LLMS 2023-2024 (Williston.net)
2023:
- So far, I think they’re a net positive. I’ve used them on a personal level to improve my productivity (and entertain myself) in all sorts of different ways. I think people who learn how to use them effectively can gain a significant boost to their quality of life.
They’re actually quite easy to build
- a few hundred lines of Python (karpathy) is enough to train nanoGPT.
- You need a lot of data to make these things work, and the quantity and quality of the training data appears to be the most important factor in how good the resulting model is.
- A year ago, the only organization that had released a generally useful LLM was OpenAI.
- We’ve now seen better-than-GPT-3 class models produced by Anthropic, Mistral, Google, Meta, EleutherAI, Stability AI, TII in Abu Dhabi (Falcon), Microsoft Research, xAI, Replit, Baidu and a bunch of other organizations.
- Microsoft’s Phi-2 claims to have used “14 days on 96 A100 GPUs”, which works out at around $35,000 using current Lambda pricing.
You can run LLMs on your own devices
- February: Meta released Llama.
- March: Georgi Gerganov released code that got it working on a MacBook.
- July: Meta released Llama 2— included permission for commercial use.
- Today: thousands of LLMs that can be run locally, on all manner of different devices.
- I run a bunch of them on my laptop.
- I run Mistral 7B on my iPhone.
- LLM provides a CLI tool for running different models via plugins.
- You can even run them entirely in your browser using WebAssembly and the latest Chrome!
Hobbyists can build their own fine-tuned models
-
The Hugging Face Open LLM Leaderboard. I can’t even attempt to count them, and any count would be out-of-date within a few hours.
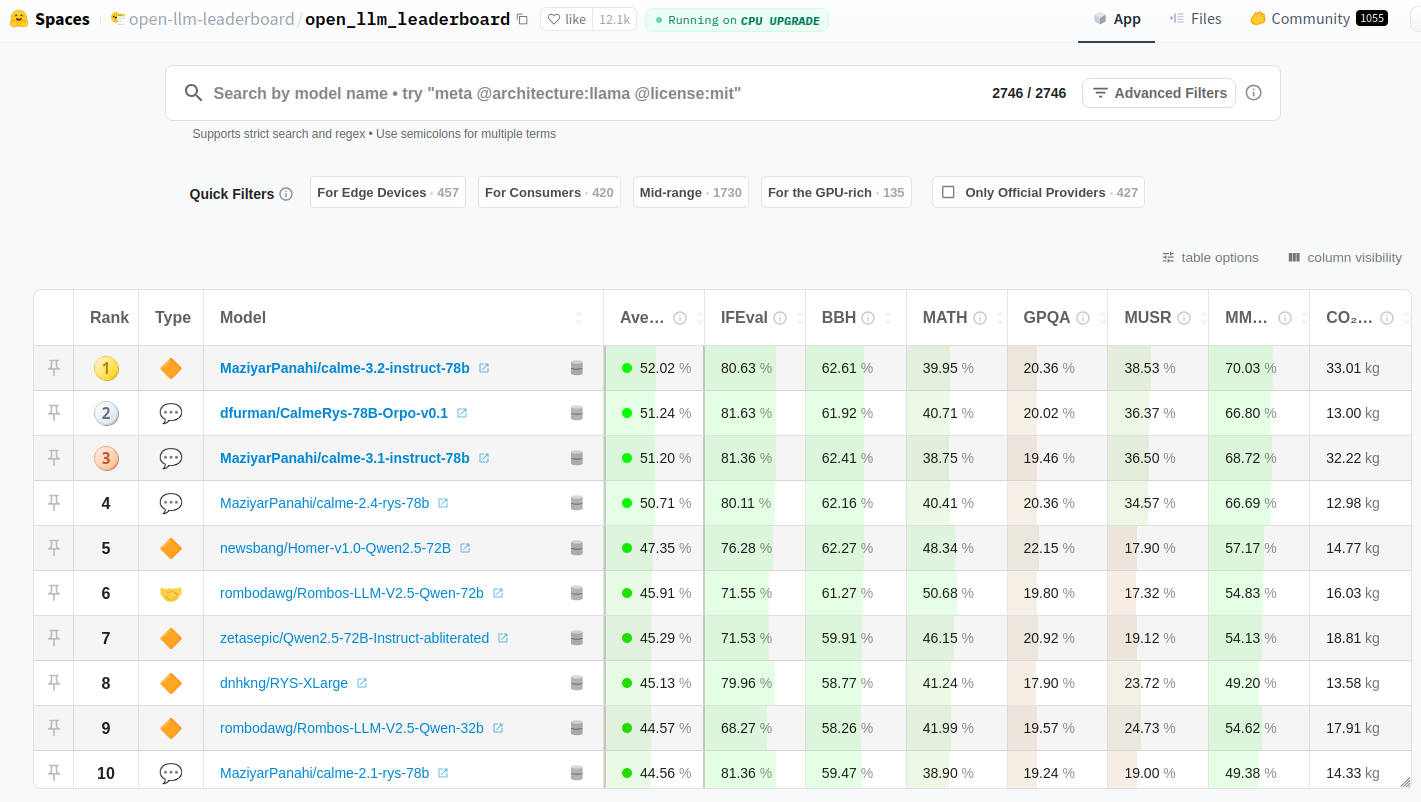
- The best openly licensed LLM at any time is rarely a foundation model: instead, it’s whichever fine-tuned community model has most recently discovered the best combination of fine-tuning data.
