lLM articles

[platform_url]//console.mistral.ai/

Model architectures, data generation, training paradigms, and unified frameworks inspired by LLMs.

Anthropic launches real-time web search for Claude AI, challenging ChatGPT's dominance while securing $3.5 billion in funding at a $61.5 billion valuation.
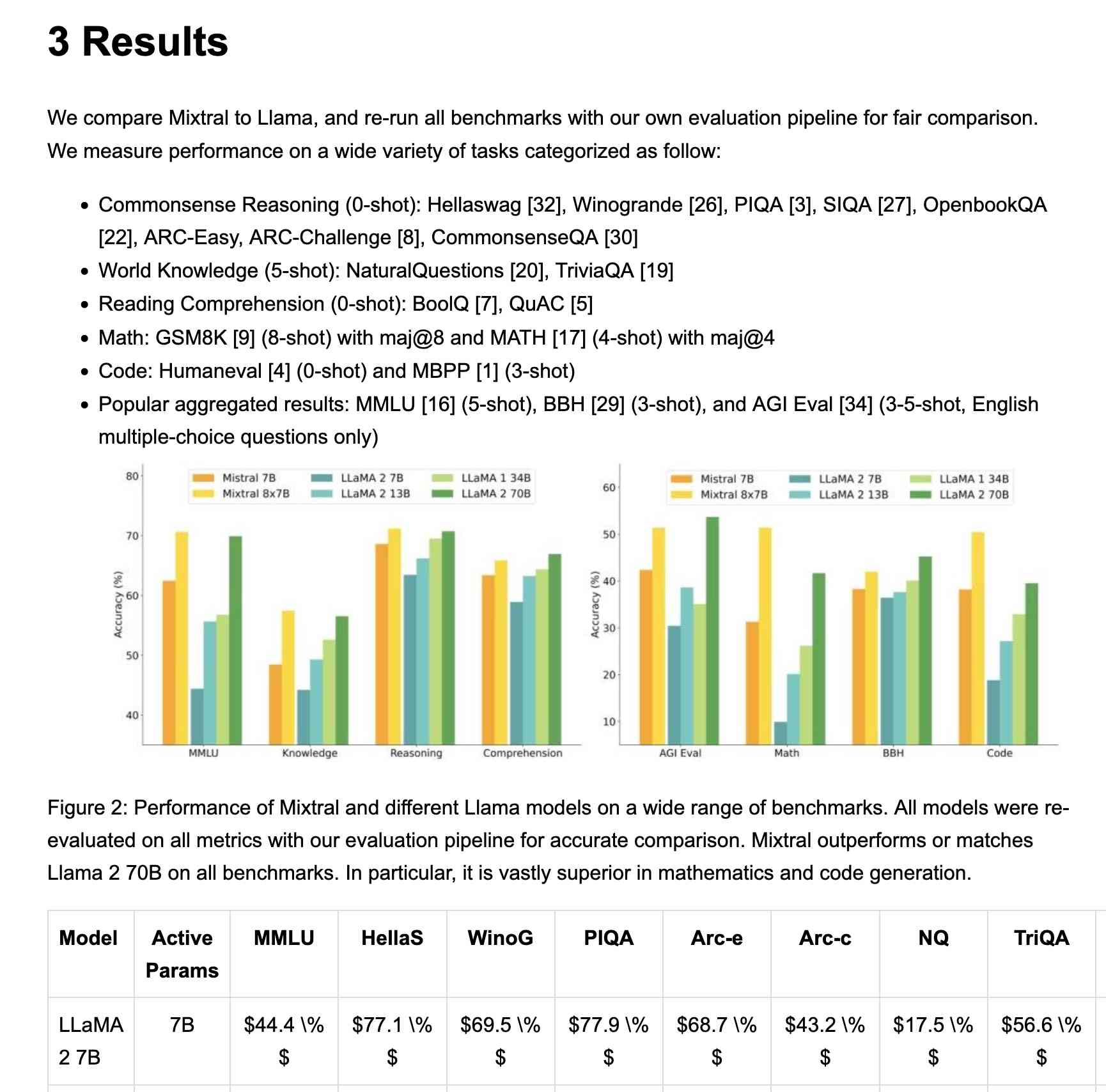
Paris-based artificial intelligence startup Mistral AI has announced the open-source release of its lightweight AI model, Mistral Small 3.1, which the company
Mistral Small 3 [came out in January](https://simonwillison.net/2025/Jan/30/mistral-small-3/) and was a notable, genuinely excellent local model that used an Apache 2.0 license. Mistral Small 3.1 offers a significant improvement: it's multi-modal …

The ellmer package for using LLMs with R is a game changer for scientists Why is ellmer a game changer for scientists? In this tutorial we’ll look at how we can access LLM agents through API calls. We’ll use this skill for created structued data fro...
Catastrophic Forgetting is a phenomenon where neural networks lose previously learned information when trained on new data, similar to human memory loss.

These models are free to use, can be fine-tuned, and offer enhanced privacy and security since they can run directly on your machine, and match the performance of proprietary solutions like o3-min and Gemini 2.0.
Model cards are documentation tools in machine learning that provide essential information about models, promoting transparency, trust, and ethical considerations in AI systems.
Plus CSS view transitions and a major update to llm-openrouter

Part 1: Inference-Time Compute Scaling Methods
New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images. It's available [via their API](https://docs.mistral.ai/api/#tag/ocr), or …
Introducing the world’s best document understanding API.
This release of the `llm-ollama` plugin adds support for [schemas](https://simonwillison.net/2025/Feb/28/llm-schemas/), thanks to a [PR by Adam Compton](https://github.com/taketwo/llm-ollama/pull/36). Ollama provides very robust support for this pattern thanks to their [structured outputs](https://ollama.com/blog/structured-outputs) …

Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.

OpenAI’s Deep Research is built for me, and I can’t use it. It’s another amazing demo, until it breaks. But it breaks in really interesting ways.

Solid techniques to get really good results from any LLM

OpenAI's president Greg Brockman recently shared this cool template for prompting their reasoning models o1/o3. Turns out, this is great for ANY reasoning… | 32 comments on LinkedIn

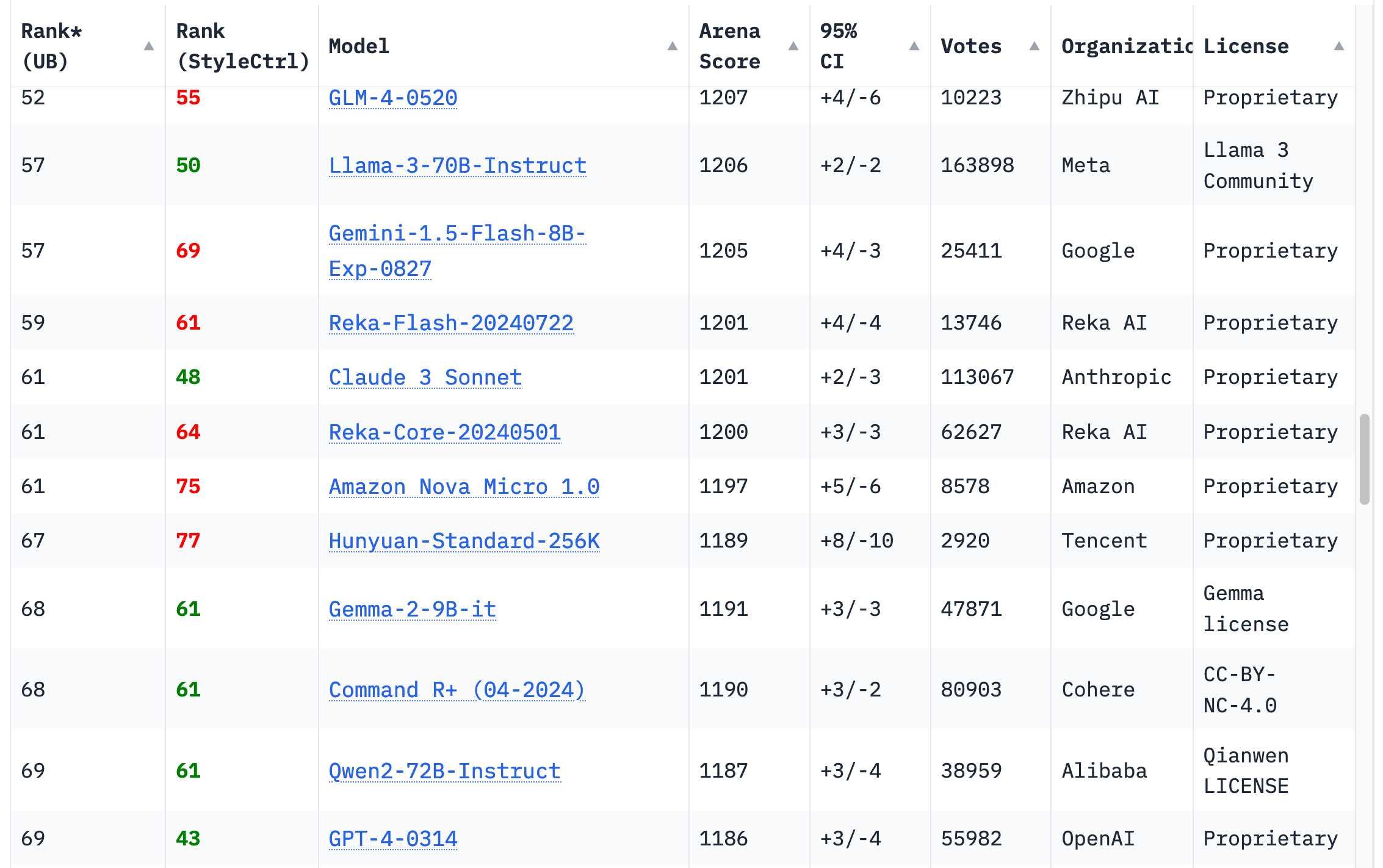
Comparison and ranking the performance of over 30 AI models (LLMs) across key metrics including quality, price, performance and speed (output speed - tokens per second & latency - TTFT), context window & others.

I share my preferences for LLMs, image models, AI video, AI music, AI-powered research, and more. These are the AI tools I regularly use or recommend to others.

A Step-by-Step Guide to Setting Up a Custom BPE Tokenizer with Tiktoken for Advanced NLP Applications in Python

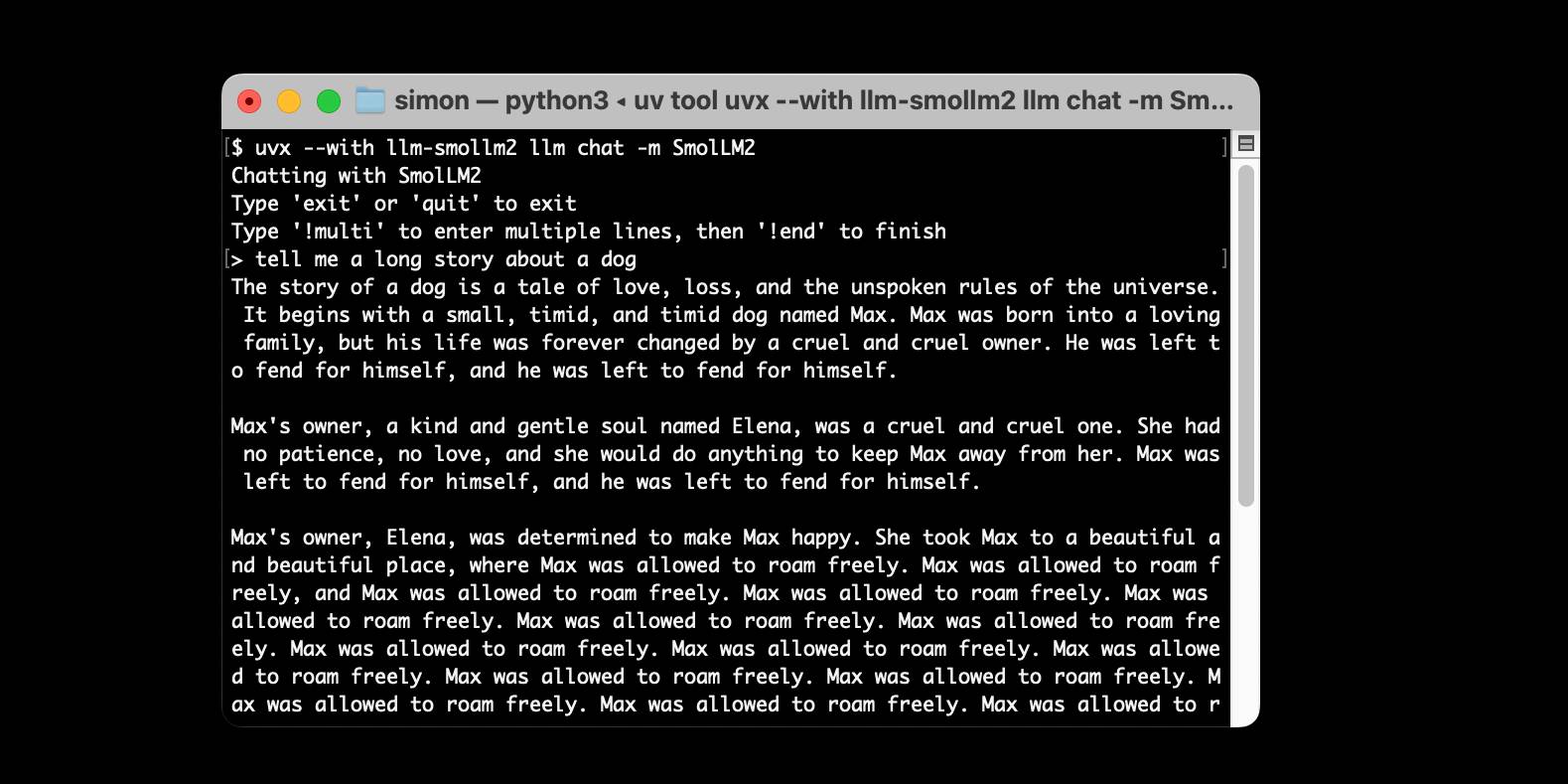
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package. This means you can now pip install …
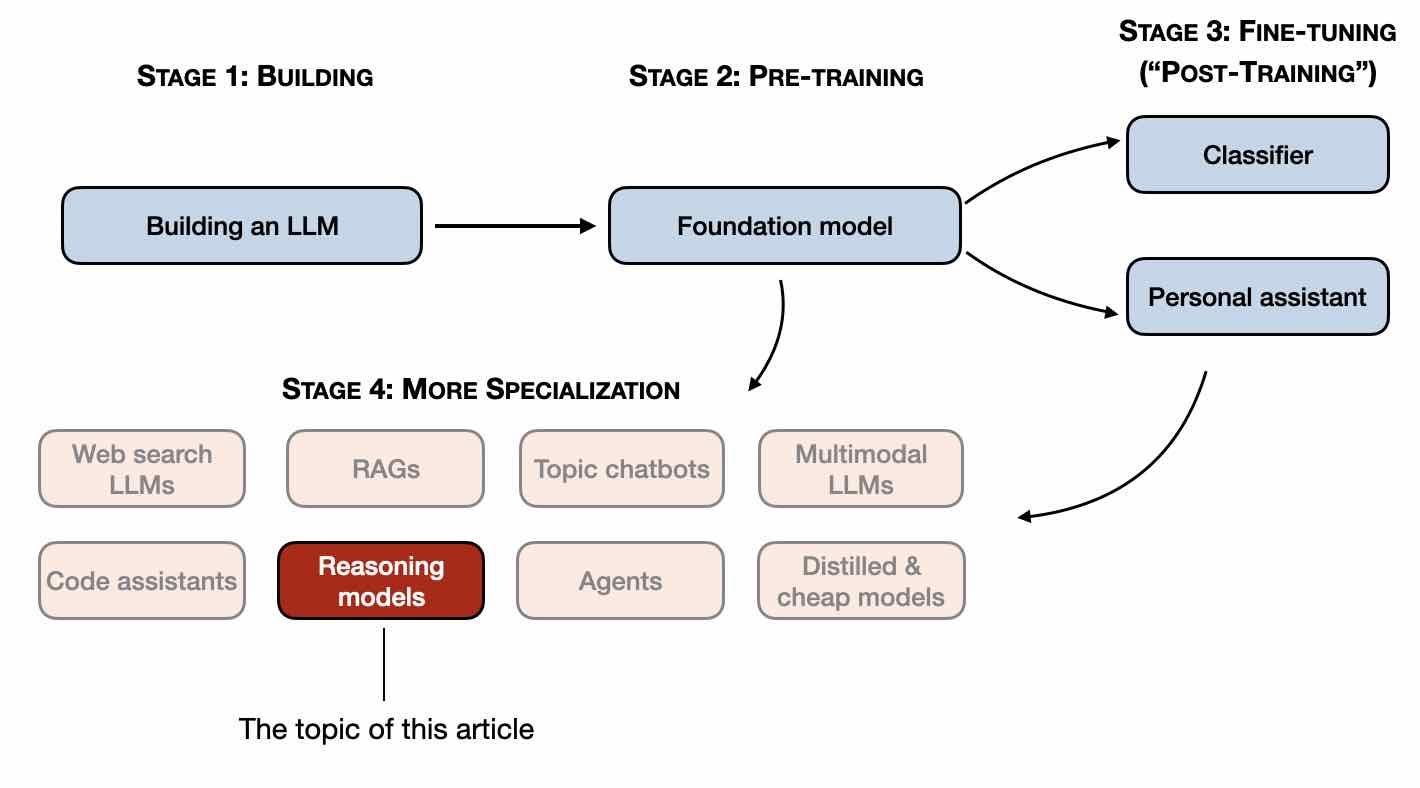
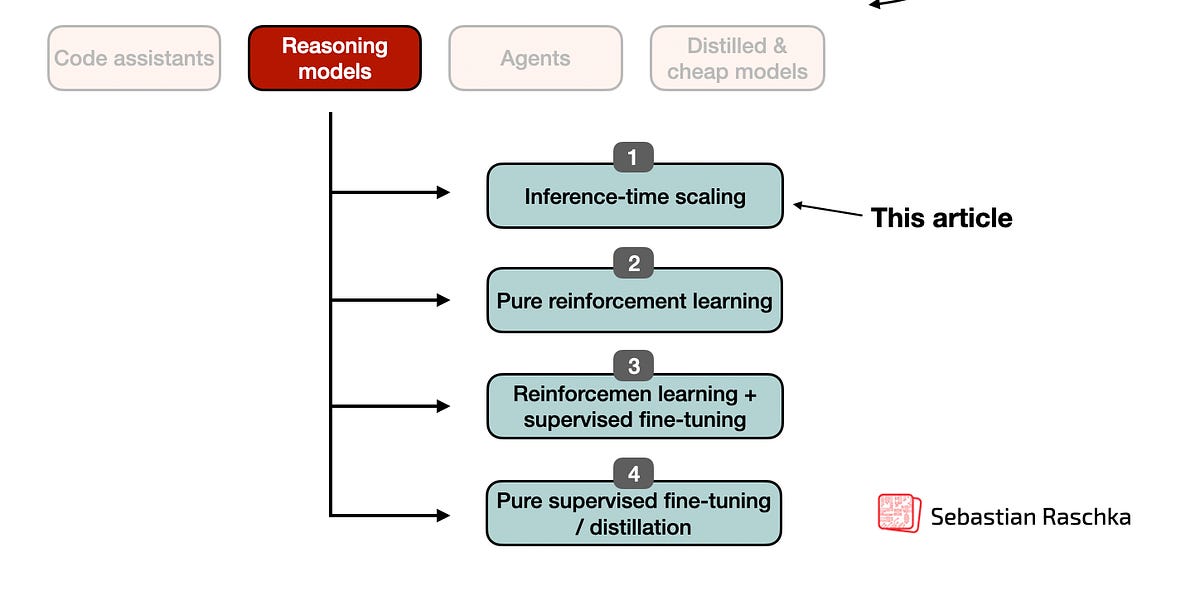
In this article, I will describe the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this p...

