object detection (machine vision)

Yesterday (24/05/2024) marked the launch of the new state-of-the-art architecture named YOLOv10 [1], representing the cutting-edge in real-time object…
Learn the basics of this advanced computer vision task of object detection in an easy to understand multi-part beginner’s guide

eBay's new generative AI tool, rolling out on iOS first, can write a product listing from a single photo -- or so the company claims.

Learn how to build a surveillance system using WebRTC for low-latency and YOLO for object detection. This tutorial will guide you through the process of using computer vision and machine learning techniques to detect and track objects in real-time video streams. With this knowledge, you can create a surveillance system for security or other applications. However, there are challenges to consider when using cameras for object detection, including data privacy and security concerns, as well as technical limitations such as low image quality and lighting conditions. This article will teach you how to overcome some of these challenges and build a reliable surveillance system.

The YOLO algorithm offers high detection speed and performance through its one-forward propagation capability. In this tutorial, we will focus on YOLOv5.

Everything you need to know to use YOLOv7 in custom training scripts
Overview of how object detection works, and where to get started

this post is explaining how permutation importance works and how we can code it using ELI5

eview and comparison of the next generation object detection

A step-by-step tutorial using a minimal amount of code

A guide on object detection algorithms and libraries that covers use cases, technical details, and offers a look into modern applications.

Evaluating object detection models is not straightforward because each image can have many objects and each object can belong to different classes. This means that we need to measure if the model…

Building an app for blood cell count detection.

If you have ever had to tinker with anchor boxes, you were probably frustrated, confused and saying to yourself, “There must be another…

A recent article came out comparing public cloud providers’ face detection APIs. I was very surprised to see all of the detectors fail to…

**Object Detection** is a computer vision task in which the goal is to detect and locate objects of interest in an image or video. The task involves identifying the position and boundaries of objects in an image, and classifying the objects into different categories. It forms a crucial part of vision recognition, alongside [image classification](/task/image-classification) and [retrieval](/task/image-retrieval). The state-of-the-art methods can be categorized into two main types: one-stage methods and two stage-methods: - One-stage methods prioritize inference speed, and example models include YOLO, SSD and RetinaNet. - Two-stage methods prioritize detection accuracy, and example models include Faster R-CNN, Mask R-CNN and Cascade R-CNN. The most popular benchmark is the MSCOCO dataset. Models are typically evaluated according to a Mean Average Precision metric. ( Image credit: [Detectron](https://github.com/facebookresearch/detectron) )

How to set up and train a Yolo v5 Object Detection model?

Visual vocabulary advances novel object captioning by breaking free of paired sentence-image training data in vision and language pretraining. Discover how this method helps set new state of the art on the nocaps benchmark and bests CIDEr scores of humans.

