. But why Cross-Entropy loss fails, and how Focal loss addresses…
Uncovering the secret behind why breads are always conveniently placed beside butter in groceries

The Shazam music recognition application made it finally possible to put a name to that song on the radio. But how does this magical miracle actually work? In this article, Toptal Freelance Software Engineer Jovan Jovanovic sheds light on the principles of audio signal processing, fingerprinting, and recognition,...

Apply Louvain’s Algorithm in Python for Community Detection

Under the new machine learning model, buyers are recommended items that are more aligned to their shopping interests on eBay.
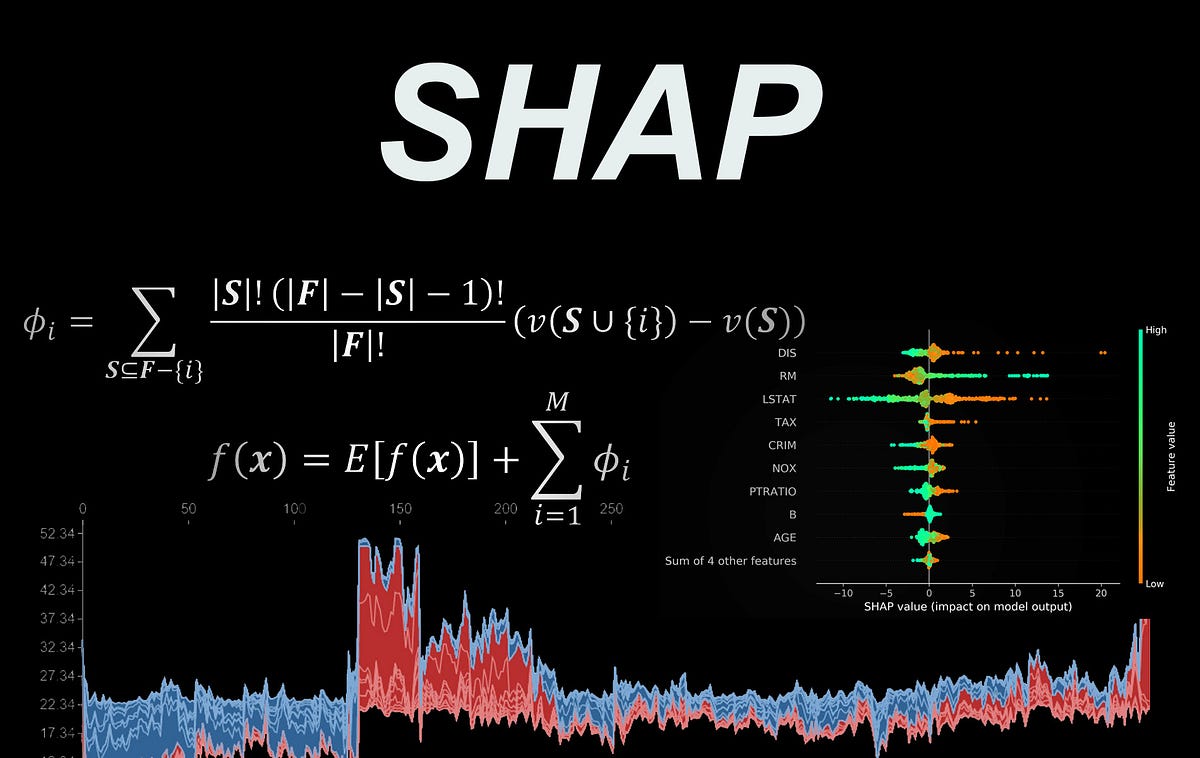
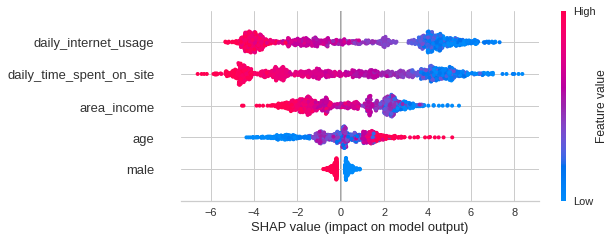
Learn how the SHAP library works under the hood

Why to learn these graph algorithms? Graph algorithms are a set of instructions that...

Use these three tools to understand the usefulness of your machine learning models
aka "Bayesian Methods for Hackers": An introduction to Bayesian methods + probabilistic programming with a computation/understanding-first, mathematics-second point of view. All i...

This thoroughly revised guide demonstrates how the flexibility of the command line can help you become a more efficient and productive data scientist. You’ll learn how to combine small yet powerful command-line tools to quickly obtain, scrub, explore, and model your data. To get you started, author Jeroen Janssens provides a Docker image packed with over 100 Unix power tools—useful whether you work with Windows, macOS, or Linux.

They can help you get an appointment or order a pizza, find the best ticket deals and bring your...
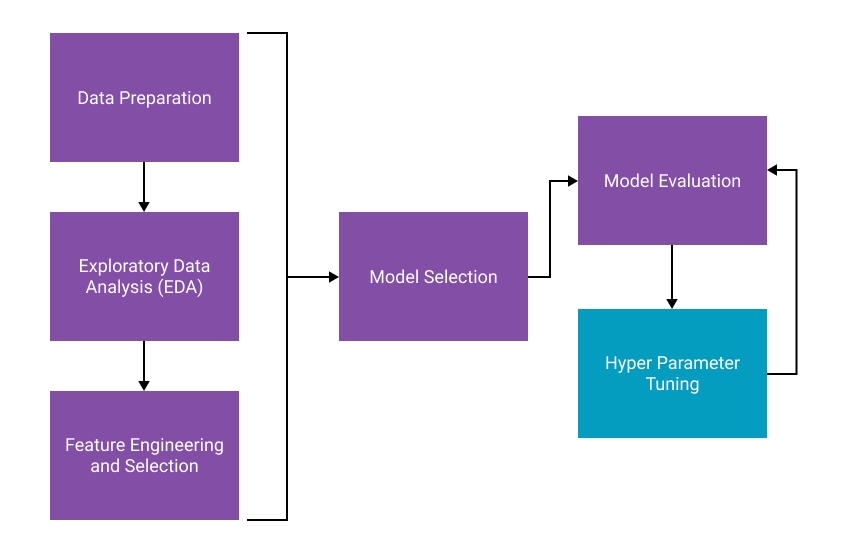
How to optimize the hyperparameters of a machine learning model and how to speed up the process
Managing Machine Learning Lifecycle made easy — explained with Python examples
Easily learn to track all of your ML experiments with metrics and logs with an example project walkthrough!

Natural Language Processing with Python, Gensim, Tensorflow, Transformers

As a data analyst at Microsoft, I must investigate and understand time-series data every day. Besides looking at some key performance…
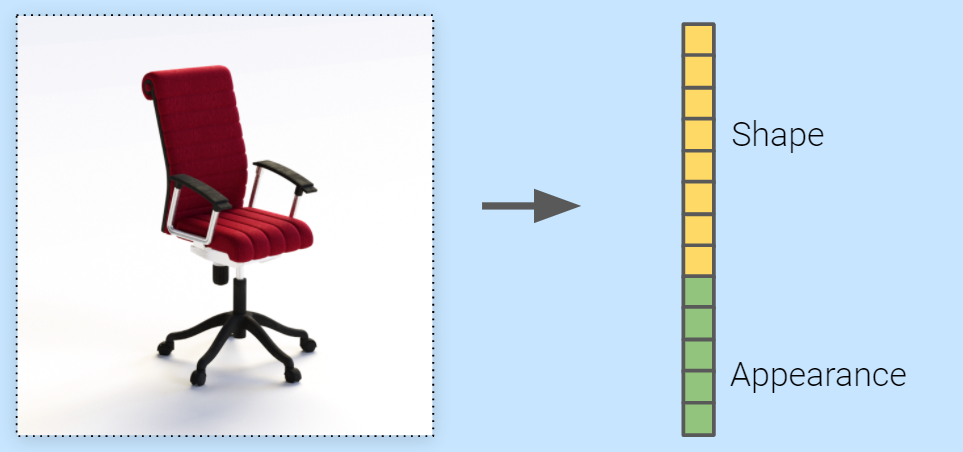
How we used NeRF to embed our entire 3D object catalogue to a shared latent space, and what it means for the future of graphics
We are excited to announce TorchRec, a PyTorch domain library for Recommendation Systems. This new library provides common sparsity and parallelism primitives, enabling researchers to build state-of-the-art personalization models and deploy them in production.
A dive into fundamentals of learning representations beyond feature vectors

Machine learning is a subfield of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way people learn, progressively improving its accuracy. This way, Machine Learning is one of the most interesting methods in Computer Science these days, and it'

We need to know what colors our merch is. But because downstream users include many different people and algorithms, we need to describe colors as a hierarch...

Two teams have shown how quantum approaches can solve problems faster than classical computers, bringing physics and computer science closer together.
based on "Hands-On Machine Learning with Scikit-Learn & TensorFlow" (O'Reilly, Aurelien Geron) - bjpcjp/scikit-and-tensorflow-workbooks
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F7399%2F1640135569_61c27b582ea87.png)
I analyzed thousands of searches by people who were diagnosed with cancer. Their queries offer valuable lessons that could improve the way doctors treat patients.

There are many great boosting Python libraries for data scientists to reap the benefits of. In this article, the author discusses LightGBM benefits and how they are specific to your data science job.
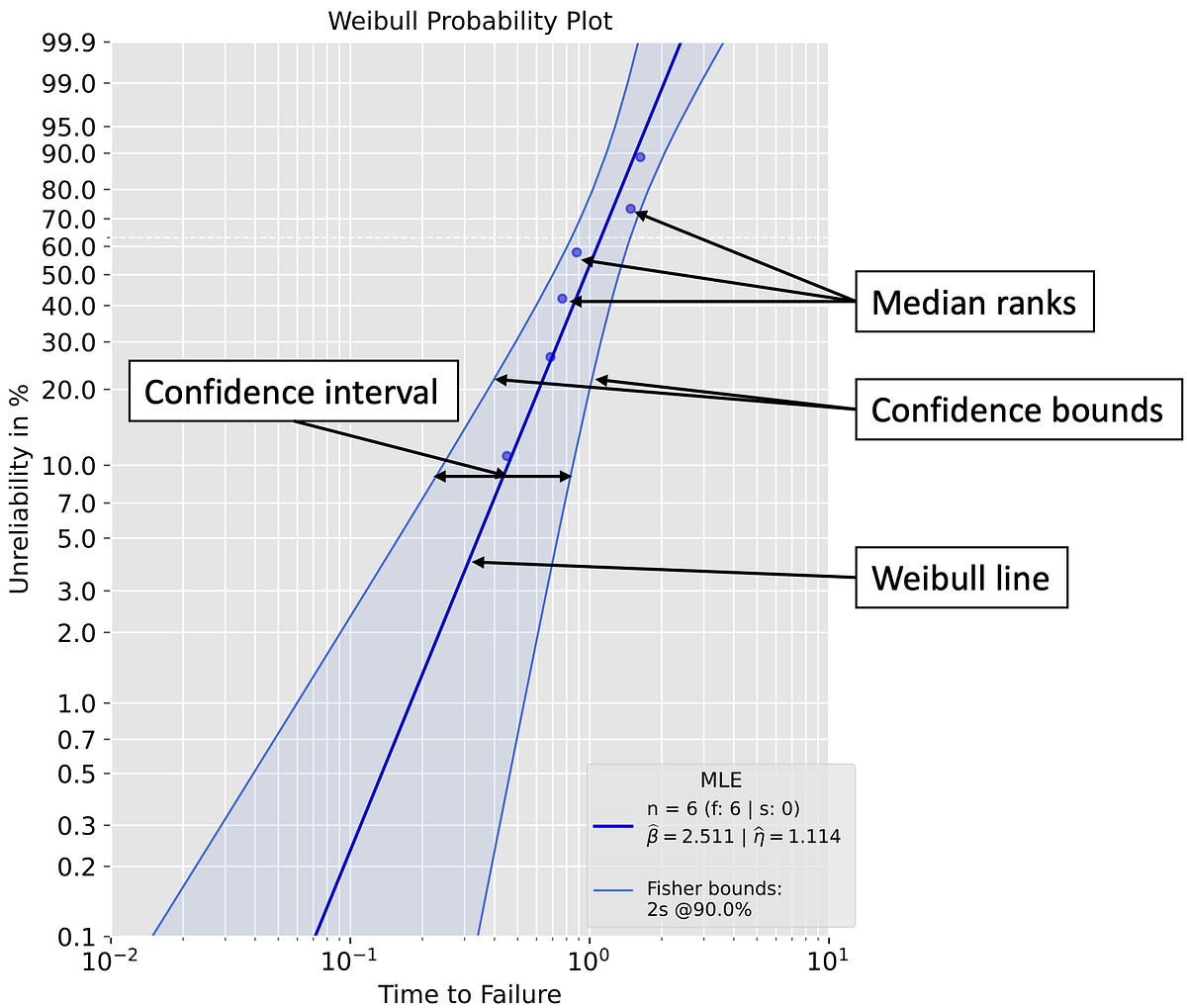
A Quick Guide to The Weibull Analysis
Prophet (FB time series prediction package) docs to Python code. - bjpcjp/fb-prophet
Updates in progress. Jupyter workbooks will be added as time allows. - bjpcjp/scikit-learn
Sourced from O'Reilly ebook of the same name.

The decision boundary is a very important visual tool for model evaluation. See how to get it to work on complex datasets
Sourced from O'Reilly ebook of the same name.
based on "Hands-On Machine Learning with Scikit-Learn & TensorFlow" (O'Reilly, Aurelien Geron) - bjpcjp/scikit-and-tensorflow-workbooks
Easily and efficiently optimize your model’s hyperparameters with Optuna with a mini project
Thread 🧵👇🏻 — Rapid (@Rapid_API)
Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow... - thoughtworks/mlops-platforms

Understanding how Regularization can be useful to improve the performance of your model
📚 Papers & tech blogs by companies sharing their work on data science & machine learning in production. - eugeneyan/applied-ml
Combining the “Trend” and “Difference” Terms
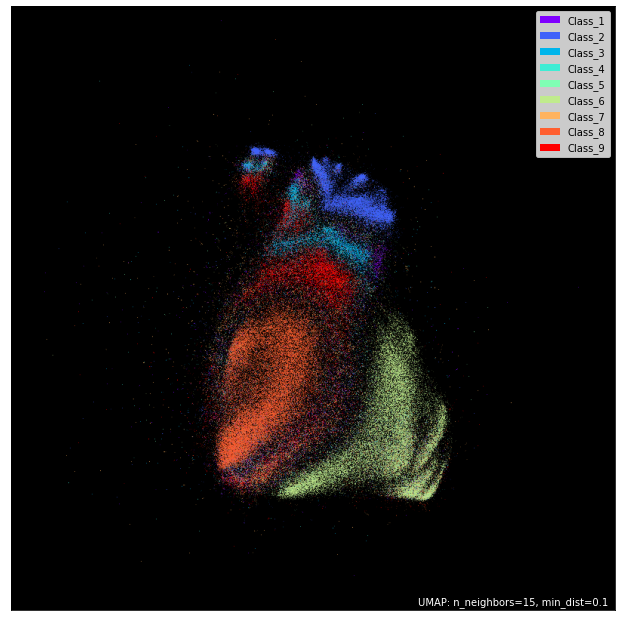
The whole ML is full of dimensionality reduction and its applications. Let’s see them in action!

Should you use PyTorch vs TensorFlow in 2023? This guide walks through the major pros and cons of PyTorch vs TensorFlow, and how you can pick the right framework.
Interactive Tools for Machine Learning, Deep Learning and Math - Machine-Learning-Tokyo/Interactive_Tools

Master usecols, chunksize, parse_dates in pandas read_csv().

Here is my take on this cool Python library and why you should give it a try

Dimensionality reduction is a vital tool for data scientists across industries. Here is a guide to getting started with it.

If an AI model can make decisions on the company’s behalf through products and services, that model is essentially their competitive edge.
Lessons learned from successful MLOps implementation

Powerful R libraries built by the World’s Biggest Tech Companies
via: — MIT CSAIL (@MIT_CSAIL)

How does Semi-Supervised Machine Learning work, and how to use it in Python?

In this first post in a series on how to build a complete machine learning product from scratch, I describe how to setup your project and tooling.

MedMNIST v2 is a large-scale MNIST-like collection of standardized biomedical images, including 12 datasets for 2D and 6 datasets for 3D. All images are pre-processed into 28 x 28 (2D) or 28 x 28 x 28 (3D) with the corresponding classification labels, so that no background knowledge is required for users. Covering primary data modalities in biomedical images, MedMNIST v2 is designed to perform classification on lightweight 2D and 3D images with various data scales (from 100 to 100,000) and diverse tasks (binary/multi-class, ordinal regression and multi-label). The resulting dataset, consisting of 708,069 2D images and 10,214 3D images in total, could support numerous research / educational purposes in biomedical image analysis, computer vision and machine learning. Description and image from: MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification Each subset keeps the same license as that of the source dataset. Please also cite the corresponding paper of source data if you use any subset of MedMNIST.
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental...

One of the best labelling tools I have ever used.

PyTorch Lightning has opened many new possibilities in deep learning and machine learning with a high level interface that makes it quicker to work with PyTorch.

Streamlit releases v1.0 of its DataOps platform for data science apps to make it easier for data scientists to share code and components.

In this post, you will learn some cool command line tricks which can help you to speed up your day-to-day R&D.

[Twitter thread, Hacker News discussion]
An introduction to the Kalman and Particle Filters and their applications in fields such as Robotics and Reinforcement Learning.
Create breathtaking visuals and “see” your data
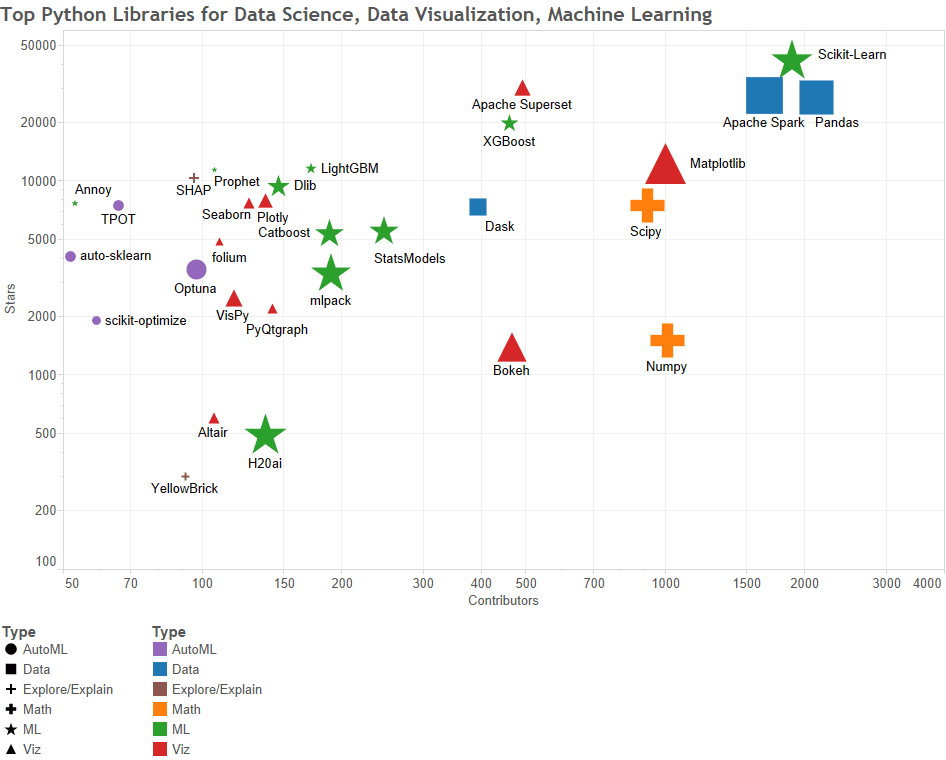
This article compiles the 38 top Python libraries for data science, data visualization & machine learning, as best determined by KDnuggets staff.

Hands-on tutorial to effectively use different Regression Algorithms
Multiplying matrices is among the most fundamental and compute-intensive operations in machine learning. Consequently, there has been significant work on efficiently approximating matrix...

Using “Kneedle” algorithmus detecting knees with Python package “kneed”
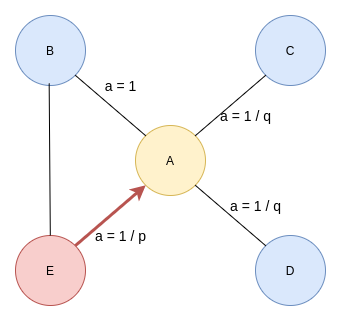
An in-depth guide to understanding node2vec algorithm and its hyper-parameters

The story of a decade-plus long journey toward a unified forecasting model.

This is part 3 of a series on bot programming originally published on the Coder One blog. Part 1:...
Why conformal prediction for uncertainty estimation can improve your predictions

Essential guide to various dimensionality reduction techniques in Python

Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application.
Papers With Code highlights trending Machine Learning research and the code to implement it.
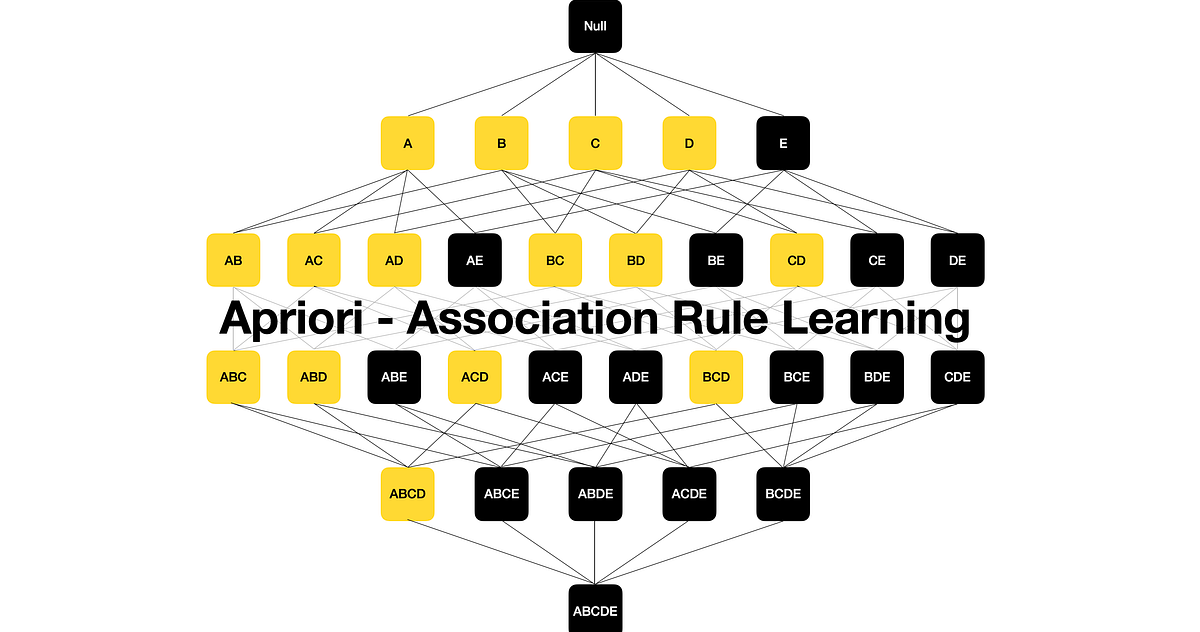
Explanation and examples of frequent itemset mining and association rule learning over relational databases in Python
With Streamlit creating a deploying a web app can be very easy!
Similarity search is one of the fastest-growing domains in AI and machine learning. At its core, it is the process of matching relevant pieces of information together.

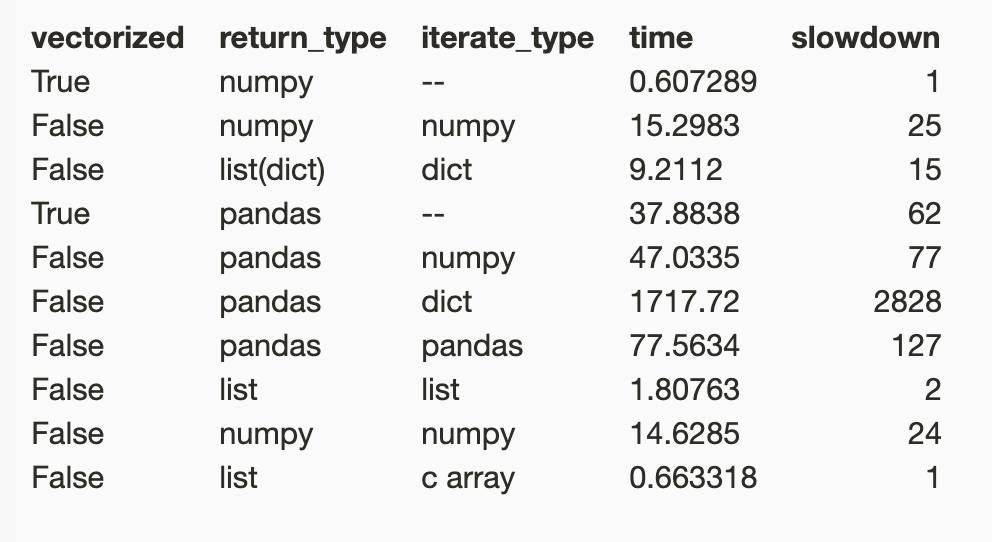
In this article, I’ll show you five ways to load data in Python. Achieving a speedup of 3 orders of magnitude.