- This is a huge advantage for open over closed models. Closed models don’t have thousands of researchers and hobbyists around the world collaborating and competing to improve them.
We don’t yet know how to build GPT-4
- Despite the advances we are yet to see an alternative model that’s better than GPT-4.
- OpenAI released GPT-4 in March. Microsoft claimed to be using it as part of the new Bing.
- Google’s Gemini Ultra has big claims.
- Mistral working to beat GPT-4 as well, and their track record is already extremely strong
- first public model only came out in September
- released two significant improvements since then.
- Still, I’m surprised that no-one has beaten the now almost year old GPT-4 by now. OpenAI clearly have some substantial tricks that they haven’t shared yet.
- Even the openly licensed ones are still the world’s most convoluted black boxes.
- The worst part is evaluating them. There are plenty of benchmarks, but no benchmark is going to tell you if an LLM actually “feels” right when you try it for a given task.
- frustrating: the level of individual prompting.
- Sometimes I’ll tweak a prompt and capitalize some of the words in it, to emphasize that I really want it to OUTPUT VALID MARKDOWN or similar.
- Did capitalizing those words make a difference? I still don’t have a good methodology for figuring that out.
LLMs are really smart, and also really, really dumb
- keep finding new things that LLMs can do that we didn’t expect—and that the people who trained the models didn’t expect either.
- the things you sometimes have to do to get the models to behave are often incredibly dumb.
- Does ChatGPT get lazy in December, because its hidden system prompt includes the current date and its training data shows that people provide less useful answers coming up to the holidays?
- No-one is entirely sure, but if you give it a different date its answers may skew slightly longer.
- Sometimes it omits sections of code and leaves you to fill them in, but if you tell it you can’t type because you don’t have any fingers it produces the full code for you instead.
- There are so many more examples like this. Offer it cash tips for better answers. Tell it your career depends on it. Give it positive reinforcement. It’s all so dumb, but it works!
Gullibility is the biggest unsolved problem
- I coined the term prompt injection in September last year.
- We’re still no closer to a robust solution to this problem..
- Language Models are gullible. They “believe” what we tell them—what’s in their training data, then what’s in the fine-tuning data, then what’s in the prompt.
- useful tools need to believe what we feed them!
- A lot of the things we want to build need them not to be gullible.
- If you hired a real-world personal assistant who believed everything that anyone told them, you would quickly find that their ability to positively impact your life was severely limited.
- I’m beginning to suspect that you can’t fully solve gullibility without achieving AGI.
Code may be the best application
- increasingly clear that writing code is one of the things LLMs are most capable of.
- weaknesses of LLMs: tendency to hallucinate—to imagine things that don’t correspond to reality. You would expect this to be a particularly bad problem for code—if an LLM hallucinates a method that doesn’t exist, the code should be useless.
- Except… you can run generated code to see if it’s correct. And with patterns like ChatGPT Code Interpreter the LLM can execute the code itself, process the error message, then rewrite it and keep trying until it works!
- So hallucination is a much lesser problem for code generation than for anything else. If only we had the equivalent of Code Interpreter for fact-checking natural language!
- On the other hand, as software engineers we are better placed to take advantage of this than anyone else. We’ve all been given weird coding interns—we can use our deep knowledge to prompt them to solve coding problems more effectively than anyone else can.
{kind=link}
The ethics of this space remain diabolically complex
- September 2023 Andy Baio and I produced the first major story on the unlicensed training data behind Stable Diffusion.
- Just this week, the New York Times launched a landmark lawsuit against OpenAI and Microsoft over this issue.
- The 69 page PDF is genuinely worth reading—especially the first few pages, which lay out the issues in a way that’s surprisingly easy to follow.
- The rest of the document includes some of the clearest explanations of what LLMs are, how they work and how they are built that I’ve read anywhere.
