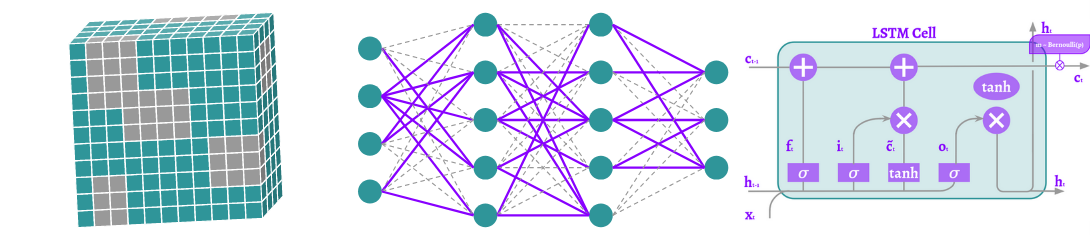
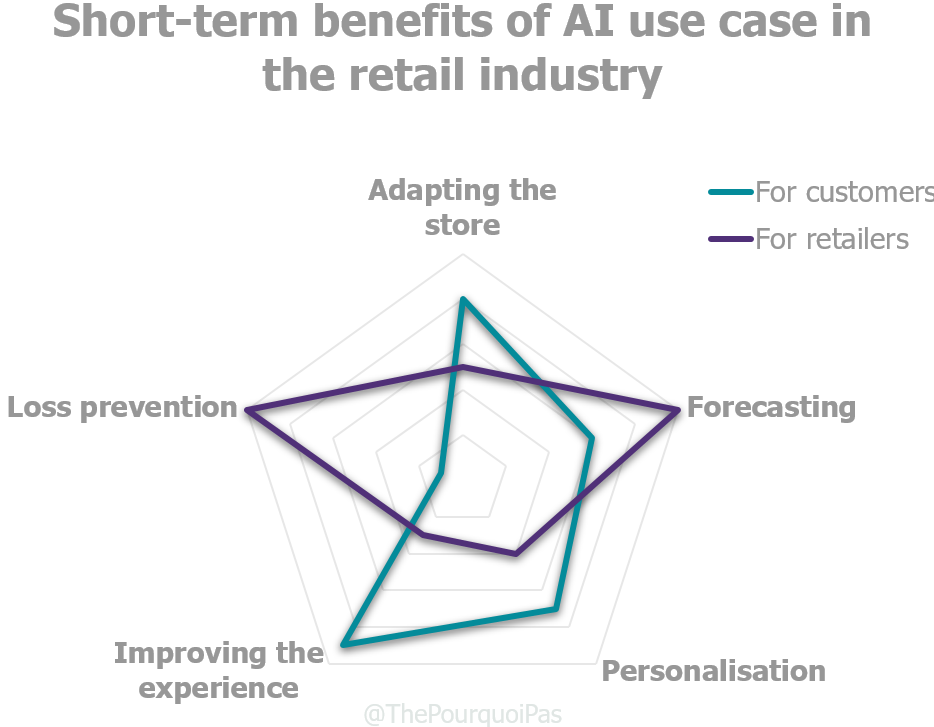
deep-learning

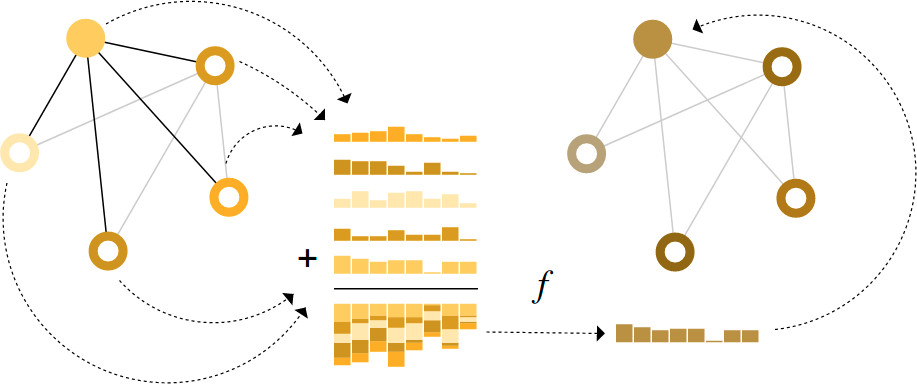
What components are needed for building learning algorithms that leverage the structure and properties of graphs?
BERT is an open source machine learning framework for natural language processing (NLP) that helps computers understand ambiguous language by using context

The latest effort, from the Mayo Clinic, holds some clues.

We picked 50 paper/models/blogs across 10 fields in AI Eng: LLMs, Benchmarks, Prompting, RAG, Agents, CodeGen, Vision, Voice, Diffusion, Finetuning. If you're starting from scratch, start here.

AI art generation has entered an era of evolution over revolution

Musings on systems, information, learning, and optimization.
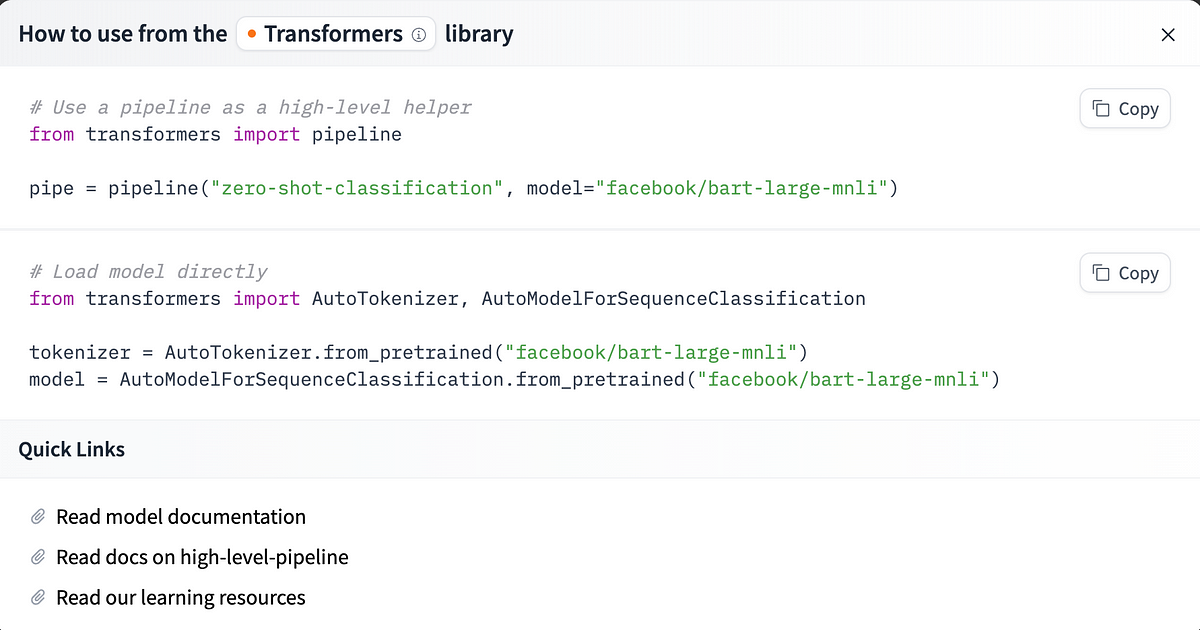
Pulling pre-trained models out of the box for your use case

Where can you find projects dealing with advanced ML topics? GitHub is a perfect source with its many repositories. I’ve selected ten to talk about in this article.
Aman's AI Journal | Course notes and learning material for Artificial Intelligence and Deep Learning Stanford classes.


In this article, I'll take you through a list of guided projects to master AI & ML with Python. AI & ML Projects with Python.


Deep learning is crucial in today's age as it powers advancements in artificial intelligence, enabling applications like image and speech recognition, language translation, and autonomous vehicles. Understanding deep learning equips individuals to harness its potential, driving innovation and solving complex problems across various industries. This article lists the top Deep Learning and Neural Networks books to help individuals gain proficiency in this vital field and contribute to its ongoing advancements and applications. Deep Learning (Adaptive Computation and Machine Learning series) This book covers a wide range of deep learning topics along with their mathematical and conceptual background. Additionally, it offers

Multi-layer perceptrons (MLPs), or fully-connected feedforward neural networks, are fundamental in deep learning, serving as default models for approximating nonlinear functions. Despite their importance affirmed by the universal approximation theorem, they possess drawbacks. In applications like transformers, MLPs often monopolize parameters and lack interpretability compared to attention layers. While exploring alternatives, such as the Kolmogorov-Arnold representation theorem, research has primarily focused on traditional depth-2 width-(2n+1) architectures, neglecting modern training techniques like backpropagation. Thus, while MLPs remain crucial, there's ongoing exploration for more effective nonlinear regressors in neural network design. MIT, Caltech, Northeastern researchers, and the NSF Institute for AI and

Deep learning architectures have revolutionized the field of artificial intelligence, offering innovative solutions for complex problems across various domains, including computer vision, natural language processing, speech recognition, and generative models. This article explores some of the most influential deep learning architectures: Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), Transformers, and Encoder-Decoder architectures, highlighting their unique features, applications, and how they compare against each other. Convolutional Neural Networks (CNNs) CNNs are specialized deep neural networks for processing data with a grid-like topology, such as images. A CNN automatically detects the important features without any human supervision.

Is Attention all you need? Mamba, a novel AI model based on State Space Models (SSMs), emerges as a formidable alternative to the widely used Transformer models, addressing their inefficiency in processing long sequences.
Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied...
This projects contains different conformal methods and approaches. Includes code generated for a experimental evaluation of a multidimensional, low-sample size biomedical dataset of oncological sub...
Why is Adam the most popular optimizer in Deep Learning? Let's understand it by diving into...
[Special thank you to Ian Kivlichan for many useful pointers (E.g. the 100+ year old Nature paper “Vox populi”) and nice feedback. 🙏 ] High-quality data is the fuel for modern data deep learning model training. Most of the task-specific labeled data comes from human annotation, such as classification task or RLHF labeling (which can be constructed as classification format) for LLM alignment training. Lots of ML techniques in the post can help with data quality, but fundamentally human data collection involves attention to details and careful execution.


Understanding how convolutional neural networks (CNNs) operate is essential in deep learning. However, implementing these networks, especially convolutions and gradient calculations, can be challenging. Many popular frameworks like TensorFlow and PyTorch exist, but their complex codebases make it difficult for newcomers to grasp the inner workings. Meet neograd, a newly released deep learning framework developed from scratch using Python and NumPy. This framework aims to simplify the understanding of core concepts in deep learning, such as automatic differentiation, by providing a more intuitive and readable codebase. It addresses the complexity barrier often associated with existing frameworks, making it easier for
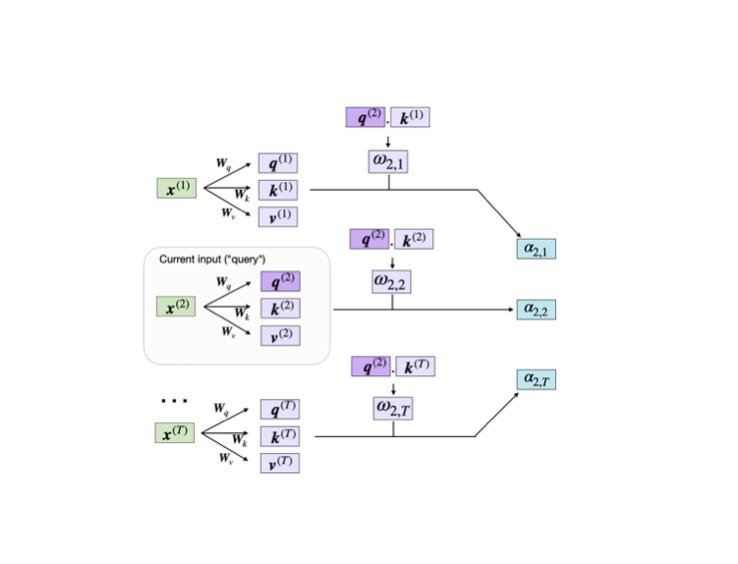
This article will teach you about self-attention mechanisms used in transformer architectures and large language models (LLMs) such as GPT-4 and Llama.

