A Blog post by Ksenia Se on Hugging Face
A Blog post by Ksenia Se on Hugging Face

Compute costs scale with the square of the input size. That’s not great.

Large Language Models (LLMs) have gained significant prominence in modern machine learning, largely due to the attention mechanism. This mechanism employs a sequence-to-sequence mapping to construct context-aware token representations. Traditionally, attention relies on the softmax function (SoftmaxAttn) to generate token representations as data-dependent convex combinations of values. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges. One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. Also, the application of SoftmaxAttn necessitates a row-wise reduction along the input sequence length,
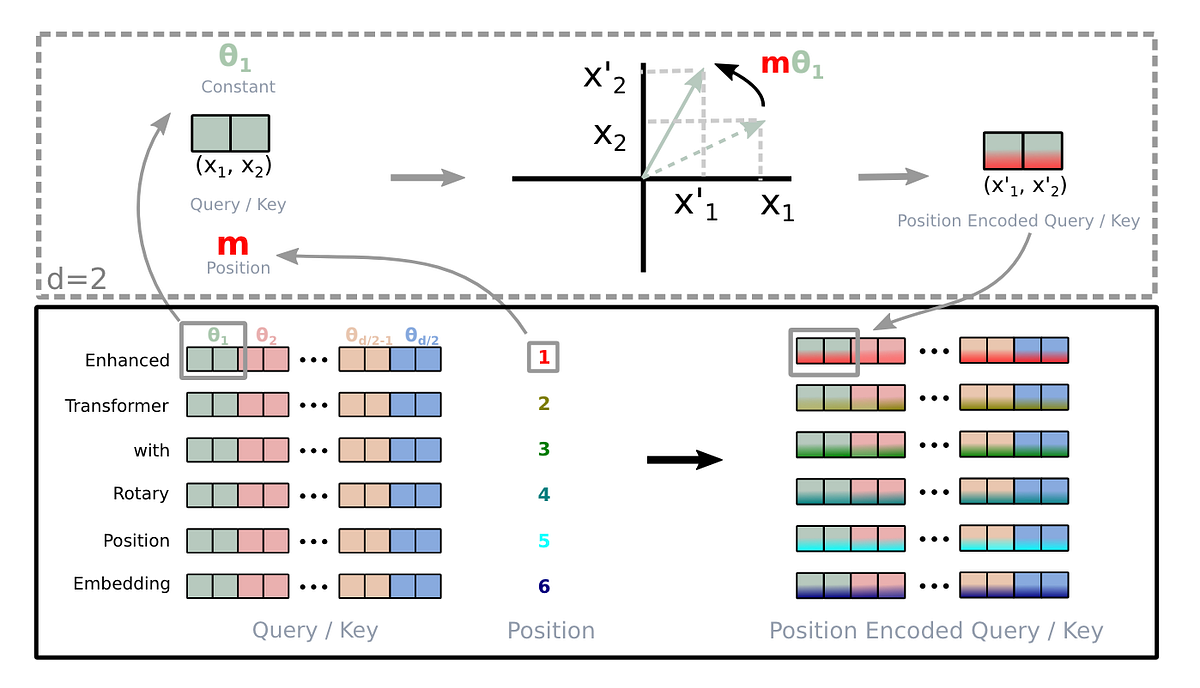
A deep dive into absolute, relative, and rotary positional embeddings with code examples

Attention, as a core layer of the ubiquitous Transformer architecture, is a bottleneck for large language models and long-context applications. FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is now used by most libraries to accelerate Transformer training and inference. This has contributed to a massive increase in LLM context length in the last two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), or even 1M (Llama 3). However, despite its success, FlashAttention has yet to take advantage of new capabilities in modern hardware, with FlashAttention-2 achieving only 35% utilization of theoretical max FLOPs on the H100 GPU. In this blogpost, we describe three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for FP8 low-precision.

Deep learning architectures have revolutionized the field of artificial intelligence, offering innovative solutions for complex problems across various domains, including computer vision, natural language processing, speech recognition, and generative models. This article explores some of the most influential deep learning architectures: Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), Transformers, and Encoder-Decoder architectures, highlighting their unique features, applications, and how they compare against each other. Convolutional Neural Networks (CNNs) CNNs are specialized deep neural networks for processing data with a grid-like topology, such as images. A CNN automatically detects the important features without any human supervision.

Large language models do better at solving problems when they show their work. Researchers are beginning to understand why.
Brands spend millions every year tracking and analyzing what their competition is doing. And it's not always so they can steal their competition's best ideas. They know this surprising marketing truth: When you do the opposite of what your competition is doing, you'll capture more attention. Why does this work? It's down to a psychological
The Math and the Code Behind Attention Layers in Computer Vision
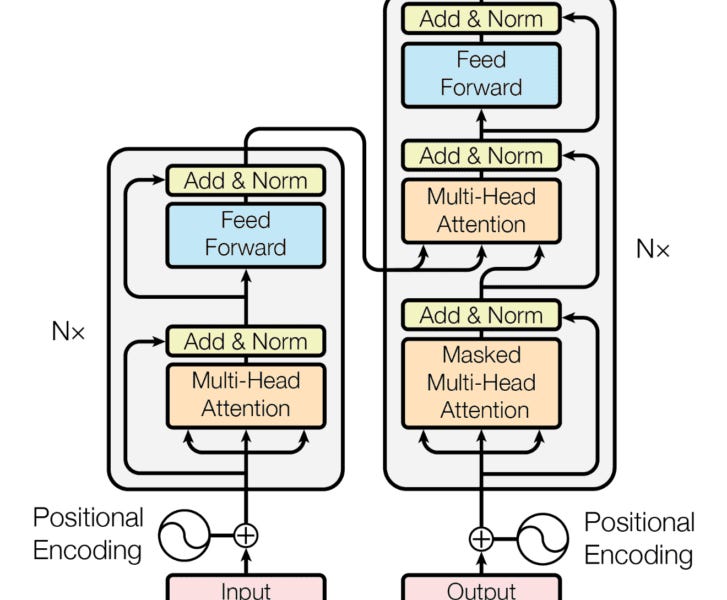
We will deep dive into understanding how transformer model work like BERT(Non-mathematical Explanation of course!). system design to use the transformer to build a Sentiment Analysis

When we talk about using different ways to share information, it's like picking the one that fits what you need! Words, pictures, and mixes of both have

Appliance makers believe more and better chimes, alerts, and jingles make for happier customers. Are they right?

The person who can capture and hold attention is the person who can effectively influence human behavior. Here's how to do it.

I used to be very anti-advertising. Fast forward two years and several pivots, and my slightly-less-early-stage business is doing $900 per month in revenue... from ads.

Distractions have become so pervasive in the digital age that we've come to accept them as normal. Here's how we can escape their grip and free our minds a little.