transformers (llms)

We insist that large language models repeatedly translate their mathematical processes into words. There may be a better way.
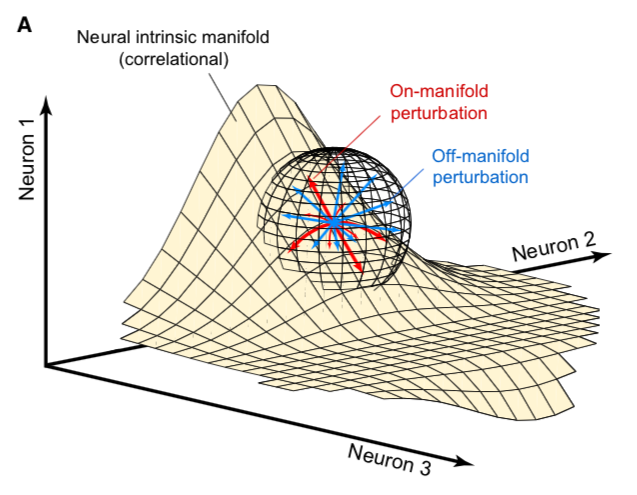

Large language models (LLMs) can understand and generate human-like text by encoding vast knowledge repositories within their parameters. This capacity enables them to perform complex reasoning tasks, adapt to various applications, and interact effectively with humans. However, despite their remarkable achievements, researchers continue to investigate the mechanisms underlying the storage and utilization of knowledge in these systems, aiming to enhance their efficiency and reliability further. A key challenge in using large language models is their propensity to generate inaccurate, biased, or hallucinatory outputs. These problems arise from a limited understanding of how such models organize and access knowledge. Without clear

Speed up your LLM inference

Natural Language Processing (NLP) has rapidly evolved in the last few years, with transformers emerging as a game-changing innovation. Yet, there are still notable challenges when using NLP tools to develop applications for tasks like semantic search, question answering, or document embedding. One key issue has been the need for models that not only perform well but also work efficiently on a range of devices, especially those with limited computational resources, such as CPUs. Models tend to require substantial processing power to yield high accuracy, and this trade-off often leaves developers choosing between performance and practicality. Additionally, deploying large models
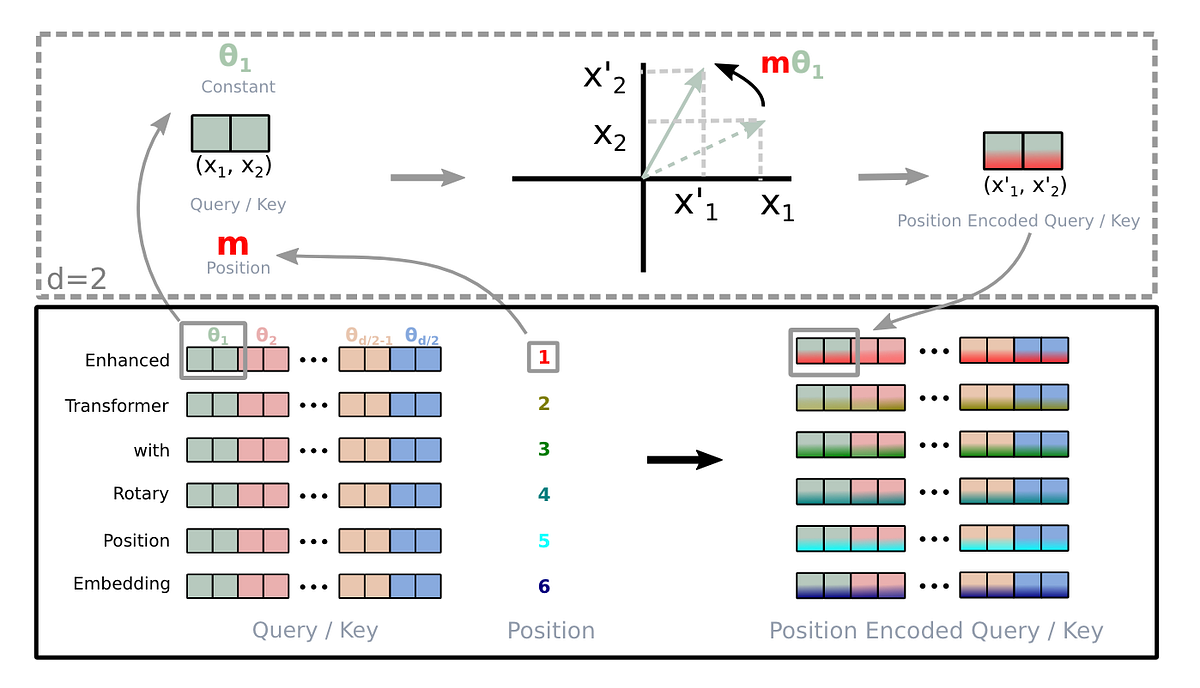
A deep dive into absolute, relative, and rotary positional embeddings with code examples