Theory and PyTorch Implementation
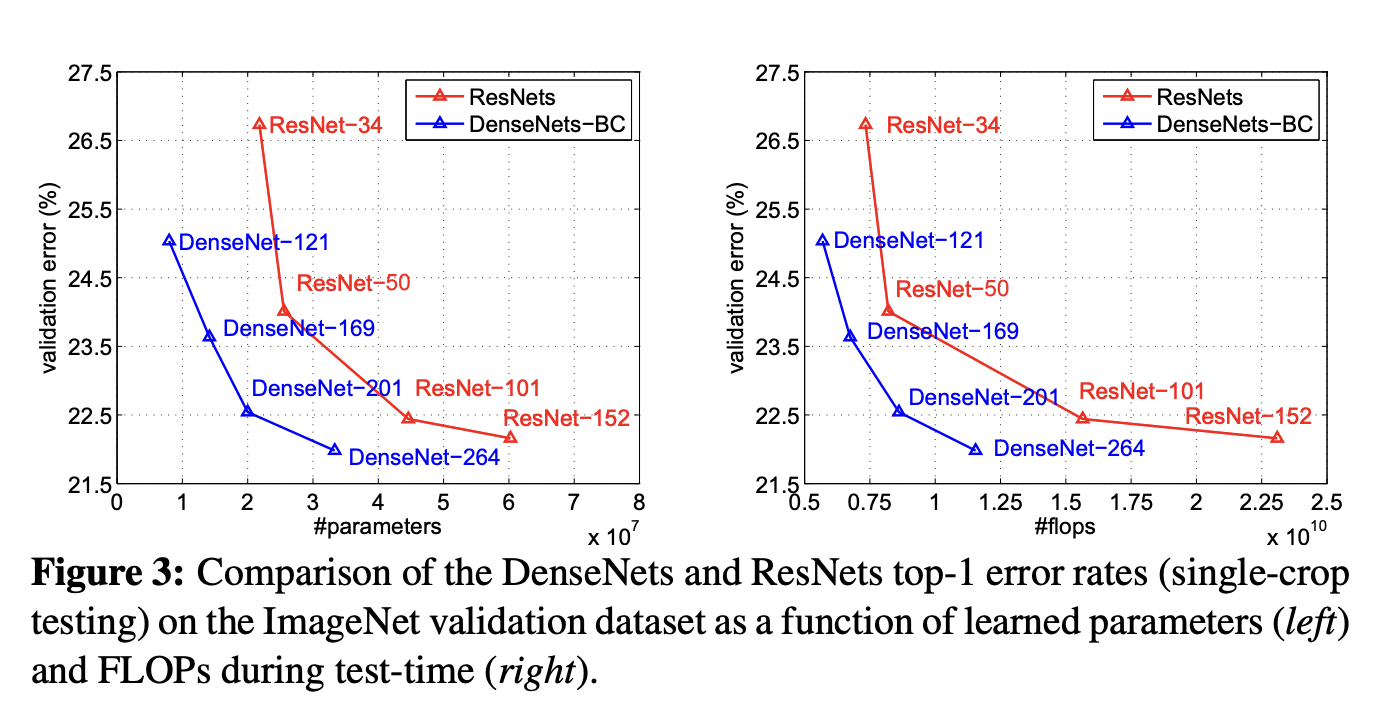
In this article we will learn about its definition, differences and how to calculate FLOPs and MACs using Python packages.
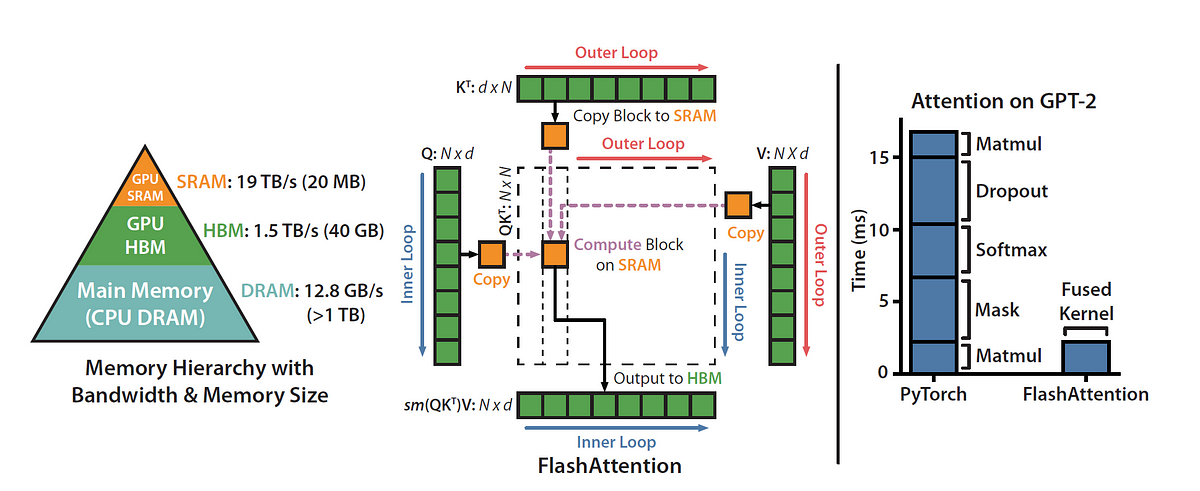
Step by step explanation of how one of the most important MLSys breakthroughs work — in gory detail.

A beginner's guide to understanding autonomous AI agents and their importance.

GPUs may dominate, but CPUs could be perfect for smaller AI models

Stanford team achieves first-ever optical backpropagation milestone
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and...

Explore what LLMs are, how they work, and gain insights into real-world examples, use cases, and best practices.

One of the creators of the famous BLIP-2 model shares his insights about the current state of multimodal generative AI.

If you're looking for a way to improve the performance of your large language model (LLM) application while reducing costs, consider utilizing a semantic cache to store LLM responses.

AI-generated images have never been more popular, and Midjourney is one of the best tools. Here's how to access the AI and what to know about using it.

A new technical paper titled “TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings” was published by researchers at Google. Abstract: “In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer... » read more
Sponsored Feature: Training an AI model takes an enormous amount of compute capacity coupled with high bandwidth memory. Because the model training can be
Start with Autoencoders to better understand GANs
I explain what is so unique about the RWKV language model.

Mike Wheatley / SiliconANGLE: Cerebras open sources seven GPT-based LLMs, ranging from 111M to 13B parameters and trained using its Andromeda supercomputer for AI, on GitHub and Hugging Face

Who Is publishing the most Impactful AI research right now? With the breakneck pace of innovation in AI, it is crucial to pick up some signal as soon as possible. No one has the time to read everything, but these 100 papers are sure to bend the road as to where our AI technology is going. The real test of impact of R&D teams is of course how the technology appears in products, and OpenAI shook the world by releasing ChatGPT at the end of November 2022, following fast on their March 2022 paper “T

A list of artificial intelligence used in semiconductor manufacturing tools from February 2023.
The top ML Papers of the Week (Mar 6 - Mar 12)

A new technical paper titled “APOSTLE: Asynchronously Parallel Optimization for Sizing Analog Transistors Using DNN Learning” was published by researchers at UT Austin and Analog Devices. Abstract “Analog circuit sizing is a high-cost process in terms of the manual effort invested and the computation time spent. With rapidly developing technology and high market demand, bringing... » read more

LLaMA-13B reportedly outperforms ChatGPT-like tech despite being 10x smaller.
Posted by Sanjiv Kumar, VP and Google Fellow, Google Research (This is Part 4 in our series of posts covering different topical areas of research a...
Many new Transformer architecture improvements have been proposed since my last post on “The Transformer Family” about three years ago. Here I did a big refactoring and enrichment of that 2020 post — restructure the hierarchy of sections and improve many sections with more recent papers. Version 2.0 is a superset of the old version, about twice the length. Notations Symbol Meaning $d$ The model size / hidden state dimension / positional encoding size.
A critical analysis of Google’s impressive new text-to-image generation tool

The regurgitation of training data exposes image diffusion models to a number of privacy and copyright risks.
Find it here, via Ryan Watkins. Further improvement is required, but the pace of current breakthroughs is remarkable.
During the last two years there has been a plethora of large generative models such as ChatGPT or Stable Diffusion that have been published. Concretely, these models are able to perform tasks such...
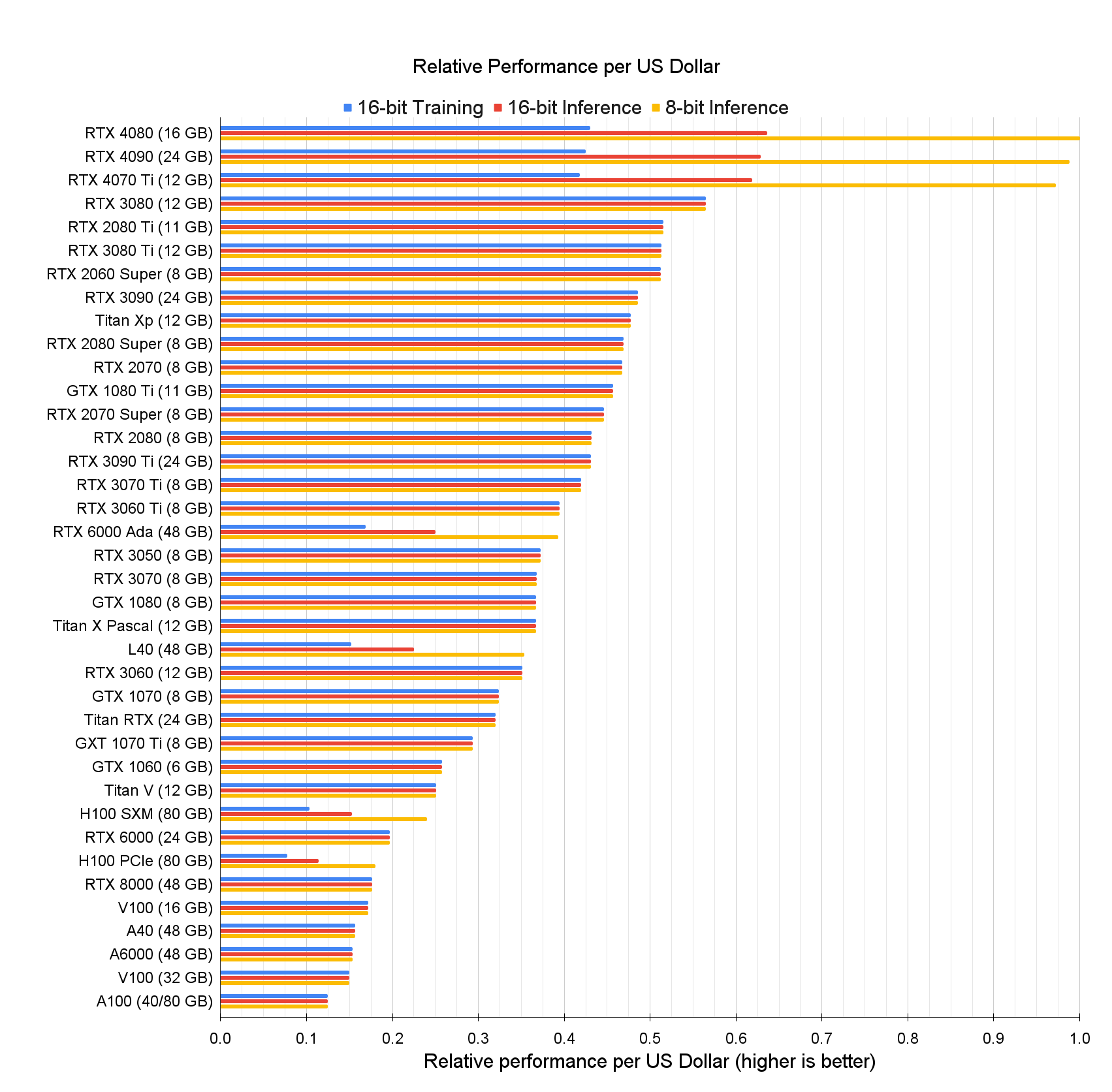
Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.
An example use case of using Variational Autoencoders (VAE) to detect anomalies in all types of data
Wasserstein distance helps WGANs outperform vanilla GANs and VAEs. This post explains why so using some easy math.

