benchmarks

Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena's evaluation framework and promote fairer, more transparent benchmarking for the field


By Matteo Wong / The Atlantic. View the full context on Techmeme.
François Chollet has constructed the ultimate test for the bots.

The past few years have witnessed the rise in popularity of generative AI and large language models (LLMs), as part of a broad AI revolution.
METEOR Score is a metric used to evaluate the quality of machine translation based on precision, recall, word alignment, and linguistic flexibility.

Comparison and ranking the performance of over 30 AI models (LLMs) across key metrics including quality, price, performance and speed (output speed - tokens per second & latency - TTFT), context window & others.
Aidan Bench attempts to measure in LLMs. - aidanmclaughlin/AidanBench

Evaluating Large Language Models (LLMs) is a challenging problem in language modeling, as real-world problems are complex and variable. Conventional benchmarks frequently fail to fully represent LLMs' all-encompassing performance. A recent LinkedIn post has emphasized a number of important measures that are essential to comprehend how well new models function, which are as follows. MixEval Achieving a balance between thorough user inquiries and effective grading systems is necessary for evaluating LLMs. Conventional standards based on ground truth and LLM-as-judge benchmarks encounter difficulties such as biases in grading and possible contamination over time. MixEval solves these problems by combining real-world user

GPU maker tops new MLPerf benchmarks on graph neural nets and LLM fine-tuning

Track, rank and evaluate open LLMs and chatbots
Human-readable benchmarks of 60+ open-source and proprietary LLMs.

Exploring the Development of the 3 Leading Open LLMs and Their Chatbot Derivatives
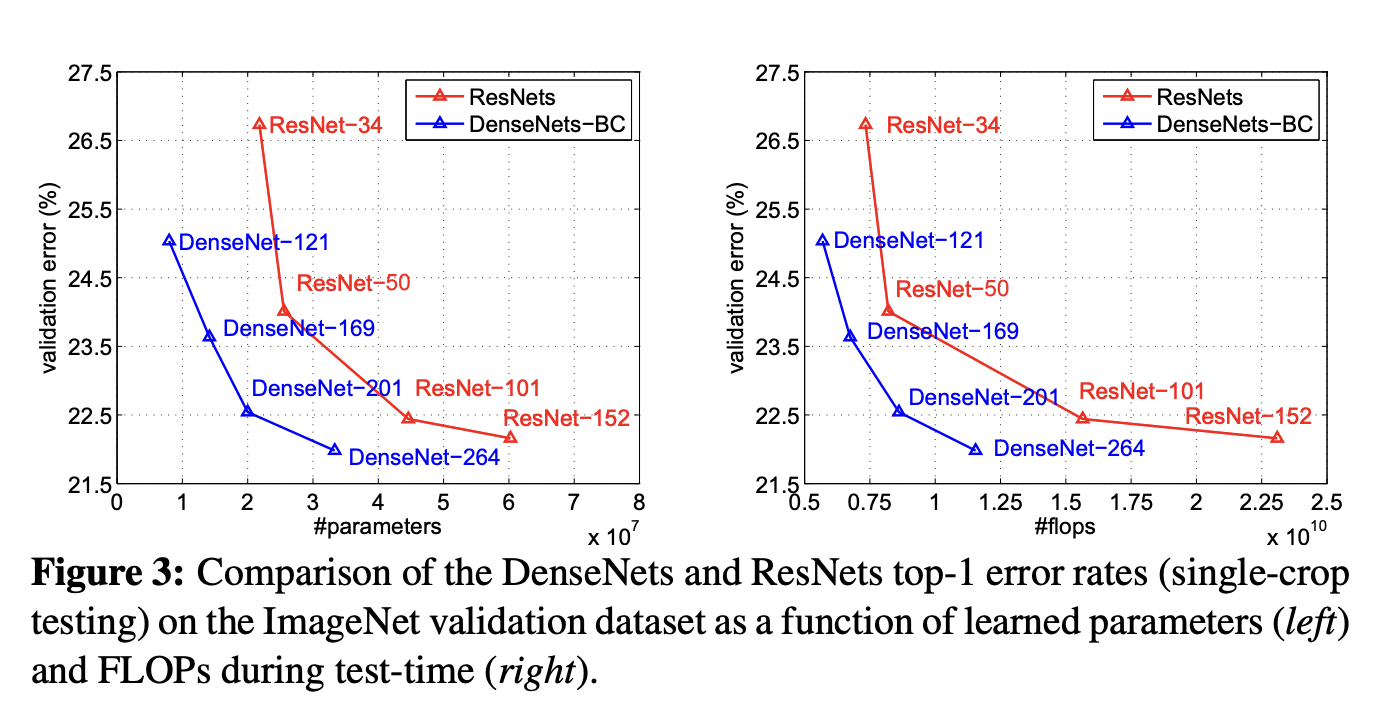
In this article we will learn about its definition, differences and how to calculate FLOPs and MACs using Python packages.
As computing system become more complex, it is becoming harder for programmers to keep their codes optimized as the hardware gets updated. Autotuners try to alleviate this by hiding as many archite…
How to Choose the Best Machine Learning Technique: Comparison Table

Benchmark your UX by first determining appropriate metrics and a study methodology. Then track these metrics across different releases of your product by running studies that follow the same established methodology.