For all their triumphs, AI systems can’t seem to generalize the concepts of “same” and “different.” Without that, researchers worry, the quest to create truly intelligent machines may be hopeless.
Combining tree-boosting with Gaussian process and mixed effects models - fabsig/GPBoost

In August, I set out to improve the machine learning ecosystem for Ruby and wasn’t sure where it would go. Over the next 5 months, I ended up...
This is a draft of a book for learning data analysis with the R language. This book emphasizes hands activities. Comments and suggestions are welcome.
Data Augmentation is one of the most important topics in Deep Computer Vision. When you train your neural network, you should do data augmentation like… ALWAYS. Otherwise, you are not using your…
A step-by-step tutorial to develop and interact with machine learning pipelines rapidly.

Sentiment Analysis, or Opinion Mining, is a subfield of NLP (Natural Language Processing) that aims to extract attitudes, appraisals, opinions, and emotions from text. Inspired by the rapid migration…
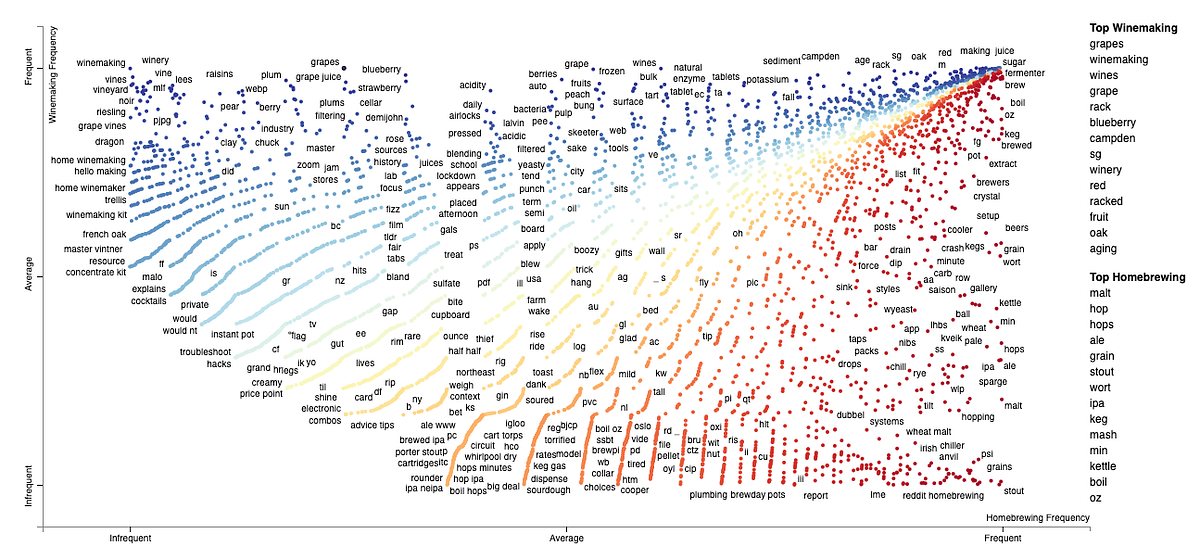
Scroll down to see how to interpret a plot created by a great tool for comparing two classes and their corpora.
In marketing analytics, conjoint analysis is a technique used to gain specific insights about consumers’ preferences. Often derived from consumer surveys, conjoint analysis can tell us, for instance…

Evaluating object detection models is not straightforward because each image can have many objects and each object can belong to different classes. This means that we need to measure if the model…
We are excited to announce that this year’s NeurIPS 2021 Conference will host a first-of-its-kind competition in large scale approximate…
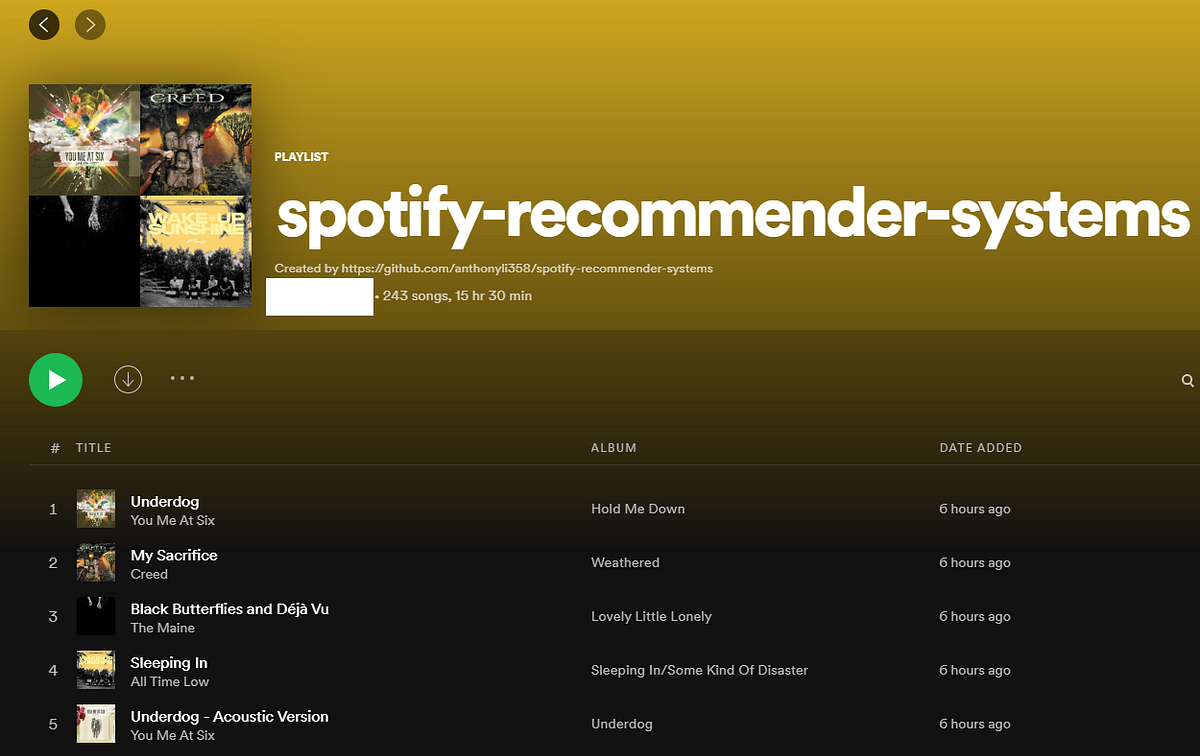
Creating Spotify recommendations with data science
Combining data science and econometrics for an introduction to the DeepIV framework, including a full Python code tutorial.
Word on the street is that PyTorch lightning is a much better version of normal PyTorch. But what could it possibly have that it brought such consensus in our world? Well, it helps researchers scale…

In this story, we are going to discuss an application of dynamic programming techniques to an optimization algorithm. Through the process of developing an optimal solution, we get to study a variety…
Essential extensions that will boost your productivity in Jupyter Notebook.

Machine-learning algorithms can quickly process thousands of hours of natural soundscapes

Modern AI systems approach tasks like recognising objects in images and predicting the 3D structure of proteins as a diligent student would prepare for an exam. By training on many example...
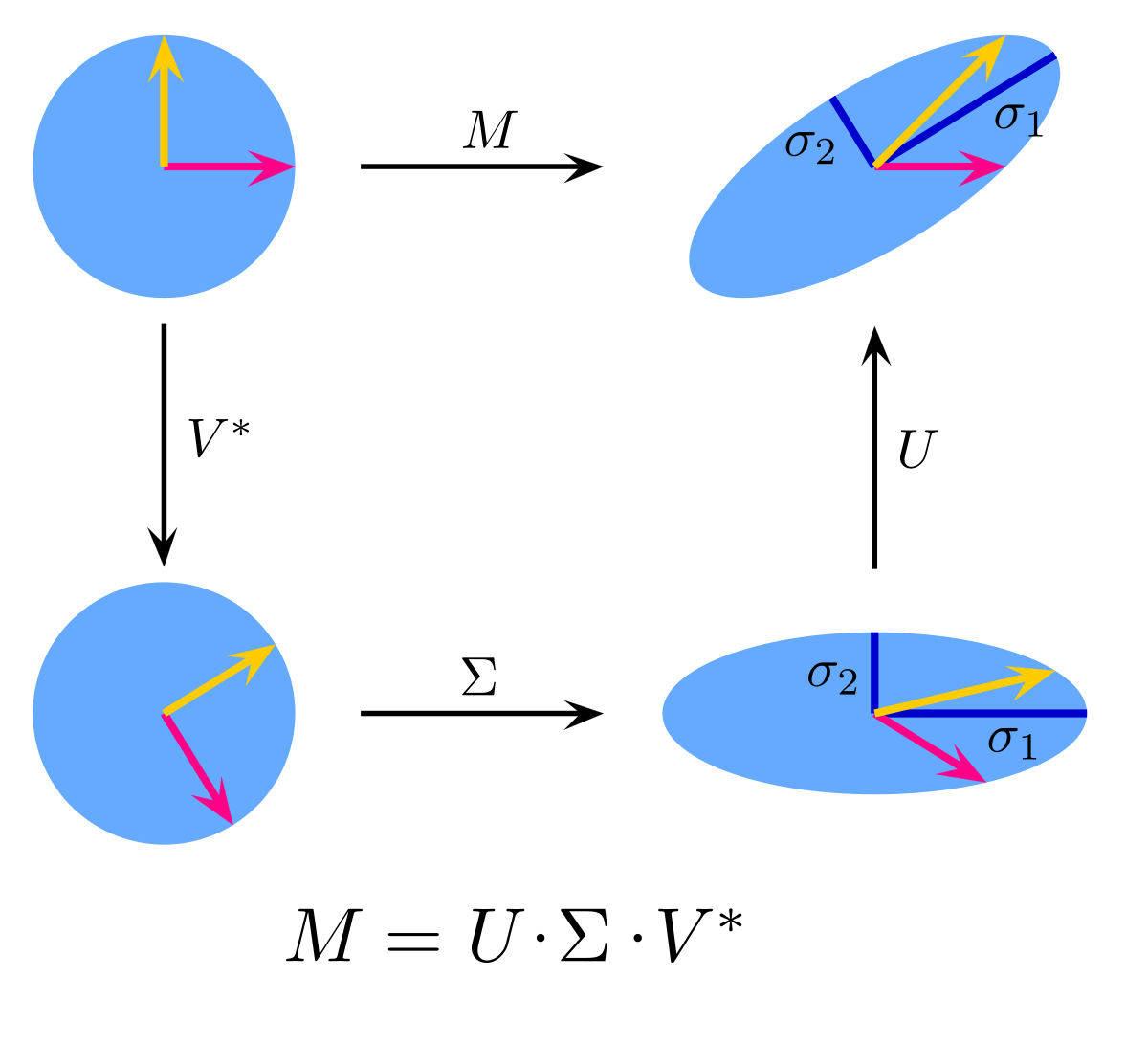
In linear algebra, the singular value decomposition (SVD) is a factorization of a real or complex matrix into a rotation, followed by a rescaling followed by another rotation. It generalizes the eigendecomposition of a square normal matrix with an orthonormal eigenbasis to any matrix. It is related to the polar decomposition.

Intuition for Unifying Theory of GLMs with Derivations in Canonical and Non-Canonical Forms
Generalized Linear Models (GLMs) play a critical role in fields including Statistics, Data Science, Machine Learning, and other computational sciences. In Part I of this Series, we provided a…

Bonus: What makes a good footballer great?

Prophet is a forecasting procedure implemented in R and Python. It is fast and provides completely automated forecasts that can be tuned by hand by data scientists and analysts.

Reduce the size of your dataset while keeping as much of the variation as possible

Framework improves efficiency, accuracy of applications that search for a handful of solutions in a huge space of candidates.

As Data Science continues to grow and develop, it’s only natural for new tools to emerge, especially considering the fact that data…

Winner’s Interview: 2nd place, Kazuki Onodera

A leading global retailer has invested heavily in becoming one of the most competitive technology companies around. Accurate and timely demand forecasting for millions of item-by-store combinations is…
Automate your hyperparameter tuning with Sklearn Pipelines and Hyperopts for multiple models in a single python call. Let's dig into the process...
There are often times when working in Data Science where we might come across a feature that is very difficult to interpret by a computer. This is often because the dimensions of the data are much…
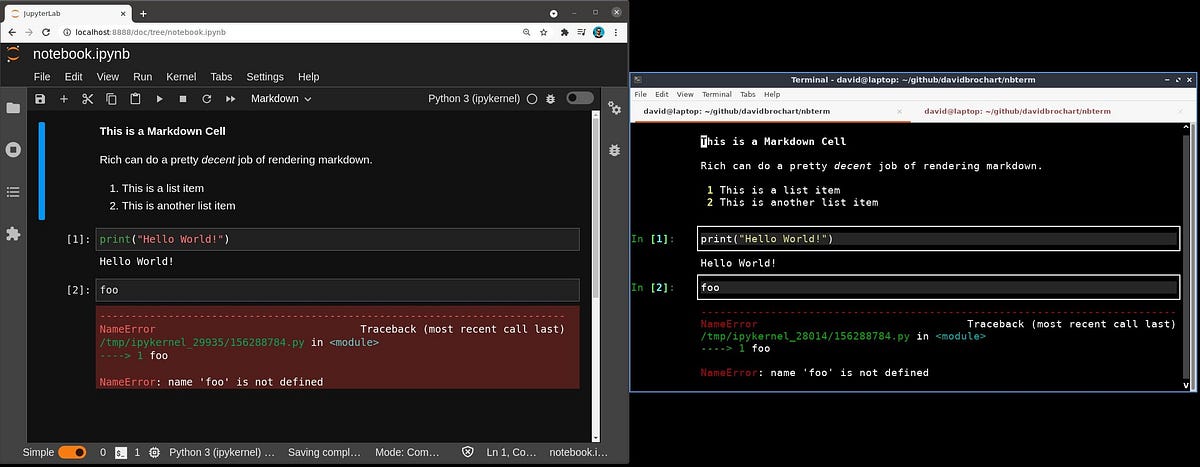
Jupyter notebooks are mostly known for their web-based user interface, such as JupyterLab or the Classic Notebook. They offer a great user…
Supervised Machine Learning — SVM, RANDOM FOREST, LOGISTIC REGRESSION

If you are dealing with a classification task, I recommend the modAL. As for the sequence labeling task, the AlpacaTag is the only choice for you. Active learning could decrease the number of labels…
Detailed tutorial on where to find a dataset, how to preprocess data, what model architecture and loss to use, and, finally, how to…
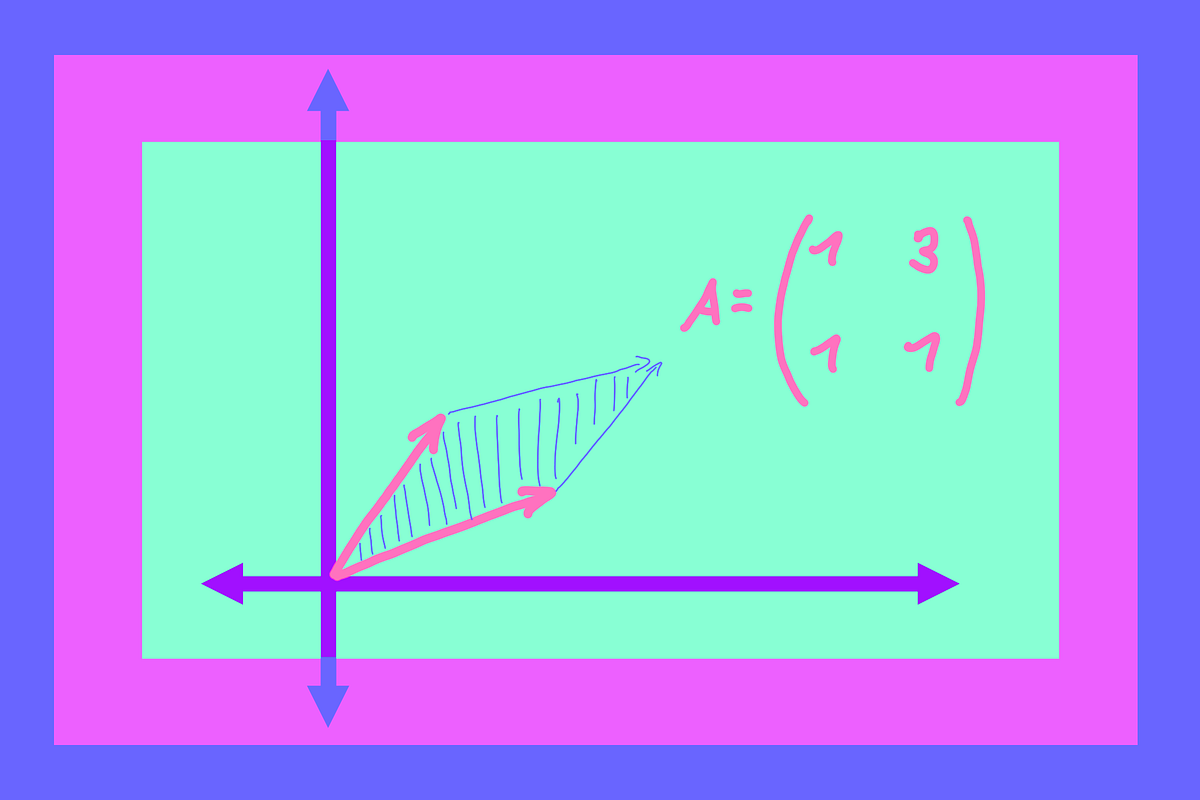
The geometric intuition behind determinants could change how you think about them.
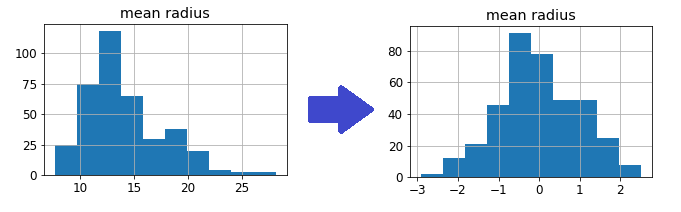
Let’s see this powerful tool of data pre-processing
PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. See how to use PyCaret's Regression Module for Time Series Forecasting.
Data Science, Machine Learning, AI & Analytics
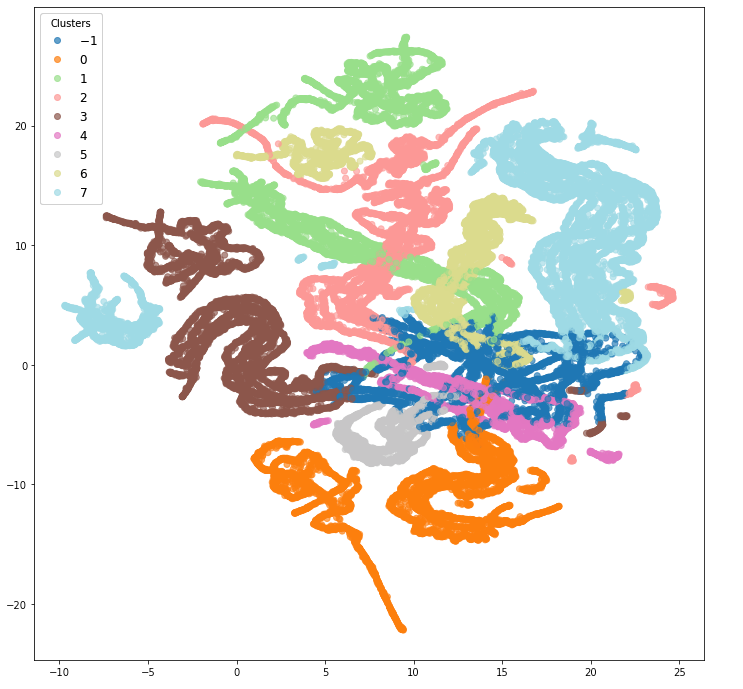
Improve clustering of user-item embedding by using GMM to generate new and tighter features
Scikit learn is *the* go to package for standard machine learning models in Python. It not only provides most of the core algorithms that…
XGBoost explained as well as gradient boosting method and HP tuning by building your own gradient boosting library for decision trees.

Successive halving completely crushes GridSearch and RandomSearch

Rice University computer scientists have demonstrated artificial intelligence (AI) software that runs on commodity processors and trains deep neural networks 15 times faster than platforms based on graphics ...
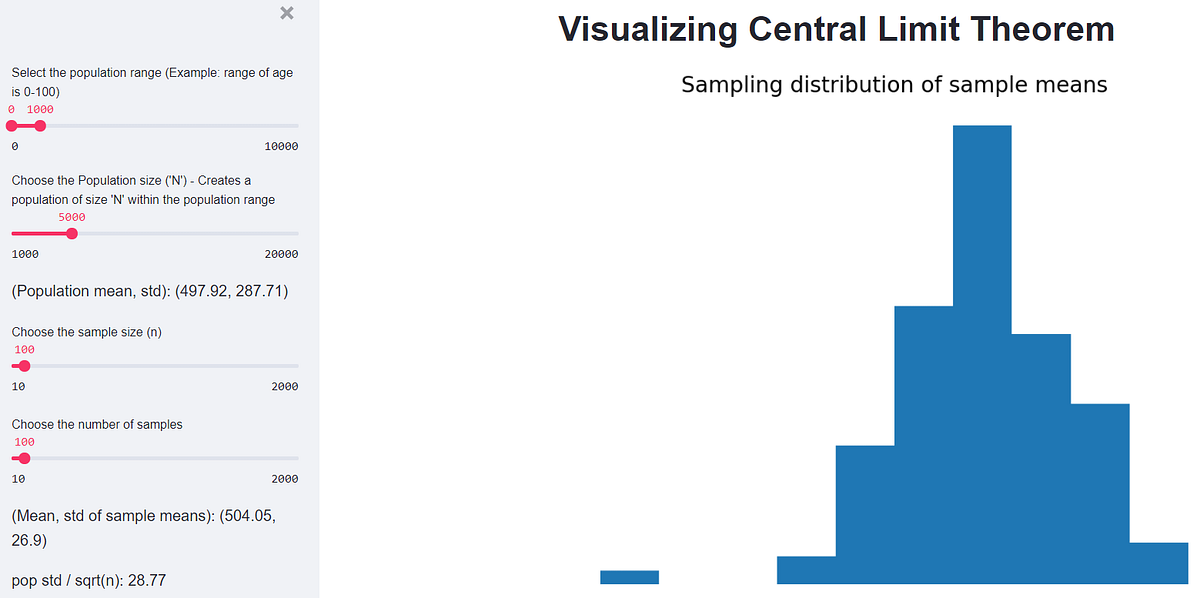
This article demonstrates the deployment of a basic Streamlit app (that simulates the Central Limit Theorem) to Heroku.