Check out this comparison of 5 AI frameworks to determine which you should choose.

The Reinforcement Learning from Human Feedback Book

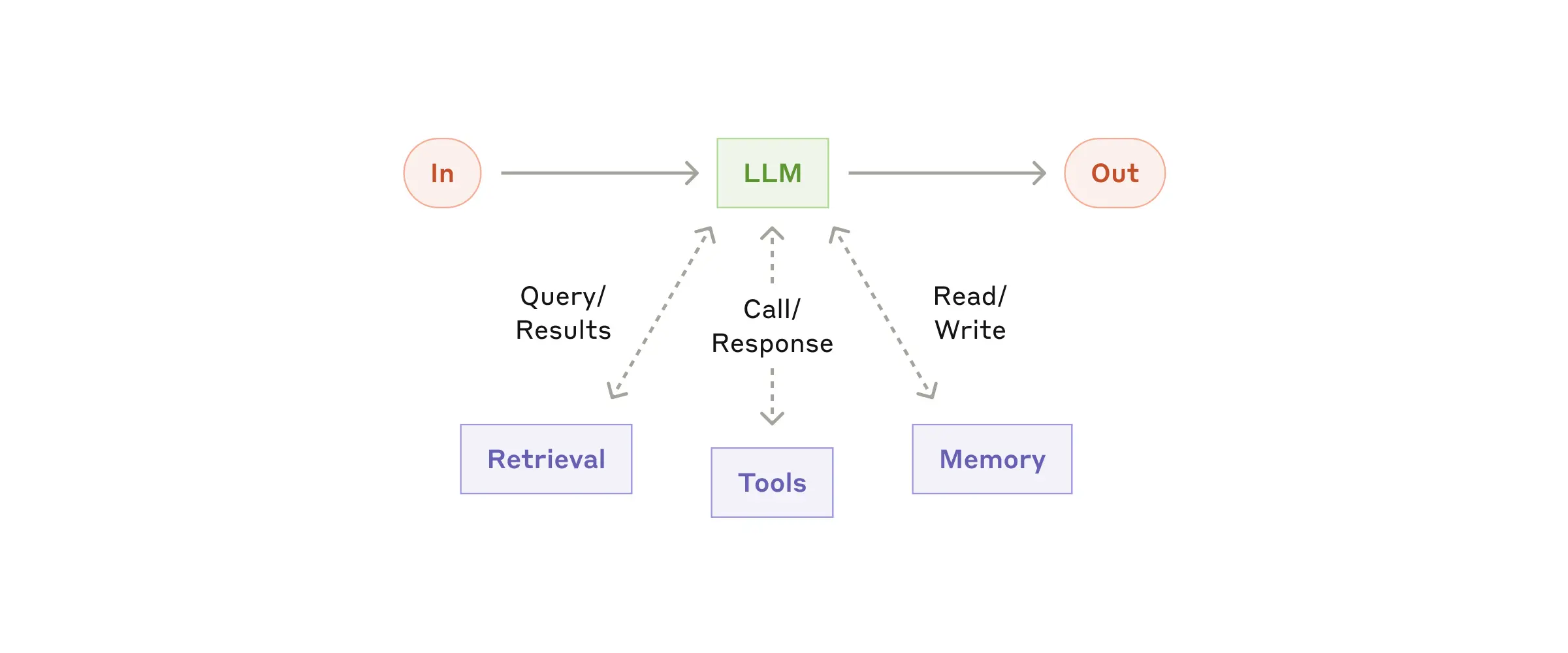
In our previous tutorial, we built an AI agent capable of answering queries by surfing the web. However, when building agents for longer-running tasks, two critical concepts come into play: persistence and streaming. Persistence allows you to save the state of an agent at any given point, enabling you to resume from that state in future interactions. This is crucial for long-running applications. On the other hand, streaming lets you emit real-time signals about what the agent is doing at any moment, providing transparency and control over its actions. In this tutorial, we’ll enhance our agent by adding these powerful
Aidan Bench attempts to measure in LLMs. - aidanmclaughlin/AidanBench
o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini …

How a Key-Value (KV) cache reduces Transformer inference time by trading memory for computation

The field of artificial intelligence is evolving rapidly, with increasing efforts to develop more capable and efficient language models. However, scaling these models comes with challenges, particularly regarding computational resources and the complexity of training. The research community is still exploring best practices for scaling extremely large models, whether they use a dense or Mixture-of-Experts (MoE) architecture. Until recently, many details about this process were not widely shared, making it difficult to refine and improve large-scale AI systems. Qwen AI aims to address these challenges with Qwen2.5-Max, a large MoE model pretrained on over 20 trillion tokens and further refined

The unusual timing of the Qwen 2.5-Max's release points to the pressure DeepSeek's meteoric rise in the past three weeks has placed on overseas rivals and domestic competition.


AI has entered an era of the rise of competitive and groundbreaking large language models and multimodal models. The development has two sides, one with open source and the other being propriety models. DeepSeek-R1, an open-source AI model developed by DeepSeek-AI, a Chinese research company, exemplifies this trend. Its emergence has challenged the dominance of proprietary models such as OpenAI’s o1, sparking discussions on cost efficiency, open-source innovation, and global technological leadership in AI. Let’s delve into the development, capabilities, and implications of DeepSeek-R1 while comparing it with OpenAI’s o1 system, considering the contributions of both spaces. DeepSeek-R1 DeepSeek-R1 is

Developers have tricks to stop artificial intelligence from making things up, but large language models are still struggling to tell the truth, the whole truth and nothing but the truth.
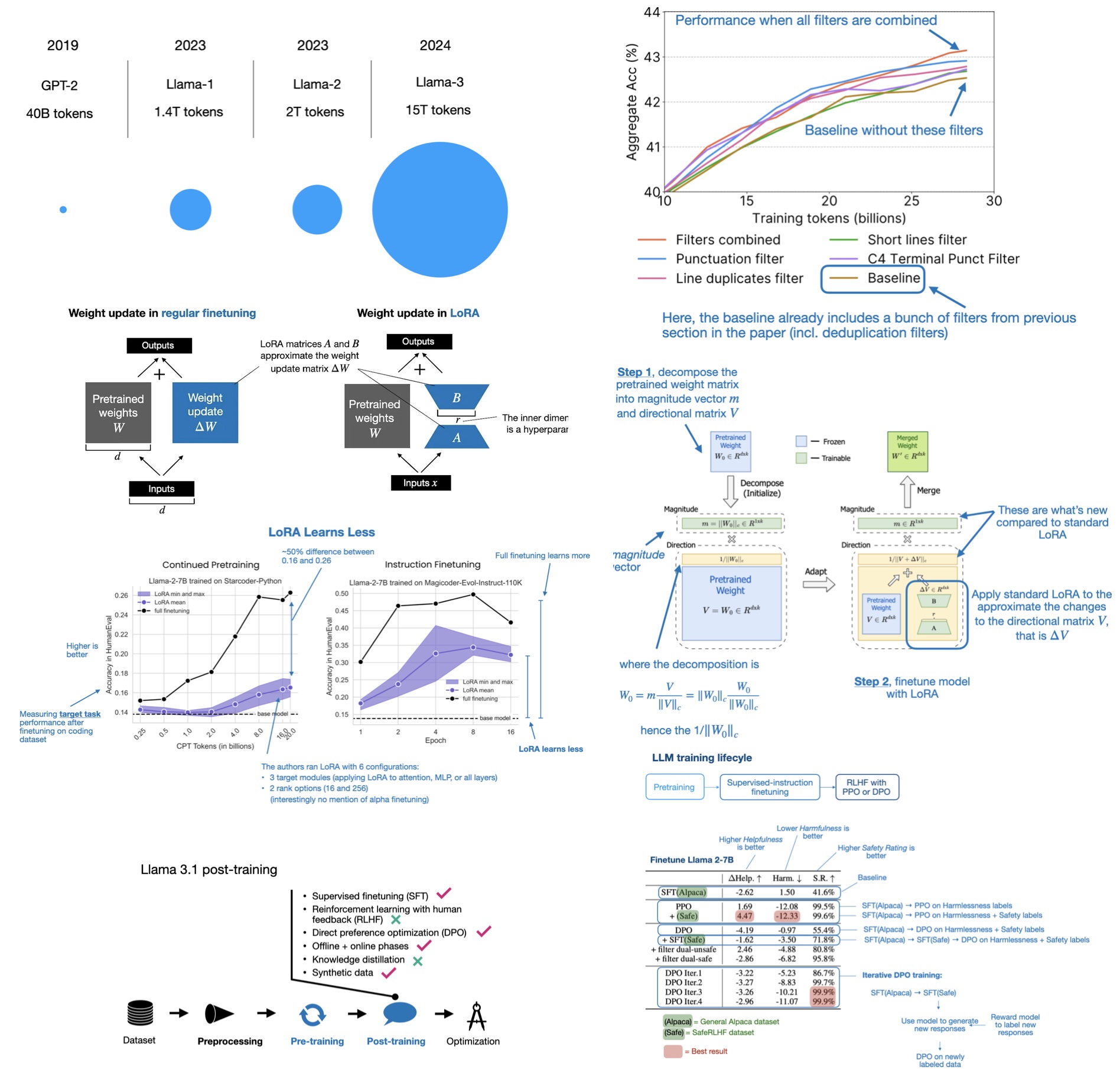
This article covers 12 influential AI research papers of 2024, ranging from mixture-of-experts models to new LLM scaling laws for precision..
New release of my [LLM](https://llm.datasette.io/) CLI tool and Python library. A bunch of accumulated fixes and features since the start of December, most notably: - Support for OpenAI's [o1 model](https://platform.openai.com/docs/models#o1) …

The company built a cheaper, competitive chatbot with fewer high-end computer chips than U.S. behemoths like Google and OpenAI, showing the limits of chip export control.

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 …

The rapid advancement and widespread adoption of generative AI systems across various domains have increased the critical importance of AI red teaming for evaluating technology safety and security. While AI red teaming aims to evaluate end-to-end systems by simulating real-world attacks, current methodologies face significant challenges in effectiveness and implementation. The complexity of modern AI systems, with their expanding capabilities across multiple modalities including vision and audio, has created an unprecedented array of potential vulnerabilities and attack vectors. Moreover, integrating agentic systems that grant AI models higher privileges and access to external tools has substantially increased the attack surface and
New paper from Microsoft describing their top eight lessons learned red teaming (deliberately seeking security vulnerabilities in) 100 different generative AI models and products over the past few years. …
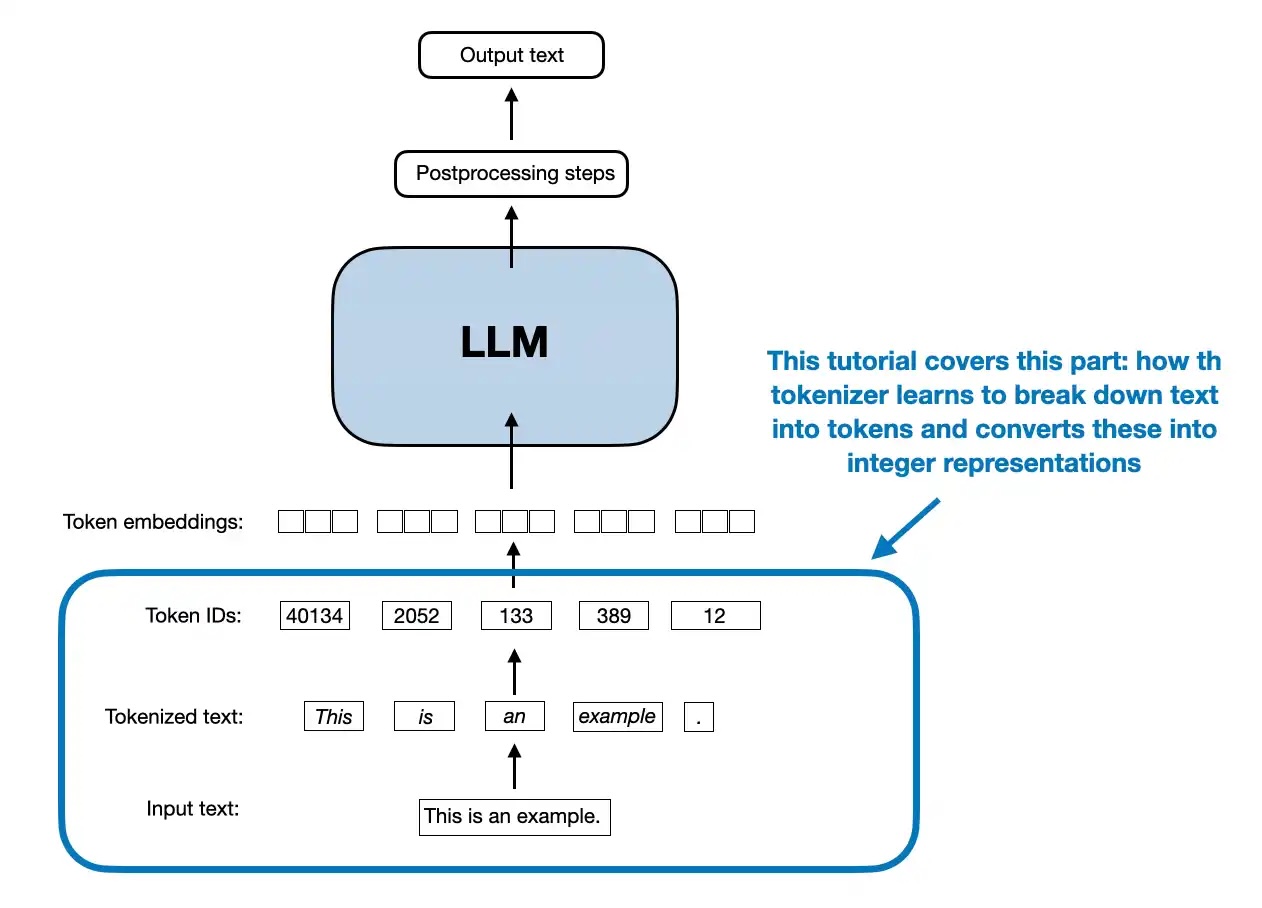
This is a standalone notebook implementing the popular byte pair encoding (BPE) tokenization algorithm, which is used in models like GPT-2 to GPT-4, Llama 3,...