Many developers who use Python for machine learning are now switching to PyTorch. Find out why and what the future could hold for TensorFlow.

Geoffrey Hinton, professor at the University of Toronto and engineering fellow at Google Brain, recently published a paper on the Forward-Forward algorithm (FF), a technique for training neural networks that uses two forward passes of data through the network, instead of backpropagation, to update the model weights.

Judea Pearl, a pioneering figure in artificial intelligence, argues that AI has been stuck in a decades-long rut. His prescription for progress? Teach machines to understand the question why.
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch

The wave of enthusiasm around generative networks feels like another Imagenet moment - a step change in what ‘AI’ can do that could generalise far beyond the cool demos. What can it create, and where are the humans in the loop?

Alphabet's DeepMind has built an AI tool that can help generate rough film and stage scripts Engadget's Kris Holt reports: Dramatron is a so-called "co-writing" tool that can generate character descriptions, plot points, location descriptions and dialogue. The idea is that human writers will be abl...
Adapting federated learning to your own datasets

The first obvious casualty of large language models is homework: the real training for everyone, though, and the best way to leverage AI, will be in verifying and editing information.

An intuitive understanding of how AI-generated art is made by Stable Diffusion, Midjourney, or DALL-E

Everything you need to know to use YOLOv7 in custom training scripts
Introduction to reinforcement learning terminologies, basics, and concepts (model-free, model-based, online, offline RL)

The world's largest chip scales to new heights.

Scientist Gary Marcus argues that “deep learning” is not the only path to true artificial intelligence.
Pure python implementation of product quantization for nearest neighbor search - matsui528/nanopq
The best indexing approach for billion-sized vector datasets

Find out how the inverted file index (IVF) is implemented alongside product quantization (PQ) for a fast and efficient approximate nearest…
Efficient vector quantization for machine learning optimizations (eps. vector quantized variational autoencoders), better than straight…

If you thought text-to-image AI was unbelievable, wait until you see how it compresses images.
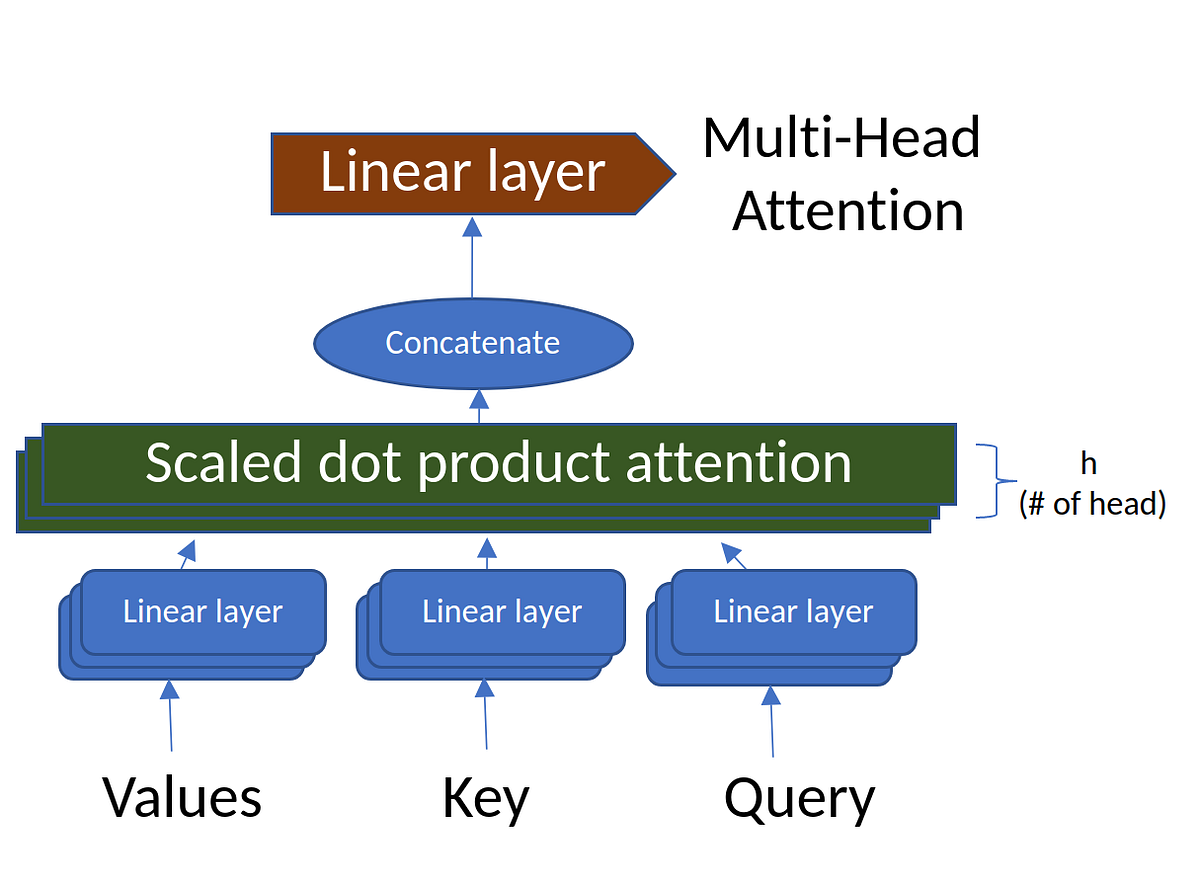
Attention, Self-Attention, Multi-head Attention, Masked Multi-head Attention, Transformers, BERT, and GPT
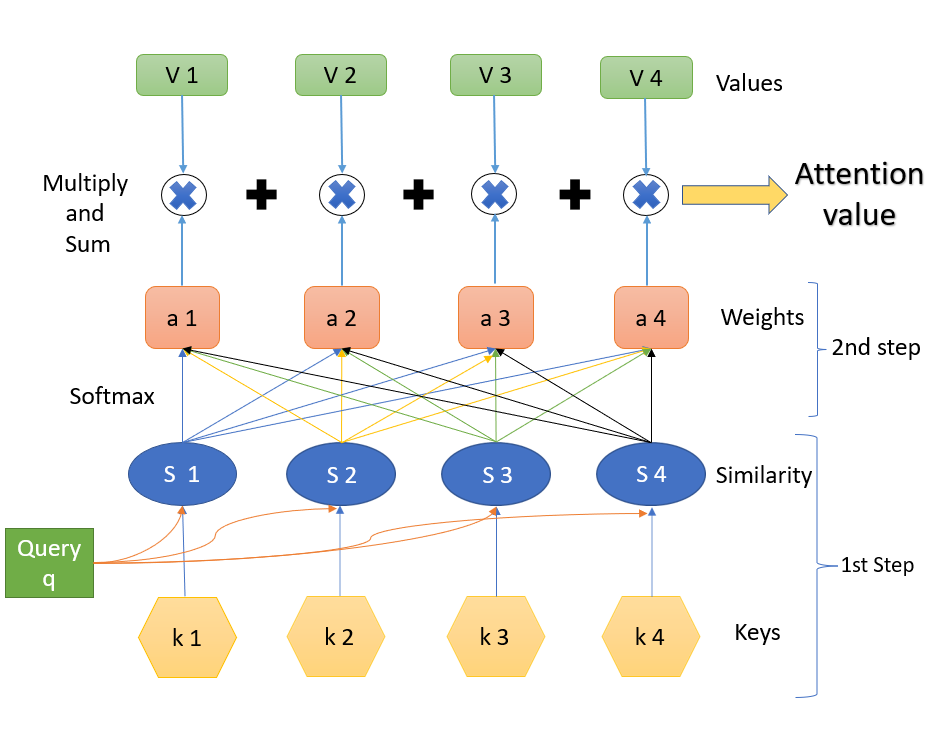
Attention, Self-Attention, Multi-head Attention, and Transformers


this post is explaining how permutation importance works and how we can code it using ELI5

To mark the occasion of the eighth Federated Logic Conference (FloC), Amazon’s Byron Cook, Daniel Kröning, and Marijn Heule discussed automated reasoning’s prospects.
The brain, the mathematics, and DL — research frontiers in 2022
The fastai book, published as Jupyter Notebooks.
Interactive deep learning book with multi-framework code, math, and discussions. Adopted at 500 universities from 70 countries including Stanford, MIT, Harvard, and Cambridge. - d2l-ai/d2l-en

An overview of DCGAN architecture with a step-by-step guide to building it yourself
We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation. It comprises 60,000 images of artwork from 10...

Posted by Ethan Dyer and Guy Gur-Ari, Research Scientists, Google Research, Blueshift Team Language models have demonstrated remarkable performance...

Learn how Imagen generates photorealistic images given only a text description.

We used GPT-3 and DALL·E to generate a children's storybook about Ash and Pikachu vs. Team Rocket. Read the story and marvel at the AI-generated visuals!
A detailed step-by-step explanation of how to build an image-captioning model in Pytorch

In a recent policy change, Google has banned deepfake-generating AI projects from Colab, its platform for hosting and running arbitrary Python code.

Dall-E can illustrate just about anything using a short text prompt. Should it?


PimEyes is a paid service that finds photos of a person from across the internet, including some the person may not want exposed. “We’re just a tool provider,” its owner said.

A comparison between Undercomplete and Sparse AE with a detailed Python example

The researchers are considered a key to the company’s future. But they have had a hard time shaking infighting and controversy over a variety of issues.
We describe the new field of mathematical analysis of deep learning. This field emerged around a list of research questions that were not answered within the classical framework of learning...

Posted by Sharan Narang and Aakanksha Chowdhery, Software Engineers, Google Research In recent years, large neural networks trained for language un...
What is an Autoencoder, and how to build one in Python?

It takes a human being around 0.1 to 0.4 seconds to blink. In even less time, an AI-based inverse rendering process developed by NVIDIA can generate a 3D scene from 2D photos.

They can help you get an appointment or order a pizza, find the best ticket deals and bring your...


Machine learning is a subfield of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way people learn, progressively improving its accuracy. This way, Machine Learning is one of the most interesting methods in Computer Science these days, and it'
based on "Hands-On Machine Learning with Scikit-Learn & TensorFlow" (O'Reilly, Aurelien Geron) - bjpcjp/scikit-and-tensorflow-workbooks
based on "Hands-On Machine Learning with Scikit-Learn & TensorFlow" (O'Reilly, Aurelien Geron) - bjpcjp/scikit-and-tensorflow-workbooks
The second edition of Deep Learning Interviews is home to hundreds of fully-solved problems, from a wide range of key topics in AI. It is designed to both rehearse interview or exam specific...
Best-practices to follow when building datasets from large pools of image and video data and tools that make it straightforward.
Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets...
Is it possible to define a coefficient of correlation which is (a) as simple as the classical coefficients like Pearson's correlation or Spearman's correlation, and yet (b) consistently estimates...

The firm pivoted away from riskier spiking neural networks using a new power management scheme

Should you use PyTorch vs TensorFlow in 2023? This guide walks through the major pros and cons of PyTorch vs TensorFlow, and how you can pick the right framework.
Interactive Tools for Machine Learning, Deep Learning and Math - Machine-Learning-Tokyo/Interactive_Tools

As we previously reported, Google unveiled its second-generation TensorFlow Processing Unit (TPU2) at Google I/O last week. Google calls this new

Nvidia has staked its growth in the datacenter on machine learning. Over the past few years, the company has rolled out features in its GPUs aimed neural

Researchers from Baidu’s Silicon Valley AI Lab (SVAIL) have adapted a well-known HPC communication technique to boost the speed and scale of their neural network training and now they are […]
In this work, we analyze the performance of neural networks on a variety of heterogenous platforms. We strive to find the best platform in terms of raw benchmark performance, performance per watt a…
Python library for computer vision labeling tasks. The core functionality is to translate bounding box annotations between different formats-for example, from coco to yolo. - GitHub - pylabel-proj...
Google did its best to impress this week at its annual IO conference. While Google rolled out a bunch of benchmarks that were run on its current Cloud TPU

Four years ago, Google started to see the real potential for deploying neural networks to support a large number of new services. During that time it was
The rise of deep-learning (DL) has been fuelled by the improvements in accelerators. GPU continues to remain the most widely used accelerator for DL applications. We present a survey of architectur…

Currently there are more than 100 companies all over the world building ASIC’s (Application specific integrated circuit) or SOC’s (System…

GPU Computing for Data Science - Download as a PDF or view online for free

This tutorial describes methods to enable efficient processing for deep neural networks (DNNs), which are used in many AI applications including computer vision, speech recognition, robotics, etc....
A curated list of the latest breakthroughs in AI (in 2021) by release date with a clear video explanation, link to a more in-depth article, and code. - louisfb01/best_AI_papers_2021

Over the last two years, there has been a push for novel architectures to feed the needs of machine learning and more specifically, deep neural networks.