Utilize the hottest ML library for state-of-the-art performance in classification

This article demonstrates the deployment of a basic Streamlit app (that predicts the Iris’ species) to Streamlit Sharing.
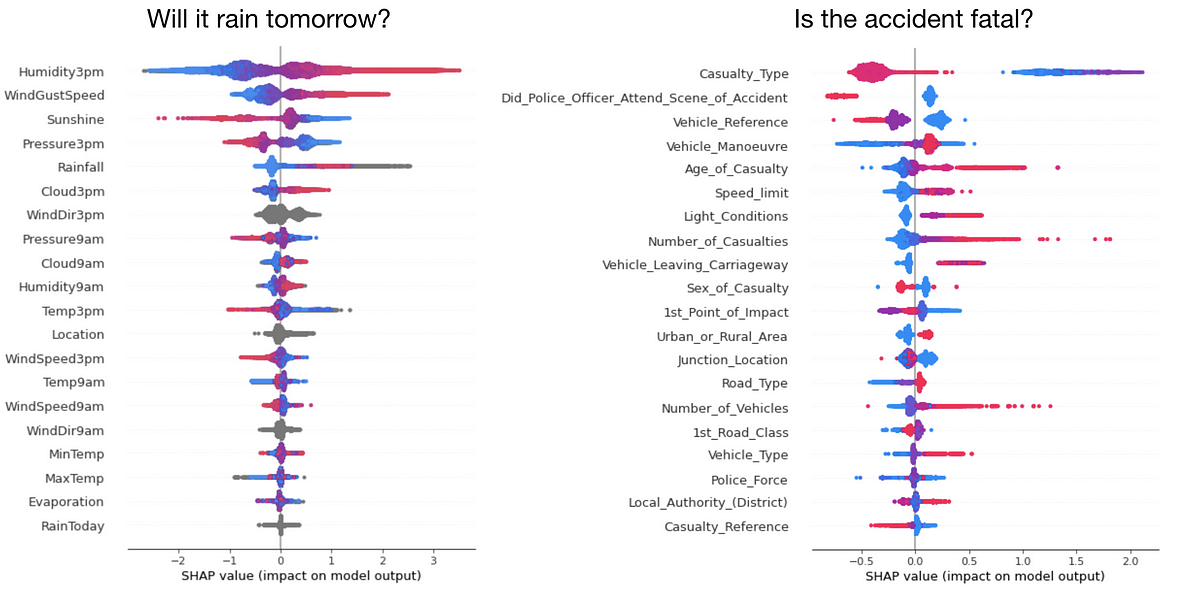
Your model is a lens into your data, and shap its telescope
Using Constraint Satisfaction Problems to solve AI Planning Problems.
In statistics, principal component regression (PCR) is a regression analysis technique that is based on principal component analysis (PCA). More specifically, PCR is used for estimating the unknown regression coefficients in a standard linear regression model.
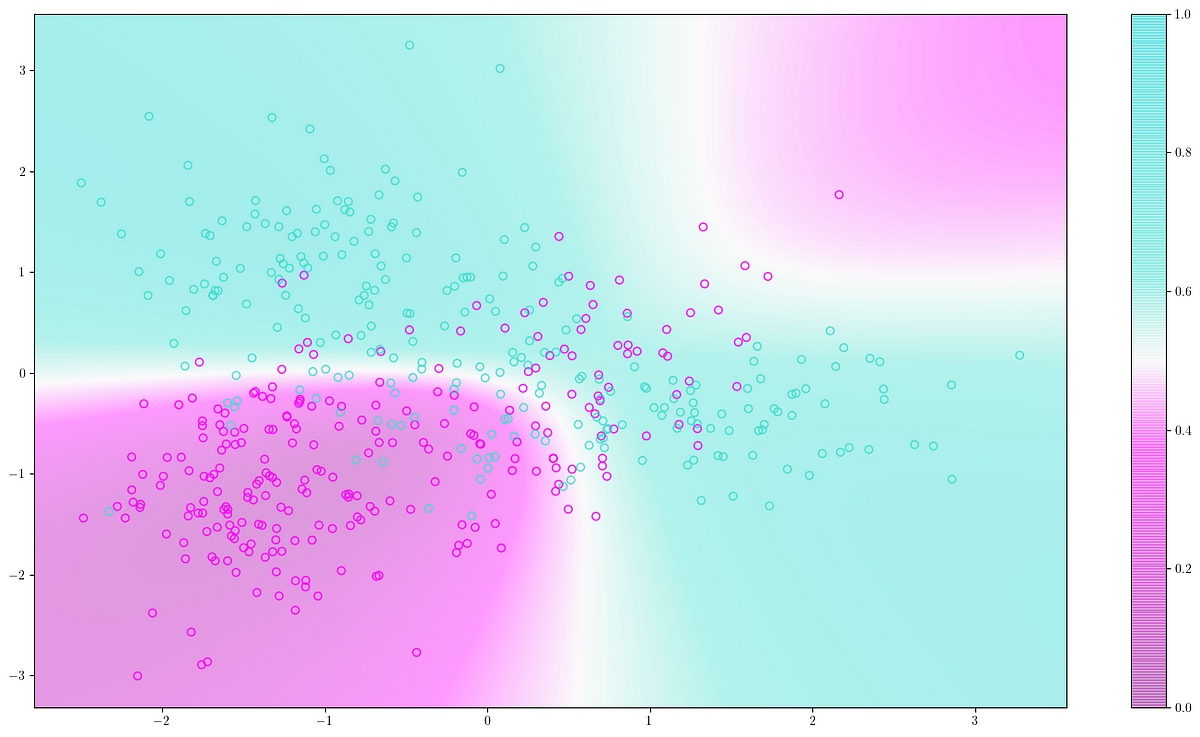
A deep introduction to Quadratic Discriminant Analysis (QDA) with theory and Python implementation
Discover datasets around the world!

The three-step framework Shopify's Data Science & Engineering team built for evaluating new search algorithms.

Machine Learning Projects solved and explained for free
This example shows how quantile regression can be used to create prediction intervals. See Features in Histogram Gradient Boosting Trees for an example showcasing some other features of HistGradien...

Creative techniques to make complex models smaller
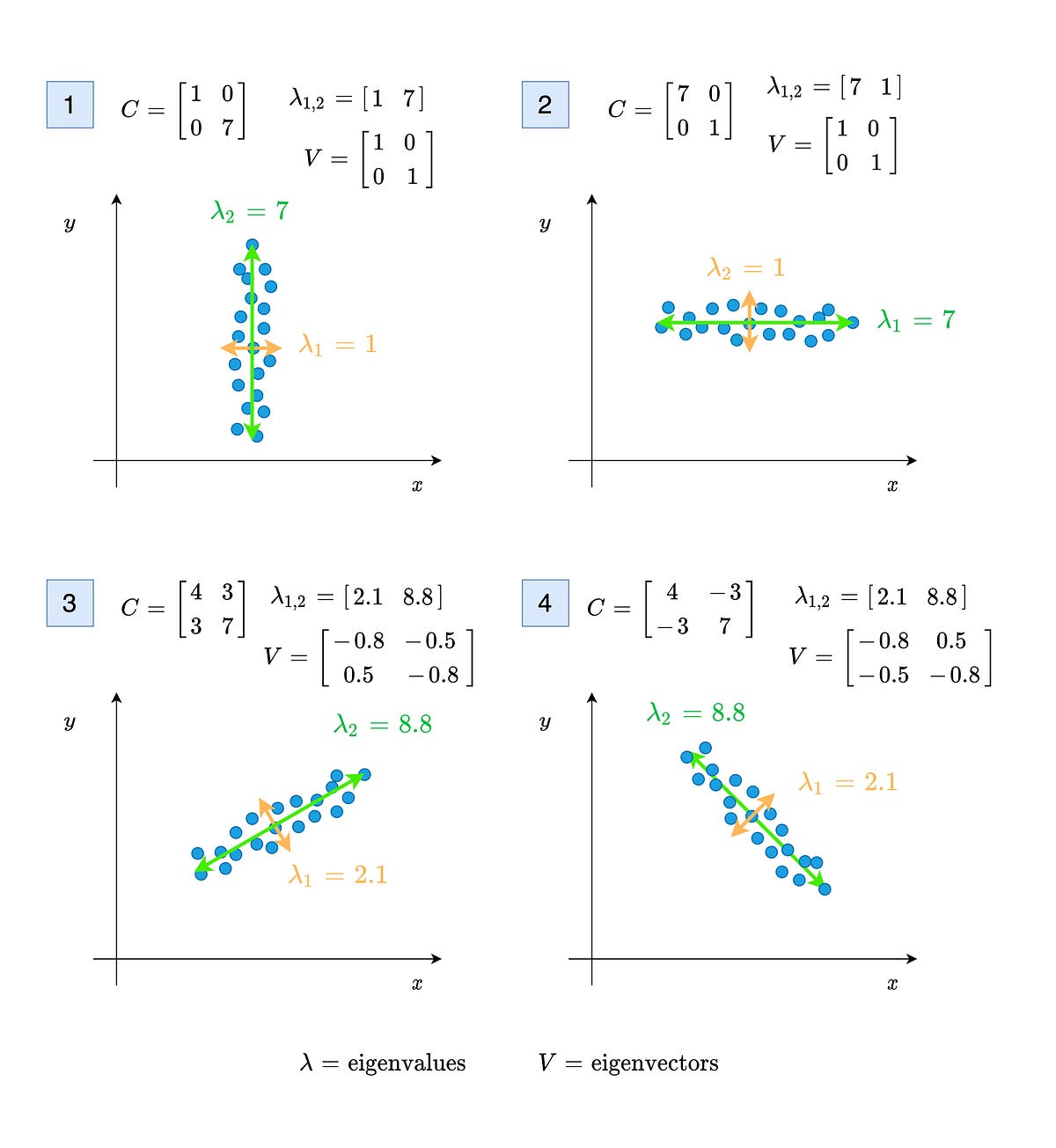
When dealing with problems on statistics and machine learning, one of the most frequently encountered terms is covariance. While most of…
Data Augmentation is one of the most important yet underrated aspects of a machine learning system …

It is a simple yet very efficient algorithm

Machine learning-based outlier detection

Note. This is an update to article: Using R and H2O to identify product anomalies during the manufacturing process.It has some updates but also code optimization from Yana Kane-Esrig( https://www.linkedin.com/in/ykaneesrig/ ), as sh...

GPU vs CPU training speed comparison for xgboost

A library for state-of-the-art self-supervised learning from images

A detailed look at differences between the two algorithms and when you should choose one over the other

an end-to-end tutorial on how to apply an emerging Data Science algorithm
Library for multi-armed bandit selection strategies, including efficient deterministic implementations of Thompson sampling and epsilon-greedy. - stitchfix/mab
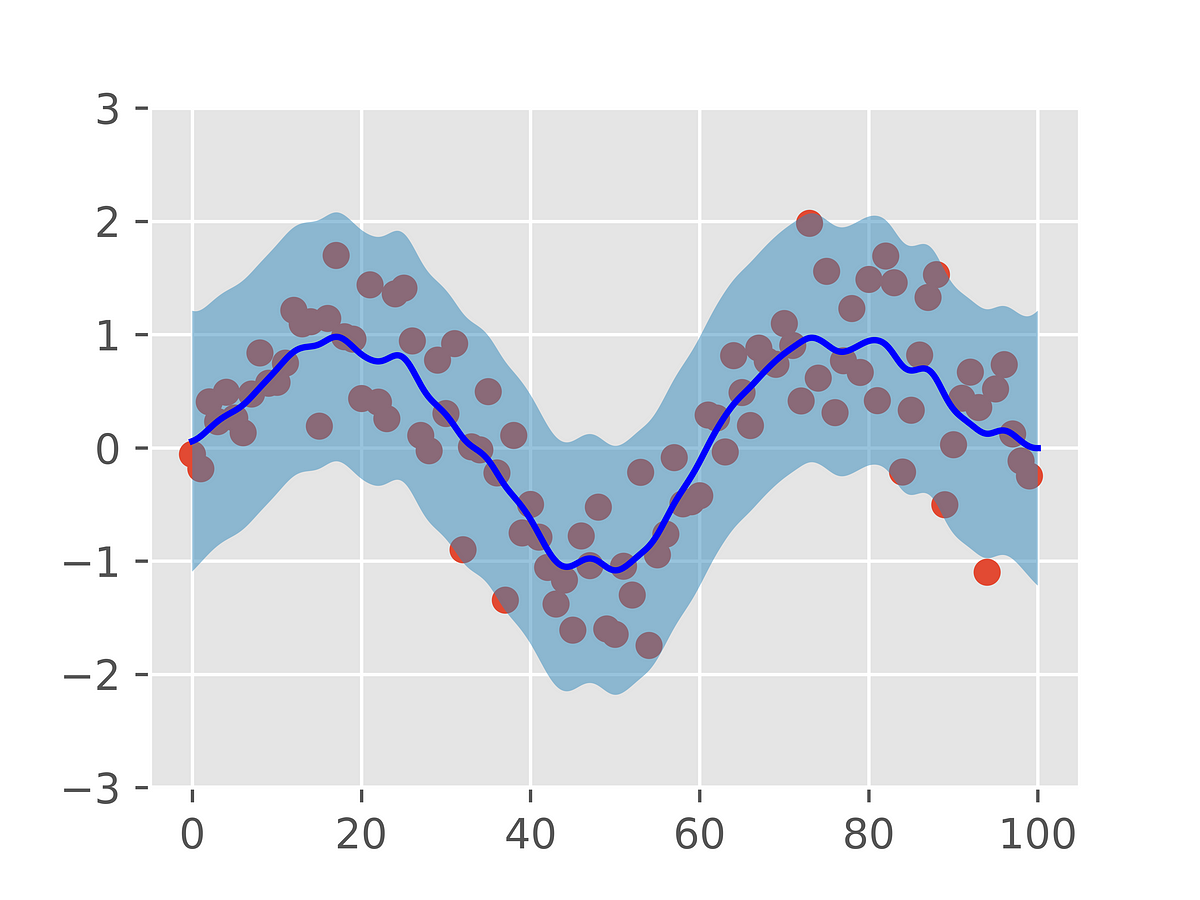
Gaussian Process Regression is a remarkably powerful class of machine learning algorithms. Here, we introduce them from first principles.
Introducing a spatial dimension into hierarchical clustering
Learn how AdaBoost works from a Math perspective, in a comprehensive and straight-to-the-point manner.

The quickest way to embed your models into web apps.
Natural Gradient Boosting for Probabilistic Prediction - stanfordmlgroup/ngboost

Train, visualize, evaluate, interpret, and deploy models with minimal code.

Instacart crunches petabytes daily to predict what will be on grocery shelves and even how long it will take to find parking

I have aggregated some of the SotA image generative models released recently, with short summaries, visualizations and comments. The overall development is summarized, and the future trends are spe…
Simple and reliable optimization with local, global, population-based and sequential techniques in numerical discrete search spaces. - SimonBlanke/Gradient-Free-Optimizers
[et_pb_section fb_built=”1″ admin_label=”Header” _builder_version=”4.12.0″ background_color=”#01012C” collapsed=”on” global_colors_info=”{}”][et_pb_row column_structure=”1_2,1_2″ _builder_version=”4.12.0″ collapsed=”on” global_colors_info=”{}”][et_pb_column type=”1_2″ _builder_version=”4.12.0″ z_index=”10″ custom_padding=”18%||||false|false” global_colors_info=”{}”][et_pb_text _builder_version=”4.14.7″ text_font=”Montserrat|800|||||||” text_text_color=”#01012C” text_font_size=”470px” text_line_height=”1em” positioning=”absolute” custom_margin=”|-30%||-10%|false|false” custom_margin_tablet=”|0%||-5%|false|false” custom_margin_phone=”|0%|||false|false” custom_margin_last_edited=”on|desktop” text_font_size_tablet=”40vw” text_font_size_phone=”40vw” text_font_size_last_edited=”on|tablet” text_text_shadow_style=”preset5″ text_text_shadow_horizontal_length=”-1.5px” text_text_shadow_vertical_length=”-1.5px” text_text_shadow_color=”#DB0EB7″ global_colors_info=”{}”] pc [/et_pb_text][et_pb_text _builder_version=”4.14.7″ header_font=”Barlow Condensed|500|||||||” header_text_color=”#FFFFFF” header_font_size=”122px” custom_margin=”||0px||false|false” header_font_size_tablet=”42px” header_font_size_phone=”26px” header_font_size_last_edited=”on|tablet” global_colors_info=”{}”] low-code machine learning [/et_pb_text][et_pb_button button_url=”https://pycaret.gitbook.io” url_new_window=”on” button_text=”GET STARTED” _builder_version=”4.14.7″ […]
Concluding this three-part series covering a step-by-step review of statistical survival analysis, we look at a detailed example implementing the Kaplan-Meier fitter based on different groups, a Log-Rank test, and Cox Regression, all with examples and shared code.
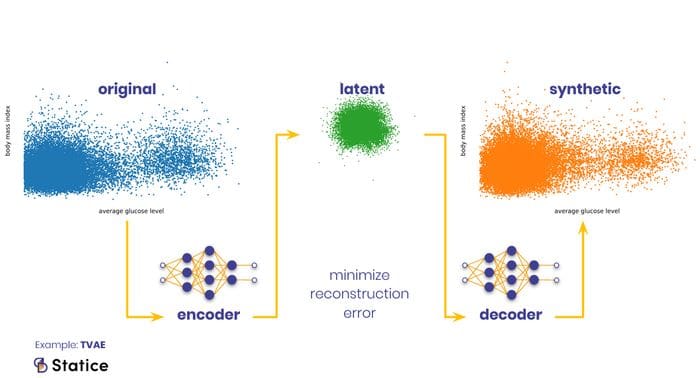
Synthetic data can be used to test new products and services, validate models, or test performances because it mimics the statistical property of production data. Today you'll find different types of structured and unstructured synthetic data.

Have you ever wondered how often do you buy certain items together? Why do you buy some items together? How likely do you purchase an item…

Ever wondered how to implement a simple baseline model for multi-class problems ? Here is one example (code included).

The error backpropagation learning algorithm is a supervised learning technique for neural networks that calculates the gradient of descent for weighting different variables.

A simple technique for boosting accuracy on ANY model you use
The data science and artificial intelligence terms you need while reading the latest research
A comprehensive guide on standard generative graph approaches with implementation in NetworkX
Computer Science, Machine Learning, Programming, Art, Mathematics, Philosophy, and Short Fiction
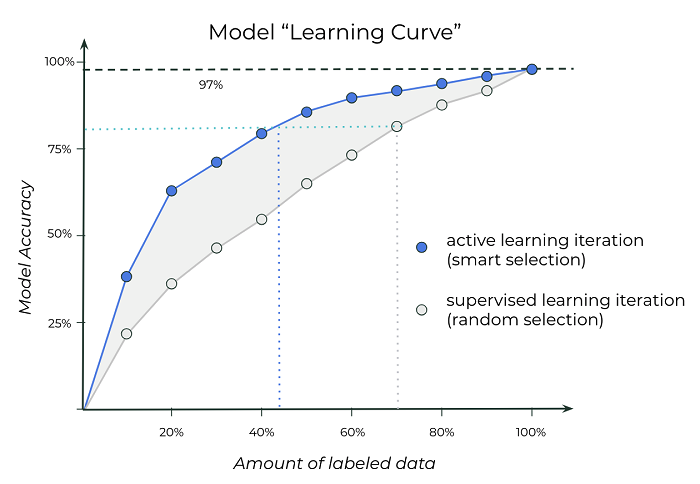
Data labeling is often the biggest bottleneck in machine learning. Active learning lets you train machine learning models with much less labeled data. The best AI-driven companies, like Tesla, use active learning.
With the power and popularity of the scikit-learn for machine learning in Python, this library is a foundation to any practitioner's toolset. Preview its core methods with this review of predictive modelling, clustering, dimensionality reduction, feature importance, and data transformation.

How to identify and segregate specific blobs in your image
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F5796%2F1601055329_Graph_826_MHeule_5K.jpg)
By making the first progress on the “chromatic number of the plane” problem in over 60 years, an anti-aging pundit has achieved mathematical immortality.

A complete explanation of the inner workings of Support Vector Machines (SVM) and Radial Basis Function (RBF) kernel
Strip charts are extremely useful to make heads or tails from dozens (and up to several hundred) of time series over very long periods of…
Using Mutual Information to measure the likelihood of candidate links in a graph.

Microsoft Excel is a powerful tool for learning the basics of data science and machine learning.

Jason Mayes Senior Creative Engineer, Google Machine Learning 101 Feel free to share this deck with others who are learning! Send me feedback here. Dec 2017 Welcome! If you are reading the notes there are a few extra snippets down here from time to time. But more for my own thoughts, feel free to...

Why is Model Compression important? A significant problem in the arms race to produce more accurate models is complexity, which leads to…
An Overview of the Most Important Features in Version 0.24

This article shows a comparison of the implementations that result from using binary, Gray, and one-hot encodings to implement state machines in an FPGA. These encodings are often evaluated and applied by the synthesis and implementation tools, so it’s important to know why the software makes these decisions.

And why your data science team needs it.

A tutorial on how to build a GitHub App that predicts and applies issue labels using Tensorflow and public datasets.

Stochastic gradient descent optimisation algorithms you should know for deep learning
This website is for sale! benchmarkfcns.xyz is your first and best source for all of the information you’re looking for. From general topics to more of what you would expect to find here, benchmarkfcns.xyz has it all. We hope you find what you are searching for!

Making the move from Docker to Live Deployments

This is the next installment in the "Practical Computer Science" series, where you will learn how to apply classic computer science concepts to solve real problems using Ruby. Today we are going to talk about Graph

Demystifying the inner workings of BFGS optimization
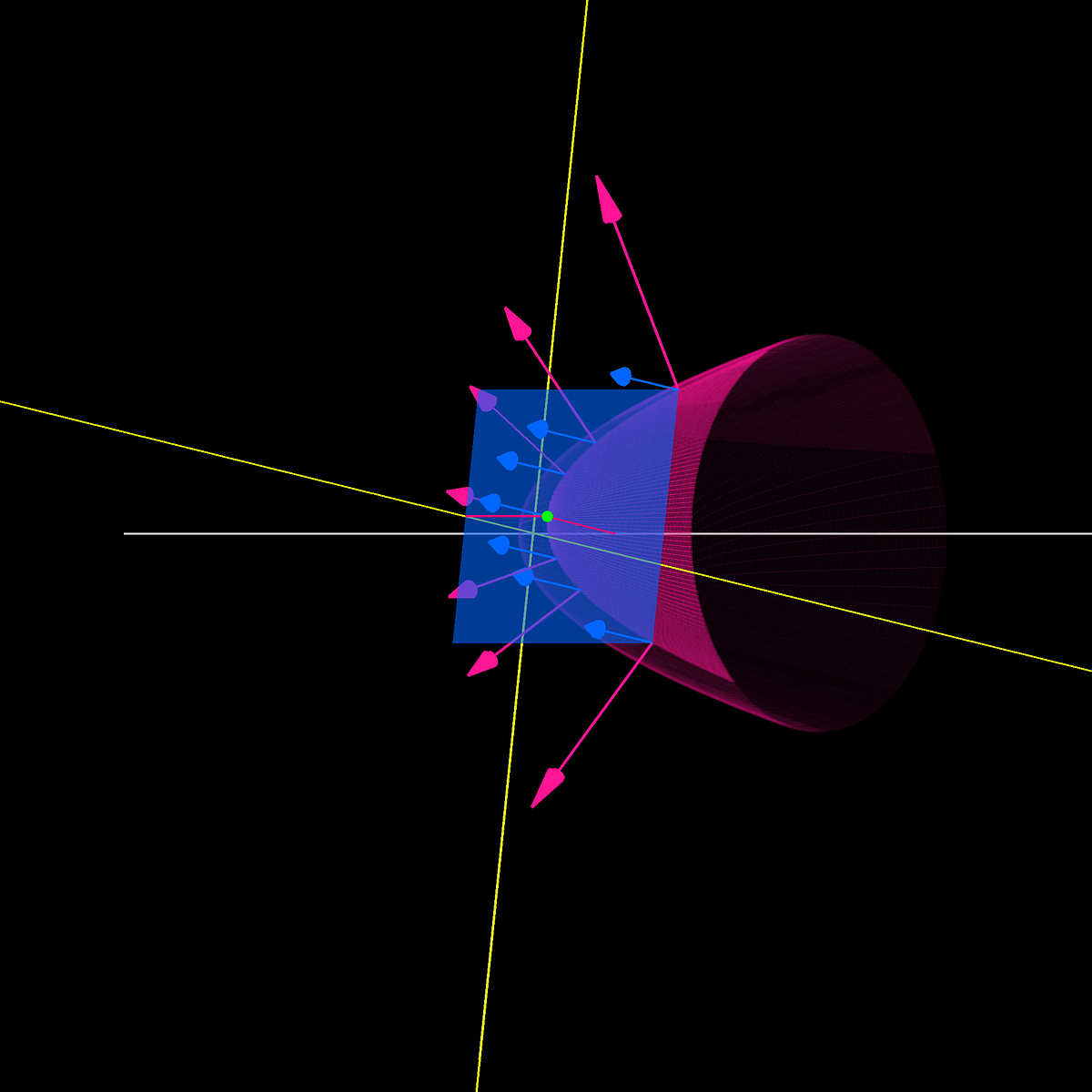
In this story, we’re going to take an aerial tour of optimization with Lagrange multipliers. When do we need them? Whenever we have an…
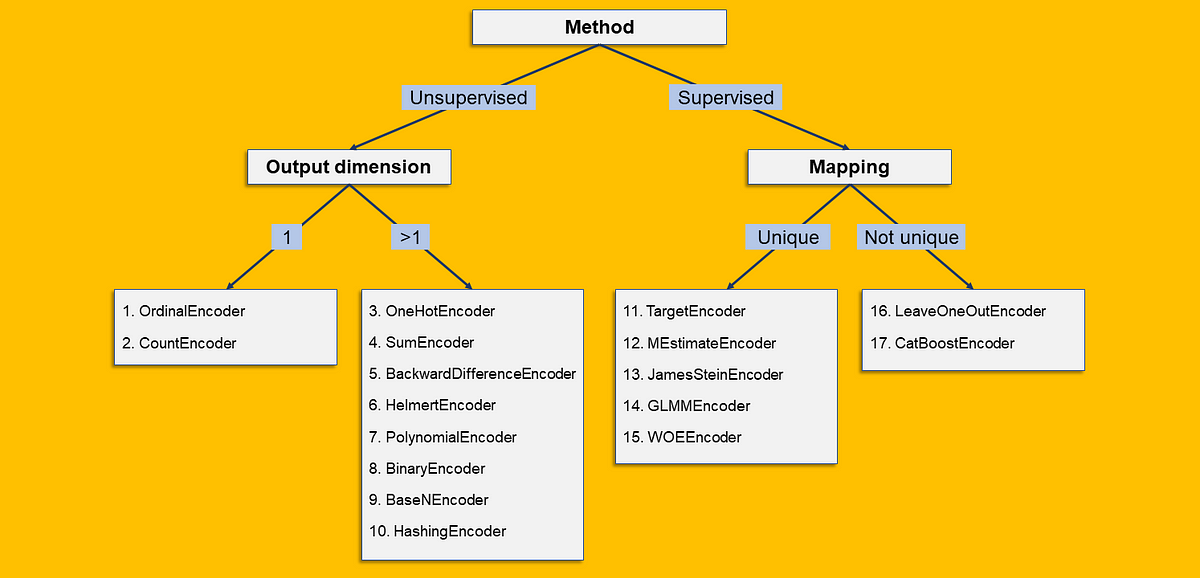
All the encodings that are worth knowing — from OrdinalEncoder to CatBoostEncoder — explained and coded from scratch in Python
Learn PSO algorithm as a bedtime story with GIFs and python code
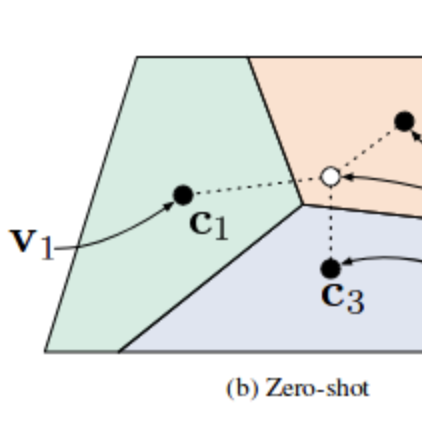
**Zero-shot learning (ZSL)** is a model's ability to detect classes never seen during training. The condition is that the classes are not known during supervised learning. Earlier work in zero-shot learning use attributes in a two-step approach to infer unknown classes. In the computer vision context, more recent advances learn mappings from image feature space to semantic space. Other approaches learn non-linear multimodal embeddings. In the modern NLP context, language models can be evaluated on downstream tasks without fine tuning. Benchmark datasets for zero-shot learning include [aPY](/dataset/apy), [AwA](/dataset/awa2-1), and [CUB](/dataset/cub-200-2011), among others. ( Image credit: [Prototypical Networks for Few shot Learning in PyTorch ](https://github.com/orobix/Prototypical-Networks-for-Few-shot-Learning-PyTorch) ) Further readings: - [Zero-Shot Learning -- A Comprehensive Evaluation of the Good, the Bad and the Ugly](https://paperswithcode.com/paper/zero-shot-learning-a-comprehensive-evaluation) - [Zero-Shot Learning in Modern NLP](https://joeddav.github.io/blog/2020/05/29/ZSL.html) - [Zero-Shot Learning for Text Classification](https://amitness.com/2020/05/zero-shot-text-classification/)
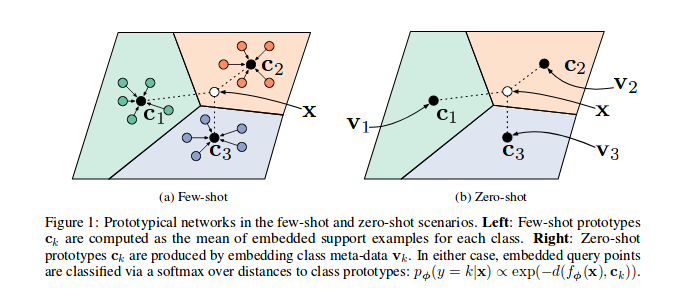
**Few-Shot Learning** is an example of meta-learning, where a learner is trained on several related tasks, during the meta-training phase, so that it can generalize well to unseen (but related) tasks with just few examples, during the meta-testing phase. An effective approach to the Few-Shot Learning problem is to learn a common representation for various tasks and train task specific classifiers on top of this representation. Source: [Penalty Method for Inversion-Free Deep Bilevel Optimization ](https://arxiv.org/abs/1911.03432)
Quantifying the effects of varying different inputs, applied on a gemstone dataset with over 50K round-cut diamonds
A Step-by-Step Guide to Host your Models!