Let’s start the year on an exciting note

We picked 50 paper/models/blogs across 10 fields in AI Eng: LLMs, Benchmarks, Prompting, RAG, Agents, CodeGen, Vision, Voice, Diffusion, Finetuning. If you're starting from scratch, start here.
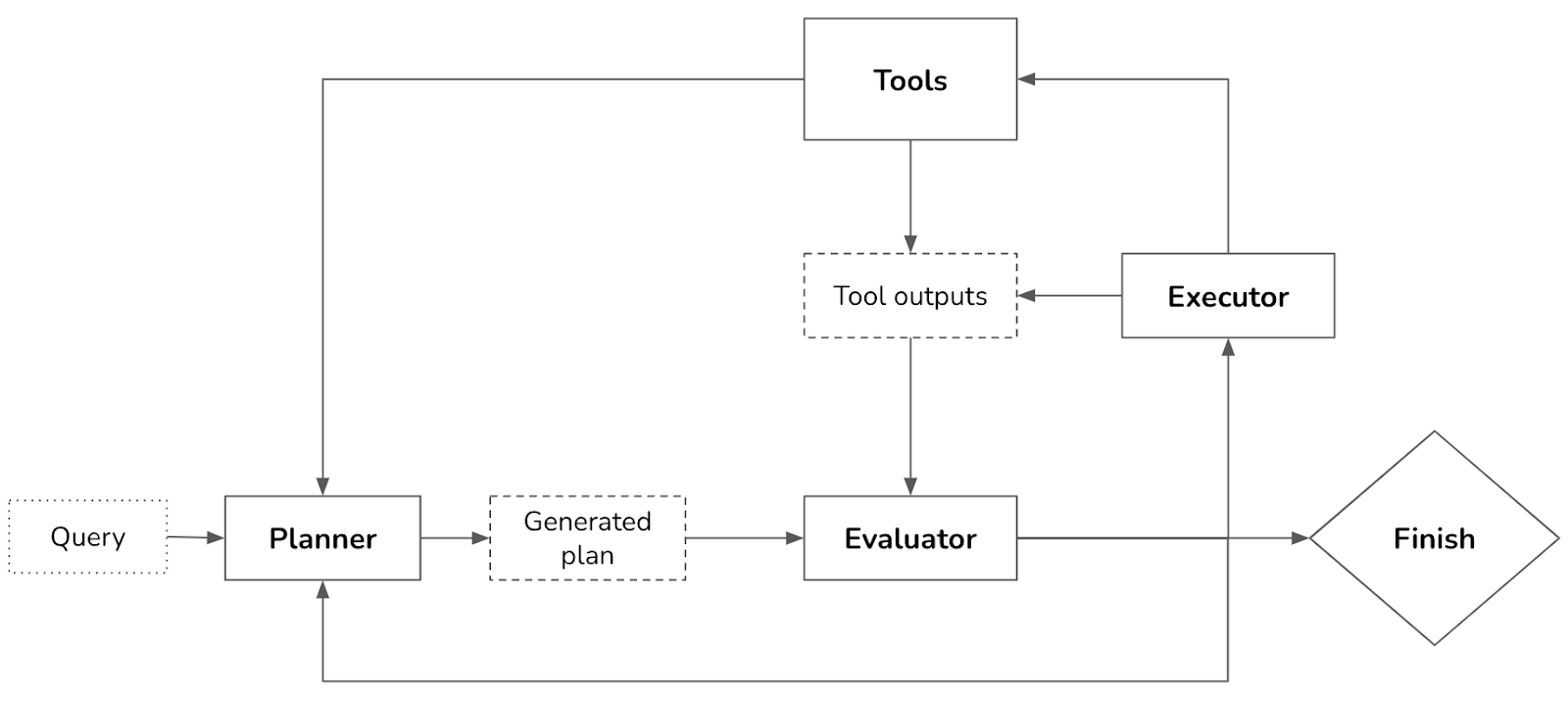
Intelligent agents are considered by many to be the ultimate goal of AI. The classic book by Stuart Russell and Peter Norvig, Artificial Intelligence: A Modern Approach (Prentice Hall, 1995), defines the field of AI research as “the study and design of rational agents.”
A comprehensive list of some of the most impactful generative papers from last year

[caption align=

Two powerful workflows that unlock everything else. Intro: Golden Age of AI Tools and AI agent frameworks begins in 2025.

A long reading list of evals papers with recommendations and comments by the evals team.

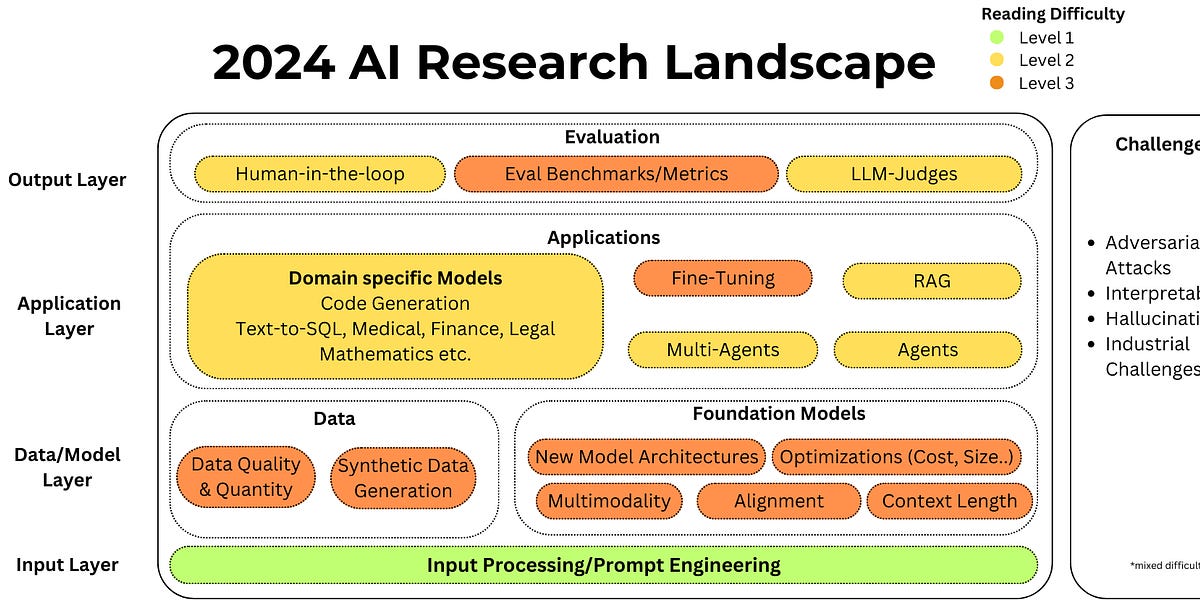
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past …
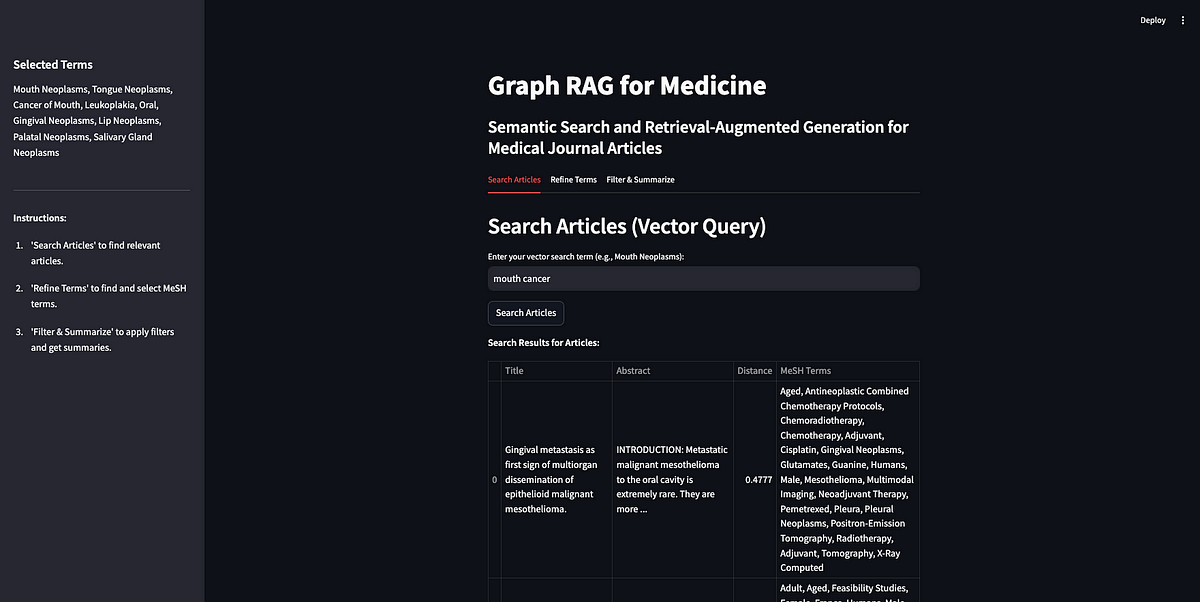
Using knowledge graphs and AI to retrieve, filter, and summarize medical journal articles
Plus building Python tools with a one-shot prompt using uv run and Claude Projects

A curated list of interesting LLM-related research papers from 2024, shared for those looking for something to read over the holidays.

Compute costs scale with the square of the input size. That’s not great.
Implement a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch

Large Language Models (LLMs) have become a cornerstone of artificial intelligence, driving advancements in natural language processing and decision-making tasks. However, their extensive power demands, resulting from high computational overhead and frequent external memory access, significantly hinder their scalability and deployment, especially in energy-constrained environments such as edge devices. This escalates the cost of operation while also limiting accessibility to these LLMs, which therefore calls for energy-efficient approaches designed to handle billion-parameter models. Current approaches to reduce the computational and memory needs of LLMs are based either on general-purpose processors or on GPUs, with a combination of weight quantization and

The artificial intelligence start-up said the new system, OpenAI o3, outperformed leading A.I. technologies on tests that rate skills in math, science, coding and logic.
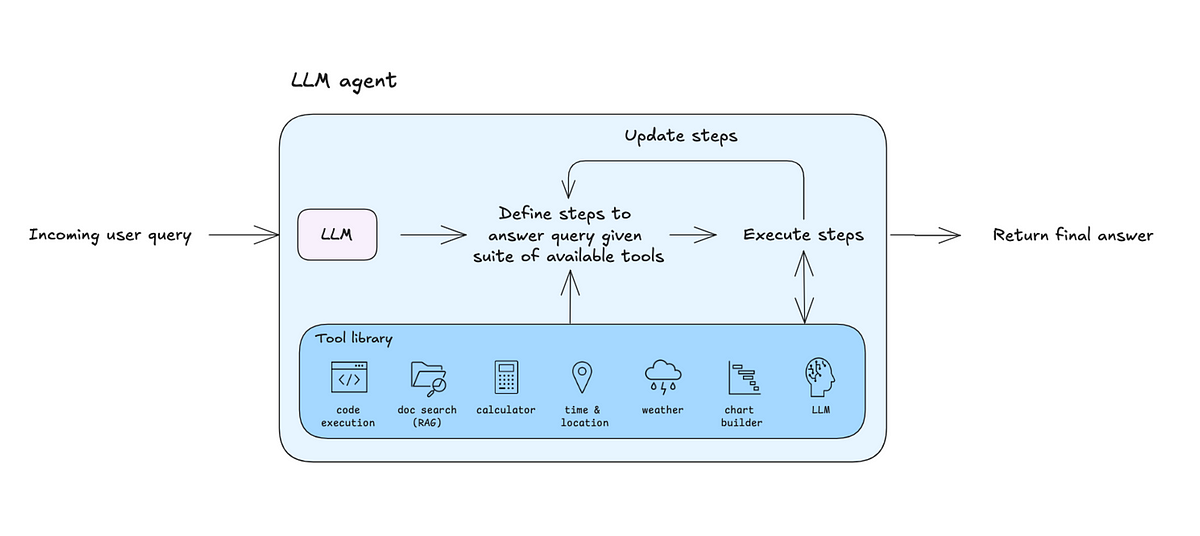
A post for developers with advice and workflows for building effective AI agents

Large Language Models (LLMs) have achieved remarkable advancements in natural language processing (NLP), enabling applications in text generation, summarization, and question-answering. However, their reliance on token-level processing—predicting one word at a time—presents challenges. This approach contrasts with human communication, which often operates at higher levels of abstraction, such as sentences or ideas. Token-level modeling also struggles with tasks requiring long-context understanding and may produce outputs with inconsistencies. Moreover, extending these models to multilingual and multimodal applications is computationally expensive and data-intensive. To address these issues, researchers at Meta AI have proposed a new approach: Large Concept Models (LCMs). Large Concept

Large language models (LLMs) can understand and generate human-like text by encoding vast knowledge repositories within their parameters. This capacity enables them to perform complex reasoning tasks, adapt to various applications, and interact effectively with humans. However, despite their remarkable achievements, researchers continue to investigate the mechanisms underlying the storage and utilization of knowledge in these systems, aiming to enhance their efficiency and reliability further. A key challenge in using large language models is their propensity to generate inaccurate, biased, or hallucinatory outputs. These problems arise from a limited understanding of how such models organize and access knowledge. Without clear

This blog explores a detailed comparison between the OpenAI API and LangChain, highlighting key differences in performance and developer experience and the low level code for why these differences exist.

Speed up your LLM inference

There has been an increasing amount of fear, uncertainty and doubt (FUD) regarding AI Scaling laws. A cavalcade of part-time AI industry prognosticators have latched on to any bearish narrative the…

It’s largely up to companies to test whether their AI is capable of superhuman harm. At Anthropic, the Frontier Red Team assesses the risk of catastrophe.

In large language models (LLMs), “hallucination” refers to instances where models generate semantically or syntactically plausible outputs but are factually incorrect or nonsensical. For example, a hallucination occurs when a model provides erroneous information, such as stating that Addison's disease causes “bright yellow skin” when, in fact, it causes fatigue and low blood pressure. This phenomenon is a significant concern in AI, as it can lead to the spread of false or misleading information. The issue of AI hallucinations has been explored in various research studies. A survey in “ACM Computing Surveys” describes hallucinations as “unreal perceptions that feel real.”

Compare AI models easily! All providers in one place.

LLMs are driving major advances in research and development today. A significant shift has been observed in research objectives and methodologies toward an LLM-centric approach. However, they are associated with high expenses, making LLMs for large-scale utilization inaccessible to many. It is, therefore, a significant challenge to reduce the latency of operations, especially in dynamic applications that demand responsiveness. KV cache is used for autoregressive decoding in LLMs. It stores key-value pairs in multi-headed attention during the pre-filling phase of inference. During the decoding stage, new KV pairs get appended to the memory. KV cache stores the intermediate key and

Kapa.ai turns your knowledge base into a reliable and production-ready LLM-powered AI assistant that answers technical questions instantly. Trusted by 100+ startups and enterprises incl. OpenAI, Docker, Mapbox, Mixpanel and NextJS.

Psst, kid, want some cheap and small LLMs?