2024
- 18 organizations’ models on Chatbot Arena Leaderboard rank higher than the original GPT-4 from March 2023 (
GPT-4-0314on the board)—70 models in total. 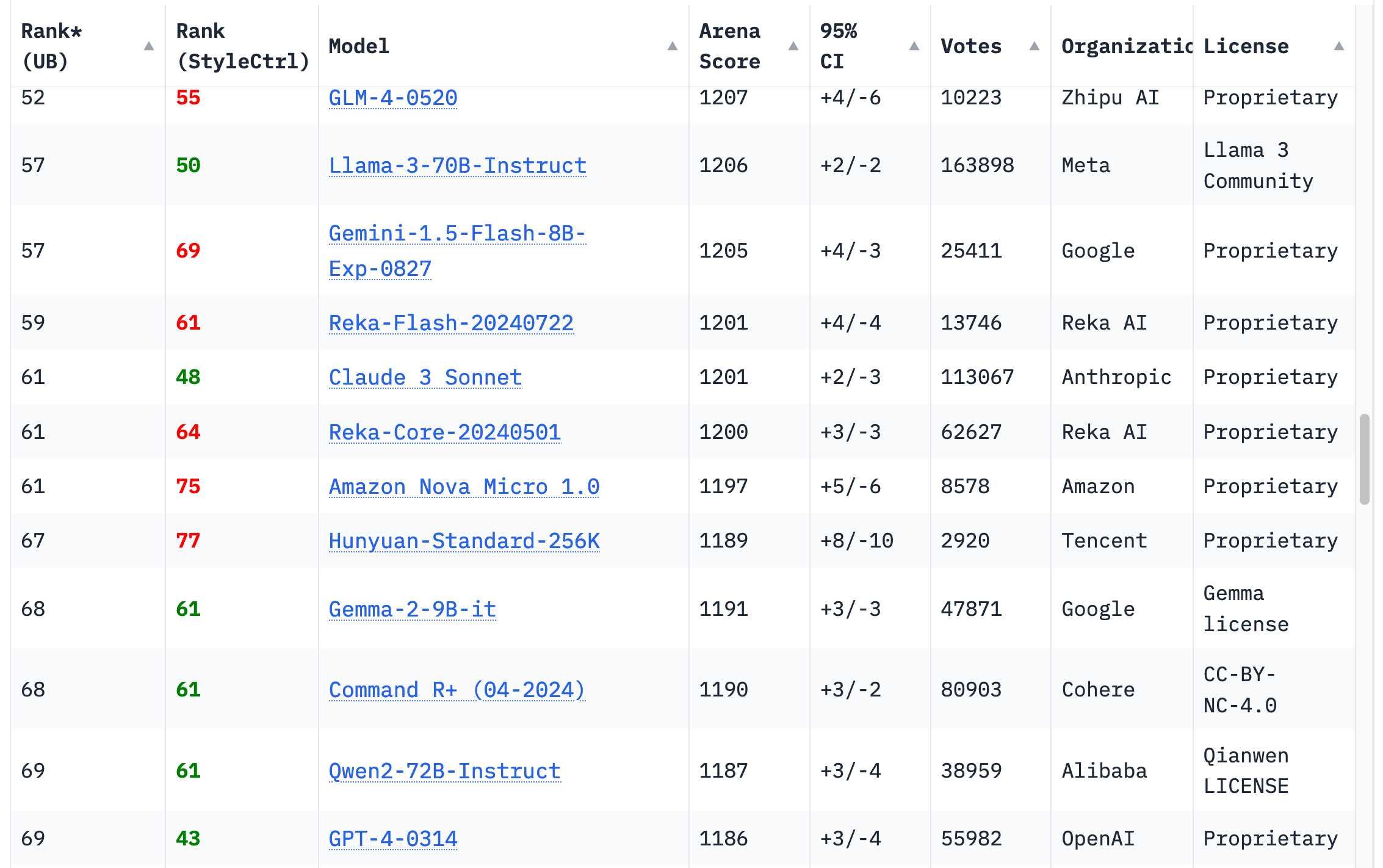
- Google’s Gemini 1.5 Pro
- released in February
- GPT-4 level outputs
- 1 million (and then later 2 million) token input context length
- The killer app: video input.
- increased context lengths
- Last year most models accepted 4,096 or 8,192 tokens, with the notable exception of Claude 2.1 which accepted 200,000.
- Today every serious provider has a 100,000+ token model, and Google’s Gemini series accepts up to 2 million.
- Longer inputs increase the scope of problems that can be solved with an LLM: you can now throw in an entire book and ask questions about its contents, but more importantly you can feed in a lot of example code to help the model correctly solve a coding problem.
- LLM use-cases with long inputs are far more interesting to me than short prompts that rely purely on the information already baked into the model weights.
- Anthropic’s Claude 3 series launched in March, and Claude 3 Opus quickly became my new favourite daily-driver.
- Claude 3.5 Sonnet launch (June) — a model that is still my favourite six months later
- (upgrade on October 22, keeping same 3.5 version number. Anthropic fans have since taken to calling it Claude 3.6).