Part one of a series on how we will measure discrepancies in Airbnb guest acceptance rates using anonymized perceived demographic data.
The sometimes confusing concepts involved in interpreting coronavirus testing

A Log-Normal Distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed.
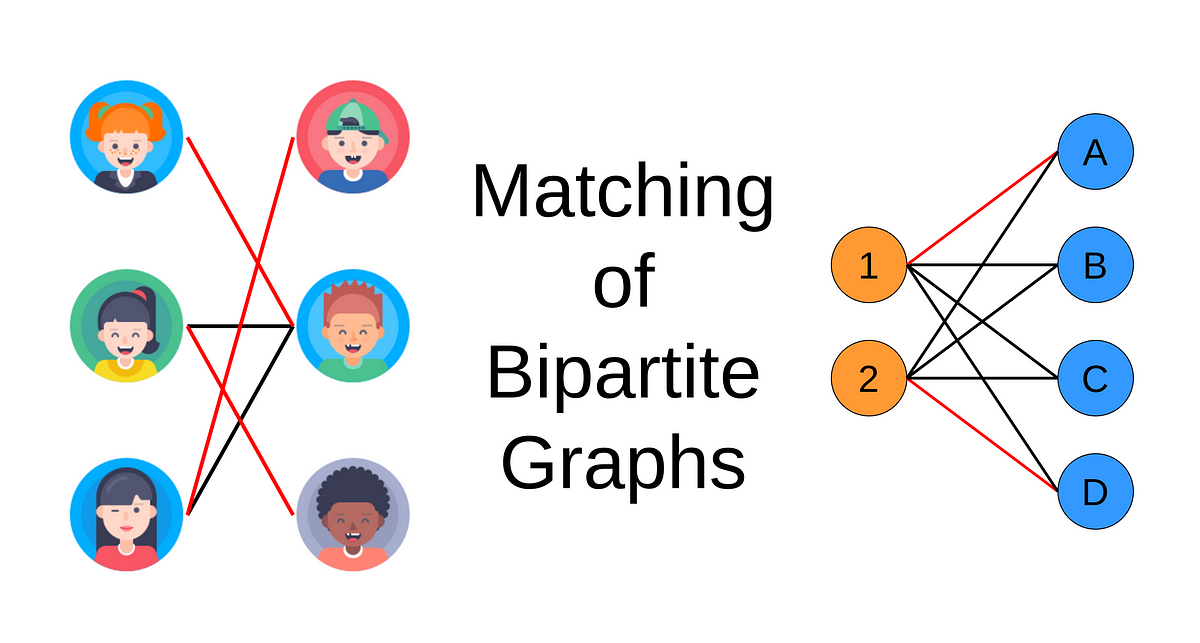
A simple introduction to matching in bipartite graphs with Python code examples
Scientists have developed an Artificial Intelligence (AI) system that recognises hand gestures by combining skin-like electronics with computer vision.
In the Deep Learning (DL) age, more and more people have encountered and used (knowingly or not) random matrices. Most of the time this…
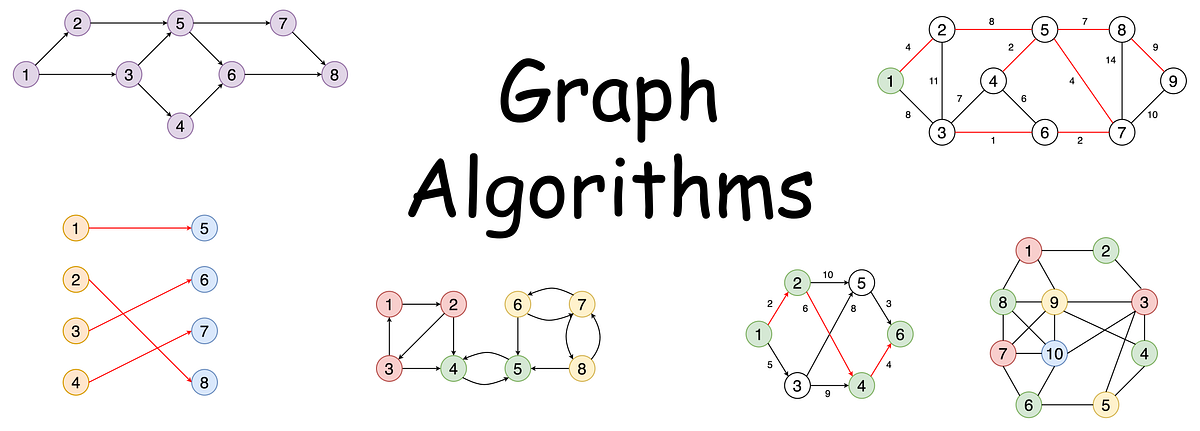
A quick introduction to 10 basic graph algorithms with examples and visualisations

A Complete Pythonic Encoding Tutorial

Learn which of the 9 most prominent automatic speech recognition engines is best for your needs, and how to use it in Python programs.

“Less than one”-shot learning can teach a model to identify more objects than the number of examples it is trained on.
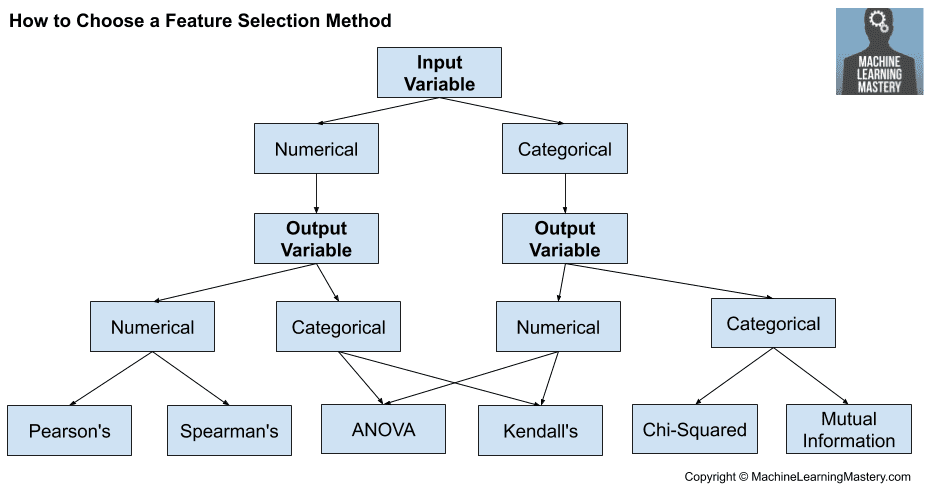
Feature selection is the process of reducing the number of input variables when developing a predictive model. It is desirable to reduce the number of input variables to both reduce the computational cost of modeling and, in some cases, to improve the performance of the model. Statistical-based feature selection methods involve evaluating the relationship between each input variable and the…

In this post, I am going to be talking about some of the most important graph algorithms you should know and how to implement them using Python.

An introduction to Data Cataloging and major tools that data teams can use for data discovery
The Adam optimization algorithm from definition to implementation
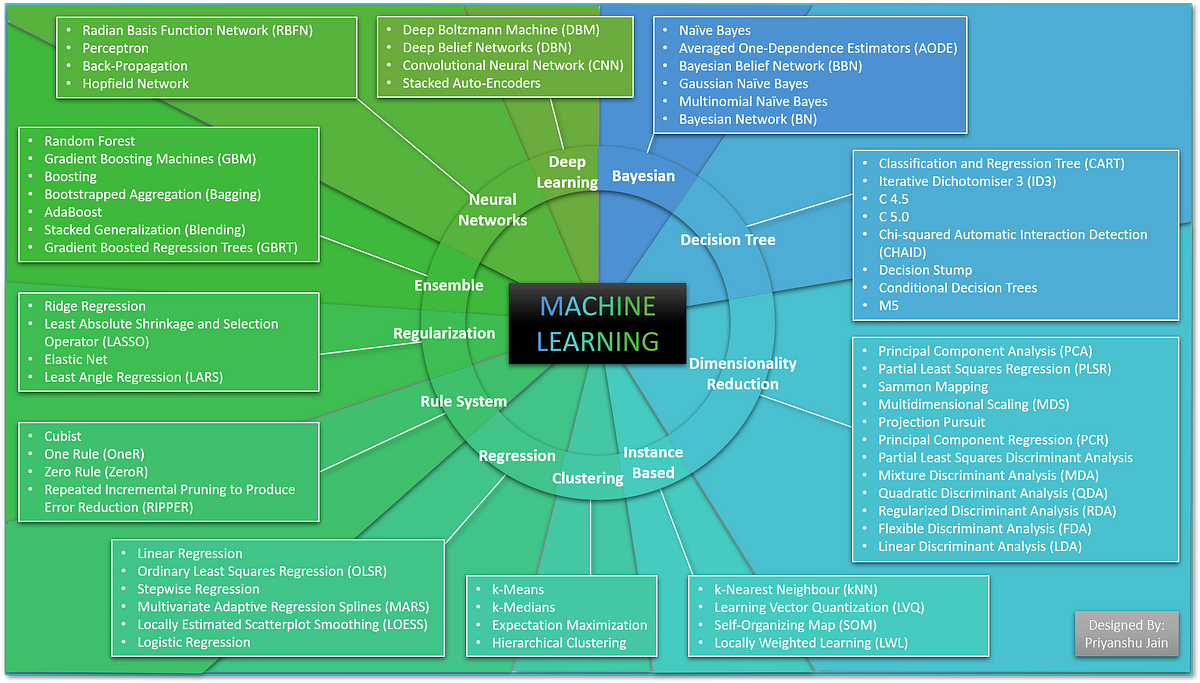
In this article I covered 63 Algorithms of Machine Learning in easy to understand manner for business professionals.

New modeling approach increases accuracy of recommendations by an average of 7%.
Using Facebook faiss library for REALLY fast kNN
Know your SMOTE ways to oversampled your data

A step-by-step guide to apply perspective transformation on images

The startup Realtime Robotics, co-founded by former MIT postdoc George Konidaris, is helping robots solve the motion planning problem by giving them collision avoidance capabilities.

A value is worthless unless it tells you something.

Floating-point formats are not the most glamorous or (frankly) the important consideration when working with deep learning models: if your model isn’t working well, then your floating-point format certainly isn’t going to save you! However, past a certain point of model complexity/model size/training time, your choice of floating-point format can have a significant impact on your model training times and even performance. Here’s how the rest of this post is structured:
Some of our insights from developing a PyTorch framework for training and running deep learning models …

Jamie Robins and I have written a book that provides a cohesive presentation of concepts of, and methods for, causal inference. Much of this material is currently scattered across journals in sever…
I come from the world of MATLAB and numerical computing, where for loops are shorn and vectors are king. During my PhD at UVM, Professor…
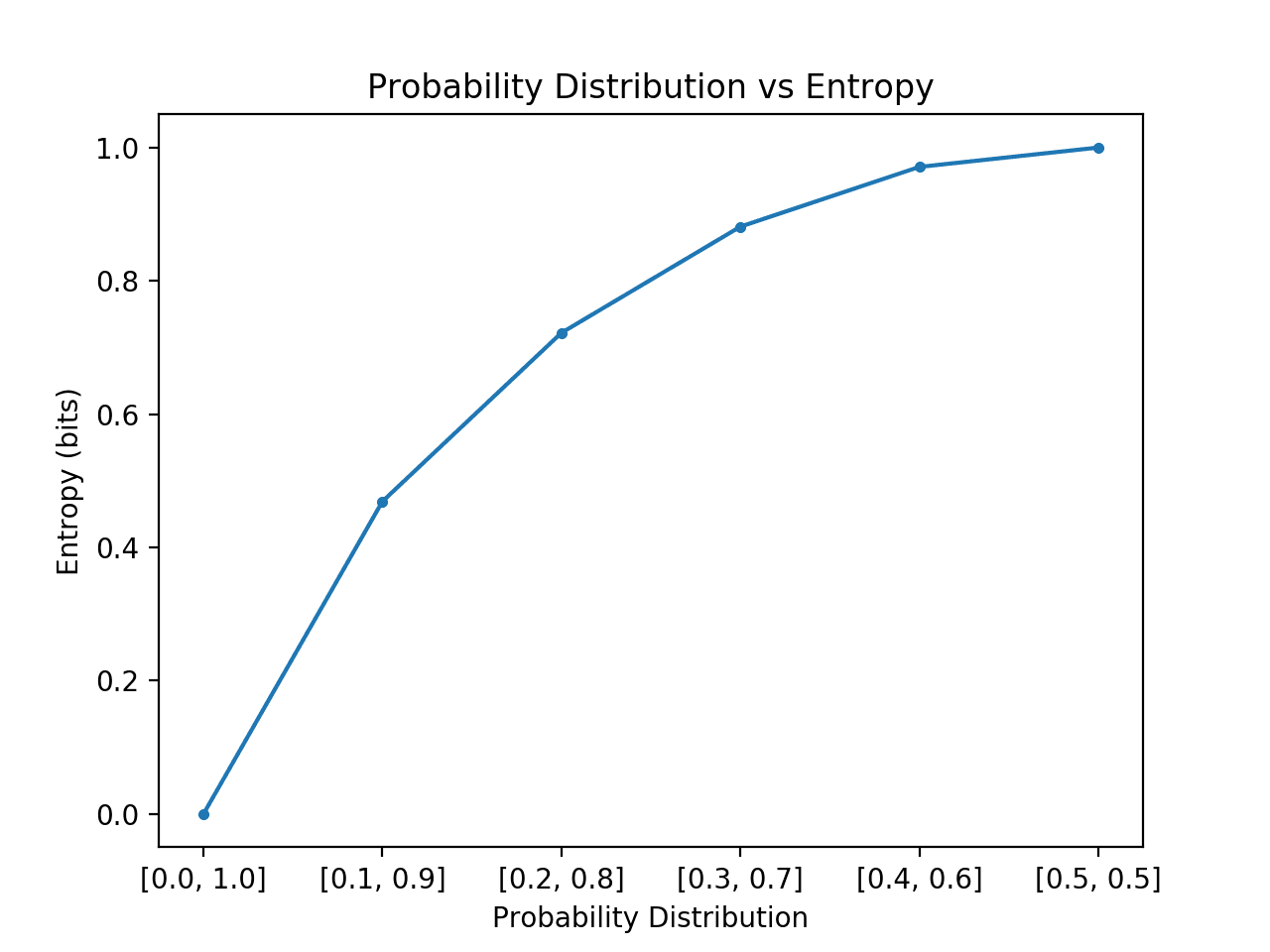
Information theory is a subfield of mathematics concerned with transmitting data across a noisy channel. A cornerstone of information theory is the idea of quantifying how much information there is in a message. More generally, this can be used to quantify the information in an event and a random variable, called entropy, and is calculated using probability. Calculating information and…
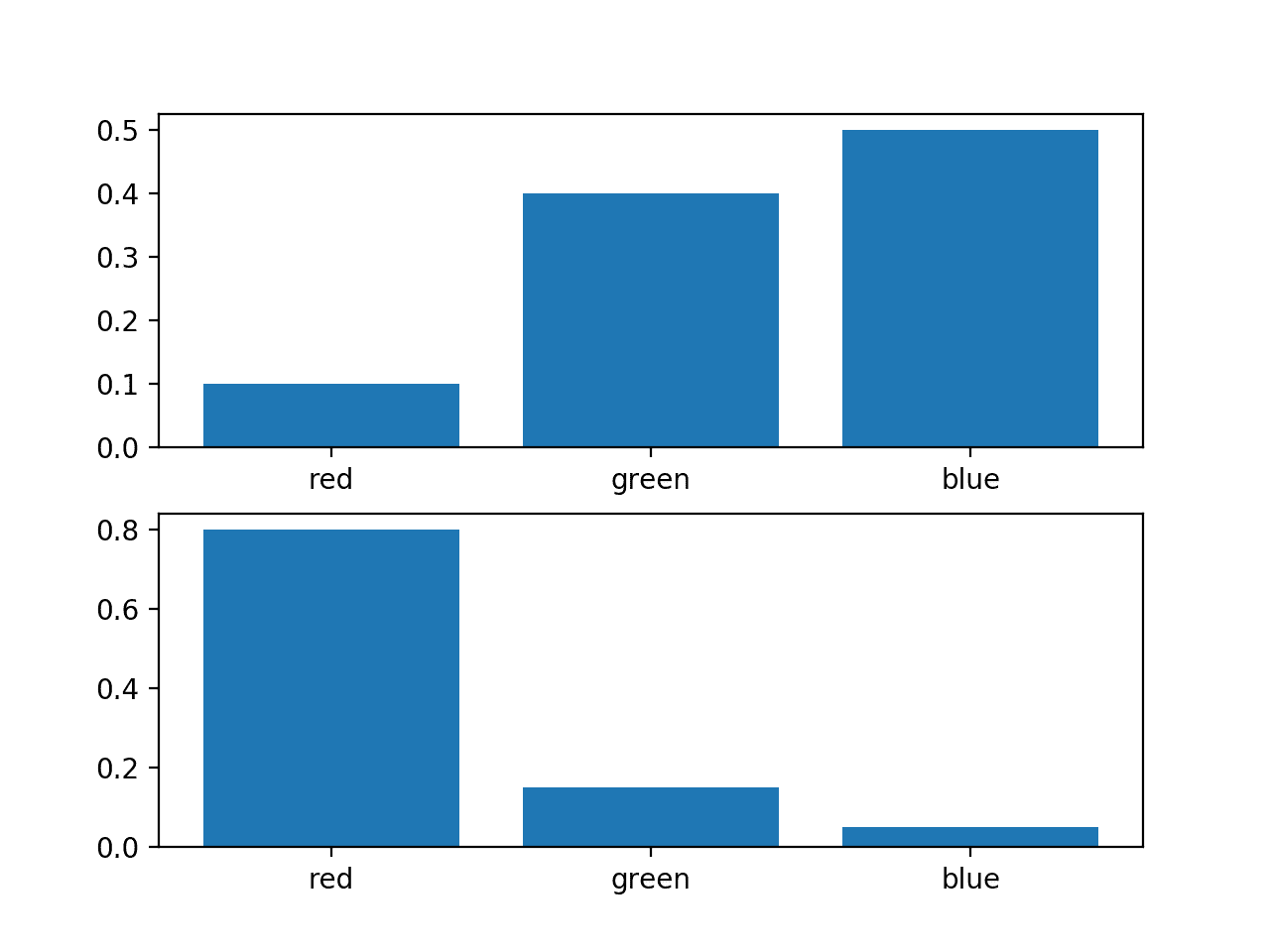
It is often desirable to quantify the difference between probability distributions for a given random variable. This occurs frequently in machine learning, when we may be interested in calculating the difference between an actual and observed probability distribution. This can be achieved using techniques from information theory, such as the Kullback-Leibler Divergence (KL divergence), or relative entropy, and the Jensen-Shannon…
In mathematical statistics, the Kullback–Leibler (KL) divergence (also called relative entropy and I-divergence[1]), denoted D KL ( P ∥ Q ) {\displaystyle D_{\text{KL}}(P\parallel Q)} , is a type of statistical distance: a measure of how one reference probability distribution P is different from a second probability distribution Q.[2][3] Mathematically, it is defined as
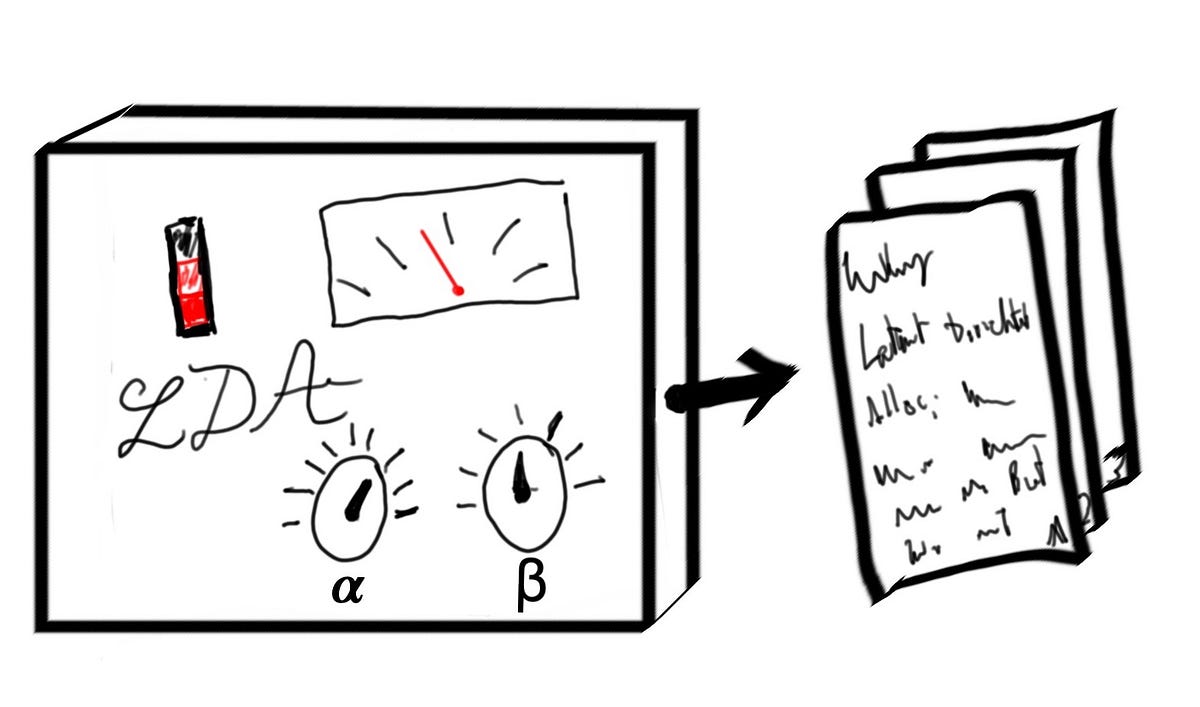
A tour of one of the most popular topic modelling techniques and a guide to implementing and visualising it using pyLDAvis

Tune your Machine Learning models with open-source optimization libraries

In this post, we will be learning a tool to reveal the working mechanism of a black box model. But before we start, let talk about…
This is companion wiki of The Hundred-Page Machine Learning Book by Andriy Burkov. The book that aims at teaching machine learning in a concise yet systematic manner.