From Sensory Substitution to Decision Transformers, Persistent Evolution Strategies and Sharpness-Aware Minimization
An overview of some of the leading libraries and frameworks out there
An overview of some of the leading libraries and frameworks out there

MedMNIST v2 is a large-scale MNIST-like collection of standardized biomedical images, including 12 datasets for 2D and 6 datasets for 3D. All images are pre-processed into 28 x 28 (2D) or 28 x 28 x 28 (3D) with the corresponding classification labels, so that no background knowledge is required for users. Covering primary data modalities in biomedical images, MedMNIST v2 is designed to perform classification on lightweight 2D and 3D images with various data scales (from 100 to 100,000) and diverse tasks (binary/multi-class, ordinal regression and multi-label). The resulting dataset, consisting of 708,069 2D images and 10,214 3D images in total, could support numerous research / educational purposes in biomedical image analysis, computer vision and machine learning. Description and image from: MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification Each subset keeps the same license as that of the source dataset. Please also cite the corresponding paper of source data if you use any subset of MedMNIST.
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental...

PyTorch Lightning has opened many new possibilities in deep learning and machine learning with a high level interface that makes it quicker to work with PyTorch.

Revealing whats behind the state-of-the art algorithm HRNet
Are there any limits to large neural networks?

A primer on automated story generation and how it it strikes at some fundamental research questions in artificial intelligence.

A guide on object detection algorithms and libraries that covers use cases, technical details, and offers a look into modern applications.
The ten essential computer vision terminologies that everyone should learn to become more proficient at computer vision with sample codes

According to the paper, their findings imply that facial recognition systems are “extremely vulnerable.”
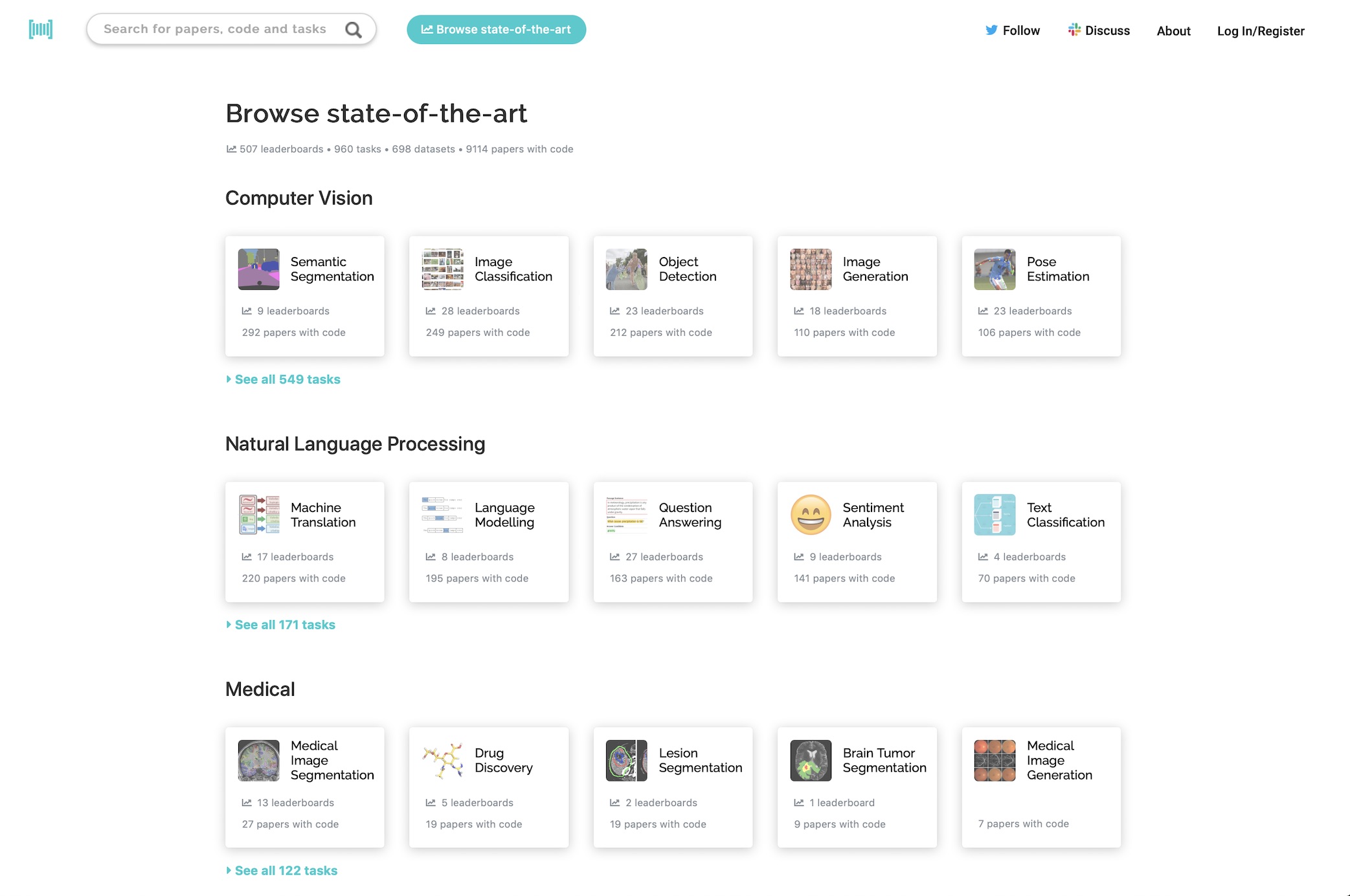
Papers With Code highlights trending Machine Learning research and the code to implement it.
Summary: We have released GPT-J-6B, 6B JAX-based (Mesh) Transformer LM (Github).GPT-J-6B performs nearly on par with 6.7B GPT-3 (or Curie) on various zero-shot down-streaming tasks.You can try out …


For all their triumphs, AI systems can’t seem to generalize the concepts of “same” and “different.” Without that, researchers worry, the quest to create truly intelligent machines may be hopeless.

Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As

Current custom AI hardware devices are built around super-efficient, high performance matrix multiplication. This category of accelerators includes the

Reconstructing Images using Reinforcement Learning and Genetic Algorithms

We’re on a journey to advance and democratize artificial intelligence through open source and open science.

In August, I set out to improve the machine learning ecosystem for Ruby and wasn’t sure where it would go. Over the next 5 months, I ended up...
BAAI conference presented Wu Dao 2.0. The most powerful AI to date.
This repository contains demos I made with the Transformers library by HuggingFace. - NielsRogge/Transformers-Tutorials

Sentiment Analysis, or Opinion Mining, is a subfield of NLP (Natural Language Processing) that aims to extract attitudes, appraisals, opinions, and emotions from text. Inspired by the rapid migration…

Evaluating object detection models is not straightforward because each image can have many objects and each object can belong to different classes. This means that we need to measure if the model…
Musings of a Computer Scientist.


In 2020-21, we celebrate that many of the basic ideas behind the Deep Learning Revolution were published three decades ago within fewer than 12 months in our "Annus Mirabilis" 1990-91
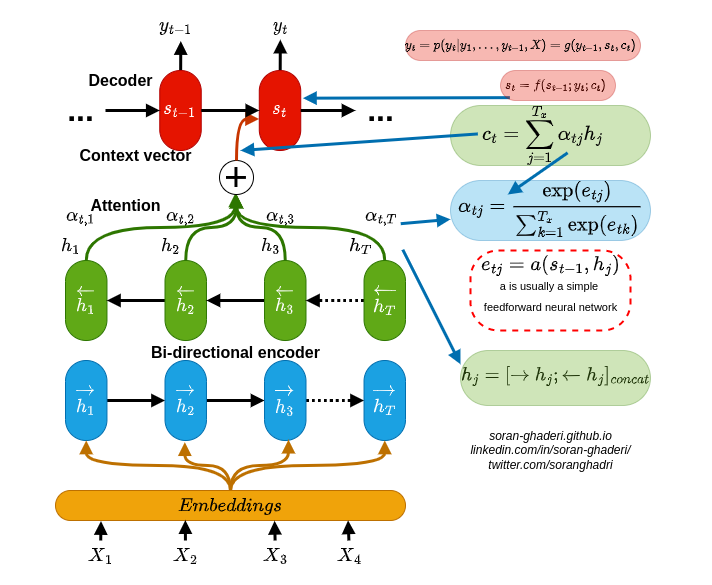
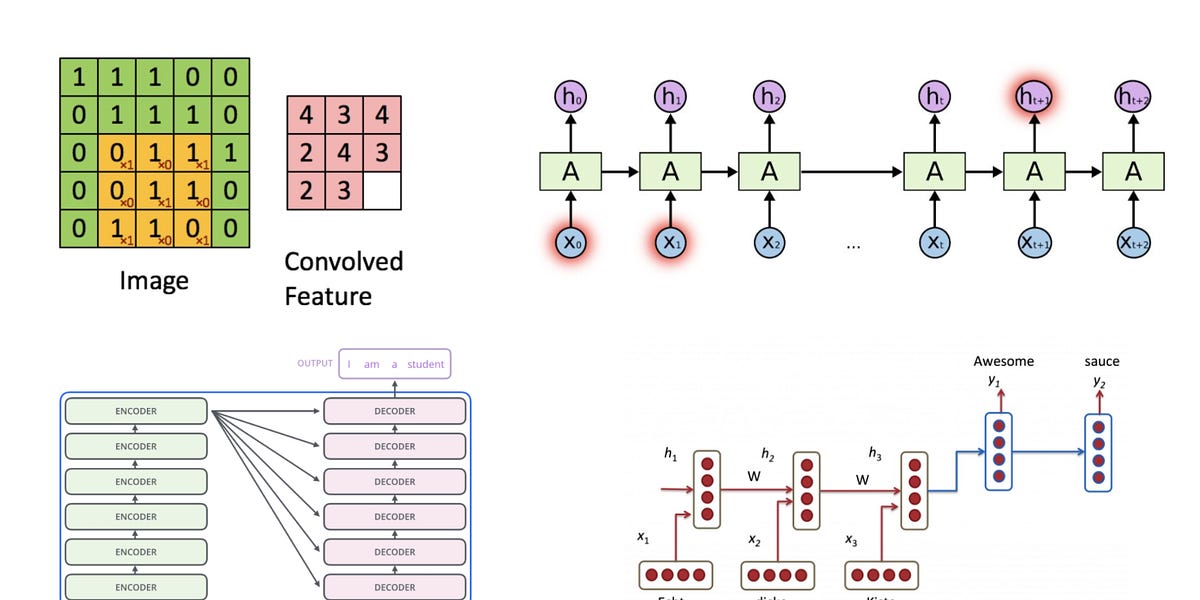
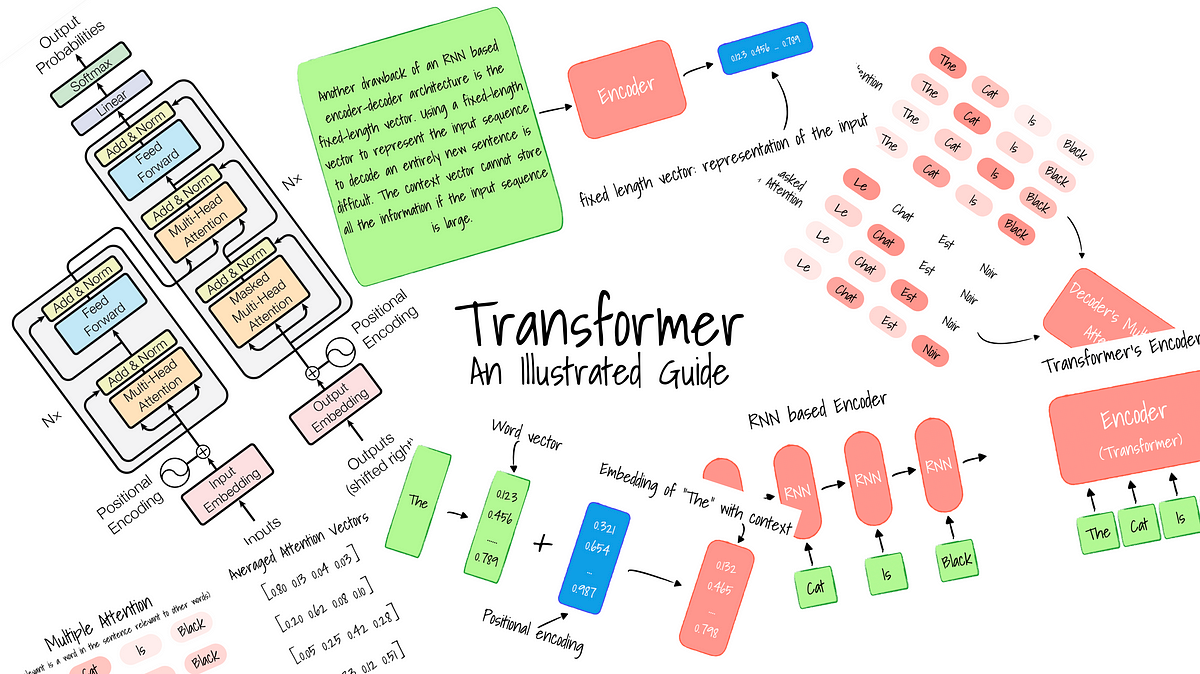
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Italian, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing this post Featured in courses at Stanford, Harvard, MIT, Princeton, CMU and others In the previous post, we looked at Attention – a ubiquitous method in modern deep learning models. Attention is a concept that helped improve the performance of neural machine translation applications. In this post, we will look at The Transformer – a model that uses attention to boost the speed with which these models can be trained. The Transformer outperforms the Google Neural Machine Translation model in specific tasks. The biggest benefit, however, comes from how The Transformer lends itself to parallelization. It is in fact Google Cloud’s recommendation to use The Transformer as a reference model to use their Cloud TPU offering. So let’s try to break the model apart and look at how it functions. The Transformer was proposed in the paper Attention is All You Need. A TensorFlow implementation of it is available as a part of the Tensor2Tensor package. Harvard’s NLP group created a guide annotating the paper with PyTorch implementation. In this post, we will attempt to oversimplify things a bit and introduce the concepts one by one to hopefully make it easier to understand to people without in-depth knowledge of the subject matter. 2020 Update: I’ve created a “Narrated Transformer” video which is a gentler approach to the topic: A High-Level Look Let’s begin by looking at the model as a single black box. In a machine translation application, it would take a sentence in one language, and output its translation in another.

