
GeoPostcodes provides the world’s most comprehensive postal/zip code database. Complete, accurate, always up-to-date and enterprise-ready.
GeoPostcodes provides the world’s most comprehensive postal/zip code database. Complete, accurate, always up-to-date and enterprise-ready.

This Statology Sprint brings together our most valuable content on Faker, Python's powerful synthetic data generation library, to help you create realistic, privacy-compliant test data for your projects.
Spectacular new open geospatial project by [Dan Snow](https://sno.ws/): > OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time …

To show a catalog of almost 100 million books in one view, phiresky mapped them based on International Standard Book Numbers, or ISBNs, with an interactive visualization.
Free and commercial U.S. counties databases. Includes latitude, longitude, population, largest city, zip codes, timezone, income and more. CSV, SQL and Excel format.

Publicly available data helps monitor ship traffic to avoid disruption of undersea internet cables, identify whale strikes, and study the footprint of underwater noise.

AI training data has a big price tag, one best-suited for deep-pocketed tech firms. This is why Harvard University plans to release a dataset that
Benchmarks & Tips for Big Data, Hadoop, AWS, Google Cloud, PostgreSQL, Spark, Python & More...

There may be a few young people in Britain today who recognize the name Ludwig Koch, but in the nineteen-forties, he constituted something of a cultural phenomenon unto himself.

The release of the FC-AMF-OCR Dataset by LightOn marks a significant milestone in optical character recognition (OCR) and machine learning. This dataset is a technical achievement and a cornerstone for future research in artificial intelligence (AI) and computer vision. Introducing such a dataset opens up new possibilities for researchers and developers, allowing them to improve OCR models, which are essential in converting images of text into machine-readable text formats. Background of LightOn and FC-AMF-OCR Dataset LightOn, a company recognized for its pioneering contributions to AI and machine learning, has continuously pushed the boundaries of technology. The FC-AMF-OCR Dataset is one

The following is a list of stadiums in the United States. They are ranked by capacity, which is the maximum number of spectators the stadium can normally accommodate. All U.S. stadiums with a current capacity of 10,000 or more are included in the list. The majority of these stadiums are used for American football, either in college football or the NFL. Most of the others are Major League Baseball ballparks or Major League Soccer stadiums.Rows shaded in yellow indicates stadium is home to an NFL, MLB, MLS, or NWSL franchise.

Learn to identify some of the more common types of unexploded ordnance (UXO) in online images using open-source tools and resources.

The pile dataset has become a hot topic in AI circles, sparking debates about how data is used and the

The full guide to creating custom datasets and dataloaders for different models in PyTorch

DMA (Designated Market Area) regions are the geographic areas and zip codes in the U.S. in which local television viewing is measured by Nielsen.

Use our plastics properties table to sort and compare plastic materials. Review typical, physical, thermal, optical, electrical properties. Ask an Expert or Get a Quote.

Solar is in the process of shearing off the base of the entire global industrial stack – energy – and the tech sector still lacks a unified thesis for how to best enable, accelerate, an…

We live in an era of genre. Browse through TV shows of the last decade to see what I mean: Horror, sci-fi, fantasy, superheroes, futuristic dystopias…. Take a casual glance at the burgeoning global film franchises or merchandising empires.

Dataset distillation is an innovative approach that addresses the challenges posed by the ever-growing size of datasets in machine learning. This technique focuses on creating a compact, synthetic dataset that encapsulates the essential information of a larger dataset, enabling efficient and effective model training. Despite its promise, the intricacies of how distilled data retains its utility and information content have yet to be fully understood. Let’s delve into the fundamental aspects of dataset distillation, exploring its mechanisms, advantages, and limitations. Dataset distillation aims to overcome the limitations of large datasets by generating a smaller, information-dense dataset. Traditional data compression methods

Analytics, management, and business intelligence (BI) procedures, such as data cleansing, transformation, and decision-making, rely on data profiling. Content and quality reviews are becoming more important as data sets grow in size and variety of sources. In addition, organizations that rely on data must prioritize data quality review. Analysts and developers can enhance business operations by analyzing the dataset and drawing significant insights from it. Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling? Examining

Computer vision has advanced significantly in recent decades, thanks in large part to comprehensive benchmark datasets like COCO. However, nearly a decade after its introduction, COCO's suitability as a benchmark for modern AI models is being questioned. Its annotations may contain biases and nuances reflecting the early stages of computer vision research. With model performance plateauing on COCO, there are concerns about overfitting to the dataset's specific characteristics, potentially limiting real-world applicability. To modernize COCO segmentation, researchers have proposed COCONut - a novel, large-scale universal segmentation dataset in this paper. Unlike previous attempts at creating large datasets that often compromised

A Fun Tutorial using Python, JSON, and Spotify API! You might find it more comfortable...
Stats about all US cities - real estate, relocation info, crime, house prices, schools, races, income, photos, sex offenders, maps, education, weather, home value estimator, recent sales, etc.