Takeaways from our experience building state-of-the-art hyperparameter tuning in Determined AI’s integrated deep learning training…

Understanding why your model is uncertain and how to estimate the level of uncertainty
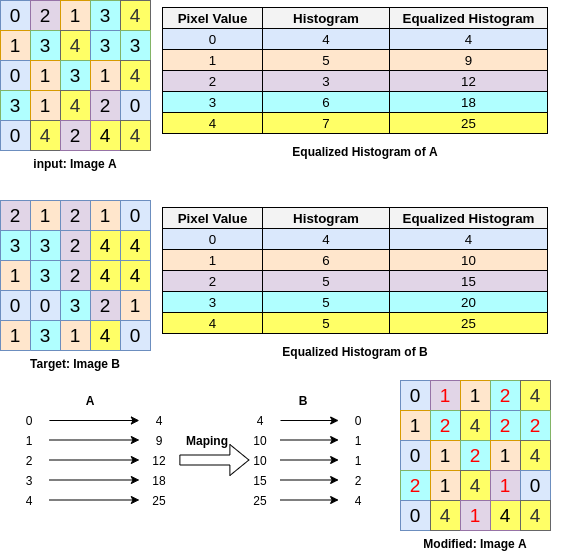
How to generate a histogram for an image, how to equalize the histogram, and finally how to modify your image histogram to be similar to…

HMM is very powerful statistical modeling tool used in speech recognition, handwriting recognition and etc. I wanted to use them, but when…
Deep dive analysis of Silhouette Method to find optimal clusters in k-Means clustering

Identify and remove outliers in each clusters from K-Means clustering

Variation-aware memory verification with brute force Monte Carlo accuracy in much less time.
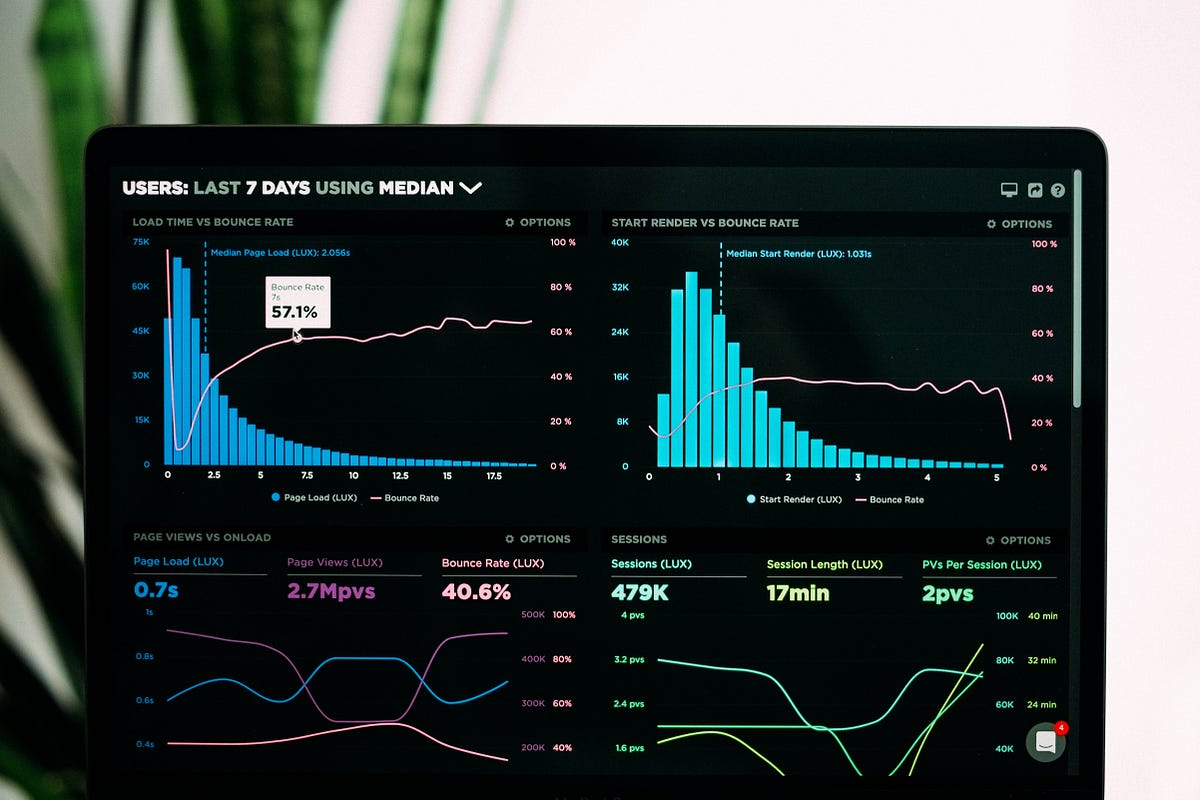
Assumptions, relationships, simulations, and so on
Bite-sized data science on fraud detection
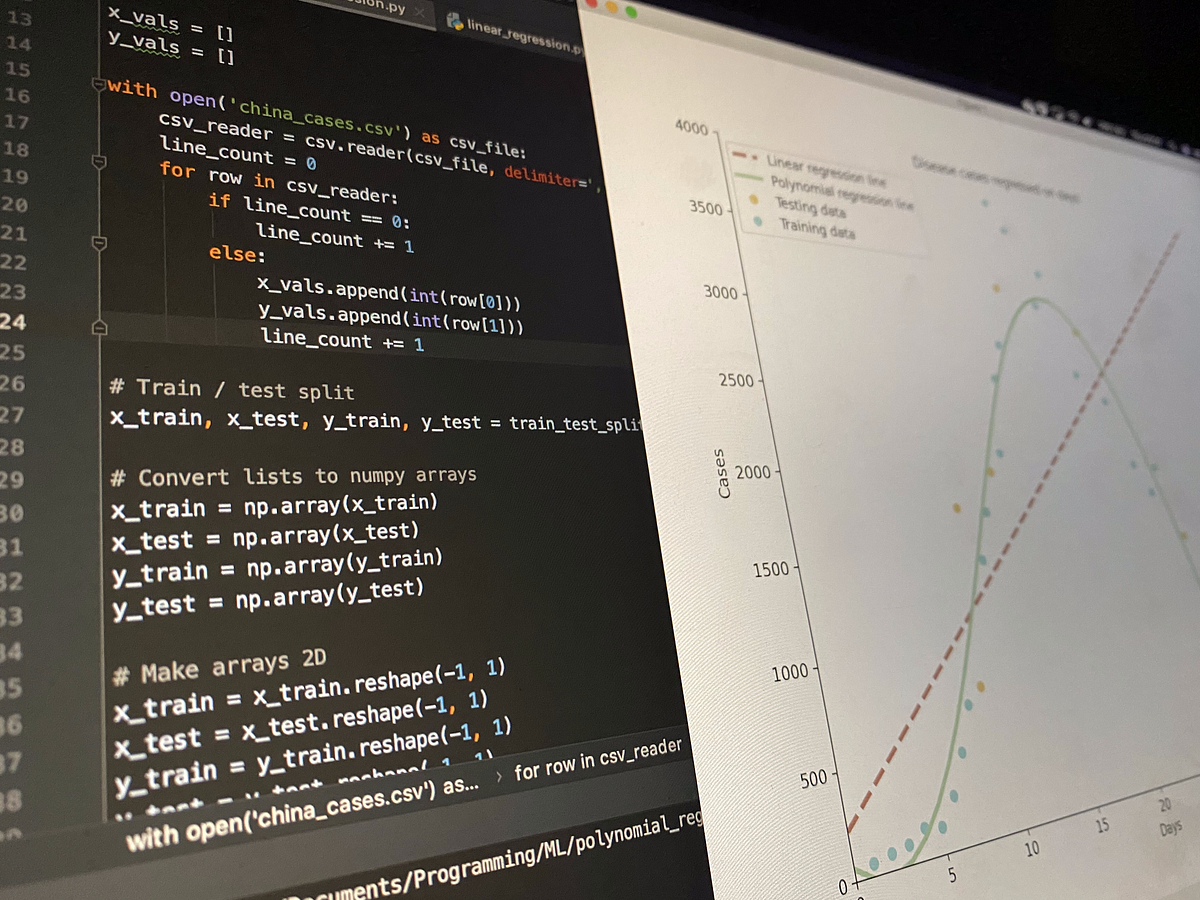
A deep-dive into the theory and application behind this Machine Learning algorithm in Python, by a student
The state-of-the-art in feature importance

Let us try to understand the most widely used loss function — Cross-Entropy.

Roughly Accurate Matrix Profiles Computed in a Fraction of the Time

An intuitive look at the abstract concept
Understand the Ultimate Linear Algebra concept with Geometry

The Intuition Behind the Popular Expectation-Maximization Algorithm with Example Code

Let ‘s go see the differences and analyze step by step the approach which is taken to compute the Sklearn’s TF-IDF

Learn to use non-Gaussian distributions in Gaussian Process models, and variational inference with Gaussian quadrature to compute…
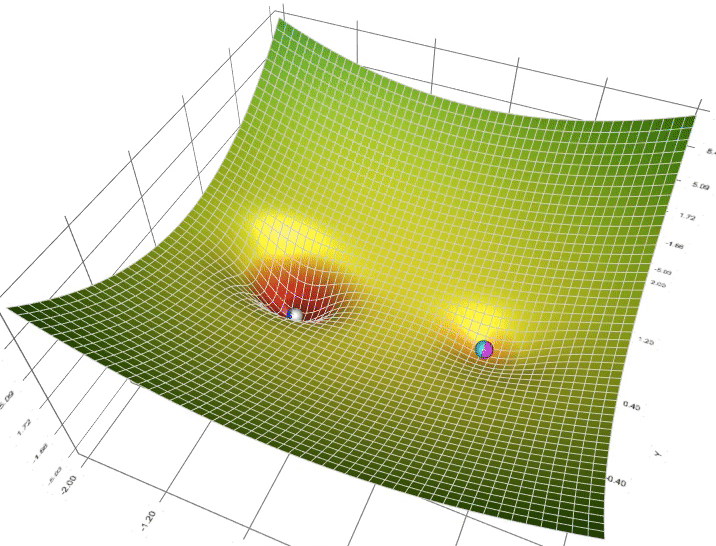
Why can AdaGrad escape saddle point? Why is Adam usually better? In a race down different terrains, which will win?
Dimensionality Reduction Techniques for Hyperspectral Images.
Understanding the mathematic behind SVM + Implementation in Python via scikit-learn
How a simple `pip install eisen` will save days of work and solve (almost) all of your problems.
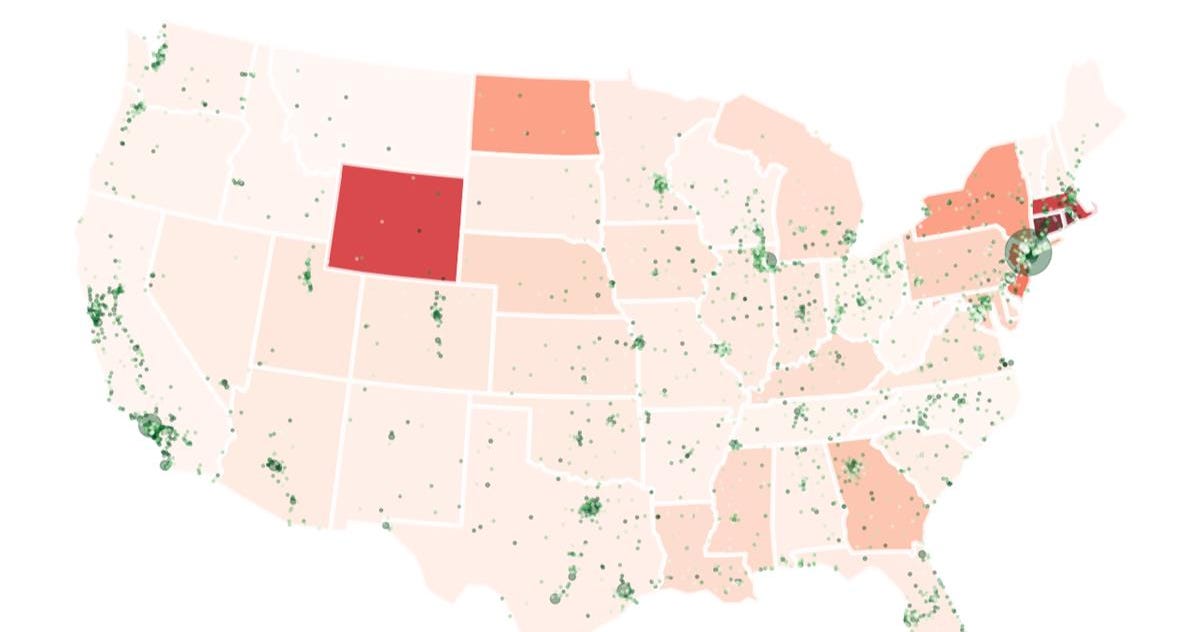
Open source tools and techniques for visualizing data on custom maps

A gentle introduction to federated learning using PyTorch and PySyft with the help of a real life example.
Why obtaining the Amazon Web Services Machine Learning — Specialty (“AWS ML”) certification is one of the best starting points to gaining…
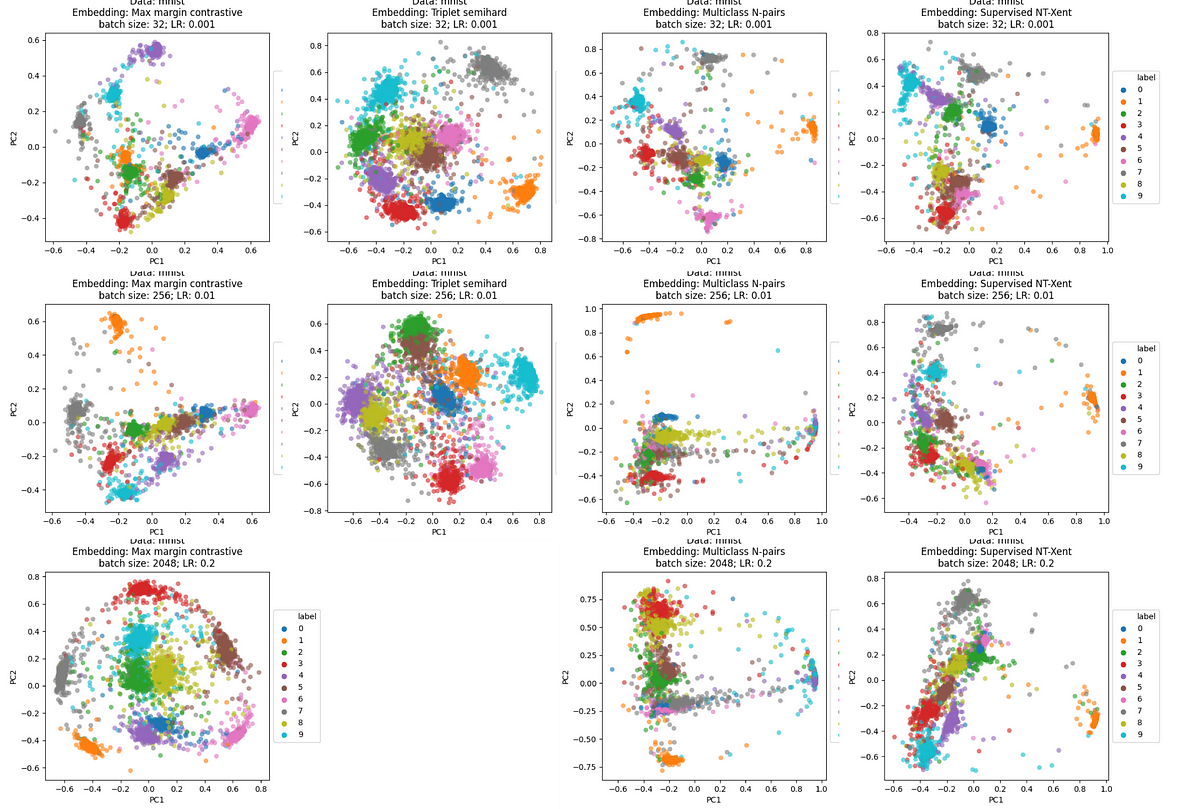
A comprehensive guide to four contrastive loss functions for contrastive learning
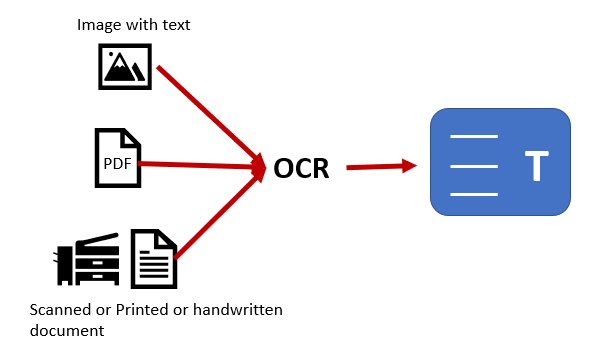
Your first step towards reading text from unstructured data

Hi all, welcome back to another post of my brand new series on Graph Theory named Graph Theory: Go Hero. I undoubtedly recommend the…
Unsupervised techniques to identify changes in the behavior
Check out these 5 cool Python libraries that the author has come across during an NLP project, and which have made their life easier.
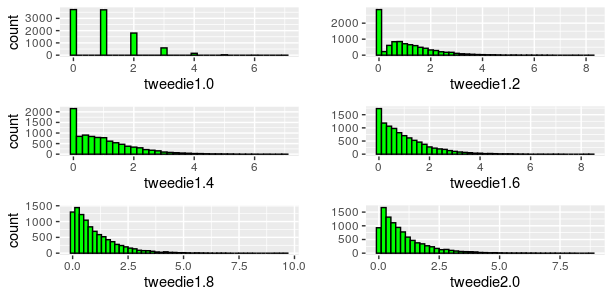
An illustrative guide to estimate the pure premium using Tweedie models in GLMs and Machine Learning
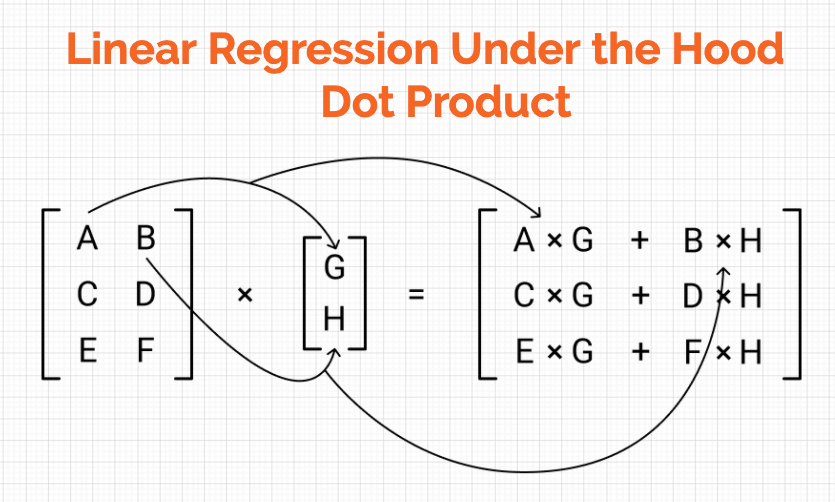
Building up the intuition for how matrices help to solve a system of linear equations and thus regressions problems
Implementation of Isolation forest from scratch for further understanding of the algorithm
Recursive Feature Elimination, or RFE for short, is a popular feature selection algorithm. RFE is popular because it is easy to configure and use and because it is effective at selecting those features (columns) in a training dataset that are more or most relevant in predicting the target variable. There are two important configuration options when using RFE: the choice…

Explaining outlier detection with PyCaret library in python
Isotonic regression is a method for obtaining a monotonic fit for 1-dimensional data. Let’s say we have data such that . (We assume no ties among the ‘s for simplicity.) Informally, isotonic regression looks for such that the ‘s approximate … Continue reading →

Case study of tweets from comments on Indonesia’s biggest media
Overview of deploying a model with the Chef — A Configuration Management Tool

Often, the input features for a predictive modeling task interact in unexpected and often nonlinear ways. These interactions can be identified and modeled by a learning algorithm. Another approach is to engineer new features that expose these interactions and see if they improve model performance. Additionally, transforms like raising input variables to a power can help to better expose the…

New method reduces training time by up to 99%, with no loss in accuracy.
Do Asian currencies move in tandem? What about emerging markets in general? Are commodity currencies like AUD and CAD closely related as…

An overview of the fundamentals behind measuring and comparing machine learning solutions
Amazon researchers describe a machine learning system that plans the movements and paths of up to 1,000 mobile warehouse robots.
DataGene - Identify How Similar TS Datasets Are to One Another (by @firmai) - firmai/datagene

How to create time series datasets with different patterns

How and why we built a custom app for visual debugging of warehouse pick paths.
Qualcomm open sources the AI Model Efficiency Toolkit on GitHub, providing a simple library plugin for AI developers.
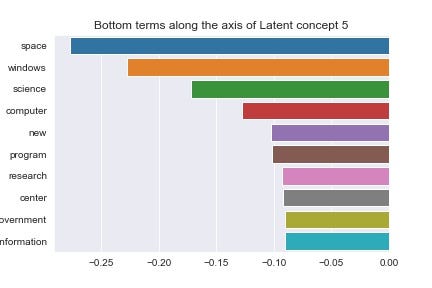
TL;DR — Text data suffers heavily from high-dimensionality. Latent Semantic Analysis (LSA) is a popular, dimensionality-reduction…
Deep dive into spatial autocorrelation and their industry use cases
Graph Theory is the study of graphs which are mathematical structures used to model pairwise relations between objects. These graphs are…

This new Python package accelerates notebook-based machine learning experimentation
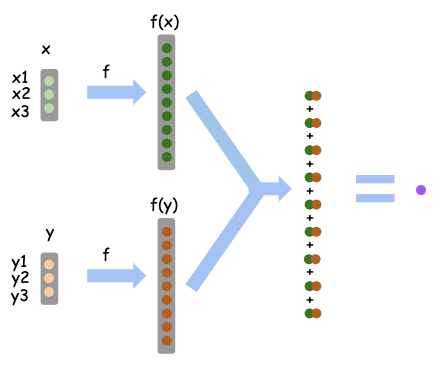
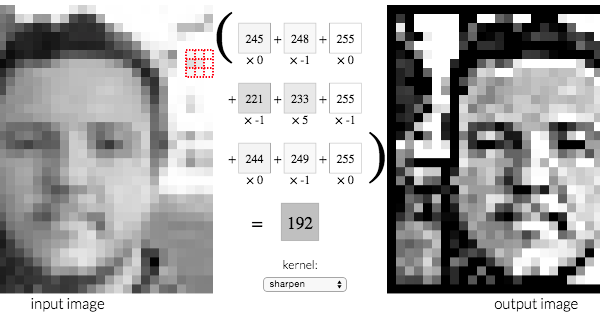
We will walk through a simple example with basic arithmetics to demystify the concept of kernel.
A Comparison of Naive Bayes and Logistic Regression
Using q-learning for sequential decision making and therefore learning to play a simple game.
Pandas is the go-to library for data science. These are the shortcuts I use to do repetitive data science tasks faster and simpler.

From not sweating missing values, to determining feature importance for any estimator, to support for stacking, and a new plotting API, here are 5 new features of the latest release of Scikit-learn which deserve your attention.

I came across Pycaret while I was browsing on a slack for data scientists. It's a versatile library in which you can apply/evaluate/tune…

In this blog, you will get an intuition behind the use of cross-entropy and log-loss in machine learning.
Deploy, scale and manage your machine learning services with Kubernetes and Terraform on GCP.

Learn about SVM or Support Vector Machine, Kernel Trick, Hyperplanes, Lagrange Multipliers using visual examples and code sections.

and how to train and deploy an ML model into production with them.
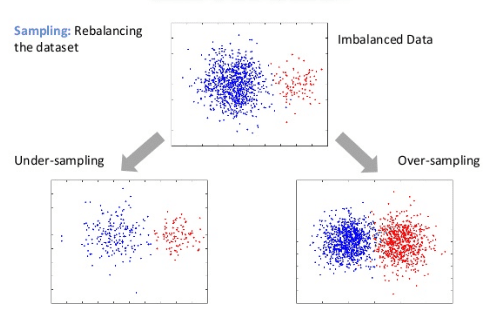
Consider a problem where you are working on a machine learning classification problem. You get an accuracy of 98% and you are very happy. But that happiness doesn’t last long when you look at the confusion matrix and realize that majority class is 98% of the total data and all examples are classified as majority… Read More »Handling imbalanced dataset in supervised learning using family of SMOTE algorithm.
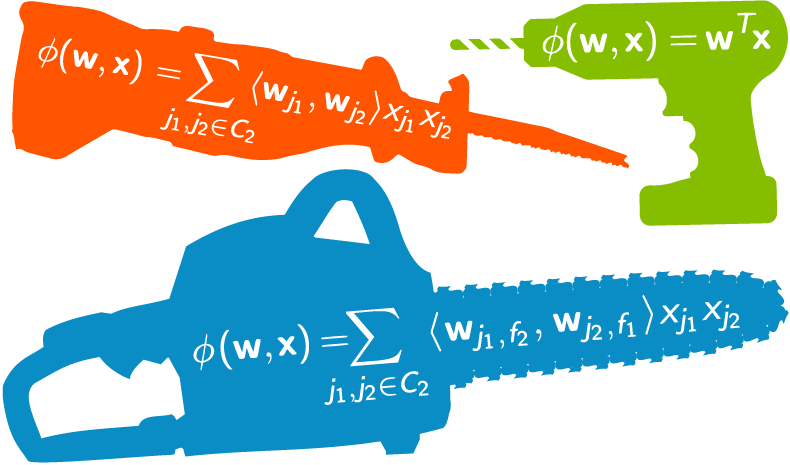
originally posted by the author on Linkedin : Link It is very tempting for data science practitioners to opt for the best known algorithms for a given problem.However It’s not the algorithm alone , which can provide the best solution ; Model built on carefully engineered and selected features can provide far better results. “Any intelligent… Read More »Feature Engineering: Data scientist's Secret Sauce !