How this novel neural network architecture changes the way we analyze complex data types, and powers revolutionary models like GPT-3 and BERT.

Google detailed TPUv4 at Google I/O 2021. They're accelerator chips that deliver high performance on AI workloads.
A cloud-native vector database, storage for next generation AI applications - milvus-io/milvus
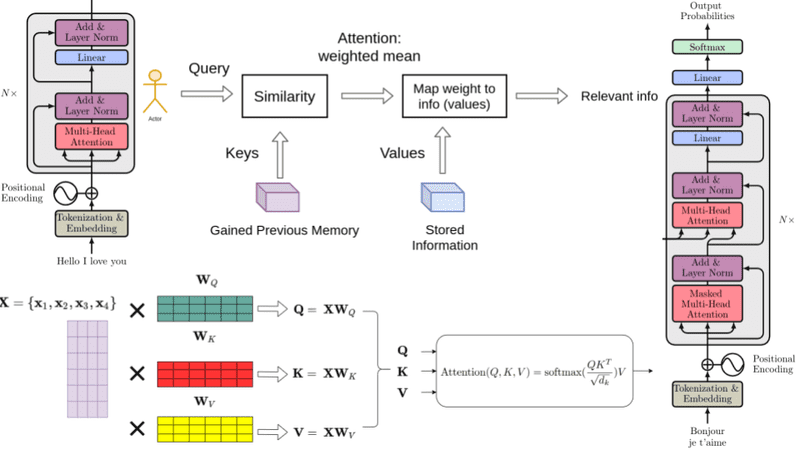
An intuitive understanding on Transformers and how they are used in Machine Translation. After analyzing all subcomponents one by one such as self-attention and positional encodings , we explain the principles behind the Encoder and Decoder and why Transformers work so well
Combining data science and econometrics for an introduction to the DeepIV framework, including a full Python code tutorial.


Pushing AI to the edge requires new architectures, tools, and approaches.
The last decade has witnessed an experimental revolution in data science and machine learning, epitomised by deep learning methods. Indeed, many high-dimensional learning tasks previously thought...


Computer vision is the field of computer science that focuses on replicating parts of the complexity...
This blog post is part of a mini-series that talks about the different aspects of building a PyTorch Deep Learning project using Variational Autoencoders. In Part 1, we looked at the variational…
:pencil2: Web-based image segmentation tool for object detection, localization, and keypoints - jsbroks/coco-annotator

Rice University computer scientists have demonstrated artificial intelligence (AI) software that runs on commodity processors and trains deep neural networks 15 times faster than platforms based on graphics ...
See how to build end-to-end NLP pipelines in a fast and scalable way on GPUs — from feature engineering to inference.
Keep your neural network alive by understanding the downsides of ReLU

Reinforcement learning (RL) is a powerful type of AI technology that can learn strategies to optimally control large, complex systems.
Algorithms off the convex path.
In recent years, GANs (generative adversarial networks) have been all the rage in the field of deep-learning generative models, leaving…

The dogfighting AI DARPA is developing is set to make the challenging migration from a synthetic environment to the real world soon.

Computer scientists from the University at Buffalo used the method to successfully detect Deepfakes taken from This Person Does Not Exist.
340 votes, 28 comments. If anyone wants to brush up on recent methods in EBMs, Normalizing Flows, GANs, VAEs, and Autoregressive models, I just…

Deep Nostalgia AI brings your photos to life just like in the Harry Potter movies.

Building an app for blood cell count detection.

The NLP application ecosystem is in its earliest stages, and it's not yet clear whether GPT-3 or a different model will be the foundation.
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F5812%2F1601307462_Lung-Scan_2880x1860_Lede.jpg)
The laws of physics stay the same no matter one’s perspective. Now this idea is allowing computers to detect features in curved and higher-dimensional space.
The principle of equivariance to symmetry transformations enables a theoretically grounded approach to neural network architecture design. Equivariant networks have shown excellent performance and...
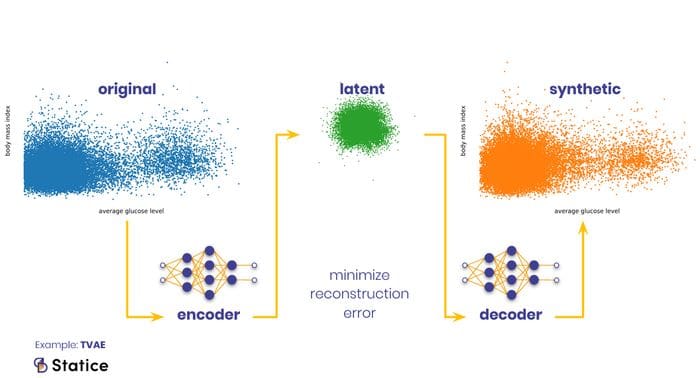
Synthetic data can be used to test new products and services, validate models, or test performances because it mimics the statistical property of production data. Today you'll find different types of structured and unstructured synthetic data.

The error backpropagation learning algorithm is a supervised learning technique for neural networks that calculates the gradient of descent for weighting different variables.

A simple technique for boosting accuracy on ANY model you use
The data science and artificial intelligence terms you need while reading the latest research

Speech and natural language processing (NLP) have become the foundation for most of the AI development in the enterprise today, as textual data represents a significant portion of unstructured content.

Activation functions are functions which take an input signal and convert it to an output signal. Activation functions introduce…
The ability of the Generative Adversarial Networks (GANs) framework to learn generative models mapping from simple latent distributions to arbitrarily complex data distributions has been...
Recently, a colleague of mine asked me a few questions like “why do we have so many activation functions?”, “why is that one works better…

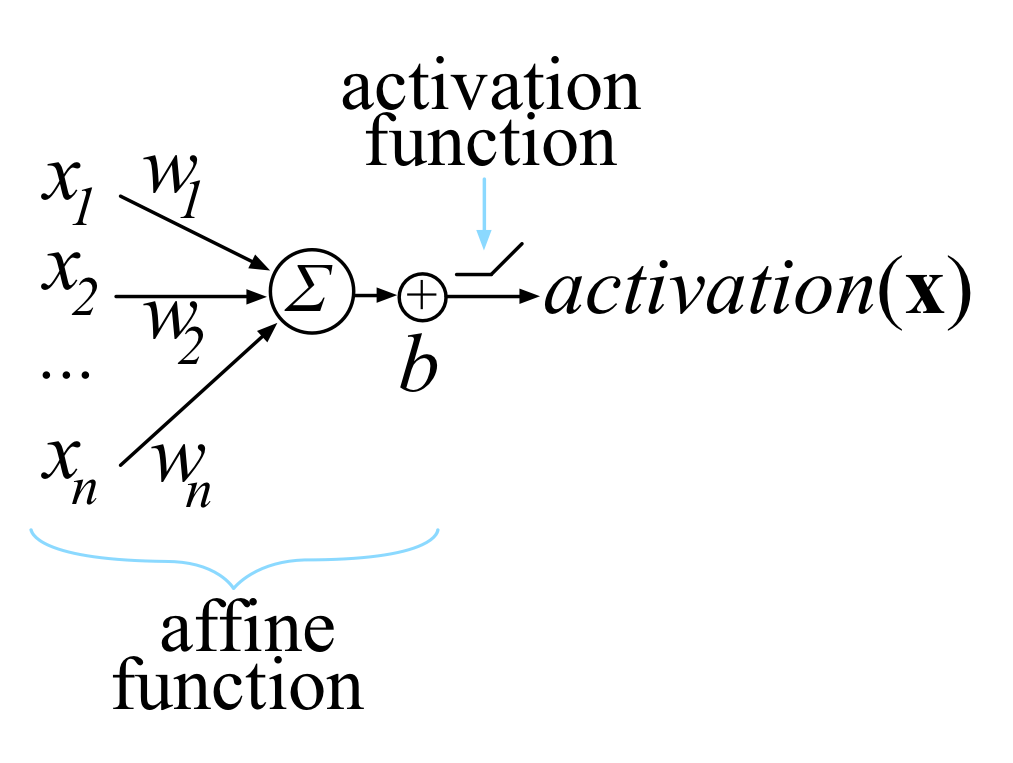
Activation functions are functions that we apply in neural networks after (typically) applying an affine transformation combining weights and input features. They are typically non-linear functions. The rectified linear unit, or ReLU, has been the most popular in the past decade, although the choice is architecture dependent and many alternatives have emerged in recent years. In this section, you will find a constantly updating list of activation functions.