A proactive, coordinated effort can reduce the chances that manipulations will impact model performance and protect algorithmic integrity.

Beautiful, free images and photos that you can download and use for any project. Better than any royalty free or stock photos.
Open Library is an open, editable library catalog, building towards a web page for every book ever published. Read, borrow, and discover more than 3M books for free.
The Pile is a 825 GiB diverse, open source language modelling data set that consists of 22 smaller, high-quality datasets combined together.

Developing large-scale datasets has been critical in computer vision and natural language processing. These datasets, rich in visual and textual information, are fundamental to developing algorithms capable of understanding and interpreting images. They serve as the backbone for enhancing machine learning models, particularly those tasked with deciphering the complex interplay between visual elements in images and their corresponding textual descriptions. A significant challenge in this field is the need for large-scale, accurately annotated datasets. These are essential for training models but are often not publicly accessible, limiting the scope of research and development. The ImageNet and OpenImages datasets, containing human-annotated

Nitasha Tiku / Washington Post: Analysis of 1,800 AI datasets: ~70% didn't state what license should be used or had been mislabeled with more permissive guidelines than their creators intended

Human motion capture has emerged as a key tool in various industries, including sports, medical, and character animation for the entertainment sector. Motion capture is utilized in sports for multiple purposes, including injury prevention, injury analysis, video game industry animations, and even generating informative visualization for TV broadcasters. Traditional motion capture systems provide solid results in the majority of circumstances. Still, they are expensive and time-consuming to set up, calibrate, and post-process, making them difficult to utilize on a broad scale. These concerns are made worse for aquatic activities like swimming, which bring up unique problems such as marker reflections

Europe at the end of the nineteenth century and beginning of the twentieth: what a time and place to be alive.

Read For Free, Anywhere, Anytime. An online library of over 1000 classic short stories. H. G. Wells, Edgar Allan Poe, H. P. Lovecraft, Anton Chekhov, Beatrix Potter.

BookCorpus has helped train at least thirty influential language models (including Google’s BERT, OpenAI’s GPT, and Amazon’s Bort), according to HuggingFace. This is the research question that…

Large-scale pre-trained Vision and language models have demonstrated remarkable performance in numerous applications, allowing for the replacement of a fixed set of supported classes with zero-shot open vocabulary reasoning over (nearly arbitrary) natural language queries. However, recent research has revealed a fundamental flaw in these models. For instance, their inability to comprehend Visual Language Concepts (VLC) that extend 'beyond nouns,' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or their difficulty with compositional reasoning, such as comprehending the significance of the word order in a sentence. Vision and language models, powerful machine-learning algorithms that learn

An analysis of a chatbot data set by The Washington Post reveals the proprietary, personal, and often offensive websites that go into an AI’s training data.
A ready-to-run code which identifies and anonymises places, based on the GeoNames database

Some Unique Data Visualization Techniques for Getting High-Level Insight into the Data

Posted by Mahima Pushkarna, Senior Interaction Designer, and Andrew Zaldivar, Senior Developer Relations Engineer, Google Research As machine learn...