A walkthrough of some of Netflix’s interview questions!
Weird data is important. Often in data science, the goal is to discover trends in the data. However, consider doctors looking at images of…

In-depth Interview Q&A from Facebook, Amazon, Apple, Netflix, and Google

This post is the last in our series of 5 blog posts highlighting use case presentations from the 2nd Edition of Seville Machine Learning School (MLSEV). You may also check out the previous posts ab…
Lambdaclass's blog about distributed systems, machine learning, compilers, operating systems, security and cryptography.

A detailed step-by-step guide to build a Lane Line Detection algorithm in OpenCV.
Why do we need Stochastic, Batch, and Mini Batch Gradient Descent when implementing Deep Neural Networks?

Introduction on Stacked Auto-encoder and Technical Walk-through on Model Creation using Pytorch
Bringing Neural Architecture into Recommendations
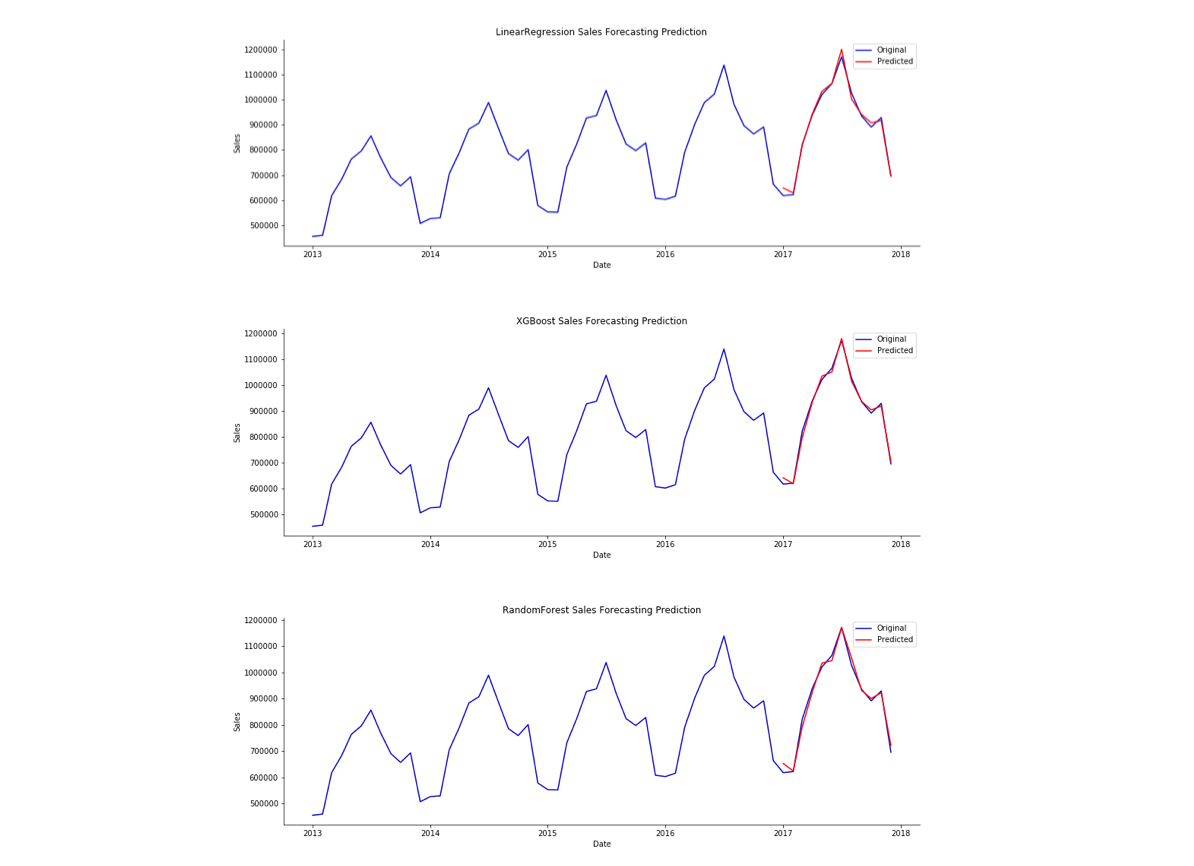
Comparing Linear Regression, Random Forest Regression, XGBoost, LSTMs, and ARIMA Time Series Forecasting
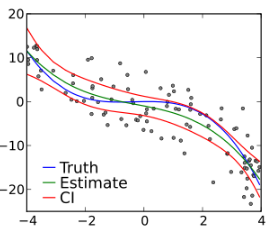
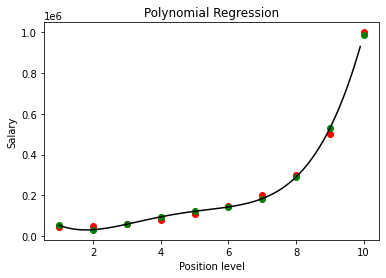
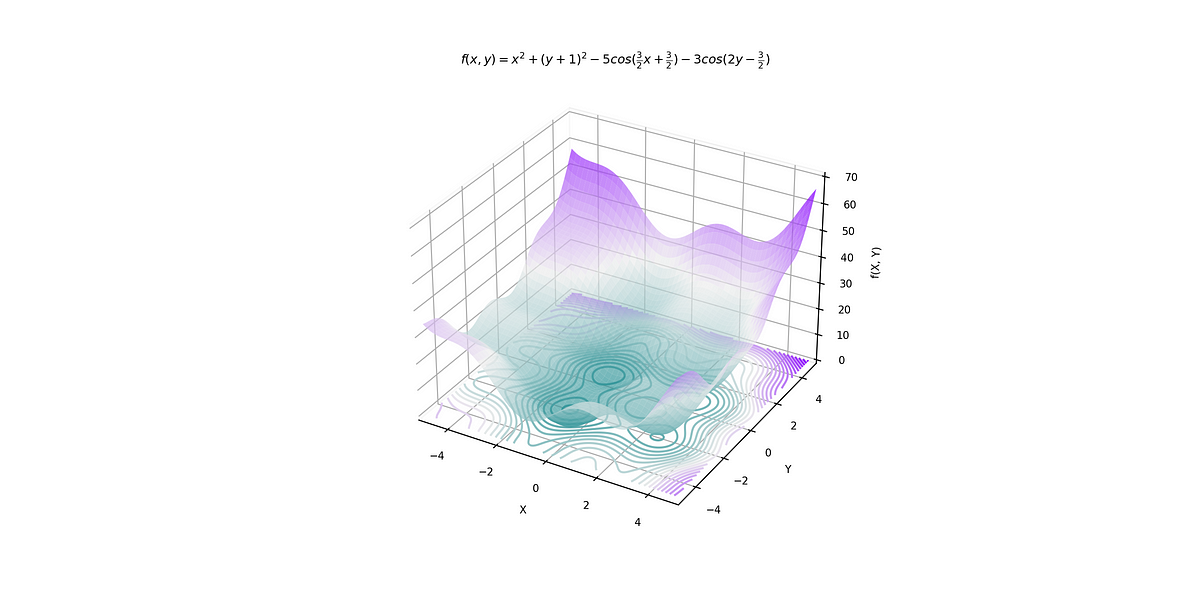
In this article, we show that the issue with polynomial regression is not over-fitting, but numerical precision. Even if done right, numerical precision still remains an insurmountable challenge. We focus here on step-wise polynomial regression, which is supposed to be more stable than the traditional model. In step-wise regression, we estimate one coefficient at a… Read More »Deep Dive into Polynomial Regression and Overfitting
In this piece, I attempt to explain the mathematical reasoning behind this ‘complex’ name.

Plotting heatmaps, contour plots, and 3D plots with Python

Are you not able to load your NumPy data into memory? Does your model have to wait for data to be loaded after each epoch? Is your Keras…
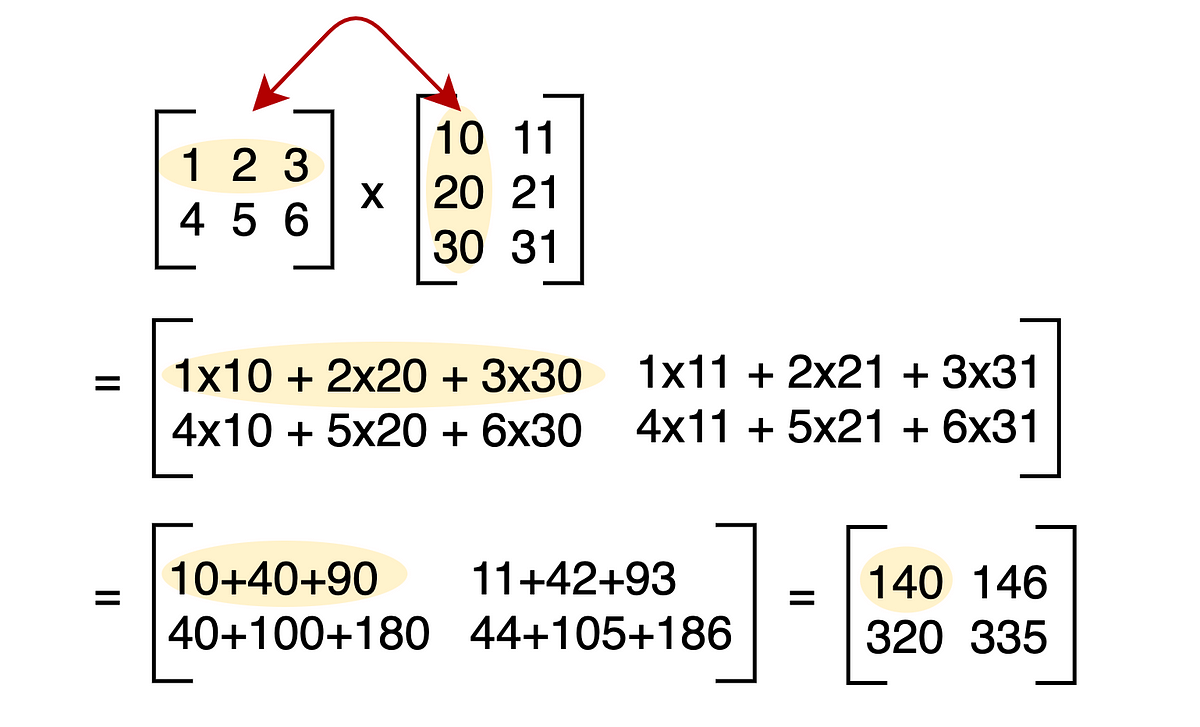
Learn matrix multiplication for machine learning by following along with Python examples
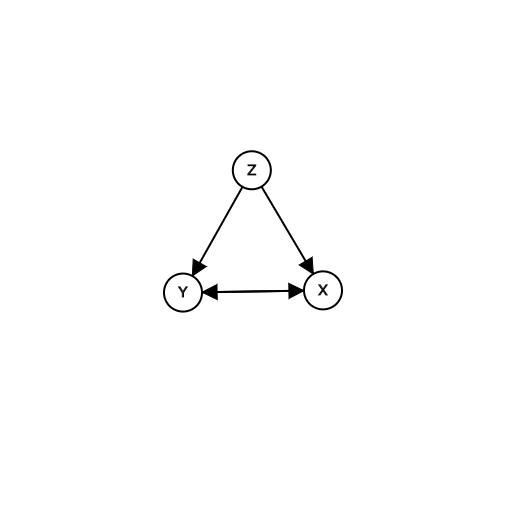
Finding relationships between different variables/ features in a dataset during a data analysis task is one of the key and fundemental…
torchlayers aims to do what Keras did for TensorFlow, providing a higher-level model-building API and some handy defaults and add-ons useful for crafting PyTorch neural networks.

How does pivot work? What is the main pandas building block? And more …
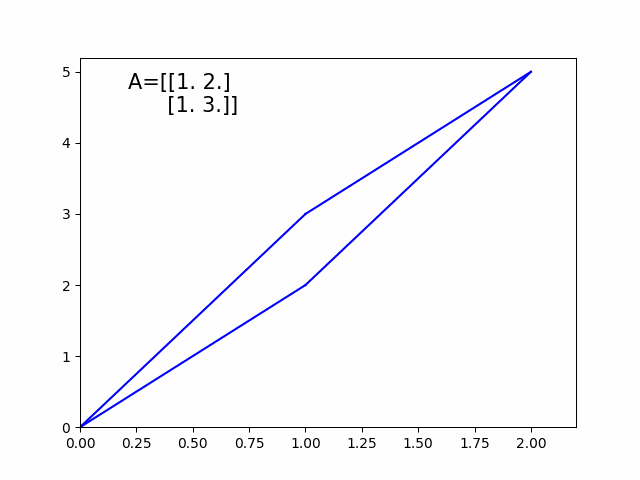
A comprehensive but simple guide which focus more on the idea behind the formula rather than the math itself — start building the block…
It’s not a silver bullet metric to classification problems

An intuitive explanation of t-SNE algorithm and why it’s so useful in practice.
The determinant is related to the volume of a parallelepiped spanned by the vectors in a matrix lets see how.

This guide will show in detail how item based recommendation system works and how to implement it in real work environment.

An Explanation and Implementation of Matrix Factorization

I’m not going to bury the lede: Most machine learning benchmarks are bad. And not just kinda-sorta nit-picky bad, but catastrophically and fundamentally flawed. TL;DR: Please, for the love of sta…
A complete guide on using the most cited clustering algorithm effectively
https://github.com/sepandhaghighi/pycm https://www.pycm.ir custom_rounder function added #279 complement function added sparse_matrix attribute added…

Which boosting algorithm will reign supreme in this head-to-head competition?

This article explains the ID3 Algorithm, in details with calculations, which is one of the many Algorithms used to build Decision Trees.
In this post, we will see several basic optimisation algorithms that you can use in various data science problems.

Why and How to use with examples of Keras/XGBoost
Imagine having your Friends Working with your Local Jupyter Notebook in a Remote Machine
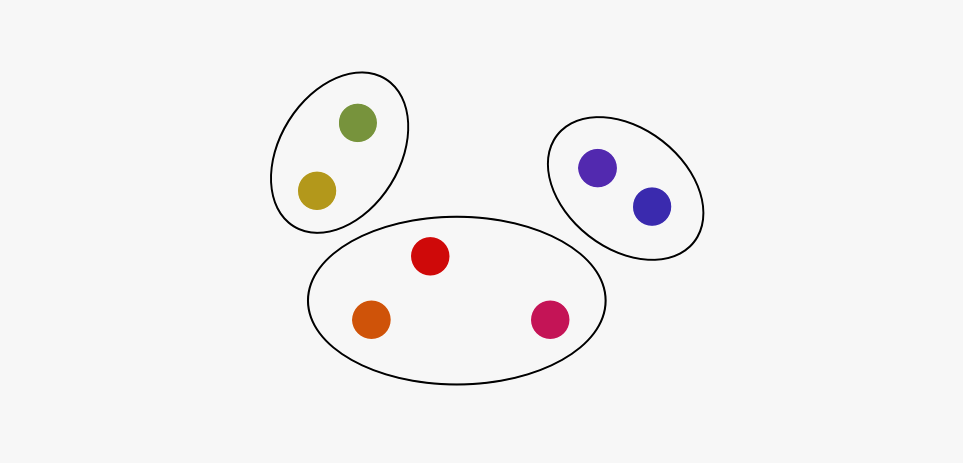
All you need to know about k-means, brown clustering, tf-idf, topic models and LDA.
:extract_focal()/https%3A%2F%2Fs3.amazonaws.com%2Fpocket-syndicated-images%2Farticles%2F1644%2F1568747880_GettyImages-465645737.jpg)
Networks regulate everything from ant colonies and middle schools to epidemics and the internet. Here’s how they work.
Retail Analytics: Data Science for Retail
Since deep neural networks were developed, they have made huge contributions to everyday lives. Machine learning provides more rational advice than humans are capable of in almost every aspect of...
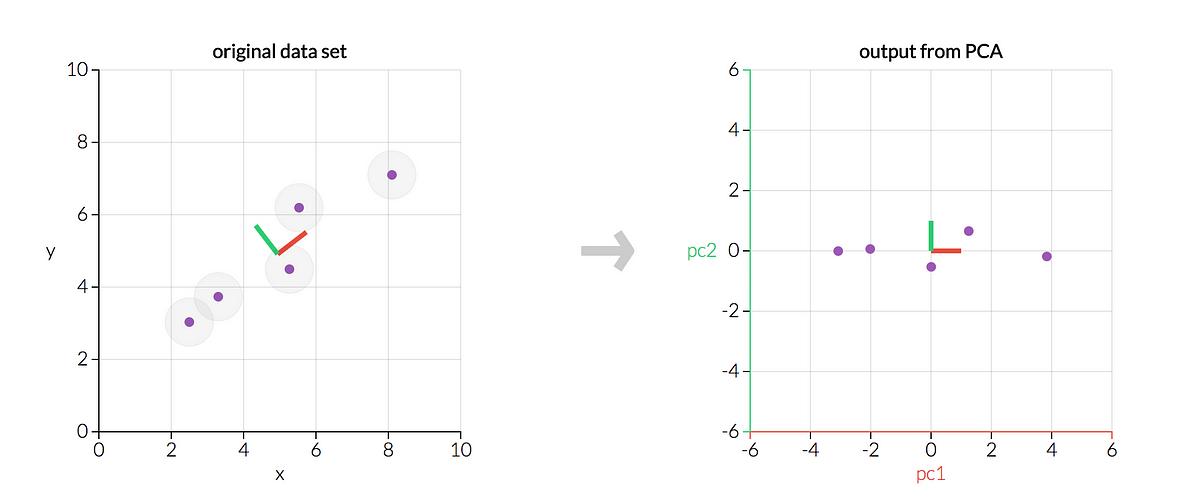
At the beginning of the textbook I used for my graduate stat theory class, the authors (George Casella and Roger Berger) explained in the…
How to classify unlabeled data when all you have is just a sample of positive data
A step by step guide for implementing one of the most trending machine learning algorithm using numpy
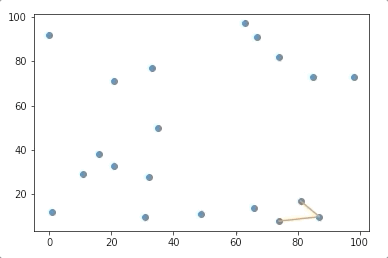
Using residual plots to validate your regression models

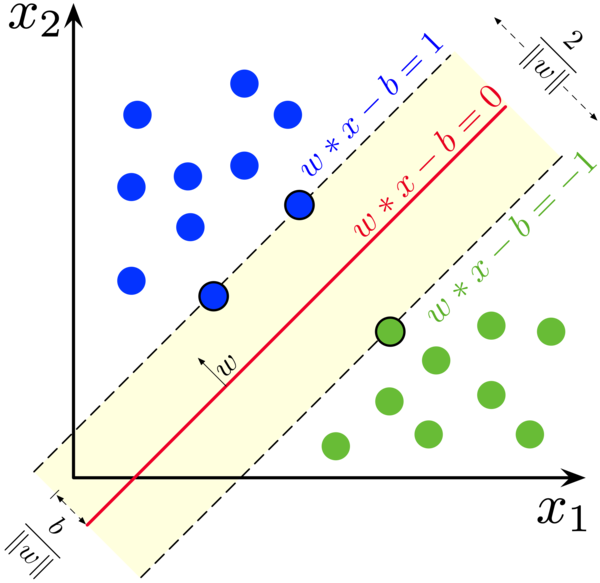
Using Support Vector Machines (SVMs) for Regression

Going above and beyond state-of-the-art with confidence!
249 votes, 21 comments. pytorch-optimizer -- collections of ready to use optimization algorithms for PyTorch, includes: AccSGD, AdaBound, AdaMod…
How to Leverage Data Visualization with Wrapping Algorithm

Multi-armed bandits are a simple but very powerful framework for algorithms that make decisions over time under uncertainty. “Introduction to Multi-Armed Bandits” by Alex Slivkins provides an accessible, textbook-like treatment of the subject.

DataRobot MLOps is helping to increase AI value by automating the deployment, optimization, and governance of machine learning applications.
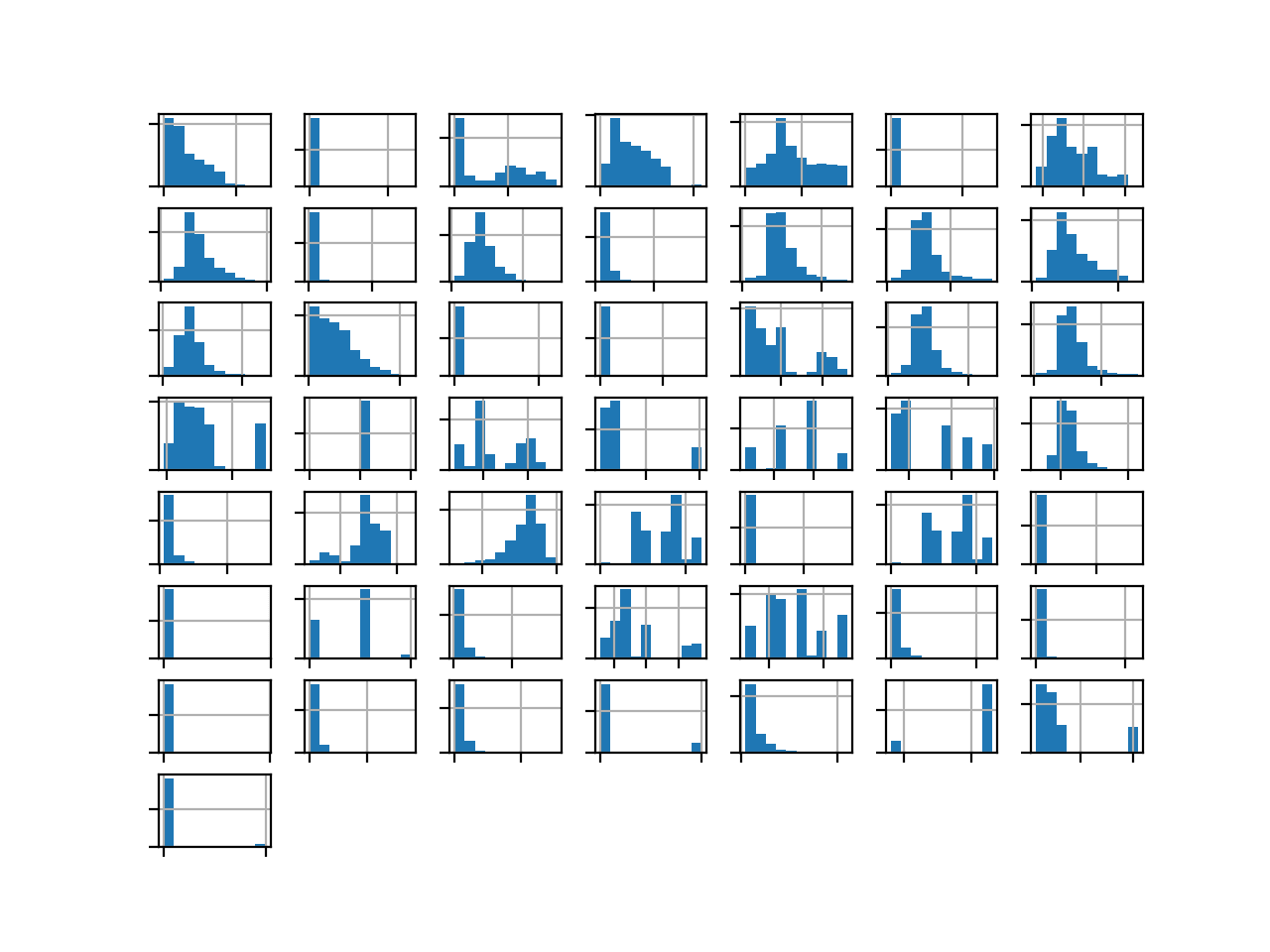
Many imbalanced classification tasks require a skillful model that predicts a crisp class label, where both classes are equally important. An example of an imbalanced classification problem where a class label is required and both classes are equally important is the detection of oil spills or slicks in satellite images. The detection of a spill requires mobilizing an expensive response,…
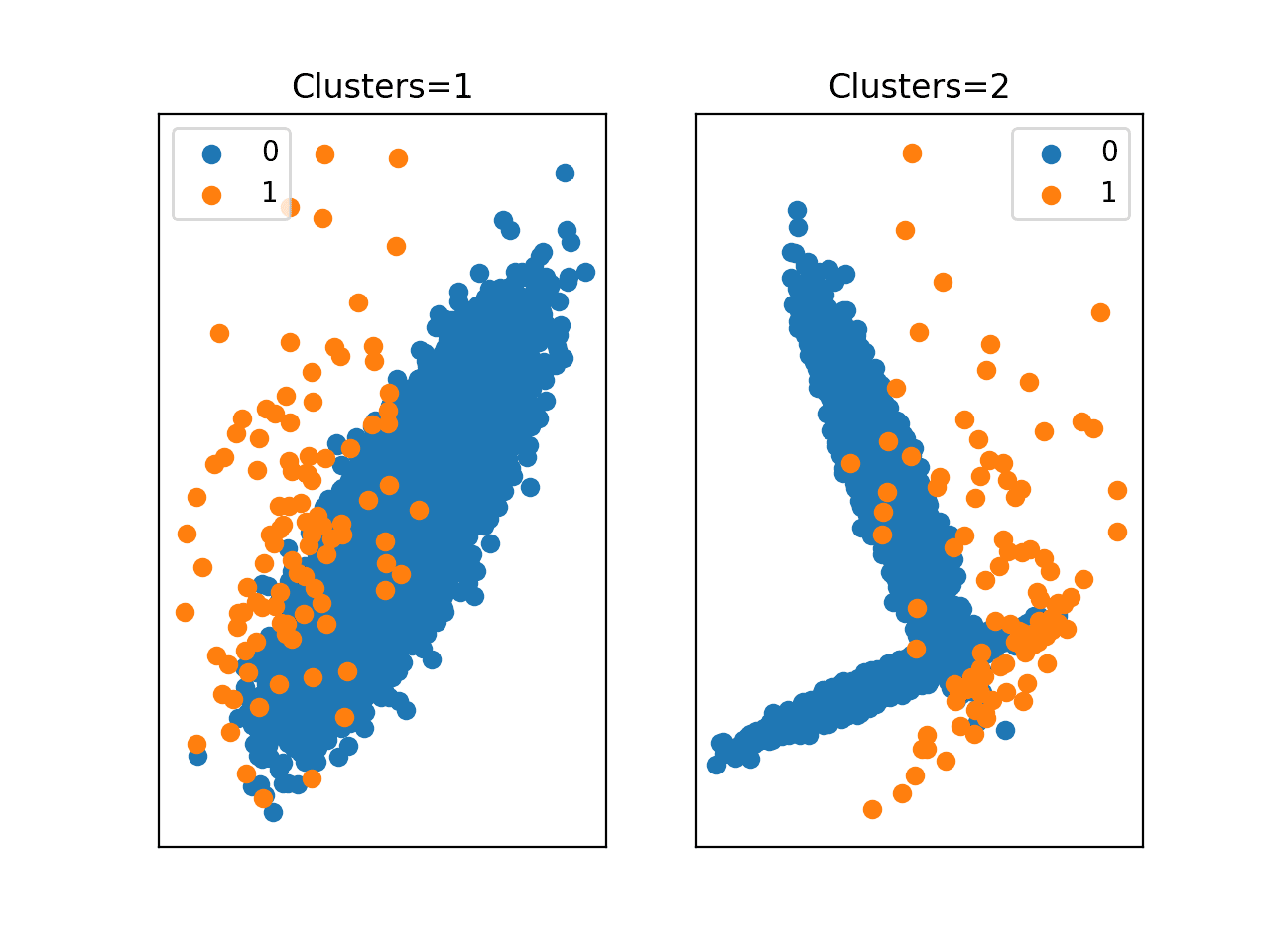
Imbalanced classification is primarily challenging as a predictive modeling task because of the severely skewed class distribution. This is the cause for poor performance with traditional machine learning models and evaluation metrics that assume a balanced class distribution. Nevertheless, there are additional properties of a classification dataset that are not only challenging for predictive modeling but also increase or compound…