- the Chatbot Arena leaderboard is still the most useful place to get a vibes-based evaluation of models—you’ll see that GPT-4-0314 has fallen to around 70th place.
- organizations with higher scoring models: Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, 01 AI, Amazon, Cohere, DeepSeek, Nvidia, Mistral, NexusFlow, Zhipu AI, xAI, AI21 Labs, Princeton and Tencent.
{kind=link}
Some of those GPT-4 models run on my laptop
- A 64GB M2 MacBook Pro could just about run a GPT-3-class model in March last year has now run multiple GPT-4 class models.
- Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac
- Meta’s Llama 3.3 70B (released in December): I can now run a GPT-4 class model on my laptop]
- These models take up enough of my 64GB of RAM that I don’t run them often.
- Meta’s Llama 3.2 models deserve a special mention. They may not be GPT-4 class, but at 1B and 3B sizes they punch massively above their weight.
- I run Llama 3.2 3B on my iPhone using the free MLC Chat iOS app and it’s a shockingly capable model for its tiny (<2GB) size.
- Try asking it for “a plot outline of a Netflix Christmas movie where a data journalist falls in love with a local ceramacist”. Here’s what I got, at a respectable 20 tokens per second:
- Here’s the rest of the transcript. It’s bland, but my phone can pitch bland and generic Christmas movies to Netflix now!
LLM prices crashed, thanks to competition and increased efficiency
- The past twelve months have seen a dramatic collapse in the cost of running a prompt through the top tier hosted LLMs.
- OpenAI pricing, December 2023 (Internet Archive):
- $30/million input tokens (GPT-4)
- $10/mTok (GPT-4 Turbo)
- $1/mTok (GPT-3.5 Turbo)
- Today:
- o1: $30/mTok (OpenAI’s most expensive model)
- GPT-4o: $2.50/mTok (12x cheaper than GPT-4)
- GPT-4o mini: $0.15/mTok nearly 7x cheaper than GPT-3.5 and *massively more capable.)
- Other model providers charge even less.
- Anthropic’s Claude 3 Haiku (from March, but still their cheapest model) is $0.25/mTok.
- Google’s Gemini 1.5 Flash is $0.075/mTok
- Gemini 1.5 Flash 8B is $0.0375/mTok (27x cheaper than GPT-3.5 Turbo last year.)
- These price drops are driven by increased competition and increased efficiency. They tie directly to how much energy is being used for running prompts.
- Here’s a fun napkin calculation: how much would it cost to generate short descriptions of every one of the 68,000 photos in my personal photo library using Google’s Gemini 1.5 Flash 8B (released in October), their cheapest model?
- Each photo would need 260 input tokens and around 100 output tokens.
- 260 * 68,000 = 17,680,000 input tokens
- 17,680,000 * $0.0375/million = $0.66
- 100 * 68,000 = 6,800,000 output tokens
- 6,800,000 * $0.15/million = $1.02
- That’s a total cost of $1.68 to process 68,000 images. That’s so absurdly cheap I had to run the numbers three times to confirm I got it right.
- Each photo would need 260 input tokens and around 100 output tokens.
- How good are those descriptions?
-
Here’s the LLM CLI prompt:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
-
Here’s the result (260 input tokens, 92 output tokens. Cost approximately 0.0024 cents)
-
A shallow dish, likely a hummingbird or butterfly feeder, is red. Pieces of orange slices of fruit are visible inside the dish. Two butterflies are positioned in the feeder, one is a dark brown/black butterfly with white/cream-colored markings. The other is a large, brown butterfly with patterns of lighter brown, beige, and black markings, including prominent eye spots. The larger brown butterfly appears to be feeding on the fruit.
Multimodal vision is common, audio and video are starting to emerge
- My butterfly example above illustrates another key trend from 2024: the rise of multi-modal LLMs.
- GPT-4 Vision, OpenAI’s DevDay, Nov’2023.
- Gemini 1.0 announcedDec’2023
- Claude 3 series from Anthropic March,
- Gemini 1.5 Pro April (images, audio and video)
- Qwen2-VL
- Mistral’s Pixtral 12B
- Meta’s Llama 3.2 11B and 90B.
- OpenAI audio input and output
- SmolVLM from Hugging Face
- Amazon Nova image and video models.
- I upgraded my LLM CLI tool to support multi-modal models via attachments. It now has plugins for a whole collection of different vision models.
Voice and live camera mode are science fiction come to life
-
The audio and live video modes that have started to emerge deserve a special mention.
- ability to talk to ChatGPT first arrived in September 2023, but it was mostly an illusion:
- OpenAI used their excellent Whisper speech-to-text model and a new tts-1 text-to-speech model) to enable conversations with the ChatGPT mobile apps, but the actual model just saw text.