The Allen Institute’s release includes recordings from a whopping 300,000 mouse neurons. Now the challenge is figuring out what to do with all that data.
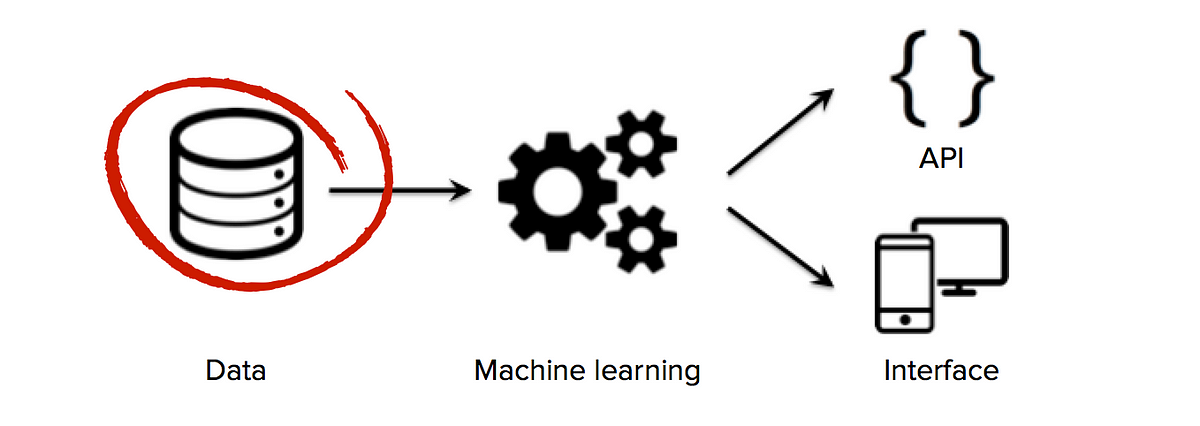
The “unreasonable effectiveness” of data for machine-learning applications has been widely debated over the years (see here, here and…
We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation. It comprises 60,000 images of artwork from 10...
Posted by Sara Beery, Student Researcher, and Jonathan Huang, Research Scientist, Google Research, Perception Team Over four billion people live in...

When AllMusic launched 25 years ago, it wasn't an obvious big data play. But it became one. Hidden in its millions of entries is music's collective history.

To understand what's happening, but also what's coming if synthetic data does get more broadly adopted, we talked to various CEOs and VCs over the last few months.

How you can pull one of a few dozen example political, sporting, education, and other frames on-the-fly.
Our zip code database is a unified view of public datasets like the Census, American Community Survey, Bureau of Labor Statistics and the CDC, spanning 800+ data points, also offering a free zip code database.
Best-practices to follow when building datasets from large pools of image and video data and tools that make it straightforward.

MedMNIST v2 is a large-scale MNIST-like collection of standardized biomedical images, including 12 datasets for 2D and 6 datasets for 3D. All images are pre-processed into 28 x 28 (2D) or 28 x 28 x 28 (3D) with the corresponding classification labels, so that no background knowledge is required for users. Covering primary data modalities in biomedical images, MedMNIST v2 is designed to perform classification on lightweight 2D and 3D images with various data scales (from 100 to 100,000) and diverse tasks (binary/multi-class, ordinal regression and multi-label). The resulting dataset, consisting of 708,069 2D images and 10,214 3D images in total, could support numerous research / educational purposes in biomedical image analysis, computer vision and machine learning. Description and image from: MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification Each subset keeps the same license as that of the source dataset. Please also cite the corresponding paper of source data if you use any subset of MedMNIST.
With an estimated 44 zettabytes of data in existence in our digital world today and approximately 2.5 quintillion bytes of new data generated daily, there is a lot of data out there you could tap into for your data science projects. It's pretty hard to curate through such a massive…

In this article, I'm going to walk you through a tutorial on web scraping to create a dataset using Python and BeautifulSoup.
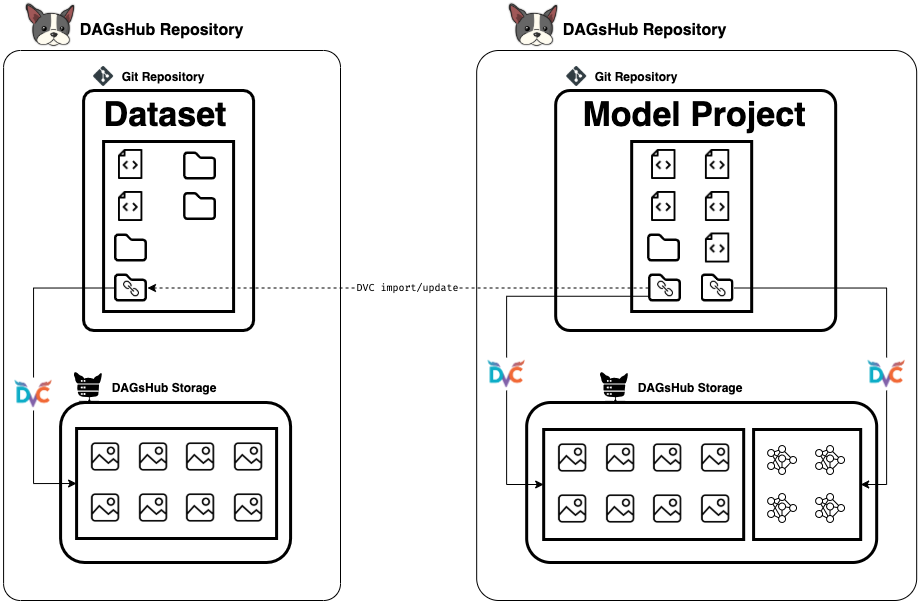
Create, maintain, and contribute to a long-living dataset that will update itself automatically across projects.
Discover datasets around the world!
This is an interface for searching and browsing the UMLS Metathesaurus data. Our goal here is to present the UMLS Metathesaurus data in a useful way.