By popular demand, I’ve updated this article with the latest tutorials from the past 12 months. Check it out here

Learn about the model that is used in most reinforcement learning problems.
Delivering accurate insights is the core function of any data scientist. Navigating the development road toward this goal can sometimes be tricky, especially when cross-collaboration is required, and these lessons learned from building a search application will help you negotiate the demands between accuracy and speed.

This article will introduce you to Markov Chain Monte Carlo (MCMC) methods, namely Metropolis-Hastings and Bayesian inference, and demonstrate how you can harness them for your next project.

MDP in action: the next step toward solving real-life problems with RL and AI

This is the fourth post in an article series about MIT's Linear Algebra course. In this post I will review lecture four on factorizing a matrix A into a product of a lower-triangular matrix L and an upper-triangular matrix U, or in other words A=LU. The lecture also shows how to find the inverse of matrix product A·B,...
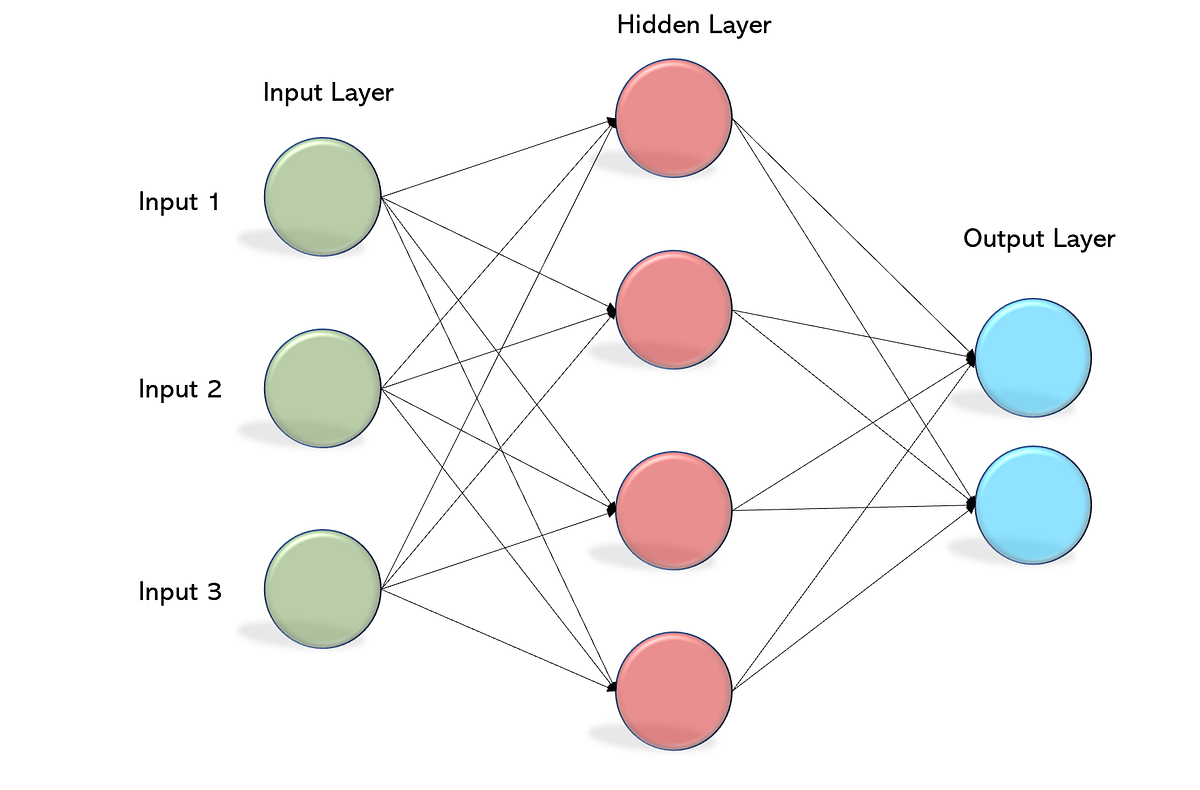
Machine learning is one of the hottest topics in computer science today. And not without a reason: it has helped us do things that couldn’t be done before like image classification, image generation and natural language processing. But all of it boils down to a really simple concept: you give the computer data and the computer then finds patterns in that data. This is called “learning” or “training”, depending on your point of view. These learnt patterns can be extrapolated to make predictions. How? That’s what we are looking at today.
This article is about Market Basket Analysis & the Apriori algorithm that works behind it.
Estimating expected time of arrival (ETA) is crucial to what we do at Lyft. Estimates go directly to riders and drivers using our apps, as…
Which algorithm works best for unbalanced data? Are there any tradeoffs?
Learn the basics of verifying segmentation, analyzing the data, and creating segments in this tutorial. When reviewing survey data, you will typically be handed Likert questions (e.g., on a scale of 1 to 5), and by using a few techniques, you can verify the quality of the survey and start…
This list of lists contains books, notebooks, presentations, cheat sheets, and tutorials covering all aspects of data science, machine learning, deep learning, statistics, math, and more, with most documents featuring Python or R code and numerous illustrations or case studies. All this material is available for free, and consists of content mostly created in 2019… Read More »40+ Modern Tutorials Covering All Aspects of Machine Learning
2.1K votes, 110 comments. 1.3M subscribers in the Python community. The official Python community for Reddit! Stay up to date with the latest news…
Preparing for a job interview can be a full-time job, and Data Science interviews are no different. Here are 121 resources that can help you study and quiz your way to landing your dream data science job.

This post is about explaining the various techniques you can use to handle imbalanced datasets
Learn how to implement adversarial validation that builds a classifier to determine if your data is from the training or testing sets. If you can do this, then your data has issues, and your adversarial validation model can help you diagnose the problem.
An introduction on how to fine-tune Machine and Deep Learning models using techniques such as: Random Search, Automated Hyperparameter Tuning and Artificial Neural Networks Tuning.

Behind every recommender system lies a bevy of metrics.
Scikit-Optimize, or skopt, is a simple and efficient library to minimize (very) expensive and noisy black-box functions. It implements several…

Evolutionary algorithms are an unsupervised learning alternative to neural networks that rely on fitness functions instead of trained nodes for evaluation.
Atlas: A Dataset and Benchmark for E-commerce Clothing Product Categorization - vumaasha/Atlas
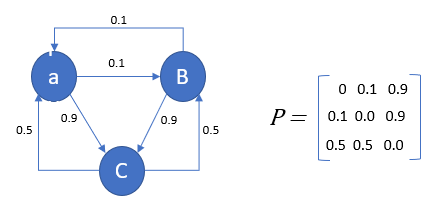
Solving real-world problems with probabilities
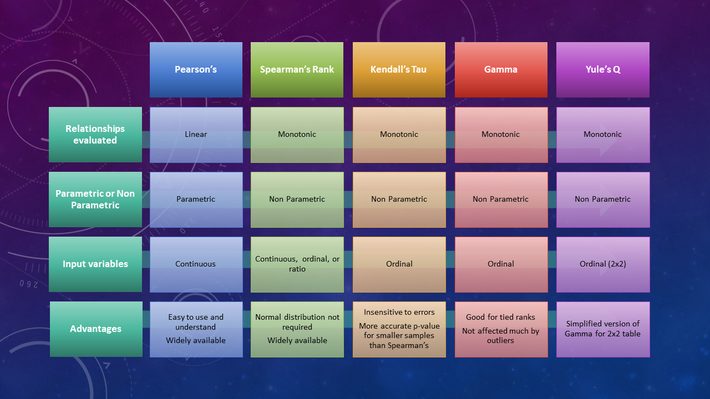
Correlation coefficients enable to you find relationships between a wide variety of data. However, the sheer number of options can be overwhelming. This picture sums up the differences between five of the most popular correlation coefficients. Part two covers several less popular correlation coefficients. Further reading: Gamma & Coefficient & Yule’s Q Kendall’s Tau Pearson… Read More »Correlation Coefficients in One Picture

This post is about various evaluation metrics and how and when to use them.

Over the past few years, deep learning has been taking by storm many industries. From voice recognition to image analysis and synthesis, neural networks have turned out to be very efficient at solv…
I'm planning on sorting ~100,000 images to use as data for a computer vision application. With this much data, shaving a little time off of each…
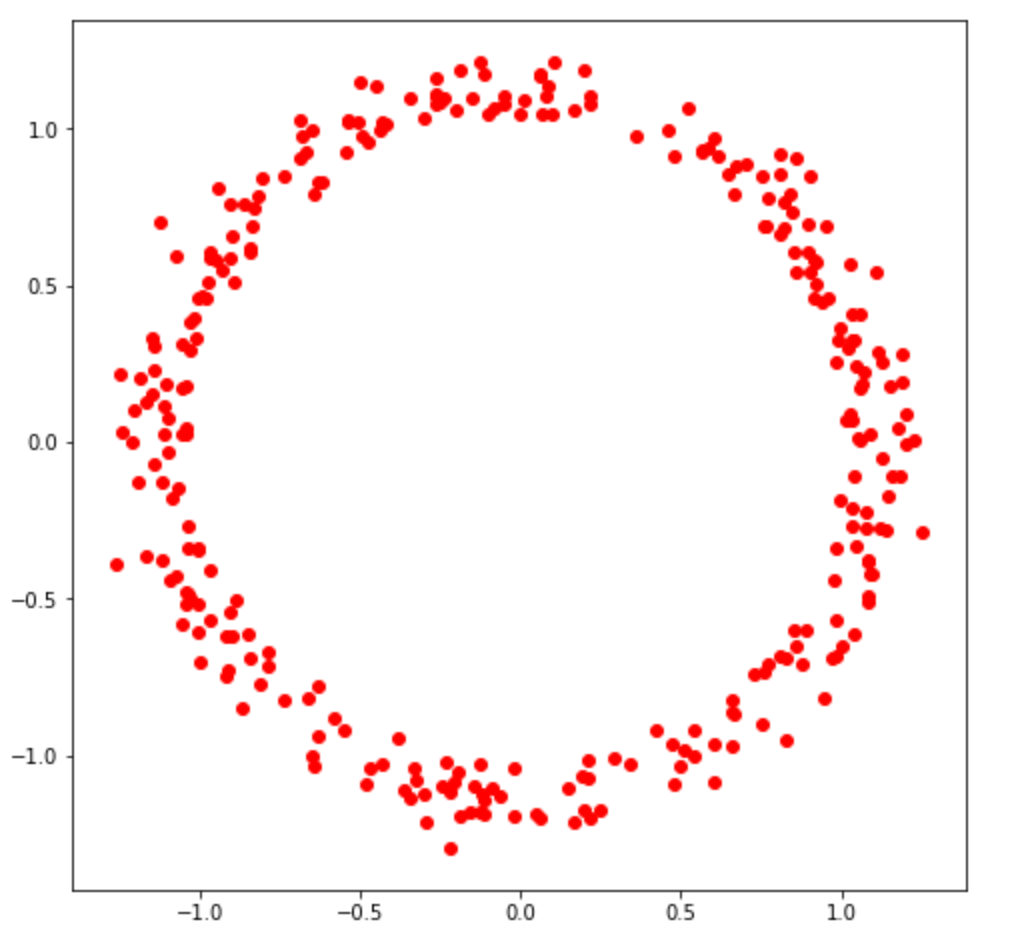
Density estimation is estimating the probability density function of the population from the sample
23 votes, 13 comments. A recent blog post How Exactly UMAP Works provides a different perspective on explaining the UMAP dimensionality reduction…

Is the Rectified Adam (RAdam) optimizer actually better than the standard Adam optimizer? According to my 24 experiments, the answer is no, typically not (but there are cases where you do want to use it instead of Adam).
We show what metric to use for visualizing and determining an optimal number of clusters much better than the usual practice — elbow method.
Data Science Dojo blog features the most recent, and relevant articles about data science, analytics, generative AI, large language models, machine learning, and data visualization.

This post is about various evaluation metrics and how and when to use them.

UMAP is a new dimensionality reduction technique that offers increased speed and better preservation of global structure.

MLCommons ML benchmarks help balance the benefits and risks of AI through quantitative tools that guide responsible AI development.
This guide explores research centered on a variety of advanced loss functions for machine learning models.
The article contains a brief introduction to various concepts related to Hierarchical clustering algorithm.
Each customer has an individualized style map, laying out her feelings about peasant blouses, A-line dresses, or pencil skirts.

Many of you might have heard of the concept “Wisdom of the Crowd”: when many people independently guess some quantity, e.g. the number of marbles in a jar glass, the average of their guesses is often pretty accurate – even though many of the guesses are totally off. The same principle is at work in … Continue reading "Understanding AdaBoost – or how to turn Weakness into Strength"
There is an unreasonable amount of information that can be extracted from what people publicly say on the internet. Learn how to do it.
A curated list of gradient boosting research papers with implementations. - GitHub - benedekrozemberczki/awesome-gradient-boosting-papers: A curated list of gradient boosting research papers with ...
How Instacart uses Machine Learning to spot lost demand in its fulfillment chain

Using ARIMA model, you can forecast a time series using the series past values. In this post, we build an optimal ARIMA model from scratch and extend it to Seasonal ARIMA (SARIMA) and SARIMAX models. You will also see how to build autoarima models in python

A brief rundown of packages and ideas to generate synthetic data for self-driven data science projects and deep diving into machine…

Matthew Conlen provides a short explainer of how kernel density estimation works. Nifty.

This article discusses and compares different approaches of how to compare two text strings.
Although extremely useful for visualizing high-dimensional data, t-SNE plots can sometimes be mysterious or misleading.
The code used to generate the plots for this post can be found here.
Some Tricks and Code for Kaggle and Everyday work. This post is about useful feature engineering methods and tricks that I have learned and end up using often.
In vector calculus, the Jacobian matrix (/dʒəˈkoʊbiən/,[1][2][3] /dʒɪ-, jɪ-/) of a vector-valued function of several variables is the matrix of all its first-order partial derivatives. When this matrix is square, that is, when the function takes the same number of variables as input as the number of vector components of its output, its determinant is referred to as the Jacobian determinant. Both the matrix and (if applicable) the determinant are often referred to simply as the Jacobian in literature.[4] They are named after Carl Gustav Jacob Jacobi.

This post is about some of the most common sampling techniques one can use while working with data.
You can do more data science than you think from the terminal.

Term frequency–inverse document frequency uncovers the specific words that top-ranking pages use to give target keywords context.
A Python Library for Outlier and Anomaly Detection, Integrating Classical and Deep Learning Techniques - yzhao062/pyod
Find out how to use randomness to learn your data by using Noise Contrastive Estimation with this guide that works through the particulars of its implementation.
168 votes, 13 comments. 2.2M subscribers in the datascience community. A space for data science professionals to engage in discussions and debates on…
As data scientists or Machine learning experts, we are faced with tonnes of columns of data to extract insight from, among these features…
Category theory is a relatively new branch of mathematics that has transformed much of pure math research. The technical advance is that category theory provides a framework in which to organize formal systems and by which to translate between them, allowing one to transfer knowledge from one field to another. But this same organizational framework also has many compelling examples outside of pure math. In this course, we will give seven sketches on real-world applications of category theory.

How to turn a collection of small building blocks into a versatile tool for solving regression problems.
Discussions: Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments) Translations: Chinese (Simplified), French, Korean, Portuguese, Russian “There is in all things a pattern that is part of our universe. It has symmetry, elegance, and grace - those qualities you find always in that which the true artist captures. You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. We try to copy these patterns in our lives and our society, seeking the rhythms, the dances, the forms that comfort. Yet, it is possible to see peril in the finding of ultimate perfection. It is clear that the ultimate pattern contains it own fixity. In such perfection, all things move toward death.” ~ Dune (1965) I find the concept of embeddings to be one of the most fascinating ideas in machine learning. If you’ve ever used Siri, Google Assistant, Alexa, Google Translate, or even smartphone keyboard with next-word prediction, then chances are you’ve benefitted from this idea that has become central to Natural Language Processing models. There has been quite a development over the last couple of decades in using embeddings for neural models (Recent developments include contextualized word embeddings leading to cutting-edge models like BERT and GPT2). Word2vec is a method to efficiently create word embeddings and has been around since 2013. But in addition to its utility as a word-embedding method, some of its concepts have been shown to be effective in creating recommendation engines and making sense of sequential data even in commercial, non-language tasks. Companies like Airbnb, Alibaba, Spotify, and Anghami have all benefitted from carving out this brilliant piece of machinery from the world of NLP and using it in production to empower a new breed of recommendation engines. In this post, we’ll go over the concept of embedding, and the mechanics of generating embeddings with word2vec. But let’s start with an example to get familiar with using vectors to represent things. Did you know that a list of five numbers (a vector) can represent so much about your personality?
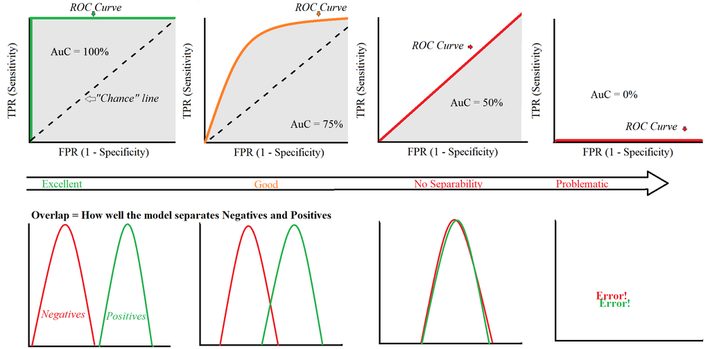
With a ROC curve, you’re trying to find a good model that optimizes the trade off between the False Positive Rate (FPR) and True Positive Rate (TPR). What counts here is how much area is under the curve (Area under the Curve = AuC). The ideal curve in the left image fills in 100%, which means… Read More »ROC Curve Explained in One Picture
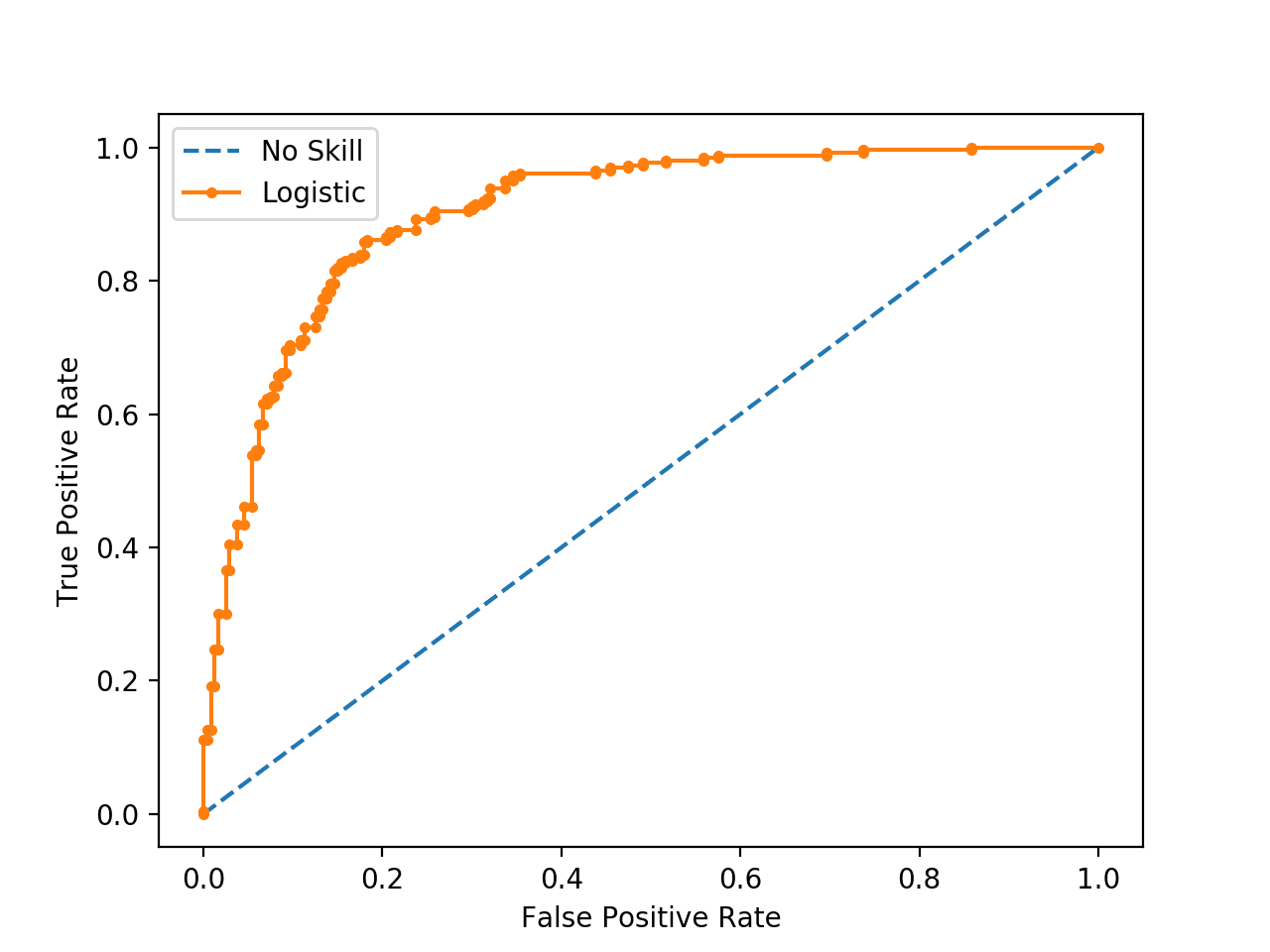
It can be more flexible to predict probabilities of an observation belonging to each class in a classification problem rather than predicting classes directly. This flexibility comes from the way that probabilities may be interpreted using different thresholds that allow the operator of the model to trade-off concerns in the errors made by the model, such as the number of…
A while back, there was a discussion comparing the performance of using the hashbrown crate (based on Google’s SwissTable implementation1) in the Rust compiler. In the last RustFest, Amanieu was experimenting on integrating his crate into stdlib, which turned out to have some really promising results. As a result, it’s being planned to move the crate into stdlib. I insist on watching this talk when you have some free time! ↩
There are many techniques to detect and optionally remove outliers from a dataset. In this blog post, we show an implementation in KNIME Analytics Platform of four of the most frequently used - traditional and novel - techniques for outlier detection.
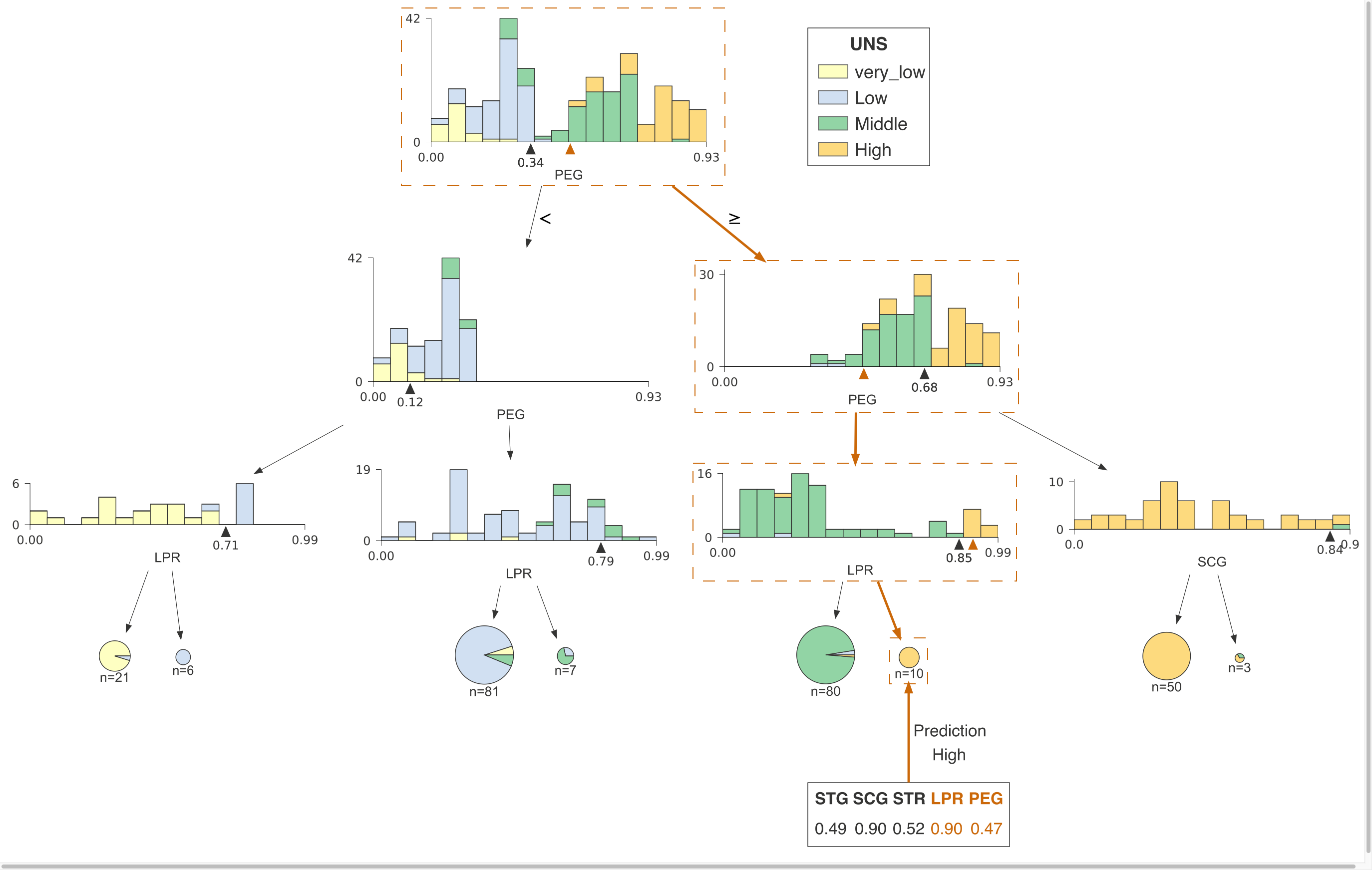
Decision trees are the fundamental building block of gradient boosting machines and Random Forests(tm), probably the two most popular machine learning models for structured data. Visualizing decision trees is a tremendous aid when learning how these models work and when interpreting models. Unfortunately, current visualization packages are rudimentary and not immediately helpful to the novice. For example, we couldn't find a library that visualizes how decision nodes split up the feature space. So, we've created a general package (part of the animl library) for scikit-learn decision tree visualization and model interpretation.
Having the right assortment of shipping boxes in the fulfillment warehouse to pack and ship customer's online orders is an indispensable and integral part of nowadays eCommerce business, as it...
Recently I’ve started using PyMC3 for Bayesian modelling, and it’s an amazing piece of software! The API only exposes as much of heavy machinery of MCMC as you need — by which I mean, just the pm.sample() method (a.k.a., as Thomas Wiecki puts it, the Magic Inference Button™). This really frees up your mind to think about your data and model, which is really the heart and soul of data science! That being said however, I quickly realized that the water gets very deep very fast: I explored my data set, specified a hierarchical model that made sense to me, hit the Magic Inference Button™, and… uh, what now? I blinked at the angry red warnings the sampler spat out.