The advent of LLMs has propelled advancements in AI for decades. One such advanced application of LLMs is Agents, which replicate human reasoning remarkably. An agent is a system that can perform complicated tasks by following a reasoning process similar to humans: think (solution to the problem), collect (context from past information), analyze(the situations and data), and adapt (based on the style and feedback). Agents encourage the system through dynamic and intelligent activities, including planning, data analysis, data retrieval, and utilizing the model's past experiences. A typical agent has four components: Brain: An LLM with advanced processing capabilities, such as
Notes from the Latent Space paper club. Follow along or start your own! - eugeneyan/llm-paper-notes
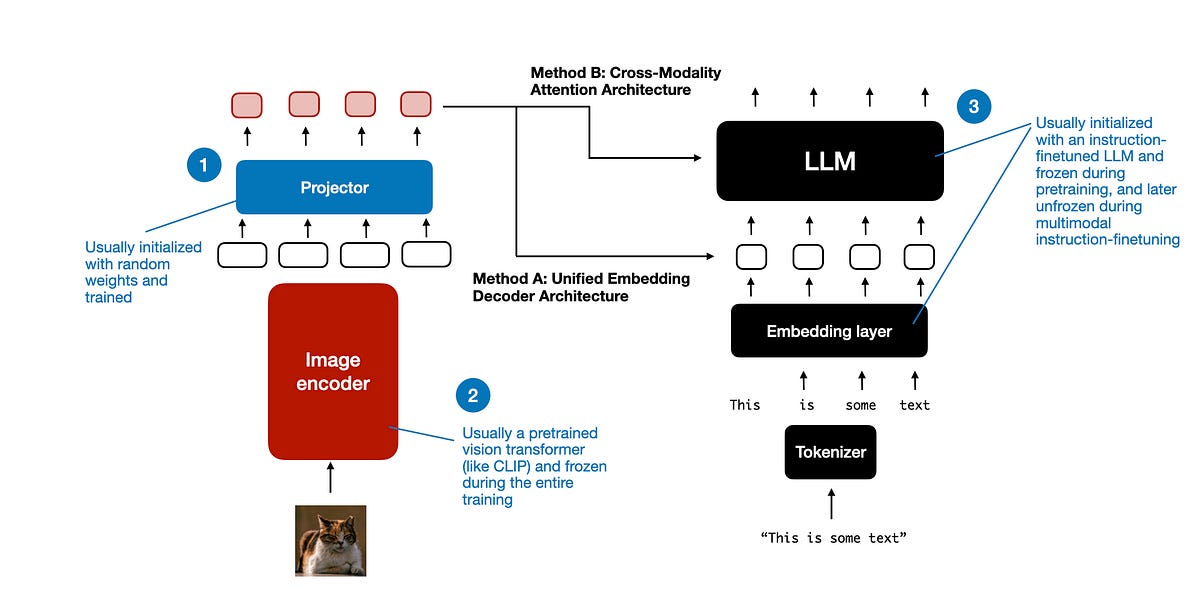
An introduction to the main techniques and latest models

Are they good or bad?
9 October 2024, Mathias Parisot, Jakub Zavrel.Even in the red hot global race for AI dominance, you publish and you perish, unless your peers pick up your work, build further on it, and you manage to drive real progress in the field. And of course, we are all very curious who is currently having that kind of impact. Are the billions of dollars spent on AI R&D paying off in the long run? So here is, in continuation of our popular publication impact analysis of last year, Zeta Alpha's ranking of t
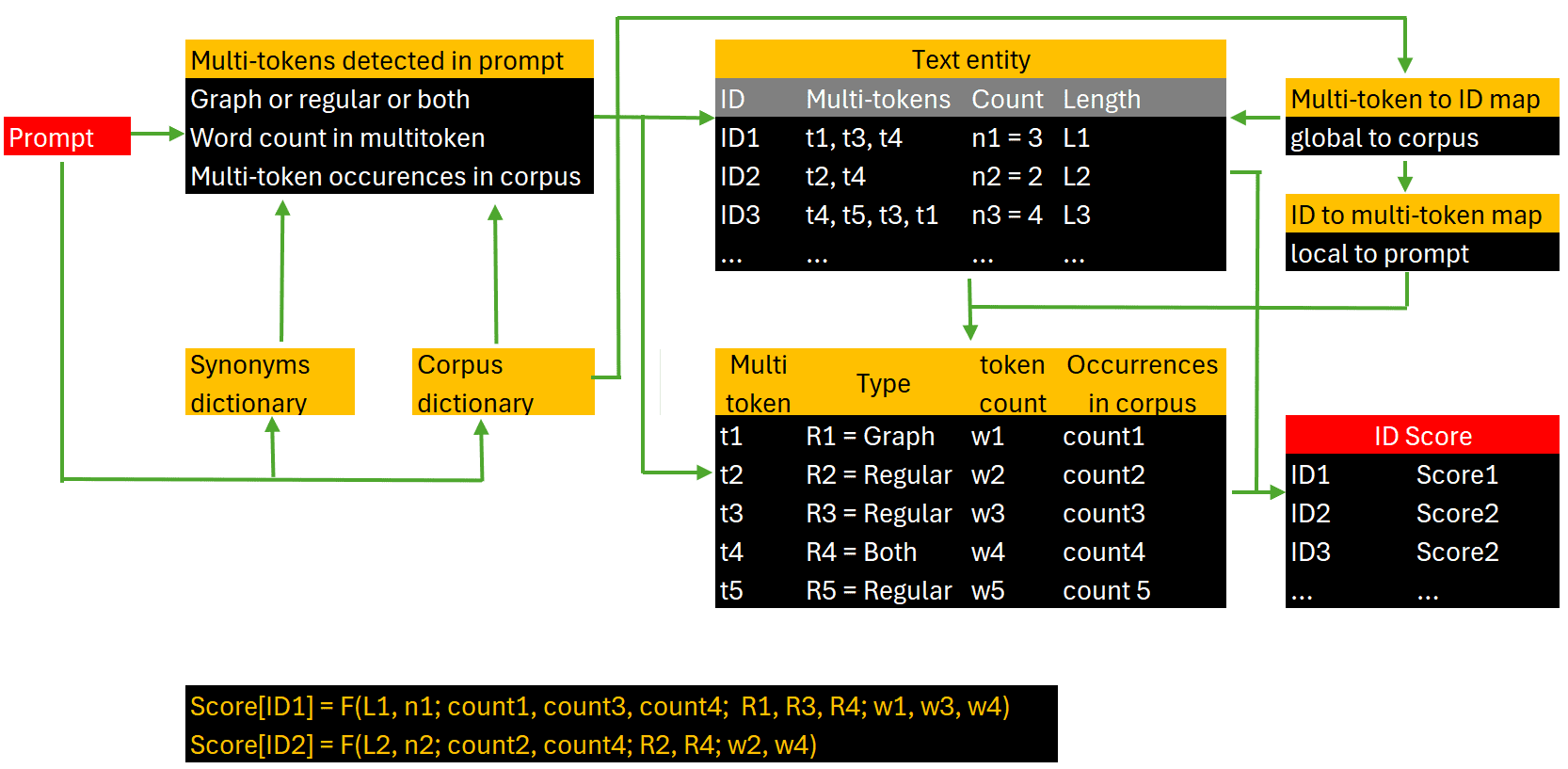
LLM Chunking, Indexing, Scoring and Agents, in a Nutshell. The new PageRank of RAG/LLM. With details on building relevancy scores.
A discussion of how Anthropic's researchers developed Claude's new computer use skill, along with some relevant safety considerations

In this article, I share the five essential LLM tools that I currently find indispensable, and which have the potential to help revolutionize the way you work.

Anthropic, the AI vendor second in size only to OpenAI, has a powerful family of generative AI models called Claude. These models can perform a range of

Nvidia quietly launched a groundbreaking AI model that surpasses OpenAI’s GPT-4 and Anthropic’s Claude 3.5, signaling a major shift in the competitive landscape of artificial intelligence.
Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch

Understanding the mechanistic interpretability research problem and reverse-engineering these large language models
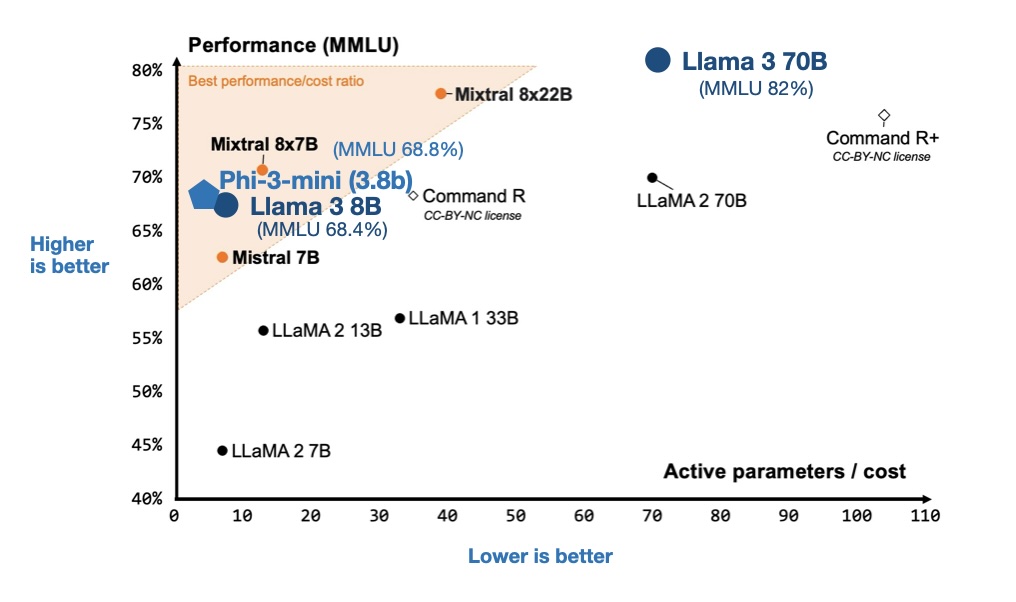
Llama 3.1 is the latest version of Meta's large language models, with a new model weight, 405 billion parameters, the biggest model it's trained.

The newly unveiled Llama 3.1 collection of 8B, 70B, and 405B large language models (LLMs) is narrowing the gap between proprietary and open-source models. Their open nature is attracting more…

Meta announced the release of Llama 3.1, the most capable model in the LLama Series. This latest iteration of the Llama series, particularly the 405B model, represents a substantial advancement in open-source AI capabilities, positioning Meta at the forefront of AI innovation. Meta has long advocated for open-source AI, a stance underscored by Mark Zuckerberg’s assertion that open-source benefits developers, Meta, and society. Llama 3.1 embodies this philosophy by offering state-of-the-art capabilities in an openly accessible model. The release aims to democratize AI, making cutting-edge technology available to various users and applications. The Llama 3.1 405B model stands out for

Meta llama 3.1 405b kicks off a fresh chapter for open-source language models. This breakthrough brings unmatched skills to AI
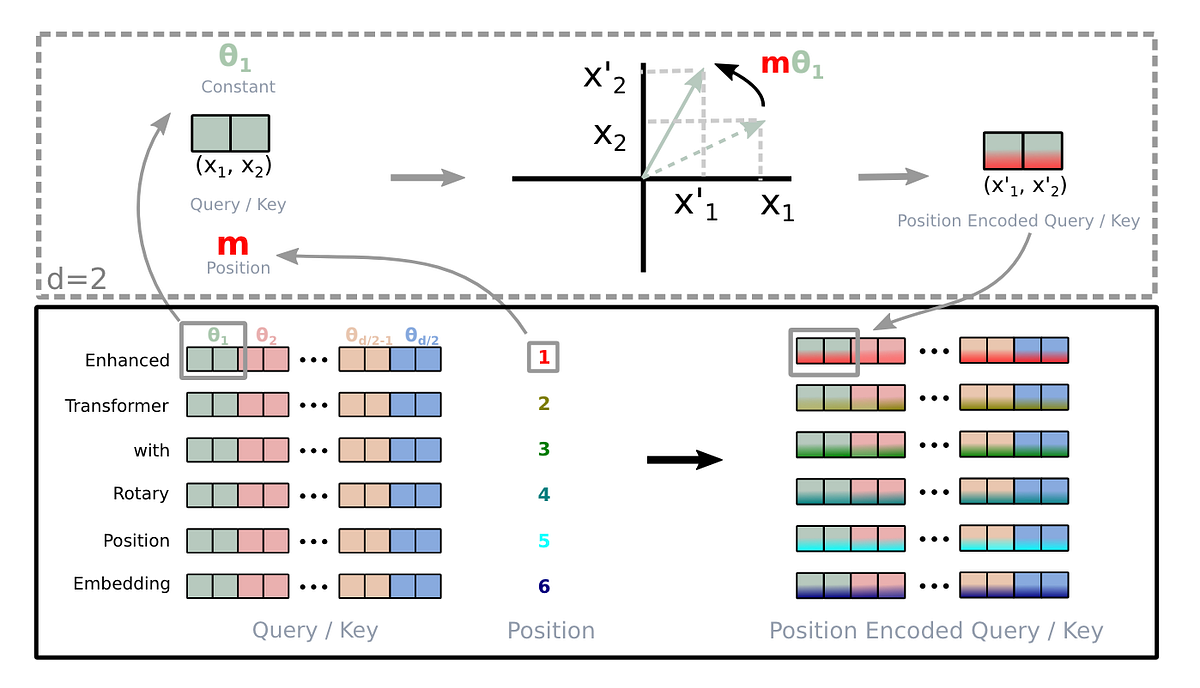
A deep dive into absolute, relative, and rotary positional embeddings with code examples

Introducing Claude 3.5 Sonnet—our most intelligent model yet. Sonnet now outperforms competitor models and Claude 3 Opus on key evaluations, at twice the speed.
In addition to its practical implications, recent work on “meaning representations” could shed light on some old philosophical questions.
Anyscale is the leading AI application platform. With Anyscale, developers can build, run and scale AI applications instantly.

We would like to thank Voltage Park, Dell, H5, and NVIDIA for their invaluable partnership and help with setting up our cluster. A special…

Experience the leading models to build enterprise generative AI apps now.

AI startup Gradient and cloud platform Crusoe teamed up to extend the context window of Meta's Llama 3 models to 1 million tokens.

In the developing field of Artificial Intelligence (AI), the ability to think quickly has become increasingly significant. The necessity of communicating with AI models efficiently becomes critical as these models get more complex. In this article we will explain a number of sophisticated prompt engineering strategies, simplifying these difficult ideas through straightforward human metaphors. The techniques and their examples have been discussed to see how they resemble human approaches to problem-solving. Chaining Methods Analogy: Solving a problem step-by-step. Chaining techniques are similar to solving an issue one step at a time. Chaining techniques include directing the AI via a systematic

Evaluating Large Language Models (LLMs) is a challenging problem in language modeling, as real-world problems are complex and variable. Conventional benchmarks frequently fail to fully represent LLMs' all-encompassing performance. A recent LinkedIn post has emphasized a number of important measures that are essential to comprehend how well new models function, which are as follows. MixEval Achieving a balance between thorough user inquiries and effective grading systems is necessary for evaluating LLMs. Conventional standards based on ground truth and LLM-as-judge benchmarks encounter difficulties such as biases in grading and possible contamination over time. MixEval solves these problems by combining real-world user

In the rapidly advancing field of Artificial Intelligence (AI), effective use of web data can lead to unique applications and insights. A recent tweet has brought attention to Firecrawl, a potent tool in this field created by the Mendable AI team. Firecrawl is a state-of-the-art web scraping program made to tackle the complex problems involved in getting data off the internet. Web scraping is useful, but it frequently requires overcoming various challenges like proxies, caching, rate limitations, and material generated with JavaScript. Firecrawl is a vital tool for data scientists because it addresses these issues head-on. Even without a sitemap,

We reproduce the GPT-2 (124M) from scratch. This video covers the whole process: First we build the GPT-2 network, then we optimize its training to be really fast, then we set up the training run following the GPT-2 and GPT-3 paper and their hyperparameters, then we hit run, and come back the next morning to see our results, and enjoy some amusing model generations. Keep in mind that in some places this video builds on the knowledge from earlier videos in the Zero to Hero Playlist (see my channel). You could also see this video as building my nanoGPT repo, which by the end is about 90% similar. Links: - build-nanogpt GitHub repo, with all the changes in this video as individual commits: https://github.com/karpathy/build-nanogpt - nanoGPT repo: https://github.com/karpathy/nanoGPT - llm.c repo: https://github.com/karpathy/llm.c - my website: https://karpathy.ai - my twitter: https://twitter.com/karpathy - our Discord channel: https://discord.gg/3zy8kqD9Cp Supplementary links: - Attention is All You Need paper: https://arxiv.org/abs/1706.03762 - OpenAI GPT-3 paper: https://arxiv.org/abs/2005.14165 - OpenAI GPT-2 paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf- The GPU I'm training the model on is from Lambda GPU Cloud, I think the best and easiest way to spin up an on-demand GPU instance in the cloud that you can ssh to: https://lambdalabs.com Chapters: 00:00:00 intro: Let’s reproduce GPT-2 (124M) 00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint 00:13:47 SECTION 1: implementing the GPT-2 nn.Module 00:28:08 loading the huggingface/GPT-2 parameters 00:31:00 implementing the forward pass to get logits 00:33:31 sampling init, prefix tokens, tokenization 00:37:02 sampling loop 00:41:47 sample, auto-detect the device 00:45:50 let’s train: data batches (B,T) → logits (B,T,C) 00:52:53 cross entropy loss 00:56:42 optimization loop: overfit a single batch 01:02:00 data loader lite 01:06:14 parameter sharing wte and lm_head 01:13:47 model initialization: std 0.02, residual init 01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms 01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms 01:39:38 float16, gradient scalers, bfloat16, 300ms 01:48:15 torch.compile, Python overhead, kernel fusion, 130ms 02:00:18 flash attention, 96ms 02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms 02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping 02:21:06 learning rate scheduler: warmup + cosine decay 02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms 02:34:09 gradient accumulation 02:46:52 distributed data parallel (DDP) 03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU) 03:23:10 validation data split, validation loss, sampling revive 03:28:23 evaluation: HellaSwag, starting the run 03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro 03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA 03:59:39 summary, phew, build-nanogpt github repo Corrections: I will post all errata and followups to the build-nanogpt GitHub repo (link above) SuperThanks: I experimentally enabled them on my channel yesterday. Totally optional and only use if rich. All revenue goes to to supporting my work in AI + Education.