The Sohu AI chip by Etched is a thundering breakthrough, boasting the title of the fastest AI chip to date. Its design is a testament to cutting-edge innovation, aiming to redefine the possibilities within AI computations and applications. At the center of Sohu's exceptional performance is its advanced processing capabilities, which enable it to handle complex computations at unprecedented speeds. With a capability of processing over 500,000 tokens per second on the Llama 70B model, the Sohu chip enables the creation of unattainable products with traditional GPUs. An 8xSohu server can effectively replace 160 H100 GPUs, showcasing their remarkable efficiency
This is a visual guide (scroll story) to Vision Transformers (ViTs), a class of deep learning models that have achieved state-of-the-art performance on image classification tasks.

Is Attention all you need? Mamba, a novel AI model based on State Space Models (SSMs), emerges as a formidable alternative to the widely used Transformer models, addressing their inefficiency in processing long sequences.
The Math and the Code Behind Position Embeddings in Vision Transformers
The Math and the Code Behind Attention Layers in Computer Vision
A Full Walk-Through of Vision Transformers in PyTorch
In the past few years we have seen the meteoric appearance of dozens of foundation models of the Transformer family, all of which have memorable and sometimes funny, but not self-explanatory,...

Welcome to this beginner-friendly tutorial on sentiment analysis using Hugging Face's transformers...
A quick-start guide to using open-source LLMs

This article provides a series of techniques that can lower memory consumption in PyTorch (when training vision transformers and LLMs) by approximately 20x without sacrificing modeling performance and prediction accuracy.

1) Reinforcement Learning with Human Feedback(RLHF) 2) The RLHF paper, 3) The transformer reinforcement learning framework.

Facebook’s parent company is inviting researchers to pore over and pick apart the flaws in its version of GPT-3

