Pricing algorithms - and Collusion
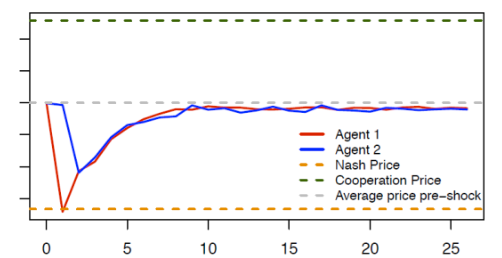
Figure 1 illustrates the punishment strategies that the algorithms autonomously learn to play. Starting from the (collusive) prices on which the algorithms have converged (the grey dotted line), we override one algorithm’s choice (the red line), forcing it to deviate downward to the competitive or Nash price (the orange dotted line) for one period. The other algorithm (the blue line) keeps playing as prescribed by the strategy it has learned. After this exogenous deviation in period , both algorithms regain control of the pricing.