Using the FeatureSelector for efficient machine learning workflows
In this blog, I will reveal, step by step, how to plot an ROC curve using Python. After that, I will explain the characteristics of a basic ROC curve.

This blog post surveys the attacks techniques that target AI (Artificial Intelligence) systems and how to protect against them.
A single-PDF version of Model Evaluation parts 1-4 is available on arXiv: https://arxiv.org/abs/1811.12808

Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.
Using mlxtend to perform market basket analysis on online retail data set.
aaronschlegel.com is your first and best source for all of the information you’re looking for. From general topics to more of what you would expect to find here, aaronschlegel.com has it all. We hope you find what you are searching for!
Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.

Get to know the ML landscape through this practical, concise overview of modern machine learning algorithms. Plus, we'll discuss the tradeoffs of each.

These techniques cover most of what data scientists and related practitioners are using in their daily activities, whether they use solutions offered by a vendor, or whether they design proprietary tools. When you click on any of the 40 links below, you will find a selection of articles related to the entry in question. Most… Read More »40 Techniques Used by Data Scientists
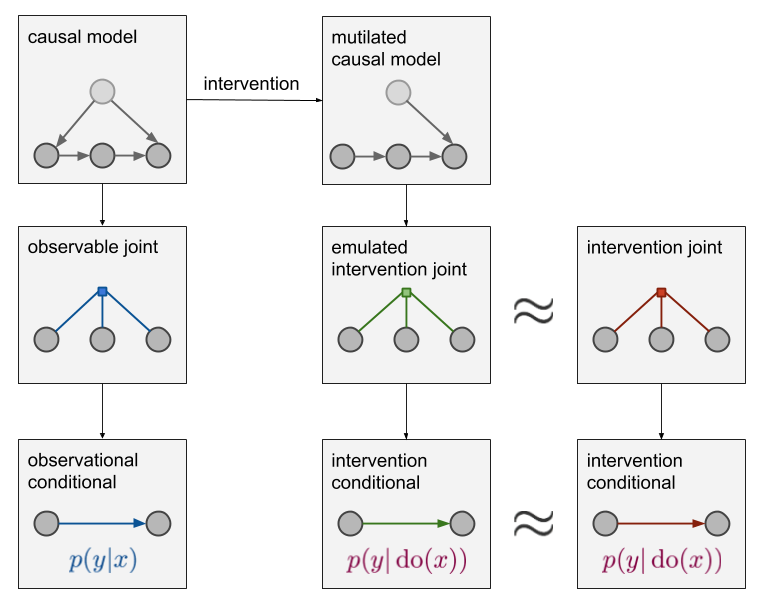
Since writing this post back in 2018, I have extended this to a 4-part series on causal inference: * ➡️️ Part 1: Intro to causal inference and do-calculus [https://www.inference.vc/untitled] * Part 2: Illustrating Interventions with a Toy Example [https://www.inference.vc/causal-inference-2-illustrating-interventions-in-a-toy-example/] * Part 3: Counterfactuals [https://www.inference.
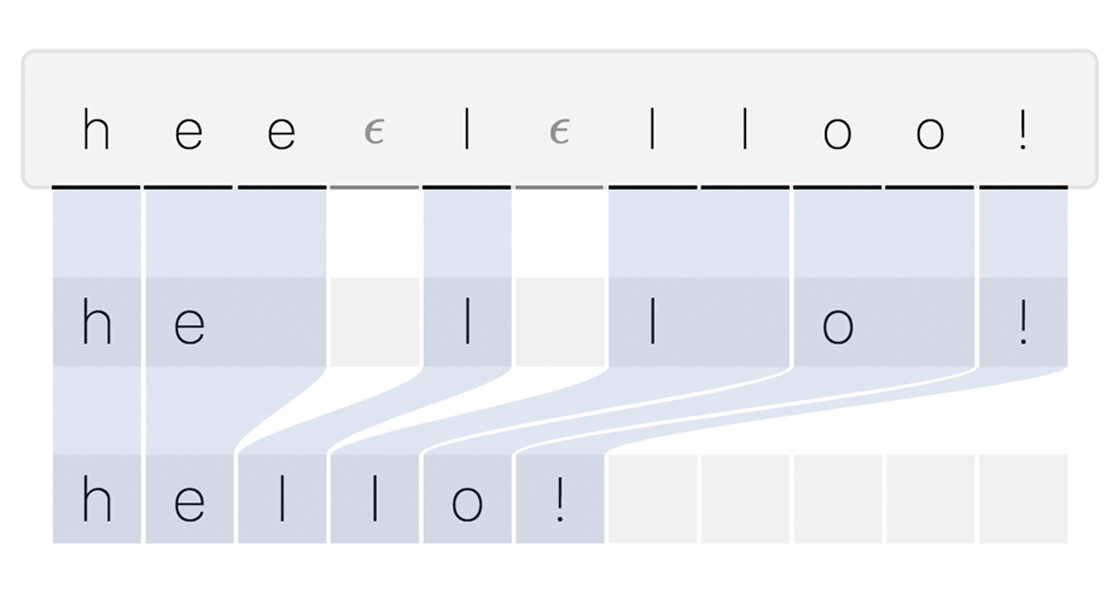
A visual guide to Connectionist Temporal Classification, an algorithm used to train deep neural networks in speech recognition, handwriting recognition and other sequence problems.
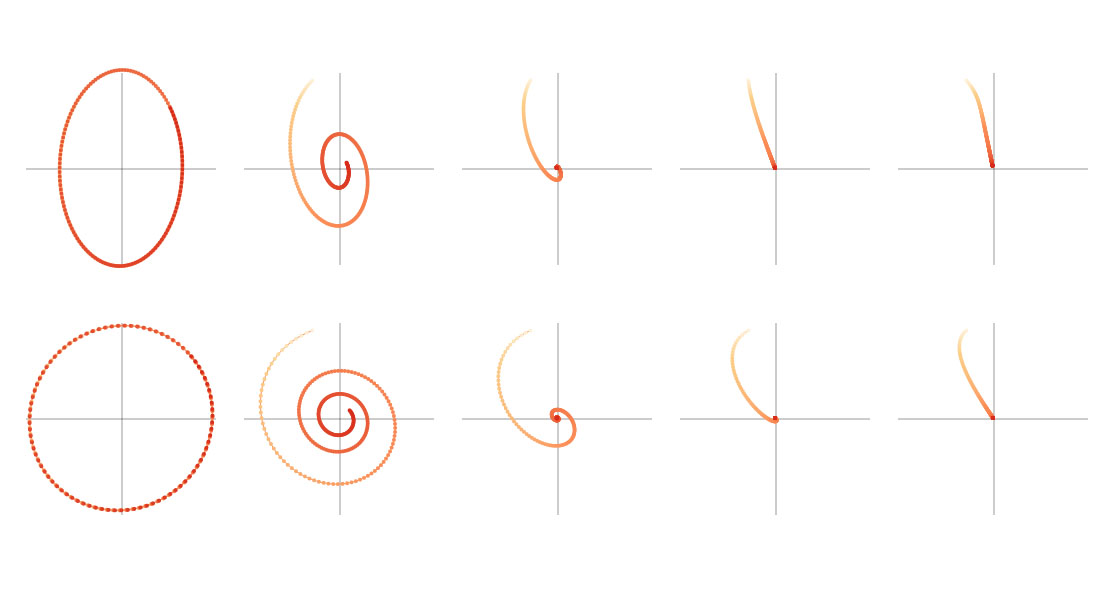
We often think of optimization with momentum as a ball rolling down a hill. This isn't wrong, but there is much more to the story.
A reference manual for creating covariance functions.

LightTag, a newly launched startup from a former NLP researcher at Citi, has built a "text annotation platform" designed to assist data scientists who
The receptive field is perhaps one of the most important concepts in Convolutional Neural Networks (CNNs) that deserves more attention from…

For many data scientists, data manipulation begins and ends with Pandas or the Tidyverse. In theory, there is nothing wrong with this…
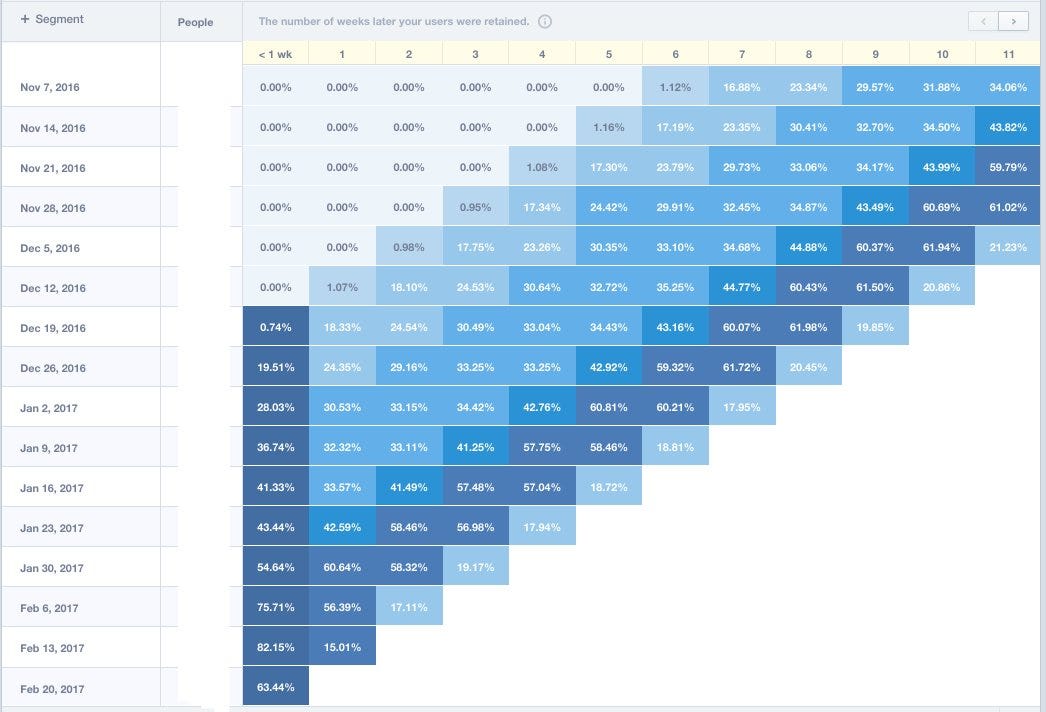
My name is Gabi (my bio), and I’m the CEO and co-founder of Chicisimo. We launched three years ago, our goal was to offer automated outfit…

Traditional strategies for taming unstructured, textual data

Data can change over time. This can result in poor and degrading predictive performance in predictive models that assume a static relationship between input and output variables. This problem of the changing underlying relationships in the data is called concept drift in the field of machine learning. In this post, you will discover the problem of concept drift and ways…
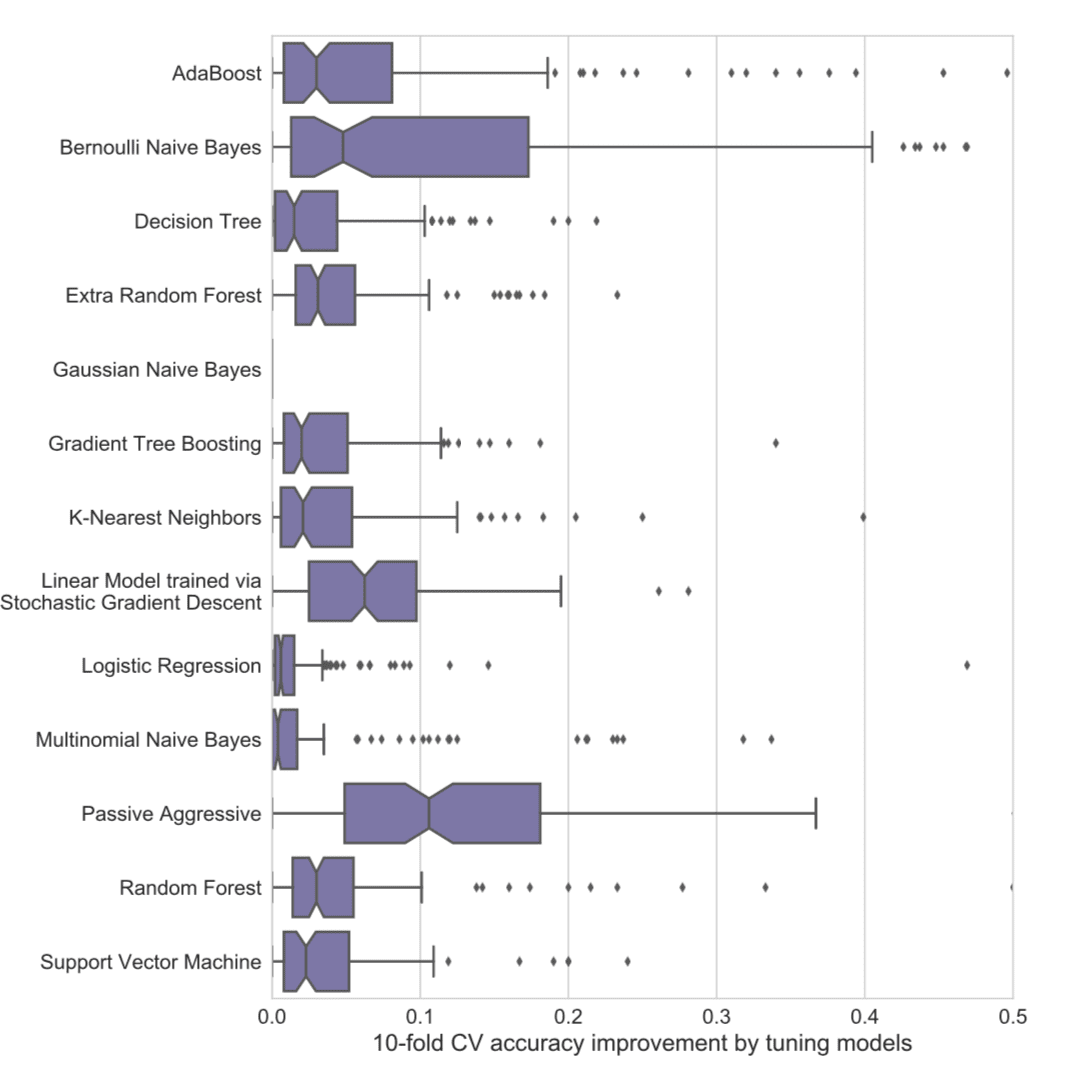
Which machine learning algorithm should you use? It is a central question in applied machine learning. In a recent paper by Randal Olson and others, they attempt to answer it and give you a guide for algorithms and parameters to try on your problem first, before spot checking a broader suite of algorithms. In this post, you will discover a…
Who is going to win this war of predictions and on what cost? Let’s explore.
We highlight recent developments in machine learning and Deep Learning related to multiscale methods, which analyze data at a variety of scales to capture a wider range of relevant features. We give a general overview of multiscale methods, examine recent successes, and compare with similar approaches.
Interested in learning the concepts behind Logistic Regression (LogR)? Looking for a concise introduction to LogR? This article is for you. Includes a Python implementation and links to an R script as well.

Traditionally, most of the multi-class classification problems (i.e. problems where you want to predict where a given sample falls into, from a set of possible results) focus on a small number of possible predictions.
Time series forecasting is an easy to use, low-cost solution that can provide powerful insights. This post will walk through introduction to three fundamental steps of building a quality model.

Three years ago we launched Chicisimo, our goal was to offer automated outfit advice. Today, with over 4 million women on the app, we want to share how our data and machine learning approach helped us grow. It’s been chaotic but it is now under control.

All of the Linear Algebra Operations that You Need to Use in NumPy for Machine Learning. The Python numerical computation library called NumPy provides many linear algebra functions that may be useful as a machine learning practitioner. In this tutorial, you will discover the key functions for working with vectors and matrices that you may find useful as a machine…

This periodic table can serve as a guide to navigate the key players in the data science space. The resources in the table were chosen by looking at surveys taken from data science users, such as the 2016 Data Science Salary Survey by O'Reilly, the 201...
This post presents an overview of the main existing recommendation system algorithms, in order for data scientists to choose the best one according a business’s limitations and requirements.
Using Self-Organizing Maps to solve the Traveling Salesman Problem The Traveling Salesman Problem is a well known challenge in Computer Science: it consists on finding the shortest route possible that traverses all cities in a given map only once. Although its simple explanation, this problem is, indeed, NP-Complete. This implies that the difficulty to solve it increases rapidly with the number of cities, and we do not know in fact a general solution that solves the problem.

This article comes from Togaware. A Survival Guide to Data Science with R These draft chapters weave together a collection of tools for the data scientist—tools that are all part of the R Statistical Software Suite. Each chapter is a collection of one (or more) pages that cover particular aspects of the topic. The chapters can be… Read More »One-page R: a survival guide to data science with R

Numenta created the open source Numenta Anomaly Benchmark (NAB) to test and their own anomaly detection algorithms. Learn more about how Numenta and Domino worked together to develop the NAB.
Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.
Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.

Imbalanced classes put "accuracy" out of business. This is a surprisingly common problem in machine learning, and this guide shows you how to handle it.
Practical Data Science with Ruby based tools.
Machine learning algorithms aren’t difficult to grasp if you understand the basic concepts. Here, a SAS data scientist describes the foundations for some of today’s popular algorithms.
Data science, also known as data-driven decision, is an interdisciplinery field about scientific methods, process and systems to extract knowledge from data in various forms, and take descision based on this knowledge. A data scientist should not only be evaluated only on his/her knowledge on machine learning, but he/she should also have good expertise on statistics. I will try to start from very basics of data science and then slowly move to expert level. So let’s get started.

Short form: Win-Vector LLC’s Dr. Nina Zumel has a three part series on Principal Components Regression that we think is well worth your time. Part 1: the proper preparation of data (including…
Ryan Marcus, assistant professor at the University of Pennsylvania. Using machine learning to build the next generation of data systems.
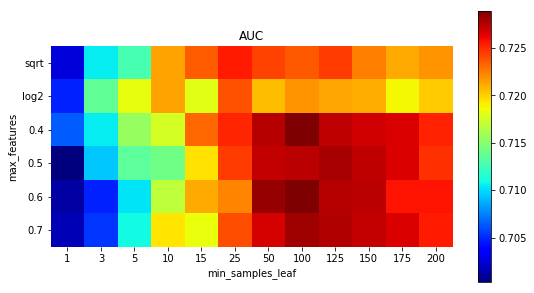
An introduction to parfit
The author presents 10 statistical techniques which a data scientist needs to master. Build up your toolbox of data science tools by having a look at this great overview post.
The Kullback-Leibler divergence between two probability distributions is sometimes called a "distance," but it's not. Here's why.
Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.
380 votes, 20 comments. 2.9M subscribers in the MachineLearning community. Beginners -> /r/mlquestions , AGI -> /r/singularity, career advices ->…

Artificial intelligence (AI) is hot. Over $4 billion in venture capital has been invested in AI firms just in the US. But supply chain planning software companies, with their cadre of operations research Ph.Ds who have been modeling complex problems for decades, may be better poised to solve many complex business problems than the hot new Silicon Valley firms.
Model evaluation metrics are used to assess goodness of fit between model and data, to compare different models, in the context of model selection, and to predict how predictions (associated with a specific model and data set) are expected to be accurate. Confidence Interval. Confidence intervals are used to assess how reliable a statistical estimate… Read More »11 Important Model Evaluation Techniques Everyone Should Know

Nina Zumel prepared an excellent article on the consequences of working with relative error distributed quantities (such as wealth, income, sales, and many more) called “Living in A Lognormal…

Update, Dec 12, 2016: There is a follow up post discussing the outcome of all of this after the election results were known.
A new “shrinking bull’s-eye” algorithm from researchers at MIT speeds up complex modeling from days to hours.