Run an open source language model in your local machine and remotely.

Midjourney model personalization is now live, offering you a more tailored image generation experience by teaching the AI your preferences.

27 examples (with actual prompts) of how product managers are using Perplexity today
The linear representation hypothesis is the informal idea that semantic concepts are encoded as linear directions in the representation spaces of large language models (LLMs). Previous work has...


The ability to discern relevant and essential information from noise is paramount in AI, particularly within large language models (LLMs). With the surge of information and the complexity of tasks, there's a need for efficient mechanisms to enhance the performance and reliability of these models. Let’s explore the essential tools & techniques for refining LLMs and delivering precise, actionable insights. The focus will be on Retrieval-Augmented Generation (RAG), agentic functions, Chain of Thought (CoT) prompting, few-shot learning, prompt engineering, and prompt optimization. Retrieval-Augmented Generation (RAG): Providing Relevant Context RAG combines the power of retrieval mechanisms with generative models, ensuring that

Choosing large language models (LLMs) tailored for specific tasks is crucial for maximizing efficiency and accuracy. With natural language processing (NLP) advancements, different models have emerged, each excelling in unique domains. Here is a comprehensive guide to the most suitable LLMs for various activities in the AI world. Hard Document Understanding: Claude Opus Claude Opus excels at tasks requiring deep understanding and interpretation of complex documents. This model excels in parsing dense legal texts, scientific papers, and intricate technical manuals. Claude Opus is designed to handle extensive context windows, ensuring it captures nuanced details and complicated relationships within the text.

Apply these techniques when crafting prompts for large language models to elicit more relevant responses.

In most cases, Perplexity produced the desired Pages, but what we found missing was the option to edit the content manually.

We tested OpenAI’s ChatGPT against Microsoft’s Copilot and Google’s Gemini, along with Perplexity and Anthropic’s Claude. Here’s how they ranked.

if the centralizing forces of data and compute hold, open and closed-source AI cannot both dominate long-term

Vision-language models (VLMs), capable of processing both images and text, have gained immense popularity due to their versatility in solving a wide range of tasks, from information retrieval in scanned documents to code generation from screenshots. However, the development of these powerful models has been hindered by a lack of understanding regarding the critical design choices that truly impact their performance. This knowledge gap makes it challenging for researchers to make meaningful progress in this field. To address this issue, a team of researchers from Hugging Face and Sorbonne Université conducted extensive experiments to unravel the factors that matter the

What goes on in artificial neural networks work is largely a mystery, even to their creators. But researchers from Anthropic have caught a glimpse.
llama3 implementation one matrix multiplication at a time - naklecha/llama3-from-scratch

Artificial intelligence (AI) has revolutionized various fields by introducing advanced models for natural language processing (NLP). NLP enables computers to understand, interpret, and respond to human language in a valuable way. This field encompasses text generation, translation, and sentiment analysis applications, significantly impacting industries like healthcare, finance, and customer service. The evolution of NLP models has driven these advancements, continually pushing the boundaries of what AI can achieve in understanding and generating human language. Despite these advancements, developing models that can effectively handle complex multi-turn conversations remains a persistent challenge. Existing models often fail to maintain context and coherence over

Now that LLMs can retrieve 1 million tokens at once, how long will it be until we don’t need retrieval augmented generation for accurate AI responses?
What a month! We had four major open LLM releases: Mixtral, Meta AI's Llama 3, Microsoft's Phi-3, and Apple's OpenELM. In my new article, I review and discus...

The capacity of large language models (LLMs) to produce adequate text in various application domains has caused a revolution in natural language creation. These models are essentially two types: 1) Most model weights and data sources are open source. 2) All model-related information is publicly available, including training data, data sampling ratios, training logs, intermediate checkpoints, and assessment methods (Tiny-Llama, OLMo, and StableLM 1.6B). Full access to open language models for the research community is vital for thoroughly investigating these models' capabilities and limitations and understanding their inherent biases and potential risks. This is necessary despite the continued breakthroughs in
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a...

Generative AI (GenAI) tools have come a long way. Believe it or not, the first generative AI tools were introduced in the 1960s in a Chatbot. Still, it was only in 2014 that generative adversarial networks (GANs) were introduced, a type of Machine Learning (ML) algorithm that allowed generative AI to finally create authentic images, videos, and audio of real people. In 2024, we can create anything imaginable using generative AI tools like ChatGPT, DALL-E, and others. However, there is a problem. We can use those AI tools but can not get the most out of them or use them

As part of data preparation for an NLP model, it’s common to need to clean up your data prior to passing it into the model. If there’s unwanted content in your output, for example, it could impact the quality of your NLP model. To help with this, the `unstructured` library includes cleaning functions to help users sanitize output before sending it to downstream applications.
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results...

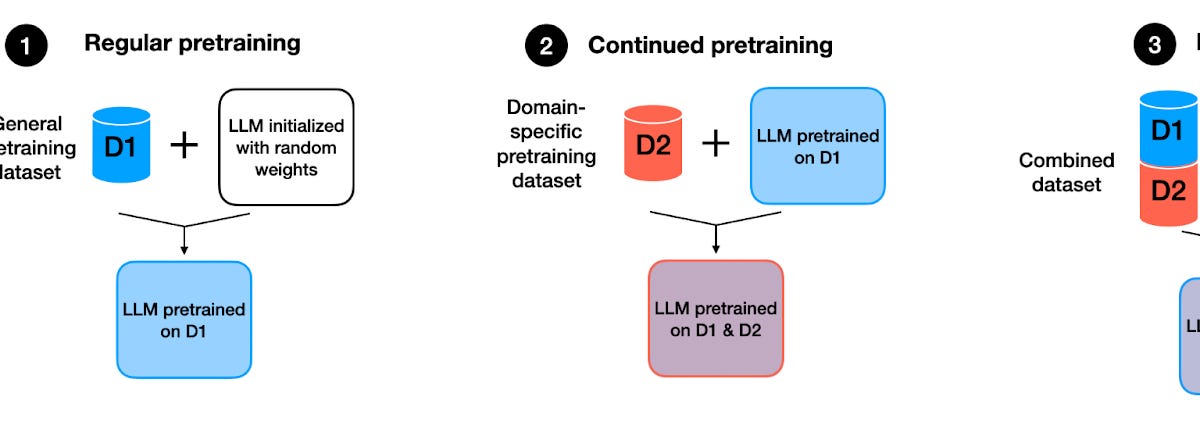
The rapid evolution in AI demands models that can handle large-scale data and deliver accurate, actionable insights. Researchers in this field aim to create systems capable of continuous learning and adaptation, ensuring they remain relevant in dynamic environments. A significant challenge in developing AI models lies in overcoming the issue of catastrophic forgetting, where models fail to retain previously acquired knowledge when learning new tasks. This challenge becomes more pressing as applications increasingly demand continuous learning capabilities. For instance, models must update their understanding of healthcare, financial analysis, and autonomous systems while retaining prior knowledge to make informed decisions. The

We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Are you curious about the intricate world of large language models (LLMs) and the technical jargon that surrounds them? Understanding the terminology, from the foundational aspects of training and fine-tuning to the cutting-edge concepts of transformers and reinforcement learning, is the first step towards demystifying the powerful algorithms that drive modern AI language systems. In this article, we delve into 25 essential terms to enhance your technical vocabulary and provide insights into the mechanisms that make LLMs so transformative. Heatmap representing the relative importance of terms in the context of LLMs Source: marktechpost.com 1. LLM (Large Language Model) Large Language

Prompt Fuzzer: The Prompt Fuzzer is an interactive tool designed to evaluate the security of GenAI application system prompts by simulating various dynamic LLM-based attacks. It assesses security by analyzing the results of these simulations, helping users fortify their system prompts accordingly. This tool specifically customizes its tests to fit the unique configuration and domain of the user's application. The Fuzzer also features a Playground chat interface, allowing users to refine their system prompts iteratively, enhancing their resilience against a broad range of generative AI attacks. Users should be aware that using the Prompt Fuzzer will consume tokens. Garak: Garak
/cdn.vox-cdn.com/uploads/chorus_asset/file/23951355/STK043_VRG_Illo_N_Barclay_1_Meta.jpg)
The models have some pretty good general knowledge.
A collection of notebooks/recipes showcasing some fun and effective ways of using Claude. - anthropics/anthropic-cookbook

Deep learning architectures have revolutionized the field of artificial intelligence, offering innovative solutions for complex problems across various domains, including computer vision, natural language processing, speech recognition, and generative models. This article explores some of the most influential deep learning architectures: Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), Transformers, and Encoder-Decoder architectures, highlighting their unique features, applications, and how they compare against each other. Convolutional Neural Networks (CNNs) CNNs are specialized deep neural networks for processing data with a grid-like topology, such as images. A CNN automatically detects the important features without any human supervision.
Discussing AI Research Papers in March 2024
My startup Truss (gettruss.io) released a few LLM-heavy features in the last six months, and the narrative around LLMs that I read on Hacker News is now starting to diverge from my reality, so I thought I’d share some of the more “surprising” lessons after churning through just north of 500 million tokens, by my […]

Run large language models on your local PC for customized AI capabilities with more control, privacy, and personalization.

Gemini 1.5 Pro launch, new version of GPT-4 Turbo, new Mistral model, and more.


We are seeing some clear categories emerge in the world of LLMs - 1) affordable (~$1 per million tokens); 2) mid-range ($8/m) and 3) top end ($25-50/m)… | 32 comments on LinkedIn

In the world of LLMs, there is a phenomenon known as "hallucinations." These hallucinations are...

The top open source Large Language Models available for commercial use are as follows. Llama - 2 Meta released Llama 2, a set of pretrained and refined LLMs, along with Llama 2-Chat, a version of Llama 2. These models are scalable up to 70 billion parameters. It was discovered after extensive testing on safety and helpfulness-focused benchmarks that Llama 2-Chat models perform better than current open-source models in most cases. Human evaluations have shown that they align well with several closed-source models. The researchers have even taken a few steps to guarantee the security of these models. This includes annotating

I wrote 84 new matmul kernels to improve llamafile CPU performance.
Researchers find large language models use a simple mechanism to retrieve stored knowledge when they respond to a user prompt. These mechanisms can be leveraged to see what the model knows about different subjects and possibly to correct false information it has stored.


What is ChatGPT? ChatGPT, developed by OpenAI, is an AI platform renowned for its conversational AI capabilities. Leveraging the power of the Generative Pre-trained Transformer models, ChatGPT generates human-like text responses across various topics, from casual conversations to complex, technical discussions. Its ability to engage users with coherent, contextually relevant dialogues stands out, making it highly versatile for various applications, including content creation, education, customer service, and more. Its integration with tools like DALL-E for image generation from textual descriptions and its continual updates for enhanced performance showcase its commitment to providing an engaging and innovative user experience. ChatGPT Key

Is Attention all you need? Mamba, a novel AI model based on State Space Models (SSMs), emerges as a formidable alternative to the widely used Transformer models, addressing their inefficiency in processing long sequences.
We like datacenter compute engines here at The Next Platform, but as the name implies, what we really like are platforms – how compute, storage,

Large language models do better at solving problems when they show their work. Researchers are beginning to understand why.
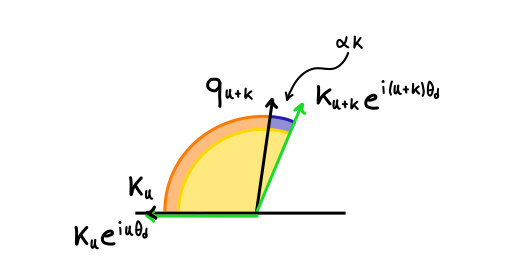
Language models (LLMs) have revolutionized the field of natural language processing (NLP) over the last few years, achieving…

Reference architecture patterns and mental models for working with Large Language Models (LLM’s)
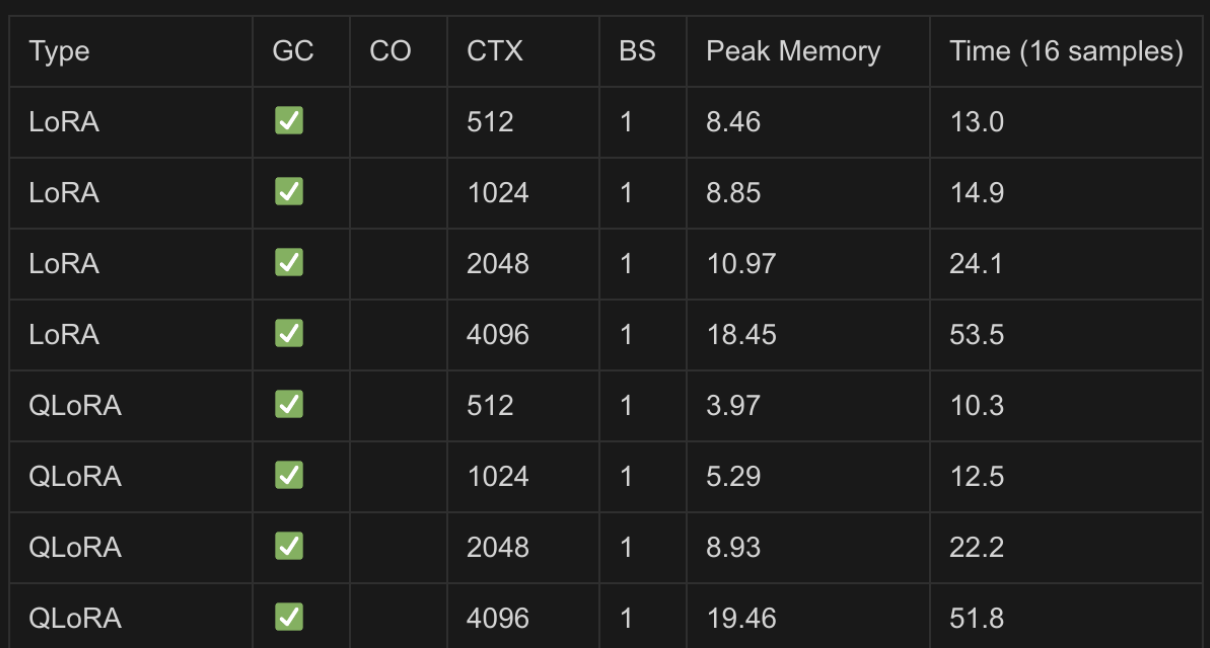
We’re releasing an open source system, based on FSDP and QLoRA, that can train a 70b model on two 24GB GPUs.

Training a specialized LLM over your own data is easier than you think…
The search giant is unifying its AI-assistant efforts under one name and trying to show it can match rivals.

Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three… | 429 comments on LinkedIn
The Amazon-backed AI startup said its "most intelligent model" outperformed OpenAI's powerful GPT-4
Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch

Understanding how well they comprehend and organize information is crucial in advanced language models. A common challenge arises in visualizing the intricate relationships between different document parts, especially when using complex models like the Retriever-Answer Generator (RAG). Existing tools can only sometimes provide a clear picture of how chunks of information relate to each other and specific queries. Several attempts have been made to address this issue, but they often need to deliver the need to provide an intuitive and interactive solution. These tools need help breaking down documents into manageable pieces and visualizing their semantic landscape effectively. As a

Step into the future of video creation with Google Lumiere, the latest breakthrough from Google Research that promises to redefine
Keep up with the latest ML research
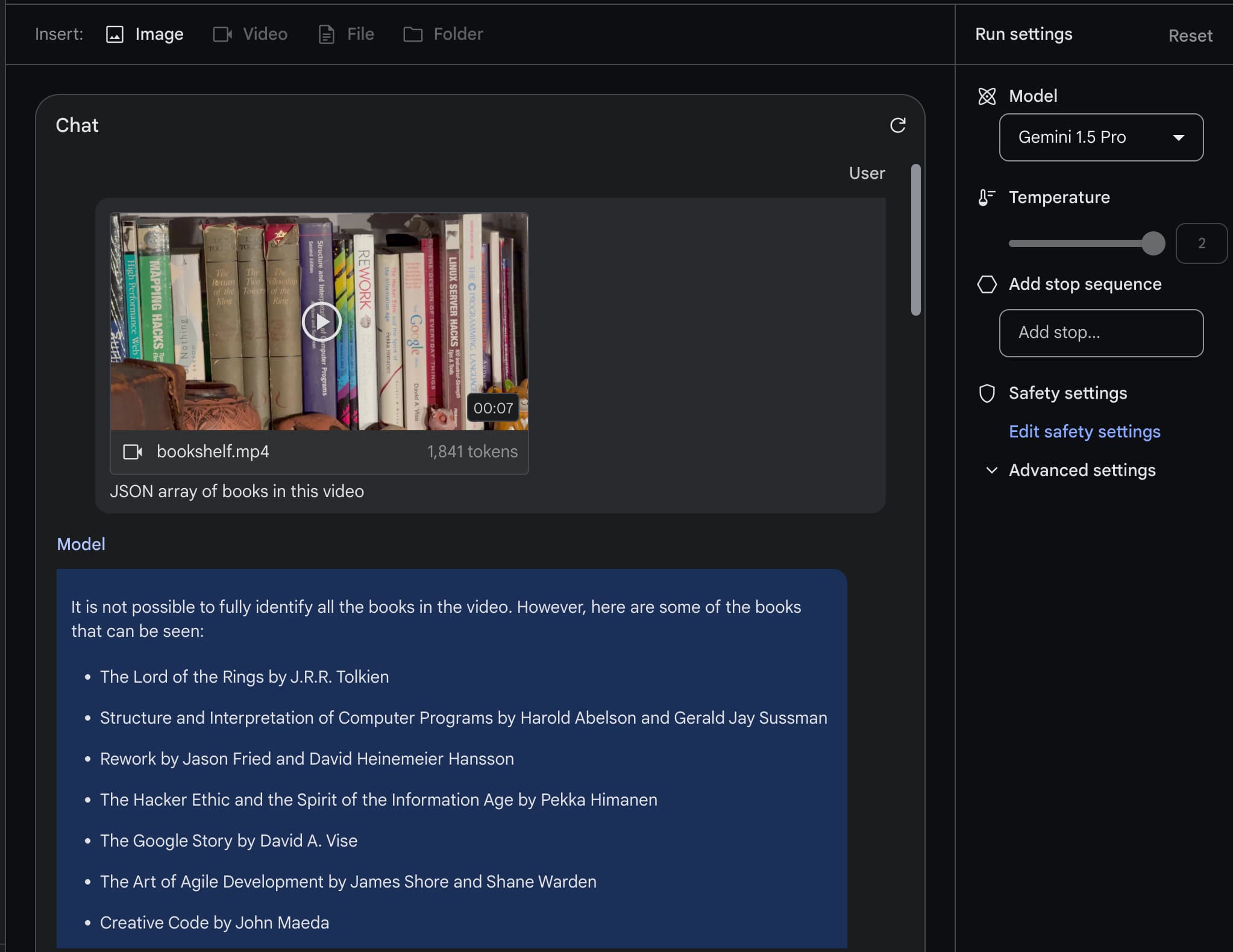
Last week Google introduced Gemini Pro 1.5, an enormous upgrade to their Gemini series of AI models. Gemini Pro 1.5 has a 1,000,000 token context size. This is huge—previously that …

This blog post will look at the “Direct Preference Optimization: Your Language Model is Secretly a Reward Model” paper and its findings.

When it comes to context windows, size matters
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single...

Are you looking for the news everyday for Sora early access like us? Well you are absolutely right because OpenAI's
Mistral Large is our flagship model, with top-tier reasoning capacities. It is also available on Azure.

A deep dive into the internals of a small transformer model to learn how it turns self-attention calculations into accurate predictions for the next token.
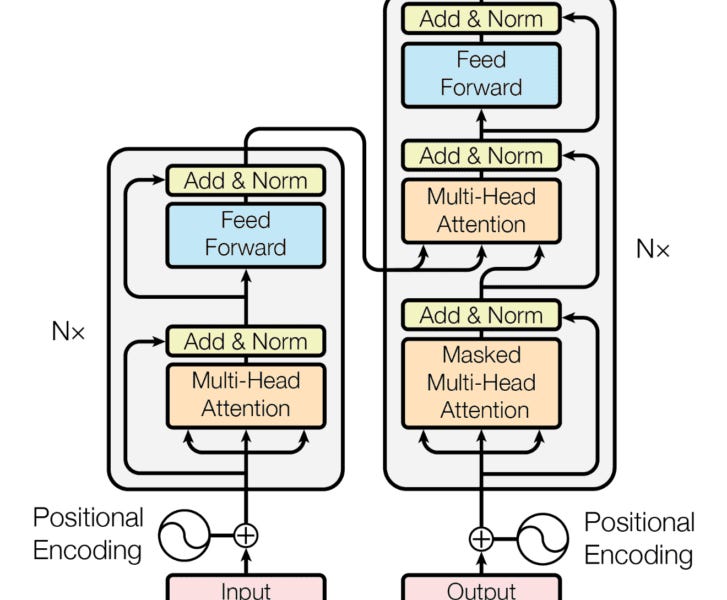
We will deep dive into understanding how transformer model work like BERT(Non-mathematical Explanation of course!). system design to use the transformer to build a Sentiment Analysis

Faster than Nvidia? Dissecting the economics

In artificial intelligence, the capacity of Large Language Models (LLMs) to negotiate mirrors a leap toward achieving human-like interactions in digital negotiations. At the heart of this exploration is the NEGOTIATION ARENA, a pioneering framework devised by researchers from Stanford University and Bauplan. This innovative platform delves into the negotiation prowess of LLMs, offering a dynamic environment where AI can mimic, strategize, and engage in nuanced dialogues across a spectrum of scenarios, from splitting resources to intricate trade and price negotiations. The NEGOTIATION ARENA is a tool and a gateway to understanding how AI can be shaped to think, react,

Sora is an AI model that can create realistic and imaginative scenes from text instructions.
LoRA (Low-Rank Adaptation) is a popular technique to finetune LLMs more efficiently. This Studio explains how LoRA works by coding it from scratch, which is an excellent exercise for looking under …

AI community is once again filled with excitement as Bard is now Gemini and Gemini Advanced offering users an exceptional
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language...

Zephyr is a series of Large Language Models released by Hugging Face trained using distilled supervised fine-tuning (dSFT) on larger models with significantly improved task accuracy.
LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
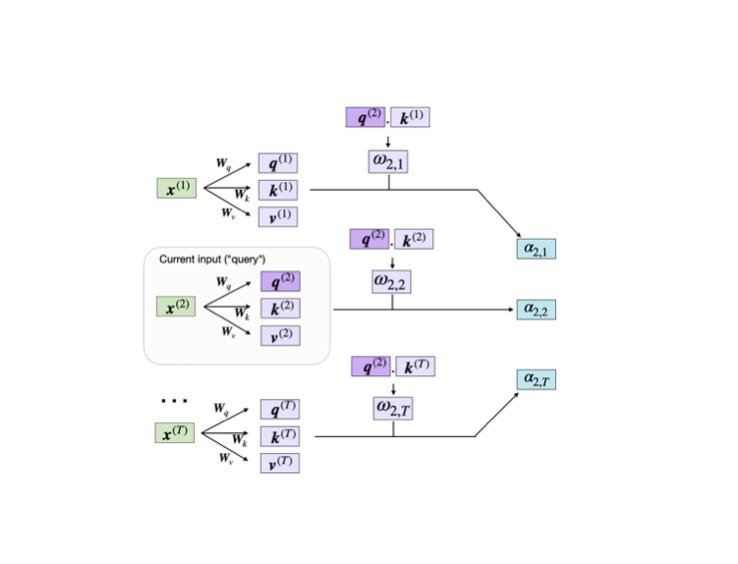
This article will teach you about self-attention mechanisms used in transformer architectures and large language models (LLMs) such as GPT-4 and Llama.

AI Driven tools for researchers and students. Use AI to summarize and understand scientific articles and research papers.

Autoregressive language models have excelled at predicting the subsequent subword in a sentence without the need for any predefined grammar or parsing concepts. This method has been expanded to include continuous data domains like audio and image production, where data is represented as discrete tokens, much like language model vocabularies. Due to their versatility, sequence models have attracted interest for use in increasingly complicated and dynamic contexts, such as behavior. Road users are compared to participants in a continuous conversation when driving since they exchange actions and replies. The question is whether similar sequence models may be used to forecast

As Midjourney rolls out new features, it continues to make some artists furious.
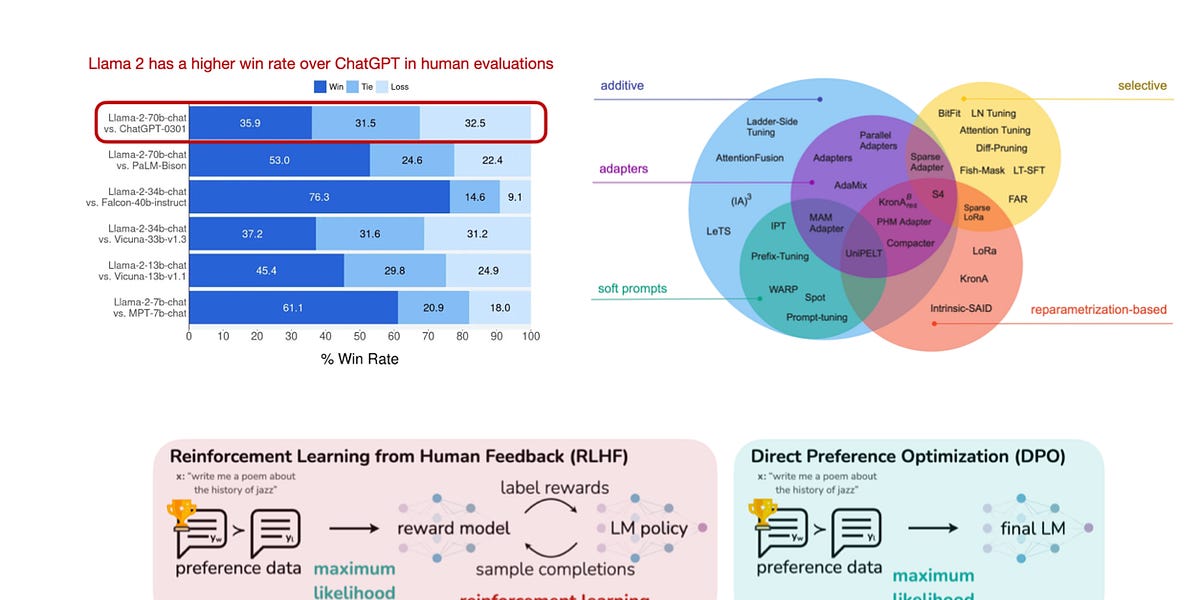
This year has felt distinctly different. I've been working in, on, and with machine learning and AI for over a decade, yet I can't recall a time when these fields were as popular and rapidly evolving as they have been this year. To conclude an eventful 2023 in machine learning and AI research, I'm excited to share 10 noteworthy papers I've read this year. My personal focus has been more on large language models, so you'll find a heavier emphasis on large language model (LLM) papers than computer vision papers this year.
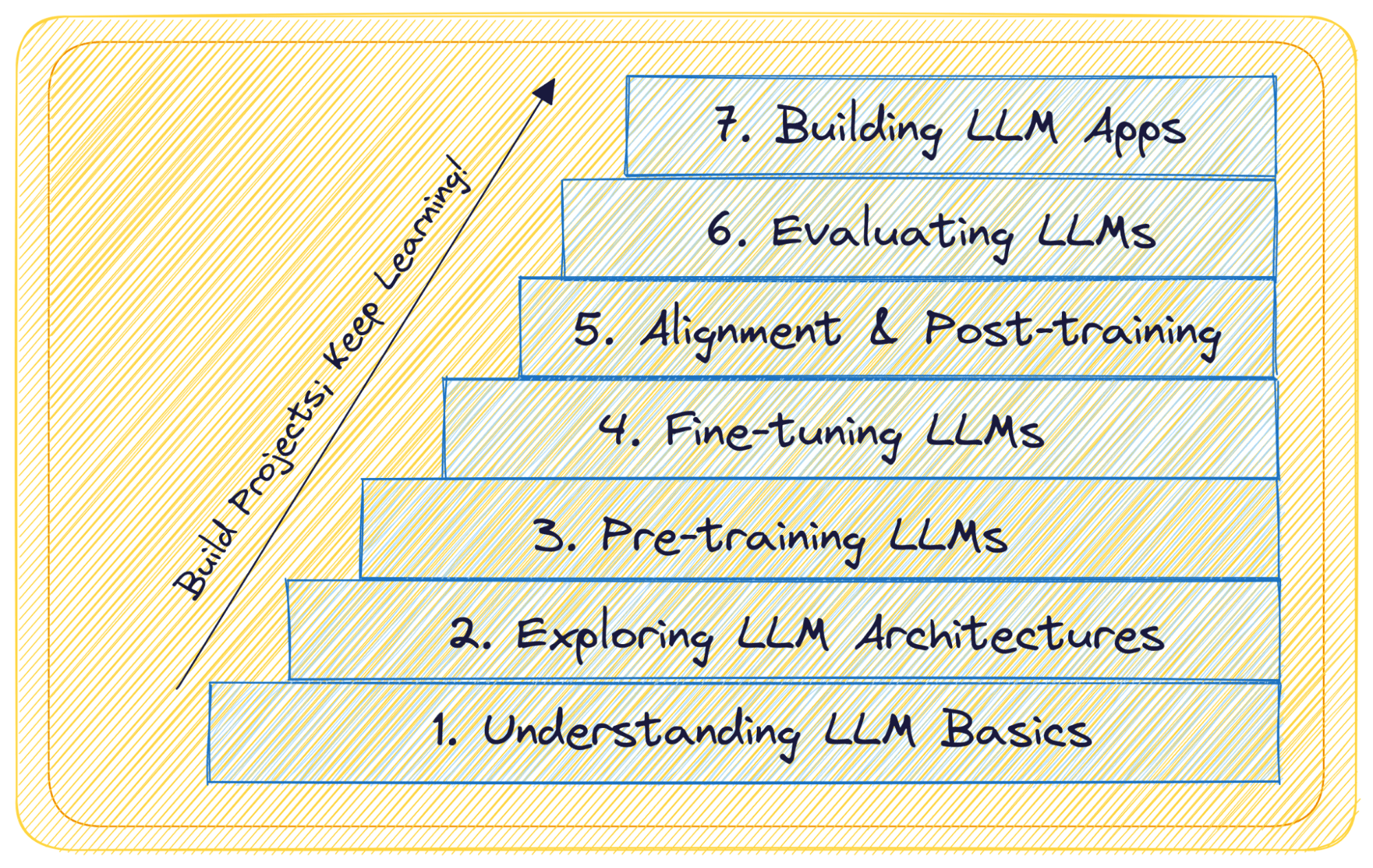
Large Language Models (LLMs) have unlocked a new era in natural language processing. So why not learn more about them? Go from learning what large language models are to building and deploying LLM apps in 7 easy steps with this guide.