- GPT-4o announcement included a demo of a brand new voice mode
- (the o is for “omni”) model accepts audio input and output incredibly realistic sounding speech without needing separate TTS or STT models.
- The demo also sounded [conspicuously similar to Scarlett Johansson](https://www.nytimes.com/2024/05/20/technology/scarlett-johansson-openai-statement.html, and after she complained the voice from the demo, Skye, never made it to a production product.
-
ChatGPT in “4o” mode is not running the new features yet (May).
- ChatGPT Advanced Voice mode roll out (August-September) = spectacular.
- I’ve been using it extensively on walks with my dog and it’s amazing how much the improvement in intonation elevates the material.
- OpenAI audio APIs.
- Even more fun: Advanced Voice mode can do accents! Here’s what happened when I told it I need you to pretend to be a California brown pelican with a very thick Russian accent, but you talk to me exclusively in Spanish.
- more multi-modal audio annoucements:
- Google’s Gemini also accepts audio input
- Google Gemini apps can speak in a similar way to ChatGPT now
- Amazon Nova - voice mode, rollout in Q125.
- [Google’s NotebookLM(https://simonwillison.net/2024/Sep/29/notebooklm-audio-overview/) - produces spookily realistic conversations between two “podcast hosts” about anything you fed into their tool.
- They later added custom instructions, so naturally I turned them into pelicans:
- live video:
- ChatGPT voice mode now provides the option to share your camera feed with the model and talk about what you can see in real time.
- Google Gemini previewing the same feature
- Gemini and OpenAI offer API access to these features.
- OpenAI WebSocket API - quite challenging to use
- OpenAI WebRTC API
Prompt driven app generation is a commodity already
-
We already knew LLMs were good at writing code.
-
Good prompts will build you a full interactive application using HTML, CSS and JavaScript (and tools like React if you wire up some extra supporting build mechanisms)—often in a single prompt.
- Anthropic kicked this idea into high gear when they released Claude Artifacts, a groundbreaking new fetaure that was initially slightly lost in the noise due to being described half way through their announcement of the incredible Claude 3.5 Sonnet.
- Claude can write you an on-demand interactive application and then let you use it directly inside the Claude interface.
- Here’s my Extract URLs app, entirely generated by Claude:
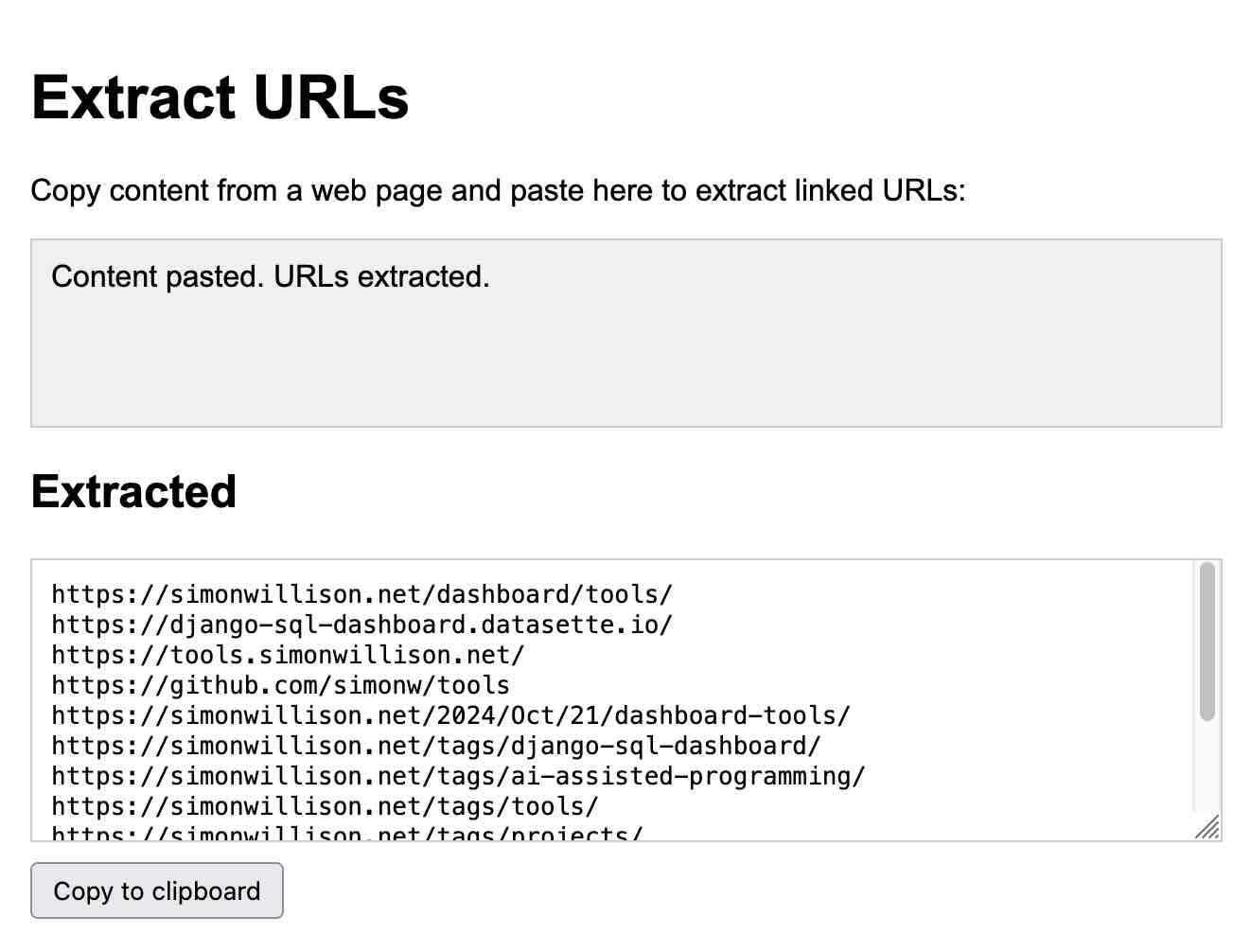
-
Steve Krause from Val Town built a version against Cerebras - shows how a 2,000 token/second LLM can iterate on an application with changes visible in less than a second.
- Chatbot Arena team introduced a whole new leaderboard for this feature
- driven by users building the same interactive app twice with two different models and voting on the answer
- Hard to come up with a more convincing argument that this feature is now a commodity that can be effectively implemented against all of the leading models.
-
I’ve been tinkering with a version of this for my Datasette project, with the goal of letting users use prompts to build and iterate on custom widgets and data visualizations against their own data. I also figured out a similar pattern for writing one-shot Python programs, enabled by uv.