State of the art modeling with image data augmentation and management

In this article we’ll serve the Tensorflow Object Detection API with Flask, Dockerize the Application and deploy it on Kubernetes.
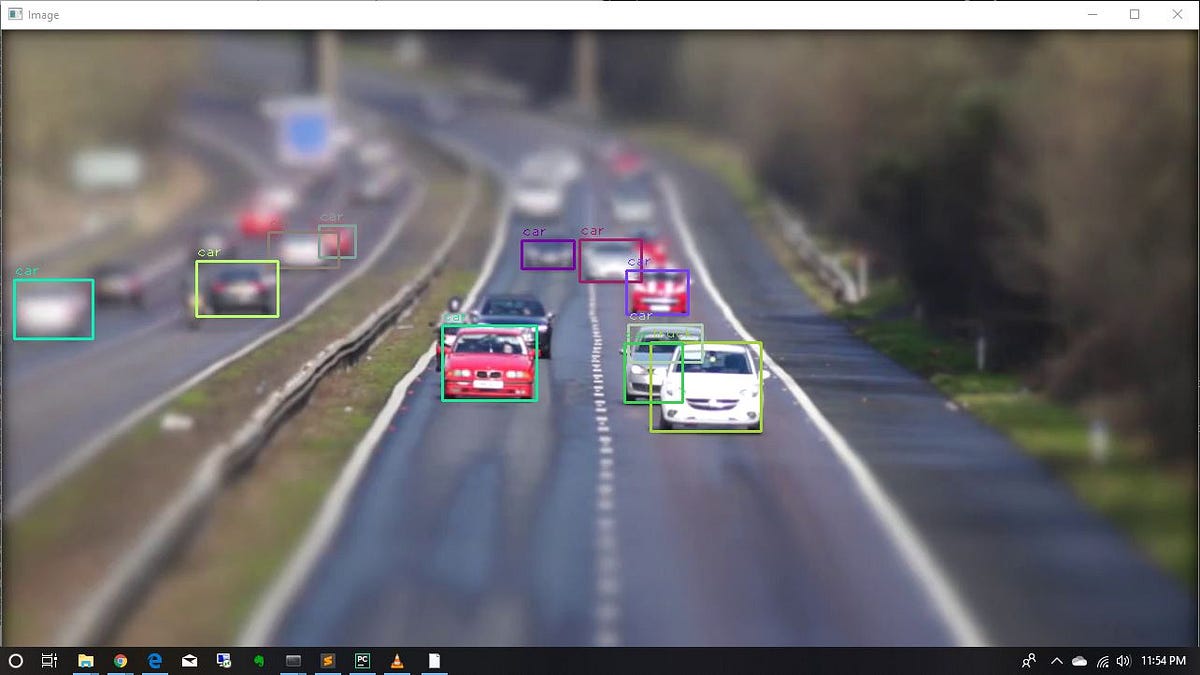
An Introduction to Object Detection with YoloV3 for beginners
Object Detection using Yolo V3 and OpenCV .
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. Code is at: https://github.com/facebookresearch/Detectron.
Easy Explanation!!! I tried
Object detection has been applied widely in video surveillance, self-driving cars, and object/people tracking. In this piece, we’ll look at the basics of object detection and review some of the most commonly-used algorithms and a few brand new approaches, as well.
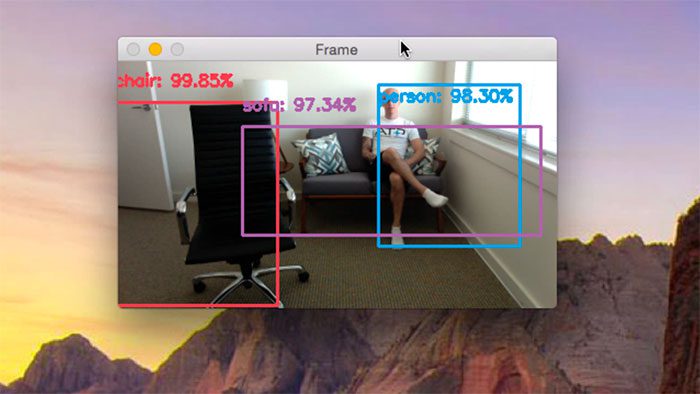
In this tutorial I demonstrate how to apply object detection with deep learning and OpenCV + Python to real-time video streams and video files.
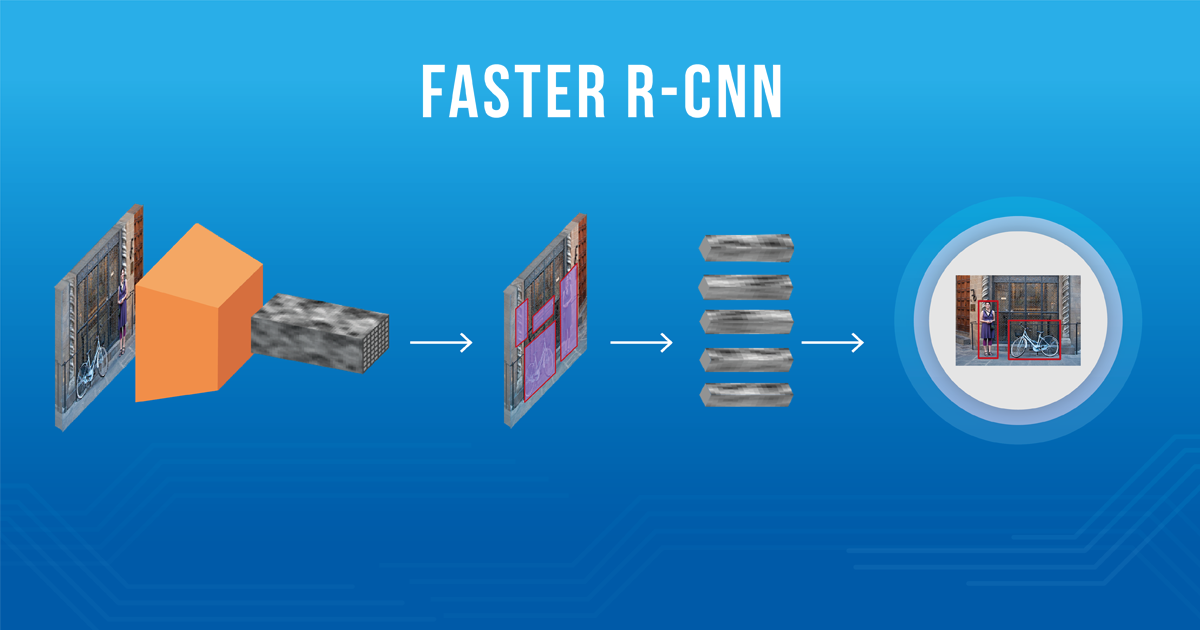
In this post, I'll explain the architecture of Faster R-CNN, starting with a high level overview, and then go over the details for each of the components. You'll be introduced to base networks, anchors as well as the region proposal network.