lLM - large language model) survey - ArXiV
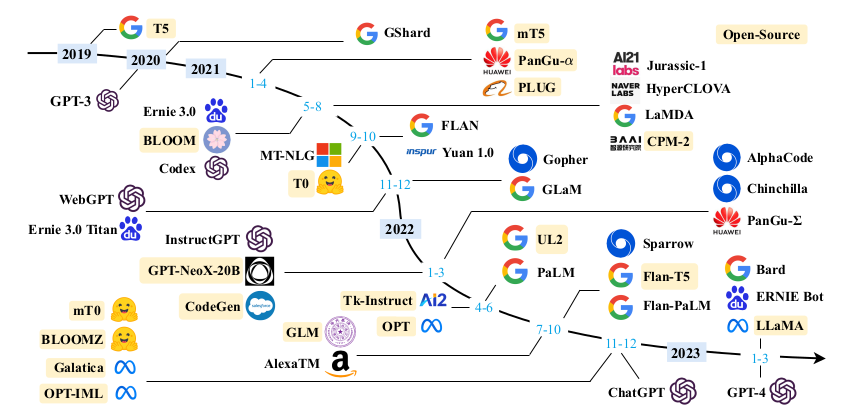
Intro - 4 development stages (thus far)
- statistical LMs- neural LMs
- pre-trained LMs
- large LMs (LLMs)
project website
LLM Overview
- background- emergent abilities
- key techniques (scaling, training, abilities, alignment tuning, tool manipulation)
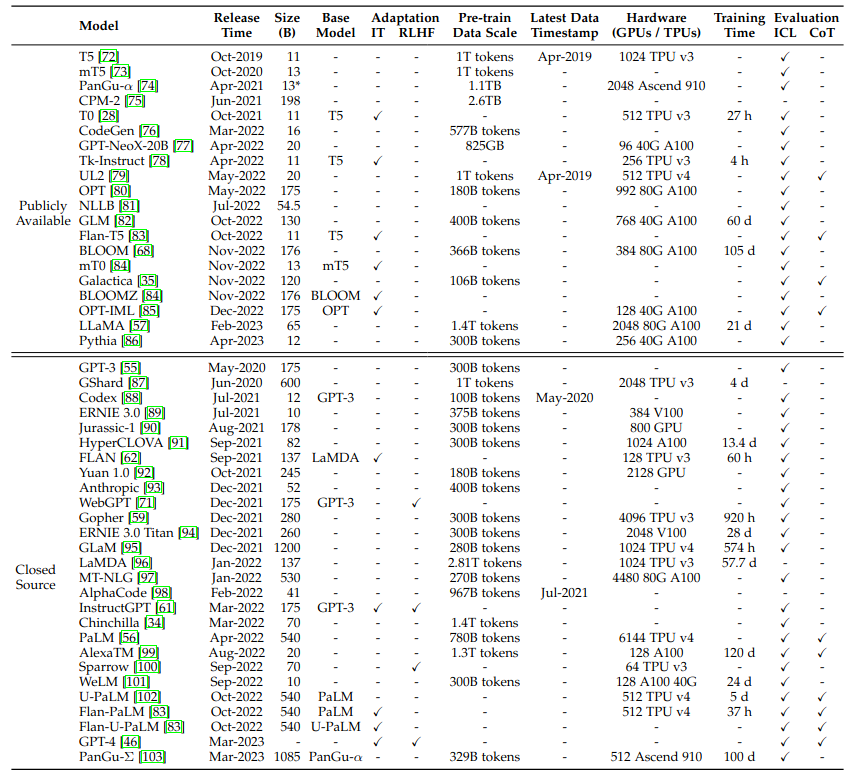
Resources - Public Model checkpoints/APIs
- models with tens of billions of params- models with hundreds of billions of params
- public APIs
- OpenAI: 7 GPT3 interfaces (ada, babbage, curie, davinci, text-ada-001, text-baggage-001, text-curie-001)
- OpenAI model overview
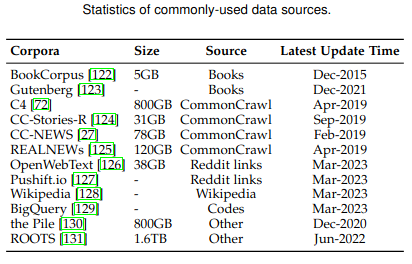
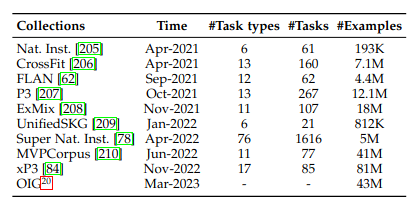
Common Corpora
- BookCorpus, Project Gutenberg- Common Crawl - multiple filtered datasets
- Reddit, OpenWebText, PushShift.io
- Wikipedia
- Code (GitHub, BigQuery, StackOverflow) - Others (ThePile, etc)
Examples
- GPT3 (175B weights, 300B tokens)- PaLM (540B weights, 780B tokens)
- LLaMA (6/13/32/65B weights, 1.0/1.4T tokens)
Code Libraries
- transformers (Python, Hugging Face)- deepspeed (PyTorch, Microsoft)
- megatron-LM (PyTorch, nVidia)
- jax (Python, Google Brain)
