Transformers cheat sheet - original on ArXiV


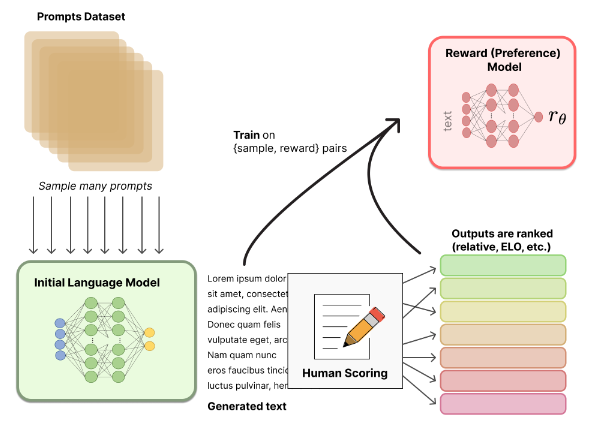

Architectures
The original Transformer architecture included an Encoder and Decoder. Sometimes it is beneficial to use only the encoder, only the decoder, or both.
Encoder Pretraining
- a.k.a. bi-directional or auto-encoding, only use the encoder
- pretraining: usually accomplished by masking words in the input sentence and training the model to reconstruct.
- At each stage attention layers can access all the input words.
- Most useful for tasks that require understanding complete sentences such as sentence classification or extractive question answering.
Decoder Pretraining
- a.k.a. auto-regressive. use only the decoder
- usually designed so the model is forced to predict the next word.
- attention layers can only access the words positioned before a given word in the sentence.
- best suited for tasks involving text generation.
Transformer (Encoder-Decoder)
- Encoder-decoder models, a.k.a. sequence-to-sequence, use both parts of the Transformer architecture.
- Attention layers of the encoder can access all the words in the input.
- decoder attention layers can only access the words positioned before a given word in the input.
- pretraining can be done using the objectives of encoder or decoder models, but usually involves something a bit more complex.
- best suited for generating new sentences depending on a given input, such as summarization, translation, or generative question answering.
Tasks
When training a model we need to define a task for the model to learn on.
“Pre-trained Models for Natural Language Processing: A Survey”[ 10 ] includes a taxonomy of pretraining tasks, all of which can be considered self-supervised.
1. Language Modeling (LM):
- Predict next token (in the case of unidirectional LM) or previous and next token (bidirectional LM)
2. Masked Language Modeling (MLM):
- mask out some tokens from input sentences then train model to predict masked tokens by the rest of the tokens
3. Permuted Language Modeling (PLM):
- same as LM but on a random permutation of input sequences.
- Then some tokens are chosen as the target - model is trained to predict these targets.
4. Denoising Autoencoder (DAE):
- take a partially corrupted input (e.g. Randomly sampling tokens from the input and replacing them with "[MASK]" elements.
- randomly delete tokens from the input or shuffle sentences in random order
- recover the original undistorted input.
5. Contrastive Learning (CTL):
- A score function for text pairs is learned by assuming some observed pairs are more semantically similar than randomly samples.
- Variants:
• Deep InfoMax (DIM): maximize mutual information between an image representation and local regions of the image;
• Replaced Token Detection (RTD): predict whether a token is replaced given its surroundings;
• Next Sentence Prediction (NSP): train the model to distinguish whether two input sentences are continuous segments from the training corpus; and
• Sentence Order Prediction (SOP): Similar to NSP, but uses two consecutive segments as positive examples, and the same segments but with their order swapped as negative examples
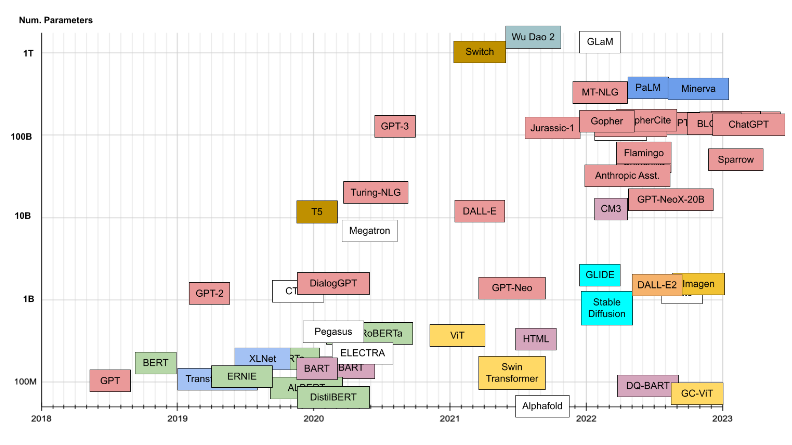
Family
Pretrainer
Extension
Apps
Pub Date
#Parameters
Data corpus
Developer
AlphaFold
Anthropic
BART
BERT
BigBird
BlenderBot3
BLOOM
ChatGPT
Chinchilla
CLIP
CM3
CTRL
DALL-E
DALL-E 2
Decision transformers
DialoGPT
DistilBERT
DQ-BART
ELECTRA
ERNIE
Flamingo
Gato
GLaM
GLIDE
Global Context ViT
Gopher
GopherCite
GPT
GPT-2
GPT-3
GPT-3.5
InstructGPT
GPT-Neo
GPT-NeoX-20B
HTML
Imagen
Jurassic-1
LAMDA
mBART
Megatron
Minerva
MT-NLG
OPT
PalM
Pegasus
RoBERTa
SeeKer
Sparrow
StableDiffusion
Swin
Switch
T5
Trajectory transformers
Transformer XL
Turing-NLG
ViT
Wu Dao 2.0
XLM-RoBERTa
XLNet