The emergence of Large Language Models (LLMs) in natural language processing represents a groundbreaking development. These models, trained on vast amounts of data and leveraging immense computational resources, promise to transform human interactions with the digital world. As they evolve through scaling and rapid deployment, their potential use cases become increasingly intricate and complex. They extend their capabilities to tasks such as analyzing dense, knowledge-rich documents, enhancing chatbot experiences to make them more genuine and engaging, and assisting human users in iterative creative processes like coding and design. One crucial feature that empowers this evolution is the capacity to effectively

In a comparative study, Researchers from Nvidia investigated the impact of retrieval augmentation and context window size on the performance of large language models (LLMs) in downstream tasks. The findings reveal that retrieval augmentation consistently enhances LLM performance, irrespective of context window size. Their research sheds light on the effectiveness of retrieval mechanisms in optimizing LLMs for various applications. Researchers delve into the domain of long-context language models, investigating the efficacy of retrieval augmentation and context window size in enhancing LLM performance across various downstream tasks. It conducts a comparative analysis of different pretrained LLMs, demonstrating that retrieval mechanisms significantly
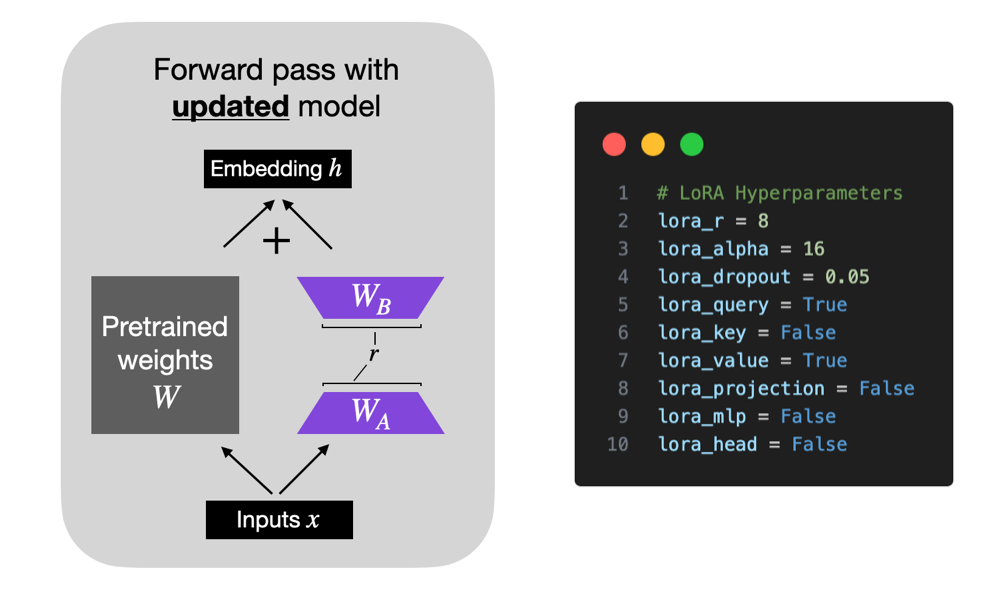
LoRA is one of the most widely used, parameter-efficient finetuning techniques for training custom LLMs. From saving memory with QLoRA to selecting the optimal LoRA settings, this article provides practical insights for those interested in applying it.

As a machine learning engineer who has witnessed the rise of Large Language Models (LLMs), I find it daunting to comprehend how the ecosystem surrounding LLMs is developing.

Unlock the power of GPT-4 summarization with Chain of Density (CoD), a technique that attempts to balance information density for high-quality summaries.
Our weekly selection of must-read Editors’ Picks and original features
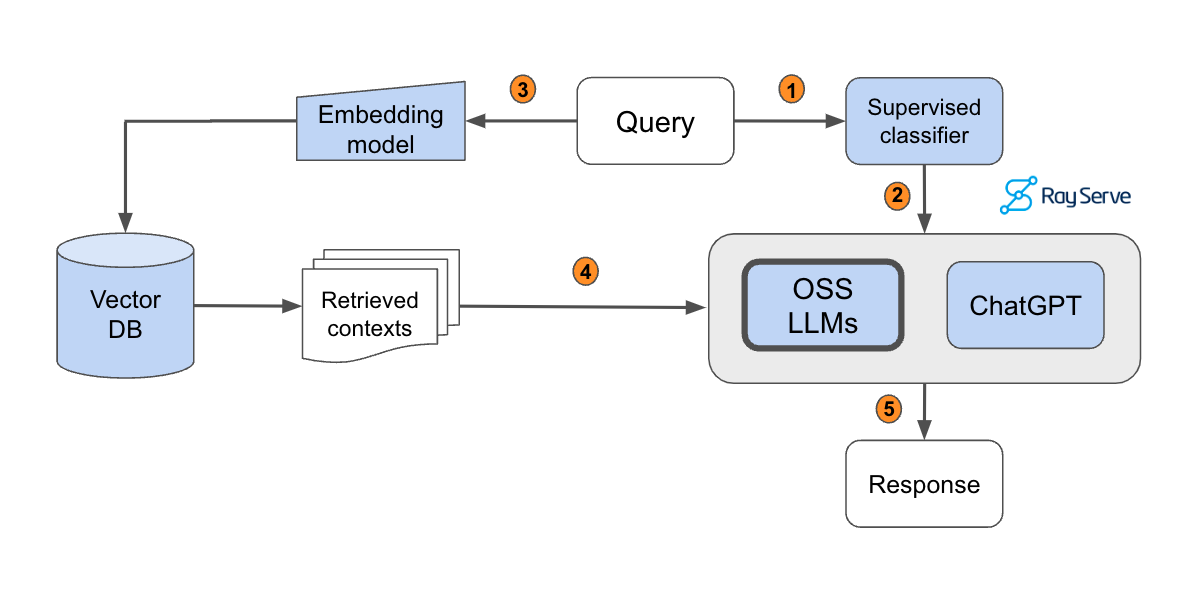
In this guide, we will learn how to develop and productionize a retrieval augmented generation (RAG) based LLM application, with a focus on scale and evaluation.
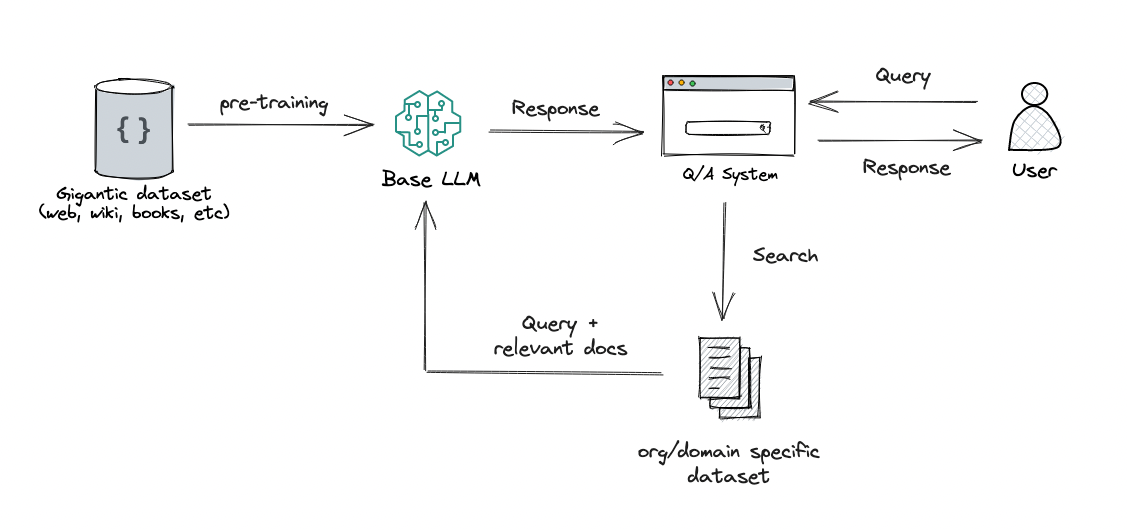
The definitive guide for choosing the right method for your use case

Discuss the concept of large language models (LLMs) and how they are implemented with a set of data to develop an application. Joas compares a collection of no-code and low-code apps designed to help you get a feel for not only how the concept works but also to get a sense of what types of models are available to train AI on different skill sets.
An End to End Example Of Seeing How Well An LLM Model Can Answer Amazon SageMaker Related Questions

Explore how the Skeleton-of-Thought prompt engineering technique enhances generative AI by reducing latency, offering structured output, and optimizing projects.
In the past few years we have seen the meteoric appearance of dozens of foundation models of the Transformer family, all of which have memorable and sometimes funny, but not self-explanatory,...

This is a story of my journey learning to build generative ML models from scratch and teaching a computer to create fonts in the process.
Eliciting product feedback elegantly is a competitive advantage for LLM-software. Over the weekend, I queried Google’s Bard, & noticed the elegant feedback loop the product team has incorporated into their product. I asked Bard to compare the 3rd-row leg room of the leading 7-passenger SUVs. At the bottom of the post is a little G button, which double-checks the response using Google searches. I decided to click it. This is what I would be doing in any case ; spot-checking some of the results.

Participants rated Bing Chat as less helpful and trustworthy than ChatGPT or Bard. These results can be attributed to Bing’s richer yet imperfect UI and to its poorer information aggregation.

Bard is now Gemini. Get help with writing, planning, learning, and more from Google AI.

We present the latest updates on ChatGPT, Bard and other competitors in the artificial intelligence arms race.

Tools to go from prototype to production
Data Curation, Transformers, Training at Scale, and Model Evaluation

Learn how to use GPT / LLMs to create complex summaries such as for medical text

Track, rank and evaluate open LLMs and chatbots

I want to provide some tips from my experience implementing a paper. I'm going to cover my tips so far from implementing a dramatically scaled-down versio...
A complete beginner-friendly introduction with example code
A quick-start guide to using open-source LLMs
Human-readable benchmarks of 60+ open-source and proprietary LLMs.

In a significant technological leap, OpenAI has announced the launch of DALL·E 3, the latest iteration in their groundbreaking text-to-image generation technology. With an unprecedented capacity to understand nuanced and detailed descriptions, DALL·E 3 promises to revolutionize the creative landscape by allowing users to translate their textual ideas into astonishingly accurate images effortlessly. DALL·E 3 is currently in research preview, offering a tantalizing glimpse into its capabilities. However, the broader availability of this cutting-edge technology is set for early October, when it will be accessible to ChatGPT Plus and Enterprise customers through the API and Labs later in the fall.

DALL-E 3, the latest version of OpenAI's ground-breaking generative AI visual art platform, was just announced with groundbreaking features, including

The young company sent shock waves around the world when it released ChatGPT. But that was just the start. The ultimate goal: Change everything. Yes. Everything.

If you're a developer or simply someone passionate about technology, you've likely encountered AI...
Seamlessly integrate LLMs into scikit-learn.
7 prompting tricks, Langchain, and Python example code

How to fine-tune Llama and other LLMs with one tool

A multifaceted challenge has arisen in the expansive realm of natural language processing: the ability to adeptly comprehend and respond to intricate and lengthy instructions. As communication nuances become more complicated, the shortcomings of prevailing models in dealing with extensive contextual intricacies have been laid bare. Within these pages, an extraordinary solution crafted by the dedicated minds at Together AI comes to light—a solution that holds the promise of reshaping the very fabric of language processing. This innovation has profound implications, especially in tasks requiring an acute grasp of extended contextual nuances. Contemporary natural language processing techniques rely heavily on
3 levels of using LLMs in practice

Word embedding vector databases have become increasingly popular due to the proliferation of massive language models. Using the power of sophisticated machine learning techniques, data is stored in a vector database. It allows for very fast similarity search, essential for many AI uses such as recommendation systems, picture recognition, and NLP. The essence of complicated data is captured in a vector database by representing each data point as a multidimensional vector. Quickly retrieving related vectors is made possible by modern indexing techniques like k-d trees and hashing. To transform big data analytics, this architecture generates highly scalable, efficient solutions for
Use these text extraction techniques to get quality data for your LLM models

A user-friendly platform for operating large language models (LLMs) in production, with features such as fine-tuning, serving, deployment, and monitoring of any LLMs.

Recent language models can take long contexts as input; more is needed to know about how well they use longer contexts. Can LLMs be extended to longer contexts? This is an unanswered question. Researchers at Abacus AI conducted multiple experiments involving different schemes for developing the context length ability of Llama, which is pre-trained on context length 2048. They linear rescaled these models with IFT at scales 4 and 16. Scaling the model to scale 16 can perform world tasks up to 16k context length or even up to 20-24k context length. Different methods of extending context length are Linear

Using ChatGPT & OpenAI's GPT API, this code tutorial teaches how to chat with PDFs, automate PDF tasks, and build PDF chatbots.
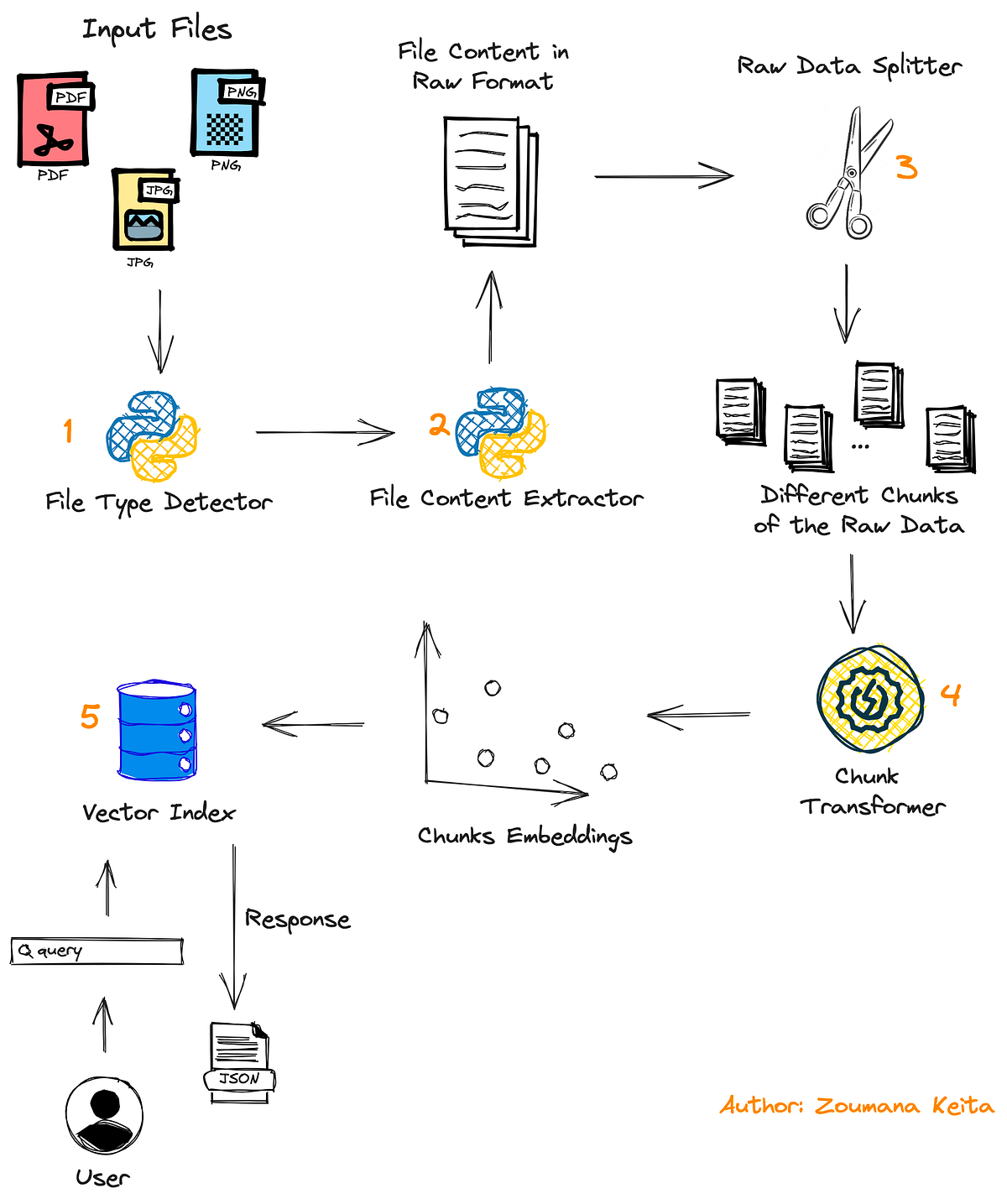
Complete guide to building an AI assistant that can answer questions about any file

Practical Advice from Experts: Fine-Tuning, Deployment, and Best Practices

LangChain is a Python library that helps you build GPT-powered applications in minutes. Get started with LangChain by building a simple question-answering app.

Latest blogs from the team at Mosaic Research

Navigating the maze of pricing plans for digital services can sometimes be a daunting task. Today, we are unveiling Midjourney

Exploring the Development of the 3 Leading Open LLMs and Their Chatbot Derivatives

A practical and simple approach for “reasoning” with LLMs

Anthropic released Claude 2, a new iteration of its AI model, to take on ChatGPT and Google Bard...