- colossal-AI (jax-based, EleutherAI)
- BMtrain (OpenBMB)
- fastMoE (Pytorch, mixture of experts models)
Pretraining Techniques
- general data (webpages, conversation text, books)- specialized data (multilingual, scientific, code)
Preprocessing Techniques
- quality filtering (classifier-based, heuristic-based, keyword-based)- reducing duplication
- privacy redaction
- tokenization

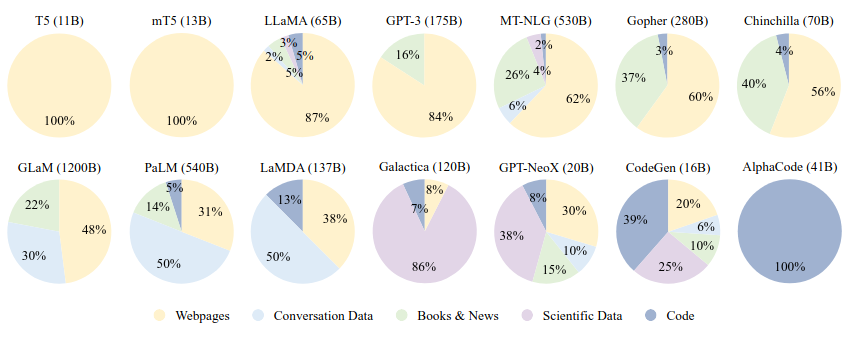
Effects of pretraining data
- source mixtures- amount of data
- quality of data
Architectures
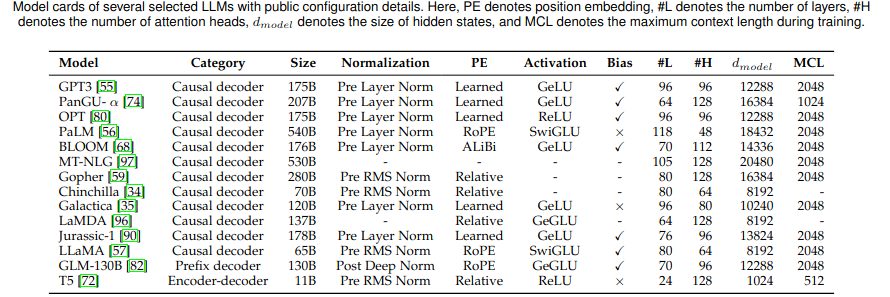
- mainstream (encoder-decoders, casual decoders, prefix decoders)Detailed configurations
- normalization (for training stability)- activation functions
- position embeddings
- attention & bias
Pretraining tasks
- language modeling (LM)- denoising autoencoding (DAE)
Model training
- optimization settings (batches, learning rates, Adam/AdamW optimizers, stabilization via weight decay & gradient clipping)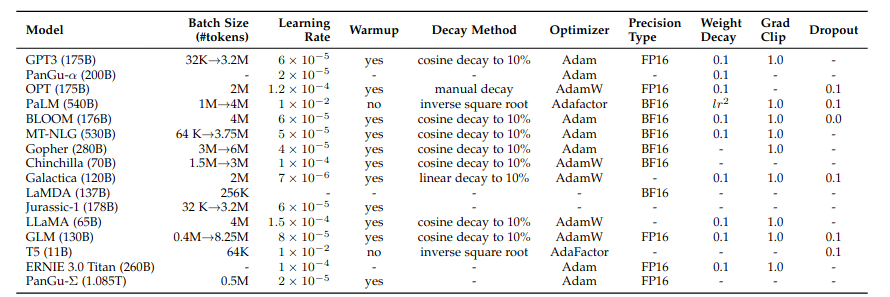
Scalable Training
- 3D parallelism (data, pipelines, tensors)- ZeRO (memory redundancy improvement)
- Mixed-precision training
- Summary
Adaptive Tuning
Instruction Tuning
- formatted instance construction- instruction tuning techniques