Transformer models are one of the most exciting new developments in machine learning. They were introduced in the paper Attention is All You Need. Transformers can be used to write stories, essays, poems, answer questions, translate between languages, chat with humans, and they can even pass exams that are hard for humans! But what are they? You’ll be happy to know that the architecture of transformer models is not that complex, it simply is a concatenation of some very useful components, each o
A Cross-Section of the Most Relevant Literature To Get Up to Speed
I explain what is so unique about the RWKV language model.
The rapidly increasing size of deep-learning models has caused renewed and growing interest in alternatives to digital computers to dramatically reduce the energy cost of running state-of-the-art...
Many new Transformer architecture improvements have been proposed since my last post on “The Transformer Family” about three years ago. Here I did a big refactoring and enrichment of that 2020 post — restructure the hierarchy of sections and improve many sections with more recent papers. Version 2.0 is a superset of the old version, about twice the length. Notations Symbol Meaning $d$ The model size / hidden state dimension / positional encoding size.
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch
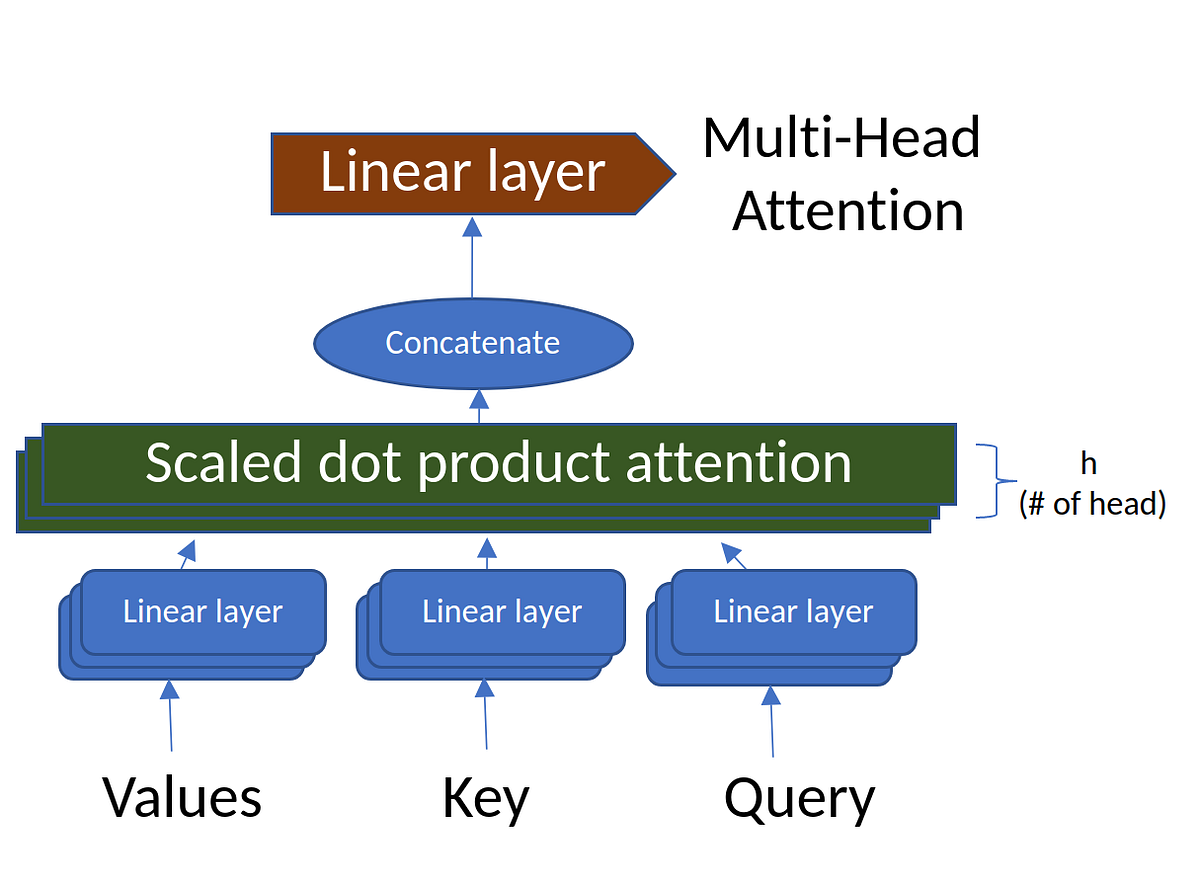
Attention, Self-Attention, Multi-head Attention, Masked Multi-head Attention, Transformers, BERT, and GPT
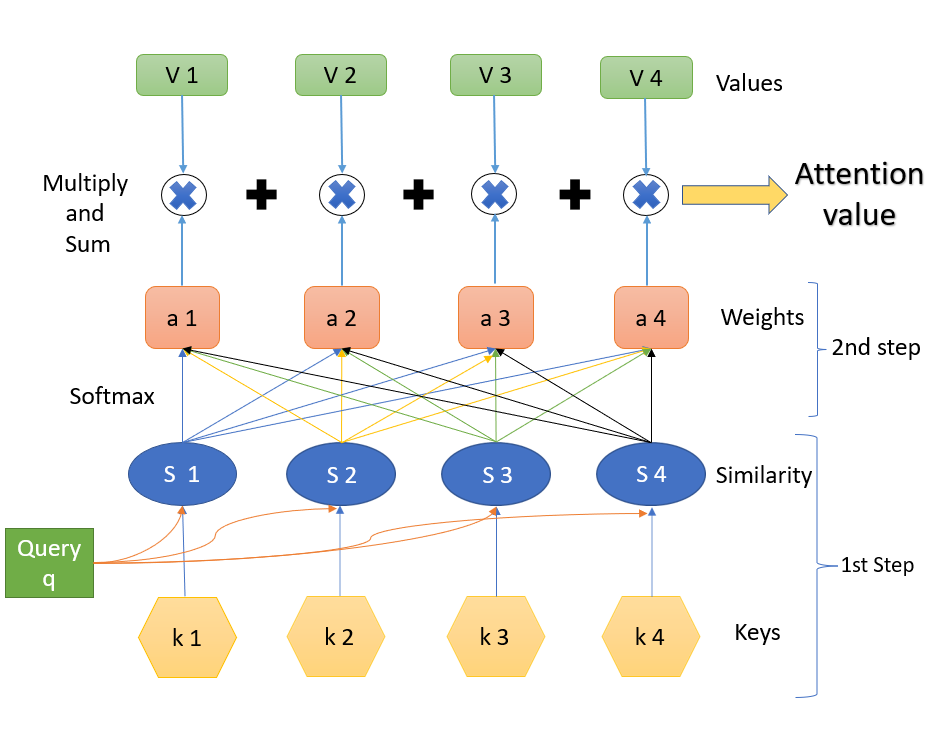
Attention, Self-Attention, Multi-head Attention, and Transformers
State-of-the-art transformers for Ruby.
Summary: We have released GPT-J-6B, 6B JAX-based (Mesh) Transformer LM (Github).GPT-J-6B performs nearly on par with 6.7B GPT-3 (or Curie) on various zero-shot down-streaming tasks.You can try out …
This repository contains demos I made with the Transformers library by HuggingFace. - NielsRogge/Transformers-Tutorials
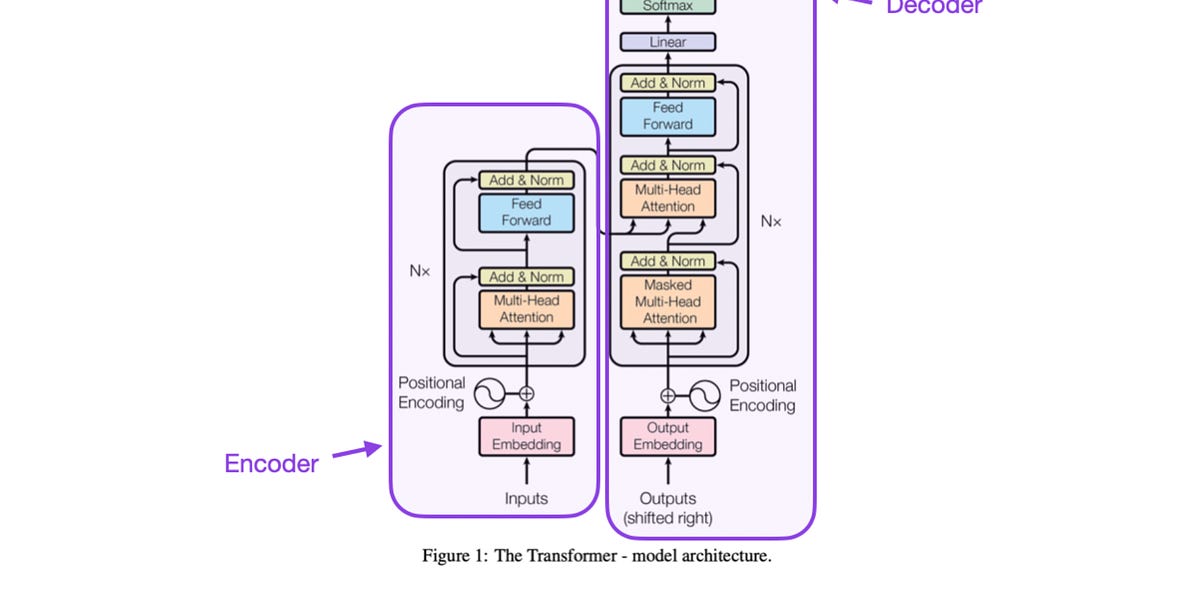