- This prompt-driven custom interface feature is so powerful and easy to build (once you’ve figured out the gnarly details of browser sandboxing) that I expect it to show up as a feature in a wide range of products in 2025.
Universal access to the best models lasted a few short months
- For a time, all three of the best available models - GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 Pro—were freely available to most of the world.
- May: OpenAI made GPT-4o free for all users.
- June: Claude 3.5 Sonnet was freely available.
- OpenAI’s launch of ChatGPT Pro - $200/month is the only way to access their most capable model, o1 Pro.
- Since the trick behind the o1 series is to expend more compute time to get better results, I don’t think those days of free access to the best available models are likely to return.
“Agents” still haven’t really happened yet
-
“agents” lack a single, clear and widely understood meaning… but the people who use the term never seem to acknowledge that.
- The two main categories I see:
- people who think AI agents are obviously things that go and act on your behalf—the travel agent model
- people who think in terms of LLMs that have been given access to tools which they can run in a loop as part of solving a problem.
- here’s 211 definitions from Twitter.
- ported to Datasette Lite
- [summarized (attempted) by
gemini-exp-1206(https://gist.github.com/simonw/beaa5f90133b30724c5cc1c4008d0654).)
-
Whatever the term may mean, agents still have that feeling of perpetually “coming soon”.
- gullibility: LLMs believe anything you tell them. Any systems that attempts to make meaningful decisions on your behalf will run into the same roadblock: how good is a travel agent, or a digital assistant, or even a research tool if it can’t distinguish truth from fiction?
- Google Search caught serving a fake description of the non-existant movie “Encanto 2”.
- It turned out to be summarizing an imagined movie listing from a fan fiction wiki.
- Prompt injection is a natural consequence of gullibility.
- Anthropic’s Amanda Askell (responsible for much of the work behind Claude’s Character):
The boring yet crucial secret behind good system prompts is test-driven development. You don’t write down a system prompt and find ways to test it. You write down tests and find a system prompt that passes them.
-
It’s become clear that writing good automated evals for LLMs is the skill that’s most needed to build useful applications on top of these models. If you have a strong eval suite you can adopt new models faster, iterate better and build more reliable and useful product features than your competition.
- Vercel’s Malte Ubl:
When @v0 first came out we were paranoid about protecting the prompt with all kinds of pre and post processing complexity. We completely pivoted to let it rip. A prompt without the evals, models, and especially UX is like getting a broken ASML machine without a manual
- Everyone knows that evals are important, but there’s a lack of great guidance for how to best implement them—I’m tracking this under my evals tag.
- My SVG pelican riding a bicycle benchmark is a pale imitation of what a real eval suite should look like.
Apple Intelligence is bad, Apple’s MLX library is excellent
- Last year it felt like my lack of a Linux/Windows machine with an NVIDIA GPU was a huge disadvantage.