Reverse engineering the curve detection algorithm from InceptionV1 and reimplementing it from scratch.
We present Text2Gestures, a transformer-based learning method to interactively generate emotive full-body gestures for virtual agents aligned with natural language text inputs. Our method generates…
The memory capacity of embedding tables in deep learning recommendation models (DLRMs) is increasing dramatically from tens of GBs to TBs across the industry. Given the fast growth in DLRMs, novel...
Classifying cross-topic natural language texts based on their argumentative structure using deep learning

The concept: When we look at a chair, regardless of its shape and color, we know that we can sit on it. When a fish is in water, regardless of its location, it knows that it can swim. This is known as the theory of affordance, a term coined by psychologist James J. Gibson. It…
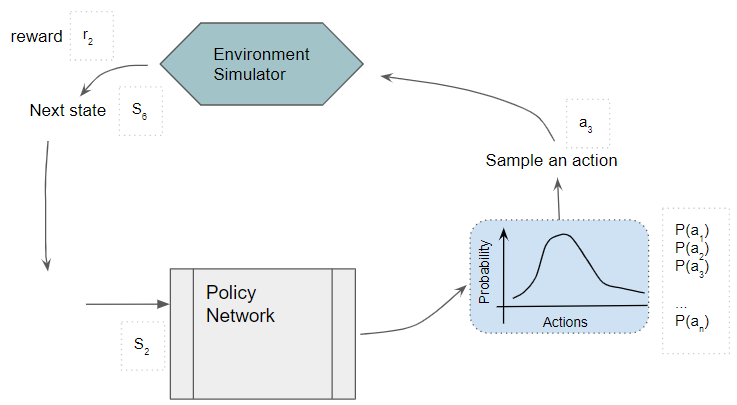
A Gentle Guide to the REINFORCE algorithm, in Plain English

Why is Model Compression important? A significant problem in the arms race to produce more accurate models is complexity, which leads to…
Papers with Code indexes various machine learning artifacts — papers, code, results — to facilitate discovery and comparison. Using this…

If you have ever had to tinker with anchor boxes, you were probably frustrated, confused and saying to yourself, “There must be another…

A recent article came out comparing public cloud providers’ face detection APIs. I was very surprised to see all of the detectors fail to…

**Pose Estimation** is a computer vision task where the goal is to detect the position and orientation of a person or an object. Usually, this is done by predicting the location of specific keypoints like hands, head, elbows, etc. in case of Human Pose Estimation. A common benchmark for this task is [MPII Human Pose](https://paperswithcode.com/sota/pose-estimation-on-mpii-human-pose) ( Image credit: [Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose](https://github.com/Daniil-Osokin/lightweight-human-pose-estimation.pytorch) )

Dimensionality reduction is the task of reducing the dimensionality of a dataset. ( Image credit: [openTSNE](https://github.com/pavlin-policar/openTSNE) )
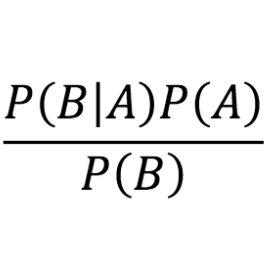
Bayesian Inference is a methodology that employs Bayes Rule to estimate parameters (and their full posterior).

**Transfer Learning** is a machine learning technique where a model trained on one task is re-purposed and fine-tuned for a related, but different task. The idea behind transfer learning is to leverage the knowledge learned from a pre-trained model to solve a new, but related problem. This can be useful in situations where there is limited data available to train a new model from scratch, or when the new task is similar enough to the original task that the pre-trained model can be adapted to the new problem with only minor modifications. ( Image credit: [Subodh Malgonde](https://medium.com/@subodh.malgonde/transfer-learning-using-tensorflow-52a4f6bcde3e) )

**Representation Learning** is a process in machine learning where algorithms extract meaningful patterns from raw data to create representations that are easier to understand and process. These representations can be designed for interpretability, reveal hidden features, or be used for transfer learning. They are valuable across many fundamental machine learning tasks like [image classification](/task/image-classification) and [retrieval](/task/image-retrieval). Deep neural networks can be considered representation learning models that typically encode information which is projected into a different subspace. These representations are then usually passed on to a linear classifier to, for instance, train a classifier. Representation learning can be divided into: - **Supervised representation learning**: learning representations on task A using annotated data and used to solve task B - **Unsupervised representation learning**: learning representations on a task in an unsupervised way (label-free data). These are then used to address downstream tasks and reducing the need for annotated data when learning news tasks. Powerful models like [GPT](/method/gpt) and [BERT](/method/bert) leverage unsupervised representation learning to tackle language tasks. More recently, [self-supervised learning (SSL)](/task/self-supervised-learning) is one of the main drivers behind unsupervised representation learning in fields like computer vision and NLP. Here are some additional readings to go deeper on the task: - [Representation Learning: A Review and New Perspectives](/paper/representation-learning-a-review-and-new) - Bengio et al. (2012) - [A Few Words on Representation Learning](https://sthalles.github.io/a-few-words-on-representation-learning/) - Thalles Silva ( Image credit: [Visualizing and Understanding Convolutional Networks](https://arxiv.org/pdf/1311.2901.pdf) )

**Object tracking** is the task of taking an initial set of object detections, creating a unique ID for each of the initial detections, and then tracking each of the objects as they move around frames in a video, maintaining the ID assignment. State-of-the-art methods involve fusing data from RGB and event-based cameras to produce more reliable object tracking. CNN-based models using only RGB images as input are also effective. The most popular benchmark is OTB. There are several evaluation metrics specific to object tracking, including HOTA, MOTA, IDF1, and Track-mAP. ( Image credit: [Towards-Realtime-MOT ](https://github.com/Zhongdao/Towards-Realtime-MOT) )

**Image Retrieval** is a fundamental and long-standing computer vision task that involves finding images similar to a provided query from a large database. It's often considered as a form of fine-grained, instance-level classification. Not just integral to image recognition alongside [classification](/task/image-classification) and [detection](/task/image-detection), it also holds substantial business value by helping users discover images aligning with their interests or requirements, guided by visual similarity or other parameters. ( Image credit: [DELF](https://github.com/tensorflow/models/tree/master/research/delf) )
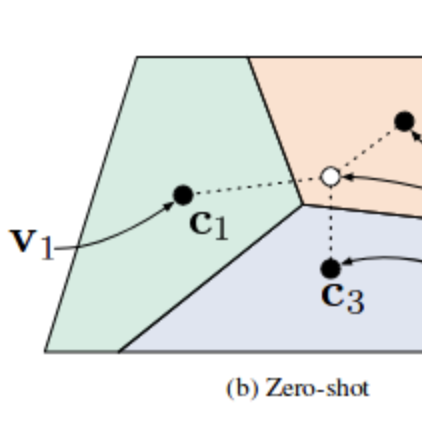
**Zero-shot learning (ZSL)** is a model's ability to detect classes never seen during training. The condition is that the classes are not known during supervised learning. Earlier work in zero-shot learning use attributes in a two-step approach to infer unknown classes. In the computer vision context, more recent advances learn mappings from image feature space to semantic space. Other approaches learn non-linear multimodal embeddings. In the modern NLP context, language models can be evaluated on downstream tasks without fine tuning. Benchmark datasets for zero-shot learning include [aPY](/dataset/apy), [AwA](/dataset/awa2-1), and [CUB](/dataset/cub-200-2011), among others. ( Image credit: [Prototypical Networks for Few shot Learning in PyTorch ](https://github.com/orobix/Prototypical-Networks-for-Few-shot-Learning-PyTorch) ) Further readings: - [Zero-Shot Learning -- A Comprehensive Evaluation of the Good, the Bad and the Ugly](https://paperswithcode.com/paper/zero-shot-learning-a-comprehensive-evaluation) - [Zero-Shot Learning in Modern NLP](https://joeddav.github.io/blog/2020/05/29/ZSL.html) - [Zero-Shot Learning for Text Classification](https://amitness.com/2020/05/zero-shot-text-classification/)
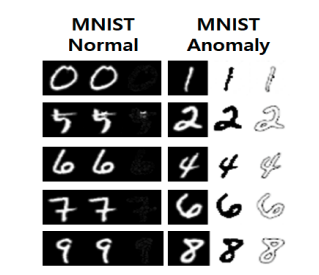
**Anomaly Detection** is a binary classification identifying unusual or unexpected patterns in a dataset, which deviate significantly from the majority of the data. The goal of anomaly detection is to identify such anomalies, which could represent errors, fraud, or other types of unusual events, and flag them for further investigation. [Image source]: [GAN-based Anomaly Detection in Imbalance Problems](https://paperswithcode.com/paper/gan-based-anomaly-detection-in-imbalance)
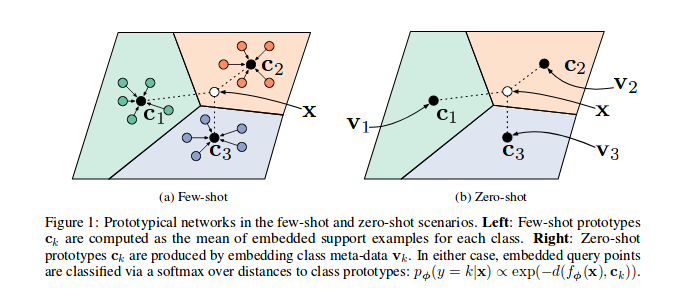
**Few-Shot Learning** is an example of meta-learning, where a learner is trained on several related tasks, during the meta-training phase, so that it can generalize well to unseen (but related) tasks with just few examples, during the meta-testing phase. An effective approach to the Few-Shot Learning problem is to learn a common representation for various tasks and train task specific classifiers on top of this representation. Source: [Penalty Method for Inversion-Free Deep Bilevel Optimization ](https://arxiv.org/abs/1911.03432)

**Depth Estimation** is the task of measuring the distance of each pixel relative to the camera. Depth is extracted from either monocular (single) or stereo (multiple views of a scene) images. Traditional methods use multi-view geometry to find the relationship between the images. Newer methods can directly estimate depth by minimizing the regression loss, or by learning to generate a novel view from a sequence. The most popular benchmarks are KITTI and NYUv2. Models are typically evaluated according to a RMS metric. Source: [DIODE: A Dense Indoor and Outdoor DEpth Dataset ](https://arxiv.org/abs/1908.00463)

**Facial Recognition** is the task of making a positive identification of a face in a photo or video image against a pre-existing database of faces. It begins with detection - distinguishing human faces from other objects in the image - and then works on identification of those detected faces. The state of the art tables for this task are contained mainly in the consistent parts of the task : the face verification and face identification tasks. ( Image credit: [Face Verification](https://shuftipro.com/face-verification) )

**Action Recognition** is a computer vision task that involves recognizing human actions in videos or images. The goal is to classify and categorize the actions being performed in the video or image into a predefined set of action classes. In the video domain, it is an open question whether training an action classification network on a sufficiently large dataset, will give a similar boost in performance when applied to a different temporal task or dataset. The challenges of building video datasets has meant that most popular benchmarks for action recognition are small, having on the order of 10k videos. Please note some benchmarks may be located in the [Action Classification](https://paperswithcode.com/task/action-classification) or [Video Classification](https://paperswithcode.com/task/video-classification) tasks, e.g. Kinetics-400.

**Denoising** is a task in image processing and computer vision that aims to remove or reduce noise from an image. Noise can be introduced into an image due to various reasons, such as camera sensor limitations, lighting conditions, and compression artifacts. The goal of denoising is to recover the original image, which is considered to be noise-free, from a noisy observation. ( Image credit: [Beyond a Gaussian Denoiser](https://arxiv.org/pdf/1608.03981v1.pdf) )

**Super-Resolution** is a task in computer vision that involves increasing the resolution of an image or video by generating missing high-frequency details from low-resolution input. The goal is to produce an output image with a higher resolution than the input image, while preserving the original content and structure. ( Credit: [MemNet](https://github.com/tyshiwo/MemNet) )

Autonomous driving is the task of driving a vehicle without human conduction. Many of the state-of-the-art results can be found at more general task pages such as [3D Object Detection](https://paperswithcode.com/task/3d-object-detection) and [Semantic Segmentation](https://paperswithcode.com/task/semantic-segmentation). (Image credit: [Exploring the Limitations of Behavior Cloning for Autonomous Driving](https://arxiv.org/pdf/1904.08980v1.pdf))

Data augmentation involves techniques used for increasing the amount of data, based on different modifications, to expand the amount of examples in the original dataset. Data augmentation not only helps to grow the dataset but it also increases the diversity of the dataset. When training machine learning models, data augmentation acts as a regularizer and helps to avoid overfitting. Data augmentation techniques have been found useful in domains like NLP and computer vision. In computer vision, transformations like cropping, flipping, and rotation are used. In NLP, data augmentation techniques can include swapping, deletion, random insertion, among others. Further readings: - [A Survey of Data Augmentation Approaches for NLP](https://paperswithcode.com/paper/a-survey-of-data-augmentation-approaches-for) - [A survey on Image Data Augmentation for Deep Learning](https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0197-0) ( Image credit: [Albumentations](https://github.com/albumentations-team/albumentations) )