12 sentiment analysis algorithms were compared on the accuracy of tweet classification. The fasText deep learning system was the winner.
This website is for sale! benchmarkfcns.xyz is your first and best source for all of the information you’re looking for. From general topics to more of what you would expect to find here, benchmarkfcns.xyz has it all. We hope you find what you are searching for!

We’re releasing an analysis showing that since 2012 the amount of compute needed to train a neural net to the same performance on ImageNet classification has been decreasing by a factor of 2 every 16 months. Compared to 2012, it now takes 44 times less compute to train a neural network to the level of AlexNet (by contrast, Moore’s Law would yield an 11x cost improvement over this period). Our results suggest that for AI tasks with high levels of recent investment, algorithmic progress has yielded more gains than classical hardware efficiency.

I’m not going to bury the lede: Most machine learning benchmarks are bad. And not just kinda-sorta nit-picky bad, but catastrophically and fundamentally flawed. TL;DR: Please, for the love of sta…

MLCommons ML benchmarks help balance the benefits and risks of AI through quantitative tools that guide responsible AI development.
MLCommons ML benchmarks help balance the benefits and risks of AI through quantitative tools that guide responsible AI development.

Buyer Experience Benchmarking of 5 Top eCommerce Sites Dec 2018 Ken Leaver

Over the last few years we have detailed the explosion in new machine learning systems with the influx of novel architectures from deep learning chip
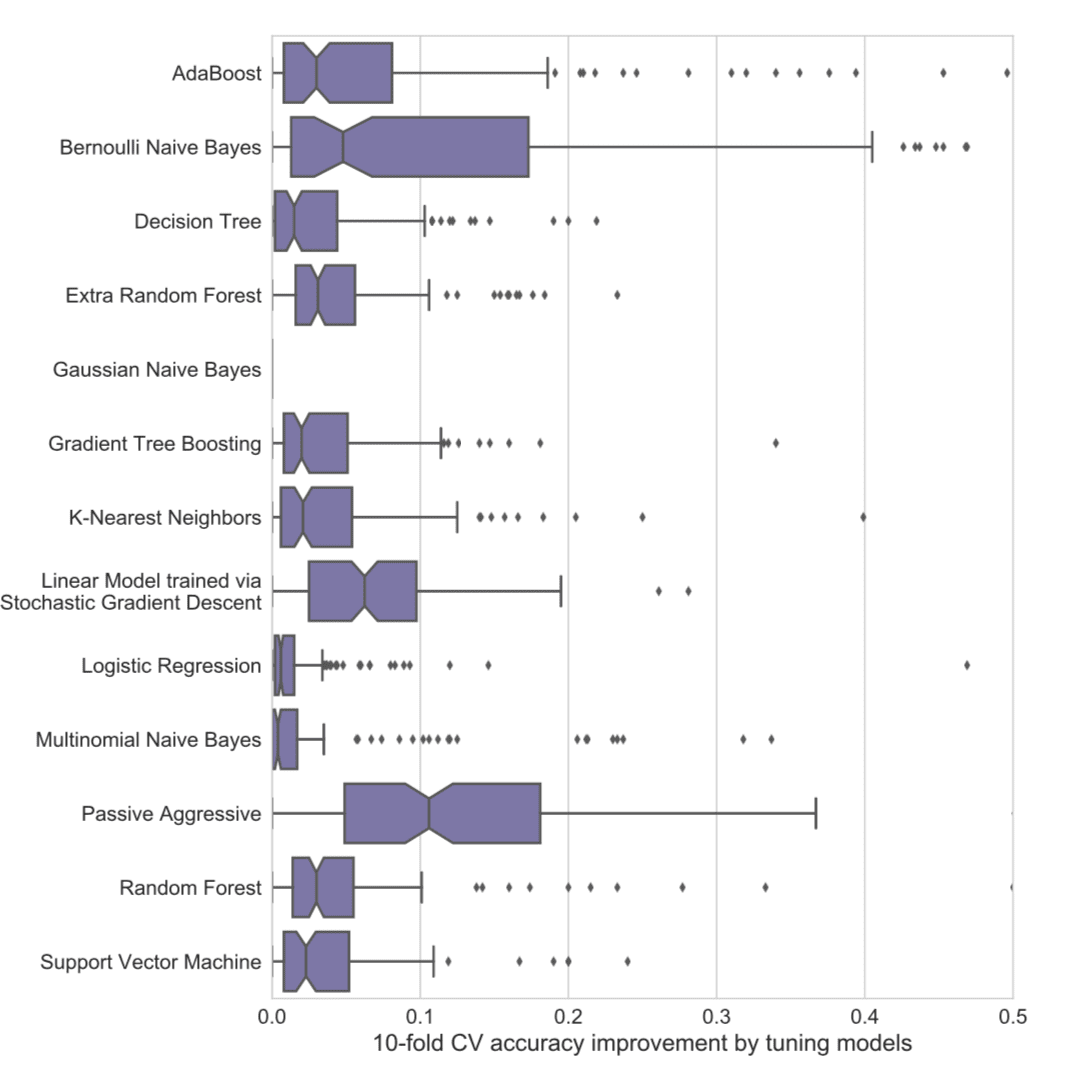
Which machine learning algorithm should you use? It is a central question in applied machine learning. In a recent paper by Randal Olson and others, they attempt to answer it and give you a guide for algorithms and parameters to try on your problem first, before spot checking a broader suite of algorithms. In this post, you will discover a…