- On paper, a 64GB Mac should be a great machine for running models due to the way the CPU and GPU can share the same memory.
-
In practice, many models are released as model weights and libraries that reward NVIDIA’s CUDA over other platforms.
- The llama.cpp ecosystem helped a lot, but the real breakthrough has been Apple’s MLX library, “an array framework for Apple Silicon”. It’s fantastic.
- mlx-lm Python supports running MLX-compatible models on my Mac, with excellent performance.
- mlx-community on Hugging Face offers more than 1,000 models that have been converted to the necessary format.
- Prince Canuma’s mlx-vlm project brings vision LLMs to Apple Silicon as well. I used it to run Qwen’s QvQ.
- While MLX is a game changer, Apple’s own “Apple Intelligence” features have mostly been a disapointment. I wrote about their initial announcement in June, and I was optimistic that Apple had focused hard on the subset of LLM applications that preserve user privacy and minimize the chance of users getting mislead by confusing features.
- Now that those features are rolling out they’re pretty weak. As an LLM power-user I know what these models are capable of, and Apple’s LLM features offer a pale imitation of what a frontier LLM can do. Instead we’re getting notification summaries that misrepresent news headlines and writing assistant tools that I’ve not found useful at all. Genmoji are kind of fun though.
The rise of inference-scaling “reasoning” models
-
The most interesting development in Q4’2024 was the introduction of a new shape of LLM, exemplified by OpenAI’s o1 models (o1-preview and o1-mini).
-
One way to think about these models is an extension of the chain-of-thought prompting trick, first explored in May 2022: LLMs are Zero-Shot Reasoners.
-
If you get a model to talk out loud about a problem it’s solving, you can get a result which the model would not have achieved otherwise.
-
o1 bakes the idea into the model. The details are somewhat obfuscated: o1 models spend “reasoning tokens” thinking through the problem that are not directly visible to the user (though the ChatGPT UI shows a summary of them), then outputs a final result.
-
The key: it opens a new way to scale a model. Instead of improving model performance with more training compute, models can now take on harder problems by spending more compute on inference.
-
o3 (the sequel to o1 (they skipped “o2” for Euro trademark reasons) has impressive results against the ARC-AGI benchmark, albeit one that likely involved more than $1,000,000 of compute time expense!
-
o3 is expected to ship in January. I doubt many people have real-world problems that would benefit from that level of compute expenditure but it appears to be a genuine next step in LLM architecture for taking on much harder problems.
- Google released
gemini-2.0-flash-thinking-exp. - Alibaba’s Qwen team released QwQ — under an Apache 2.0 license. I can run it on my own machine.
- Alibaba also released a vision reasoning model called QvQ, which I also ran locally.
-
DeepSeek released DeepSeek-R1-Lite-Preview model available to try out through their chat interface.
-
To understand more about inference scaling I recommend Is AI progress slowing down?.
- Nothing yet from Anthropic or Meta. Meta published Training Large Language Models to Reason in a Continuous Latent Space in December.
Best currently available LLM trained in China for less than $6m?
-
DeepSeek v3- followed by documentation and a paper.
-
DeepSeek v3 is a huge 685B parameter model—one of the largest openly licensed models currently available, significantly bigger than the largest of Meta’s Llama series, Llama 3.1 405B.
-
Benchmarks put it up there with Claude 3.5 Sonnet.
-
Vibe benchmarks (Chatbot Arena) currently rank it 7th, just behind the Gemini 2.0 and OpenAI 4o/o1 models. This is by far the highest ranking openly licensed model.
-
The really impressive thing about DeepSeek v3 is the training cost. (2,788,000 H800 GPU hours; estimated cost of $5,576,000). Llama 3.1 405B trained 30,840,000 GPU hours—11x that used by DeepSeek v3, for a model that benchmarks slightly worse.
-
-
Those US export regulations on GPUs to China seem to have inspired some very effective training optimizations!
The environmental impact got better
-
Energy usage of running a prompt has dropped enormously over the past couple of years.
-
OpenAI charging 100x less for a prompt compared to the GPT-3.
-
I have it on good authority that neither Google Gemini nor Amazon Nova (two of the least expensive model providers) are running prompts at a loss.
-
As individual users, we don’t need to feel any guilt for the energy consumed by the vast majority of our prompts. The impact is likely neglible compared to driving a car down the street or maybe even watching a video on YouTube.
-
DeepSeek v3 training for less than $6m is a fantastic sign that training costs can and should continue to drop.
-
For less efficient models I find it useful to compare their energy usage to commercial flights.
- The largest Llama 3 model cost about the same as a single digit number of fully loaded passenger flights from New York to London.
- That’s certainly not nothing, but once trained that model can be used by millions of people at no extra training cost.