**Domain Adaptation** is the task of adapting models across domains. This is motivated by the challenge where the test and training datasets fall from different data distributions due to some factor. Domain adaptation aims to build machine learning models that can be generalized into a target domain and dealing with the discrepancy across domain distributions. Further readings: - [A Brief Review of Domain Adaptation](https://paperswithcode.com/paper/a-brief-review-of-domain-adaptation) ( Image credit: [Unsupervised Image-to-Image Translation Networks](https://arxiv.org/pdf/1703.00848v6.pdf) )

**Image Generation** (synthesis) is the task of generating new images from an existing dataset. - **Unconditional generation** refers to generating samples unconditionally from the dataset, i.e. $p(y)$ - **[Conditional image generation](/task/conditional-image-generation)** (subtask) refers to generating samples conditionally from the dataset, based on a label, i.e. $p(y|x)$. In this section, you can find state-of-the-art leaderboards for **unconditional generation**. For conditional generation, and other types of image generations, refer to the subtasks. ( Image credit: [StyleGAN](https://github.com/NVlabs/stylegan) )

**Object Detection** is a computer vision task in which the goal is to detect and locate objects of interest in an image or video. The task involves identifying the position and boundaries of objects in an image, and classifying the objects into different categories. It forms a crucial part of vision recognition, alongside [image classification](/task/image-classification) and [retrieval](/task/image-retrieval). The state-of-the-art methods can be categorized into two main types: one-stage methods and two stage-methods: - One-stage methods prioritize inference speed, and example models include YOLO, SSD and RetinaNet. - Two-stage methods prioritize detection accuracy, and example models include Faster R-CNN, Mask R-CNN and Cascade R-CNN. The most popular benchmark is the MSCOCO dataset. Models are typically evaluated according to a Mean Average Precision metric. ( Image credit: [Detectron](https://github.com/facebookresearch/detectron) )

**Image Classification** is a fundamental task in vision recognition that aims to understand and categorize an image as a whole under a specific label. Unlike [object detection](/task/object-detection), which involves classification and location of multiple objects within an image, image classification typically pertains to single-object images. When the classification becomes highly detailed or reaches instance-level, it is often referred to as [image retrieval](/task/image-retrieval), which also involves finding similar images in a large database. Source: [Metamorphic Testing for Object Detection Systems ](https://arxiv.org/abs/1912.12162)

**Semantic Segmentation** is a computer vision task in which the goal is to categorize each pixel in an image into a class or object. The goal is to produce a dense pixel-wise segmentation map of an image, where each pixel is assigned to a specific class or object. Some example benchmarks for this task are Cityscapes, PASCAL VOC and ADE20K. Models are usually evaluated with the Mean Intersection-Over-Union (Mean IoU) and Pixel Accuracy metrics. ( Image credit: [CSAILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) )

Or, How to Act Like You Know About the Biggest AI Development since CNNs
From predicting single sentence to fine-tuning using custom dataset to finding the best hyperparameter configuration.

How Temporal Convolutional Networks are moving in favor of Sequence Modeling — Stock Trend Prediction.

Semantic segmentation is the task of predicting the class of each pixel in an image. This problem is more difficult than object detection…

Determining the optimal architectural parameters reduces network size by 84% while improving performance on natural-language-understanding tasks.

What are these new YOLO releases in 2020? How do they differ? Which one should I use?
Scientists have developed an Artificial Intelligence (AI) system that recognises hand gestures by combining skin-like electronics with computer vision.

Bringing structure to an unstructured task
Federated learning means enabling on-device training, model personalization, and more. Read more about it in this article.

What is Transfer Learning? Where can I use it? Why should I use it? How can I use it? Read On to find out!

Using Auto-Encoders to gain insight into data
443K subscribers in the learnmachinelearning community. A subreddit dedicated to learning machine learning
This is an overview of a great computer vision resource from Microsoft, which demonstrates best practices and implementation guidelines for a variety of tasks and scenarios.

AI researchers are using heartbeat detection to identify deepfake videos and even to figure out what kind of generative model created a deepfake.

In Part 1 of this series, we introduced the concept of embedding vectors. In Part 2, we discussed how embedding vectors can be used in…
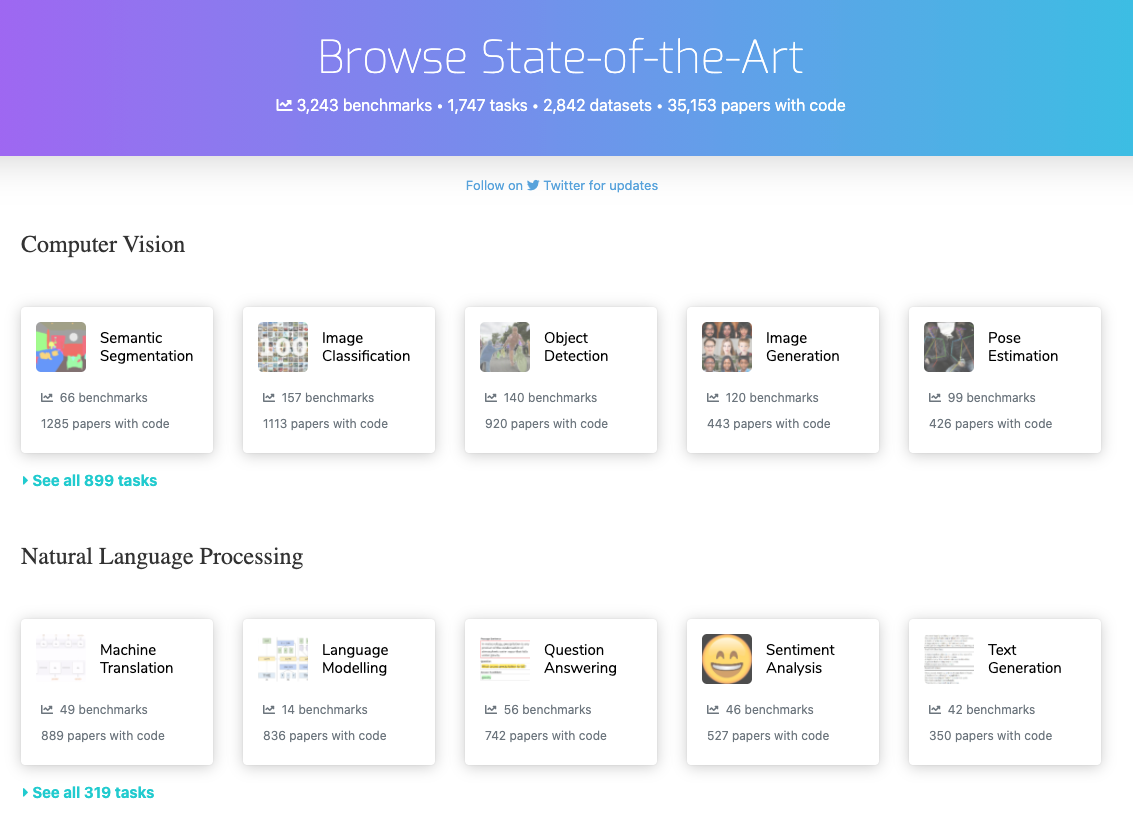
Through a joint collaboration, Papers with Code now provides category classification and code references for articles in the arXiv…

A review of 20+ deep learning NLP models and how to use them well
Machine learning is often fueled by image data. In this guide, learn the basics about image annotation, common techniques, and key workforce considerations.

PyTorch has sort of became one of the de facto standards for creating Neural Networks now, and I love its interface.
Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.

In this post, we’ll create an end to end pipeline for image multiclass classification using Pytorch.This will include training the model, putting the model’s results in a form that can be shown to business partners, and functions to help deploy the model easily. As an added feature we will look at Test Time Augmentation using Pytorch also.

One infographic that explains how Reinforcement Learning, Deep Learning and Monte Carlo Search Trees are used in AlphaGo Zero.
Reading suggestions to keep you up-to-date with the latest and classic breakthroughs in AI and Data Science

AI researchers from the Ludwig Maximilian University (LMU) of Munich have developed a bite-sized text generator capable of besting OpenAI’s state of the art GPT-3 using only a tiny fraction of its parameters. GPT-3 is a monster of an AI sys

What does Microsoft getting an "exclusive license" to GPT-3 mean for the future of AI democratization?


Read this accessible and conversational article about understanding transformers, the data science way — by asking a lot of questions that is.
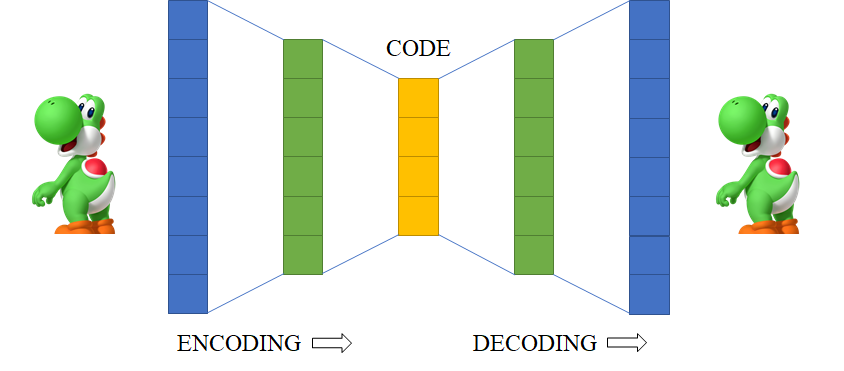
Which kinds of autoencoders exist and what are their applications?
Use a pre-trained neural network for feature extraction and cluster images using K-means.

Visual vocabulary advances novel object captioning by breaking free of paired sentence-image training data in vision and language pretraining. Discover how this method helps set new state of the art on the nocaps benchmark and bests CIDEr scores of humans.
Get up to date on one of the most promising Deep Learning technologies there is right now

Tesla's Autopilot system relies on vision rather than LIDAR, which means it can be tricked by messages on billboards and projections created by hackers.

Nvidia tops MLPerf records again, consortium adds benchmarks to measure mobile


With PyTorch and TensorFlow incorporated, the authors hope to gain a wider audience.
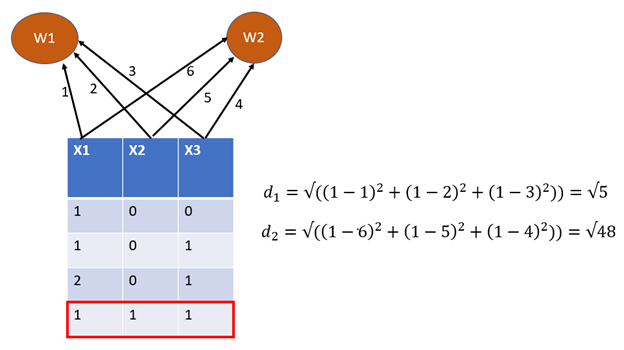
Self-Organizing Maps for Dimension Reduction, Data Visualization, and Clustering

Recognition of Oil Storage Tanks in satellite images using the Yolov3 object detection model from scratch using Tensorflow 2.x and…

A brief introduction to CenterNet (Objects as Points), TTFNet and their implementation in TensorFlow 2.2+.
Standard, Recurrent, Convolutional, & Autoencoder Networks
To researchers’ surprise, deep learning vision algorithms often fail at classifying images because they mostly take cues from textures, not shapes.

Less than 50 days after the release YOLOv4, YOLOv5 improves accessibility for realtime object detection. June 29, YOLOv5 has released the first official version of the repository. We wrote a new deep dive on YOLOv5. June 12, 8:08 AM CDT Update: In response to to community feedback, we have
Deep Dive into DNNs, CNNs, and RNNs Dropout Methods for Regularization, Monte Carlo Uncertainty, and Model Compression

Smooth python codes to augment your image datasets by yourself.