- combined instruction tuning & pretraining
- effects
Alignment Tuning
- background & criteria- collecting feedback (rankings, question-based, rule-based)
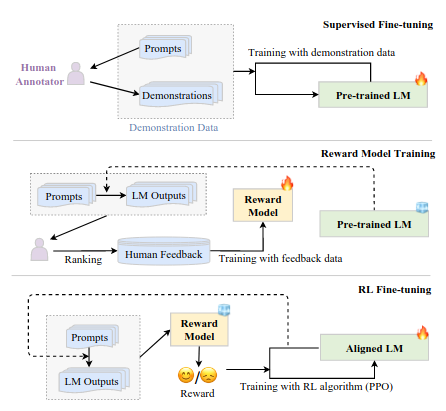
Reinforcement learning from human feedback (RHLF)
- system blocks (pretrained LM, reward model, RL trainer)- key steps
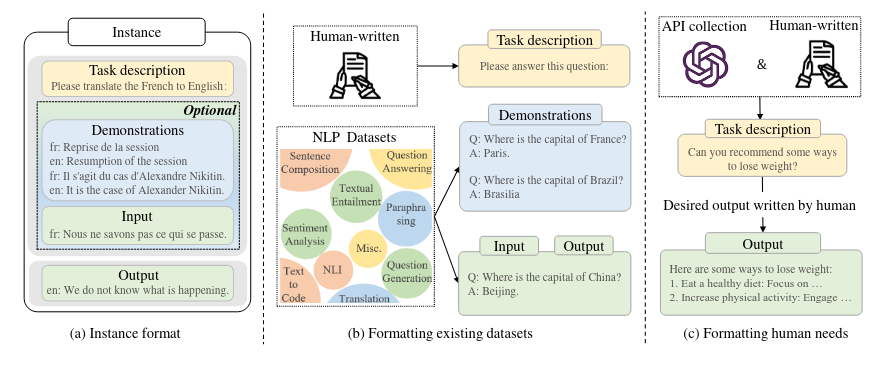
Utilization & Prompting - in-context Learning (ICL)
- prompting formulation- demo design
- demo selection
- demo format
- demo ordering
- underlying mechanism
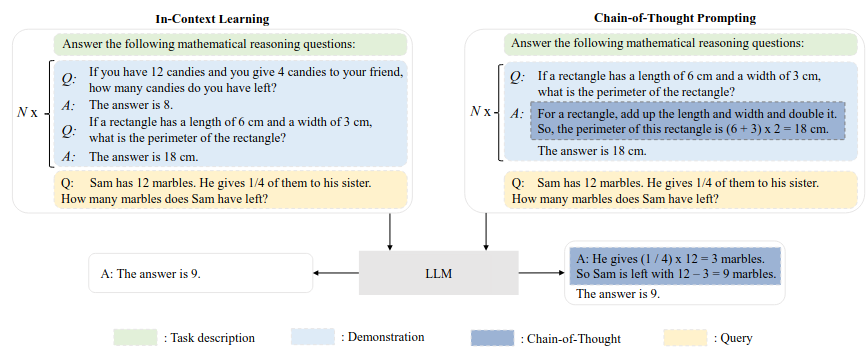
Chain-of-Thought (CoT) Prompting
- ICL with CoT (few-shot, zero-shot)- further discussion
Capacity - basic evaluation tasks
- language generation (modeling, conditional text, code synthesis; major issues)- knowledge utilization (closed/open-book QA, knowledge completion; major issues)
- complex reasoning (knowledge, symbolics, mathmatical; major issues)

Capacity - advanced ability evaluation
- human value alignment- external environment interactions
- tool manipulation
Benchmarks
- MMLU, BIG-bench, HELMConclusion/Directions
theory & principlemodel training
model utilization
safety & alignment application & ecosystem