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Italian, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing this post Featured in courses at Stanford, Harvard, MIT, Princeton, CMU and others In the previous post, we looked at Attention – a ubiquitous method in modern deep learning models. Attention is a concept that helped improve the performance of neural machine translation applications. In this post, we will look at The Transformer – a model that uses attention to boost the speed with which these models can be trained. The Transformer outperforms the Google Neural Machine Translation model in specific tasks. The biggest benefit, however, comes from how The Transformer lends itself to parallelization. It is in fact Google Cloud’s recommendation to use The Transformer as a reference model to use their Cloud TPU offering. So let’s try to break the model apart and look at how it functions. The Transformer was proposed in the paper Attention is All You Need. A TensorFlow implementation of it is available as a part of the Tensor2Tensor package. Harvard’s NLP group created a guide annotating the paper with PyTorch implementation. In this post, we will attempt to oversimplify things a bit and introduce the concepts one by one to hopefully make it easier to understand to people without in-depth knowledge of the subject matter. 2020 Update: I’ve created a “Narrated Transformer” video which is a gentler approach to the topic: A High-Level Look Let’s begin by looking at the model as a single black box. In a machine translation application, it would take a sentence in one language, and output its translation in another.

How this novel neural network architecture changes the way we analyze complex data types, and powers revolutionary models like GPT-3 and BERT.
An intuitive understanding on Transformers and how they are used in Machine Translation. After analyzing all subcomponents one by one such as self-attention and positional encodings , we explain the principles behind the Encoder and Decoder and why Transformers work so well