Emotional development is one of the largest and most productive areas of psychological research. For decades, researchers have been fascinated by how humans respond to, detect, and interpret emotional facial expressions. Much of the research in this area ...
The power of join keys and how data standards can make data more valuable and accelerate collaboration and innovation. This is the second installment of the DaaS Bible series.

Special thanks to Plotly investor, NVIDIA, for their help in reviewing these open-source Dash applications for autonomous vehicle R&D, and Lyft for initial data visualization development in Plotly. Author: Xing Han Lu, @xhlulu (originally posted on Medium) ???? To learn more about how to use Dash for Autonomous Vehicle and AI Applications register for our live webinar with […]
Learn about and download U.S. Board on Geographic Names data from the Geographic Names Information System (GNIS)

A different approach to import data files automatically in python.

How to create time series datasets with different patterns
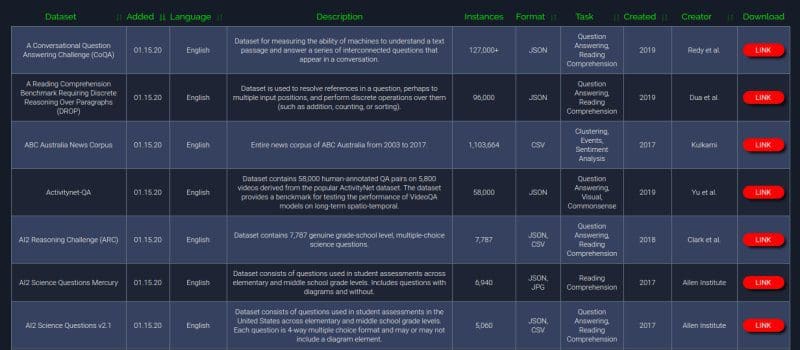
Check out this database of nearly 300 freely-accessible NLP datasets, curated from around the internet.
Connect APIs, remarkably fast. Free for developers. - PipedreamHQ/pipedream

You need to analyze data to make more informed decisions. There are many tools to help you analyze the data visually or statistically, but they only work if the data is already clean and consistent. Here is the list of 5 data cleansing Tools. Drake Drake is a simple-to-use, extensible, text-based data workflow tool that… Read More »5 Data Cleansing Tools

"Enter into picture Swarmplots, just like their name." https://lttr.ai/MJtZ #datavisualization #awesomevisualization #seaborn #python

This post is about explaining the various techniques you can use to handle imbalanced datasets

The most comprehensive visualization of U.S. public data. Data USA provides an open, easy-to-use platform that turns data into knowledge.

First trips to Paris all run the same risk: that of the museums consuming all of one's time in the city. What those new to Paris need is a museum-going strategy, not that one size will fit all.
Atlas: A Dataset and Benchmark for E-commerce Clothing Product Categorization - vumaasha/Atlas

When computer vision detectors are turned loose in the real world, their performance noticeably drops. In an effort to close this performance gap, a team of MIT and IBM researchers set out to create a very different kind of object-recognition dataset called ObjectNet.
Homepage for the National Football League's Big Data Bowl - nfl-football-ops/Big-Data-Bowl

Baidu this Thursday announced the release of ApolloScape, billed as the world’s largest open-source dataset for autonomous driving…