A reference architecture for the LLM app stack. It shows the most common systems, tools, and design patterns used by AI startups and tech companies.
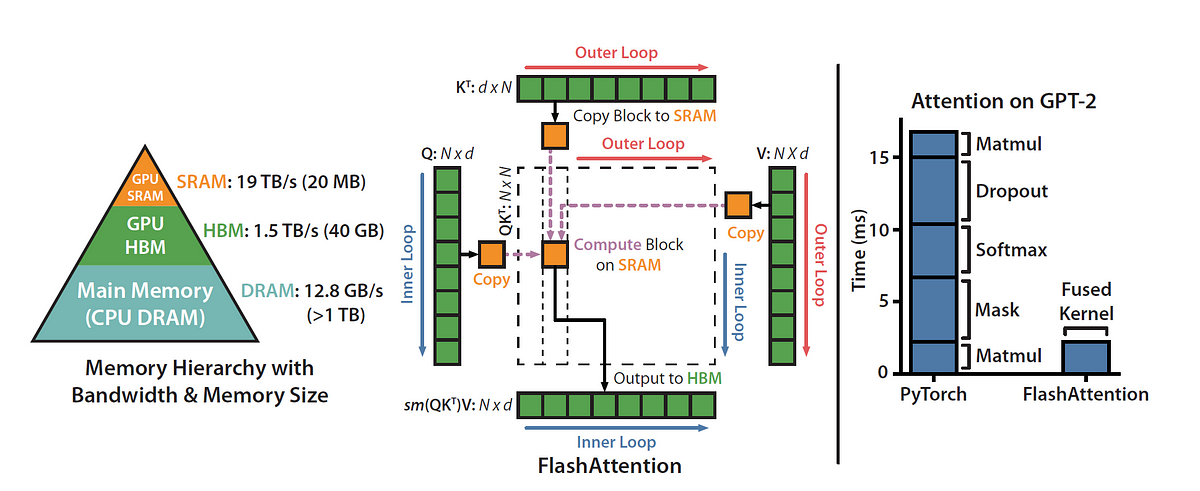
Step by step explanation of how one of the most important MLSys breakthroughs work — in gory detail.

Organizations are in a race to adopt Large Language Models. Let’s dive into how you can build industry-specific LLMs Through RAG

Want to learn more about LLMs and build cool LLM-powered applications? This free Full Stack LLM Bootcamp is all you need!

The model quickly top the Open LLM Leaderboard that ranks the performance of open source LLMs.

tldr; techniques to speed up training and inference of LLMs to use large context window up to 100K input tokens during training and…

The Observe.AI contact center LLM showed a 35% increase in accuracy compared to GPT-3.5 when automatically summarizing conversations.
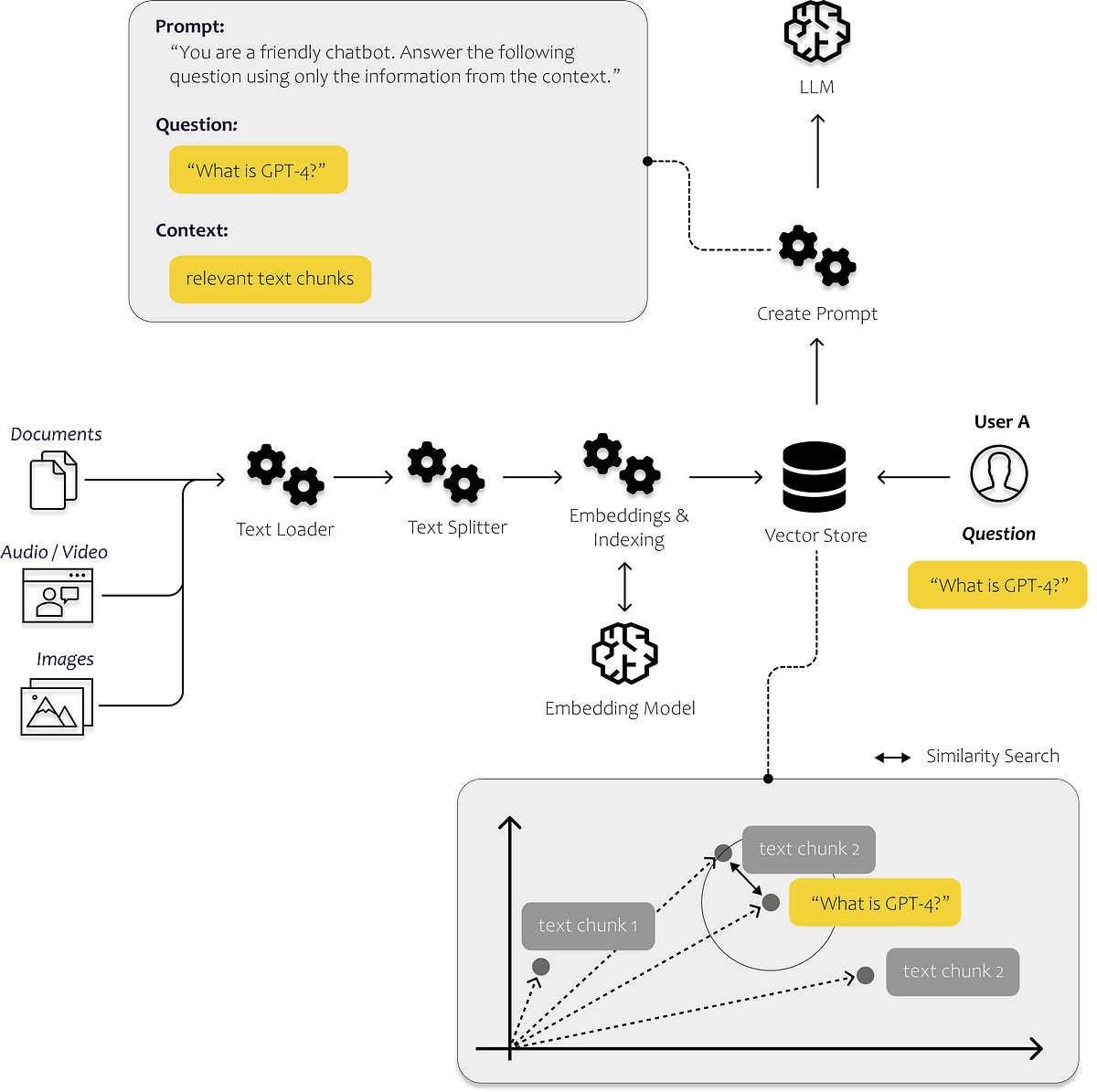
A step-by-step tutorial to document loaders, embeddings, vector stores and prompt templates

With the release of PyTorch 2.0 and ROCm 5.4, we are excited to announce that LLM training works out of the box on AMD MI250 accelerators with zero code changes and at high performance!

This article provides a series of techniques that can lower memory consumption in PyTorch (when training vision transformers and LLMs) by approximately 20x without sacrificing modeling performance and prediction accuracy.

Running Falcon-7B in the cloud as a microservice

Anthropic, the AI startup founded by ex-OpenAI execs, has released its newest chatbot, Claude 2. It's ostensibly improved in several ways.

Google is launching its AI-backed note-taking tool to "a small group of users in the US," the company said in a blog post. Formerly referred to as Project Tailwind at Google I/O earlier this year, the new app is now known as NotebookLM (the LM stands for Language Model). The Verge reports: The core...

Developed by ETH Zürich, the language explores new paradigms for LLM programming.

It crazy how far the ML field has come when it comes to fine-tuning LLMs. A year ago: it was challenging to fine-tune GPT-2 (1.5B) on a single GPU without… | 76 comments on LinkedIn

A comprehensive guide on how to use Meta's LLaMA 2, the new open-source AI model challenging OpenAI's ChatGPT and Google's Bard.

How LLaMA is making open-source cool again

Not only has LLaMA been trained on more data, with more parameters, the model also performs better than its predecessor, according to Meta.

MosaicML claims that the MPT-7B-8K LLM exhibits exceptional proficiency in summarization and answering tasks compared to previous models.

The founders of Anthropic quit OpenAI to make a safe AI company. It’s easier said than done.

This article delves into the concept of Chain-of-Thought (CoT) prompting, a technique that enhances the reasoning capabilities of large language models (LLMs). It discusses the principles behind CoT prompting, its application, and its impact on the performance of LLMs.
A curated list of practical guide resources of LLMs (LLMs Tree, Examples, Papers) - Mooler0410/LLMsPracticalGuide
Get started using Falcon-7B, Falcon-40B, and their instruct versions

Falcon LLM, is the new large language model that has taken the crown from LLaMA.

Large language models have increased due to the ongoing development and advancement of artificial intelligence, which has profoundly impacted the state of natural language processing in various fields. The potential use of these models in the financial sector has sparked intense attention in light of this radical upheaval. However, constructing an effective and efficient open-source economic language model depends on gathering high-quality, pertinent, and current data. The use of language models in the financial sector exposes many barriers. These vary from challenges in getting data, maintaining various data forms and kinds, and coping with inconsistent data quality to the crucial

Welcome to the LMM garden! A searchable list of open-source and off-the-shelf LLMs available to ML practitioners. Know of a new LLM? Add it

GPUs may dominate, but CPUs could be perfect for smaller AI models
Learn how standard greedy tokenization introduces a subtle and powerful bias that can have all kinds of unintended consequences.

AI companies are using LangChain to supercharge their LLM apps. Here is a comprehensive guide of resources to build your LangChain + LLM journey. 🔗 What is… | 45 comments on LinkedIn

AI is getting very chatty! Here’s a visualisation charting the rise of Large Language Models like GPT4, LaMDA, LLaMa, PaLM and their bots...

A new AI Bard powered by PaLM V2 that can write, translate, and code better than ChatGPT.

1) Reinforcement Learning with Human Feedback(RLHF) 2) The RLHF paper, 3) The transformer reinforcement learning framework.

Google's new machines combine Nvidia H100 GPUs with Google’s high-speed interconnections for AI tasks like training very large language models.
Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific...
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of...
OpenLLaMA, a permissively licensed open source reproduction of Meta AI’s LLaMA 7B trained on the RedPajama dataset - openlm-research/open_llama
A guidance language for controlling large language models. - guidance-ai/guidance
Anyscale is the leading AI application platform. With Anyscale, developers can build, run and scale AI applications instantly.
In the rapidly evolving field of AI, using large language models in an efficient and effective manner is becoming more and more important. In this article, y...

Created by researchers from UC Berkeley, CMU, Stanford, and UC San Diego, Vicuna is part of the new wave of models that use Meta's LLaMA as its foundation.

Many intelligent robots have come and gone, failing to become a commercial success. We’ve lost Aibo, Romo, Jibo, Baxter—even Alexa is reducing staff. Perhaps they failed to reach their potential because you can’t have a meaningful conversation with them. We are now at an inflection point: AI

Your own LLM. MiniGPT-4. WebGPT on WebGPU. Transformers from scratch. ChatGTP Plugins demo live. Whisper JAX. LLaVA. MetaAI DINO SoTA Computer Vision. Autonomous agents in LangChain. RedPajama.
An introduction to the core ideas and approaches

Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.

Facebook’s parent company is inviting researchers to pore over and pick apart the flaws in its version of GPT-3
The widespread public deployment of large language models (LLMs) in recent months has prompted a wave of new attention and engagement from advocates, policymakers, and scholars from many fields....

Introducing the new fully autonomous task manager that can create, track and prioritize your company's projects using artificial intelligence.
A Cross-Section of the Most Relevant Literature To Get Up to Speed

In this guest post, Filip Haltmayer, a Software Engineer at Zilliz, explains how LangChain and Milvus can enhance the usefulness of Large Language Models (LLMs) by allowing for the storage and retrieval of relevant documents. By integrating Milvus, a vector database, with LangChain, LLMs can process more tokens and improve their conversational abilities.
Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics. This post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models.
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and...

Explore what LLMs are, how they work, and gain insights into real-world examples, use cases, and best practices.

Garbage in, garbage out has never been more true.

If you're looking for a way to improve the performance of your large language model (LLM) application while reducing costs, consider utilizing a semantic cache to store LLM responses.

Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.

The challenge of managing and recalling facts from complex, evolving conversations is a key problem for many AI-driven applications. As information grows and changes over time, maintaining accurate context becomes increasingly difficult. Current systems often struggle to handle the evolving nature of relationships and facts, leading to incomplete or irrelevant results when retrieving information. This can affect the effectiveness of AI agents, especially when dealing with user memories and context in real-time applications. Some existing solutions have attempted to address this problem. One common approach is using a Retrieval-Augmented Generation (RAG) pipeline, which involves storing extracted facts and using techniques

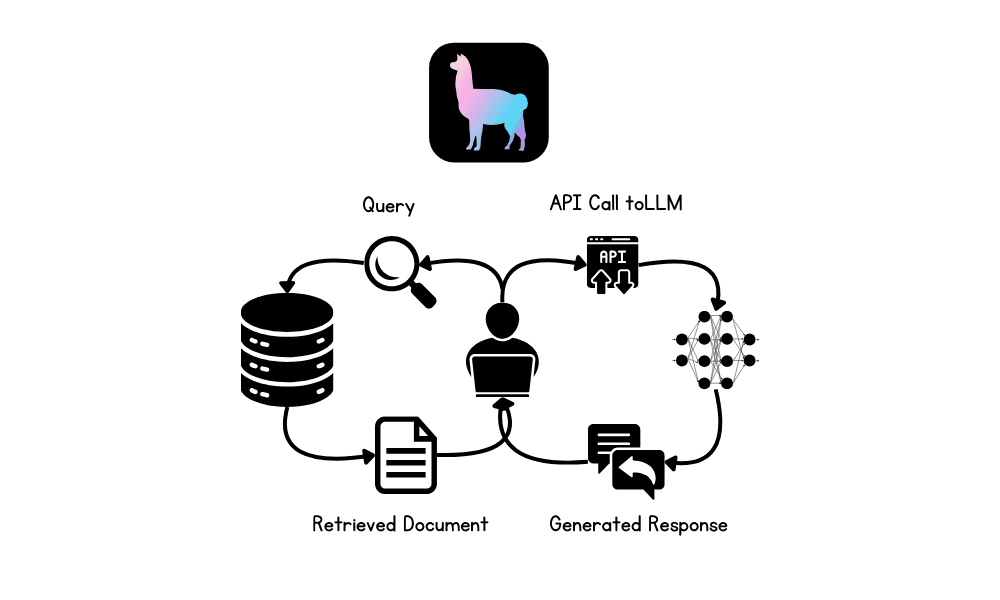
Retrieval-Augmented Generation (RAG) is a machine learning framework that combines the advantages of both retrieval-based and generation-based models. The RAG framework is highly regarded for its ability to handle large amounts of information and produce coherent, contextually accurate responses. It leverages external data sources by retrieving relevant documents or facts and then generating an answer or output based on the retrieved information and the user query. This blend of retrieval and generation leads to better-informed outputs that are more accurate and comprehensive than models that rely solely on generation. The evolution of RAG has led to various types and approaches,

Large Language Models (LLMs) have gained significant prominence in modern machine learning, largely due to the attention mechanism. This mechanism employs a sequence-to-sequence mapping to construct context-aware token representations. Traditionally, attention relies on the softmax function (SoftmaxAttn) to generate token representations as data-dependent convex combinations of values. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges. One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. Also, the application of SoftmaxAttn necessitates a row-wise reduction along the input sequence length,
[caption align=

Large Language Models (LLMs) have gained significant prominence in recent years, driving the need for efficient GPU utilization in machine learning tasks. However, researchers face a critical challenge in accurately assessing GPU performance. The commonly used metric, GPU Utilization, accessed through nvidia-smi or integrated observability tools, has proven to be an unreliable indicator of actual computational efficiency. Surprisingly, 100% GPU utilization can be achieved merely by reading and writing to memory without performing any computations. This revelation has sparked a reevaluation of performance metrics and methodologies in the field of machine learning, prompting researchers to seek more accurate ways to
Nvidia has released NVLM 1.0, a powerful open-source AI model that rivals GPT-4 and Google’s systems, marking a major breakthrough in multimodal language models for vision and text tasks.

Large language models (LLMs) have advanced significantly in recent years. However, its real-world applications are restricted due to substantial processing power and memory requirements. The need to make LLMs more accessible on smaller and resource-limited devices drives the development of more efficient frameworks for model inference and deployment. Existing methods for running LLMs include hardware acceleration techniques and optimizations like quantization and pruning. However, these methods often fail to provide a balance between model size, performance, and usability in constrained environments. Researchers developed an efficient, scalable, and lightweight framework for LLM inference, LightLLM, to address the challenge of efficiently deploying

Large Language Models (LLMs) have become a cornerstone in artificial intelligence, powering everything from chatbots and virtual assistants to advanced text generation and translation systems. Despite their prowess, one of the most pressing challenges associated with these models is the high cost of inference. This cost includes computational resources, time, energy consumption, and hardware wear. Optimizing these costs is paramount for businesses and researchers aiming to scale their AI operations without breaking the bank. Here are ten proven strategies to reduce LLM inference costs while maintaining performance and accuracy: Quantization Quantization is a technique that decreases the precision of model