The environmental impact got much, much worse
- The much bigger problem is the enormous competitive buildout of the infrastructure that is presumed to be necessary for these models in the future. Is this infrastructure necessary? DeepSeek v3’s $6m training cost and the continued crash in LLM prices might hint that it’s not. But would you want to be the big tech executive that argued NOT to build out this infrastructure only to be proven wrong in a few years’ time?
- tweet by @deepfates:
Watching in real time as “slop” becomes a term of art. the way that “spam” became the term for unwanted emails, “slop” is going in the dictionary as the term for unwanted AI generated content
Synthetic training data works great
- Model collapse first described in The Curse of Recursion: Training on Generated Data Makes Models Forget in May 2023
- Repeated in Nature in July 2024: AI models collapse when trained on recursively generated data.
-
The idea is seductive: as the internet floods with AI-generated slop the models will degenerate, feeding on their own output in a way that leads to their demise!
-
Instead, we are seeing AI labs increasingly train on synthetic content—deliberately creating artificial data to help steer their models in the right way.
-
One of the best descriptions I’ve seen of this comes from the Phi-4 technical report, which included this:
-
Synthetic data as a component of pretraining is becoming common, and the Phi series of models has emphasized the importance of synthetic data.
-
Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
-
In organic datasets, the relationship between tokens is often complex and indirect.
- Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn from next-token prediction.
- By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
-
- Another common technique: use larger models to help create training data for their smaller, cheaper alternatives—a trick used by an increasing number of labs.
- DeepSeek v3 used “reasoning” data created by DeepSeek-R1.
- Meta’s Llama 3.3 70B fine-tuning used over 25M synthetically generated examples.
LLMs somehow got even harder to use
-
LLMs are power-user tools—they’re chainsaws disguised as kitchen knives. They look deceptively simple to use—how hard can it be to type messages to a chatbot?—but in reality you need a huge depth of both understanding and experience to make the most of them and avoid their many pitfalls.
-
Did you know ChatGPT has two entirely different ways of running Python? Want to build a Claude Artifact that talks to an external API? You’d better understand CSP and CORS HTTP headers first.
-
OpenAI’s o1 may finally be able to (mostly) count the Rs in strawberry, but its abilities are still limited by its nature as an LLM and the constraints placed on it by the harness it’s running in.
- o1 can’t run web searches or use Code Interpreter
- GPT-4o can—both in that same ChatGPT UI. (o1 will pretend to do those things if you ask it to, a regression to the URL hallucinations bug from early 2023).
Knowledge is incredibly unevenly distributed
- Most people have heard of ChatGPT by now. How many have heard of Claude? The knowledge gap between the people who actively follow this stuff and the 99% of the population who do not is vast.
- The pace of change doesn’t help either. In just the past month we’ve seen general availability of live interfaces where you can point your phone’s camera at something and talk about it with your voice… and optionally have it pretend to be Santa. Most self-certified nerds haven’t even tried that yet.
- A lot of people absolutely hate this stuff. There are plenty of reasons to dislike this technology—the environmental impact, the (lack of) ethics of the training data, the lack of reliability, the negative applications, the potential impact on people’s jobs.
Everything tagged “llms” on my blog in 2024
- January
- February
- March
- April
- May
- June
- July
- August
- September
- Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
- Notes from my appearance on the Software Misadventures Podcast
- Notes on OpenAI’s new o1 chain-of-thought models
- Notes on using LLMs for code
- NotebookLM’s automatically generated podcasts are surprisingly effective
- Weeknotes: Three podcasts, two trips and a new plugin system
- October
- OpenAI DevDay 2024 live blog
- OpenAI DevDay: Let’s build developer tools, not digital God
- ChatGPT will happily write you a thinly disguised horoscope
- Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
- Experimenting with audio input and output for the OpenAI Chat Completion API
- Running Llama 3.2 Vision and Phi-3.5 Vision on a Mac with mistral.rs
- Everything I built with Claude Artifacts this week
- Initial explorations of Anthropic’s new Computer Use capability
- Notes on the new Claude analysis JavaScript code execution tool
- Run a prompt to generate and execute jq programs using llm-jq
- You can now run prompts against images, audio and video in your terminal using LLM
- W̶e̶e̶k̶n̶o̶t̶e̶s̶ Monthnotes for October
- November
- December
- First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
- Prompts.js
- I can now run a GPT-4 class model on my laptop
- ChatGPT Canvas can make API requests now, but it’s complicated
- Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
- Building Python tools with a one-shot prompt using uv run and Claude Projects
- Gemini 2.0 Flash “Thinking mode”
- December in LLMs has been a lot
- Live blog: the 12th day of OpenAI—“Early evals for OpenAI o3”
- Trying out QvQ—Qwen’s new visual reasoning model
- Things we learned about LLMs in 2024