How I Generated New Images from Random Data using DCGAN
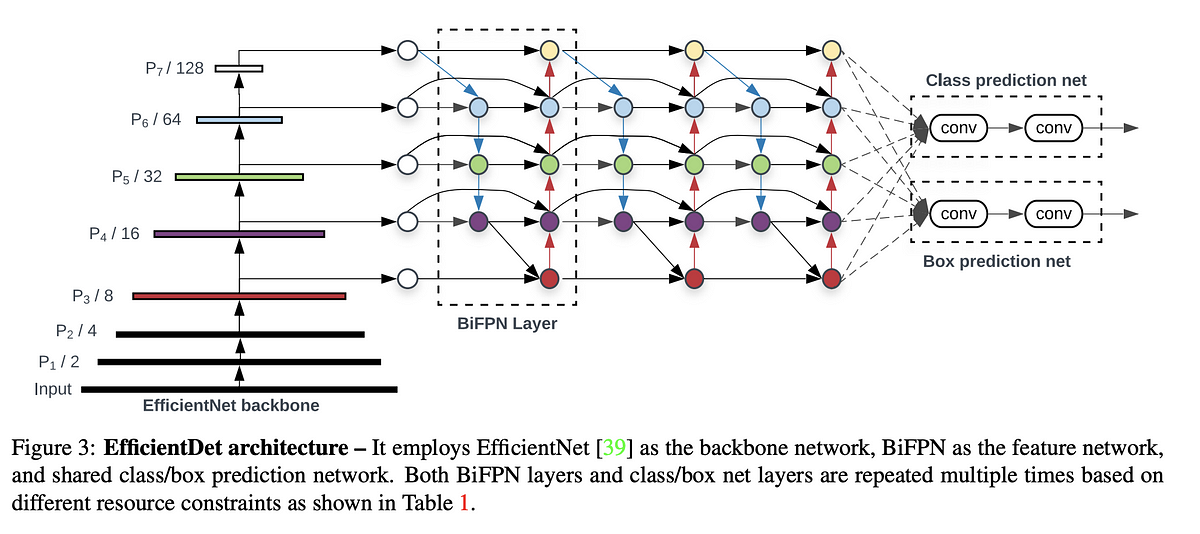
Let’s dive deep into the architectural details of all the different EfficientNet Models and find out how they differ from each other.

Webcam background change is not limited to Zoom now, I just did it in the browser with tensorflow.js body-pix model


Computer vision is evolving on a daily basis. Popular computer vision techniques such as image classification and object detection have been used extensively to solve a lot of computer vision…


We reached out to further members of the AI community for their recommendations of papers which everyone should be reading! All of the cited papers are free to access and cover a range of topics from some incredible minds.
This post collates research on the advancements of Natural Language Processing (NLP) over the years.

We’re releasing an analysis showing that since 2012 the amount of compute needed to train a neural net to the same performance on ImageNet classification has been decreasing by a factor of 2 every 16 months. Compared to 2012, it now takes 44 times less compute to train a neural network to the level of AlexNet (by contrast, Moore’s Law would yield an 11x cost improvement over this period). Our results suggest that for AI tasks with high levels of recent investment, algorithmic progress has yielded more gains than classical hardware efficiency.
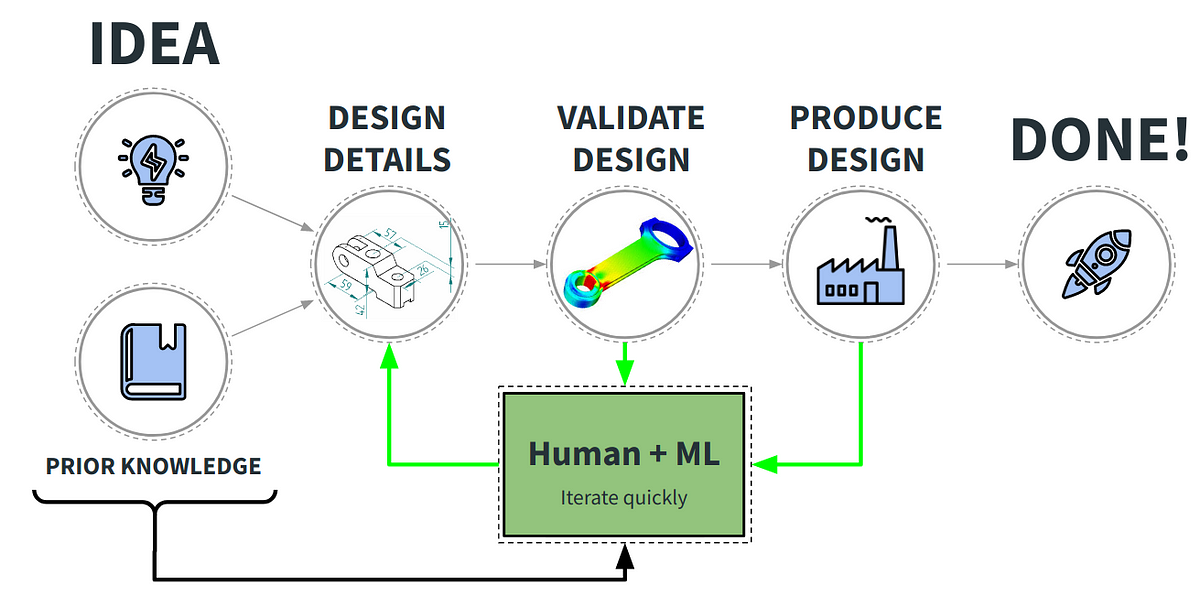
Making the design process faster and more efficient by generating 3D objects from natural language descriptions.
A library for efficient similarity search and clustering of dense vectors. - facebookresearch/faiss

Explore and manipulate the COCO image dataset for Semantic Image Segmentation with PyCoco, Tensorflow Keras Python libraries

Create a data generator and train your model on the COCO image dataset for Semantic Image Segmentation with PyCoco, Tensorflow Keras py

Usage of the new model, with examples and Colab Notebook.

An Overview Of popular python libraries for Natural Language Processing

In this article we’ll serve the Tensorflow Object Detection API with Flask, Dockerize the Application and deploy it on Kubernetes.
Paper: https://arxiv.org/abs/1910.07454 Blog Post: http://www.offconvex.org/2020/04/24/ExpLR1/ "We report experiments that state-of-the-art networks…
The new tools shows the potential of data visualizations for understanding features in a neural network.

Introduction on Stacked Auto-encoder and Technical Walk-through on Model Creation using Pytorch
We review the cost of training large-scale language models, and the drivers of these costs. The intended audience includes engineers and scientists budgeting their model-training experiments, as...
Bringing Neural Architecture into Recommendations
/cdn.vox-cdn.com/uploads/chorus_asset/file/19599985/1185354768.jpg.jpg)
AI looks well-suited for short-term weather forecasts

New approach to meta-reinforcement learning minimizes the need for costly interactions with the environment.

Extracting topics is a good unsupervised data-mining technique to discover the underlying relationships between texts. There are many…
We’ll show you how to quickly build a Streamlit app to synthesize celebrity faces using GANs, Tensorflow, and st.cache.

It’s theoretically possible to become invisible to cameras. But can it catch on?


Google published an article “Understanding searches better than ever before” and positioned BERT as one of the most important updates to…

Statistics, Algorithms, Deep Learning, NLP, & Data Organization
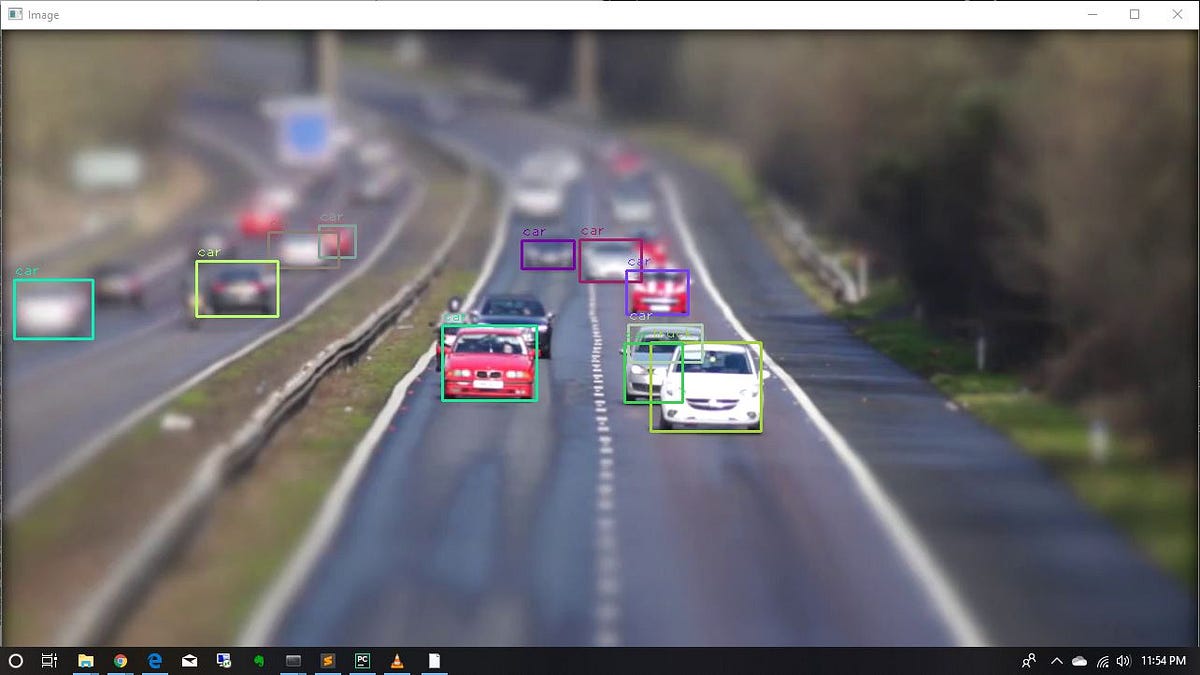
An Introduction to Object Detection with YoloV3 for beginners

Learn about different types of annotations, annotation formats and annotation tools
Object Detection using Yolo V3 and OpenCV .

TLDR This is a Free online text summarizing tool that automatically condenses long articles, documents, essays, or papers into key summary paragraphs using state-of-the-art AI.

An Explanation and Implementation of Matrix Factorization
TensorFlow code and pre-trained models for BERT.
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessible video intro to BERT The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving. Moreover, the NLP community has been putting forward incredibly powerful components that you can freely download and use in your own models and pipelines (It’s been referred to as NLP’s ImageNet moment, referencing how years ago similar developments accelerated the development of machine learning in Computer Vision tasks).
Visualizing machine learning one concept at a time.
🔥🔥Defending Against Deepfakes Using Adversarial Attacks on Conditional Image Translation Networks - natanielruiz/disrupting-deepfakes

Explore the Real-World Applications of Your Model
Mask R-CNN has been the new state of the art in terms of instance segmentation. Here I want to share some simple understanding of it to give you a first look and then we can move ahead and build our model.

Convolutional Neural Networks-Part 2: Detailed convolutional architectures enabling object-detection and face-recognition algorithms.

The toughest part of machine learning with Spark isn't what you think it is.

MLCommons ML benchmarks help balance the benefits and risks of AI through quantitative tools that guide responsible AI development.

A deep dive into the tricks that make Neural Style Transfer work

A spatial transformer network is a specialized type of convoluted neural network, or CNN, used to improve the clarity of an object in an image.

How to use snorkel’s multi-class implementation to create multi-labels

In a preprint paper, researchers at Johns Hopkins detail TrojAI, a framework for hardening AI models against adversarial attacks.
Since deep neural networks were developed, they have made huge contributions to everyday lives. Machine learning provides more rational advice than humans are capable of in almost every aspect of...

In this tutorial, you will learn how to get started with your NVIDIA Jetson Nano, including installing Keras + TensorFlow, accessing the camera, and performing image classification and object detection.
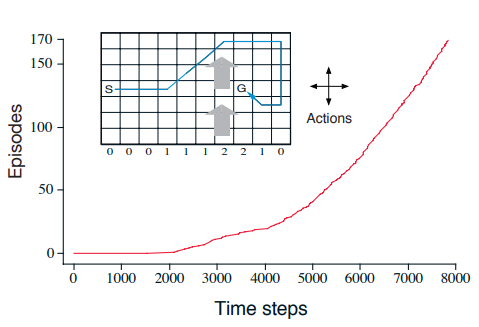
Optimizing value functions by bootstrapping through experience.

Introducing a fast, easy to use, deep learning based dimensionality reduction tool

Pre-training SmallBERTa - A tiny model to train on a tiny dataset An end to end colab notebook that allows you to train your own LM (using HuggingFace…

A step-by-step tutorial from data import to accuracy evaluation

TLDR: This is basically about converting the original attention paper by Yoshua Bengio’s group to flowcharts. Check the last diagram…

All the essential Deep Learning Algorithms you need to know including models used in Computer Vision and Natural Language Processing
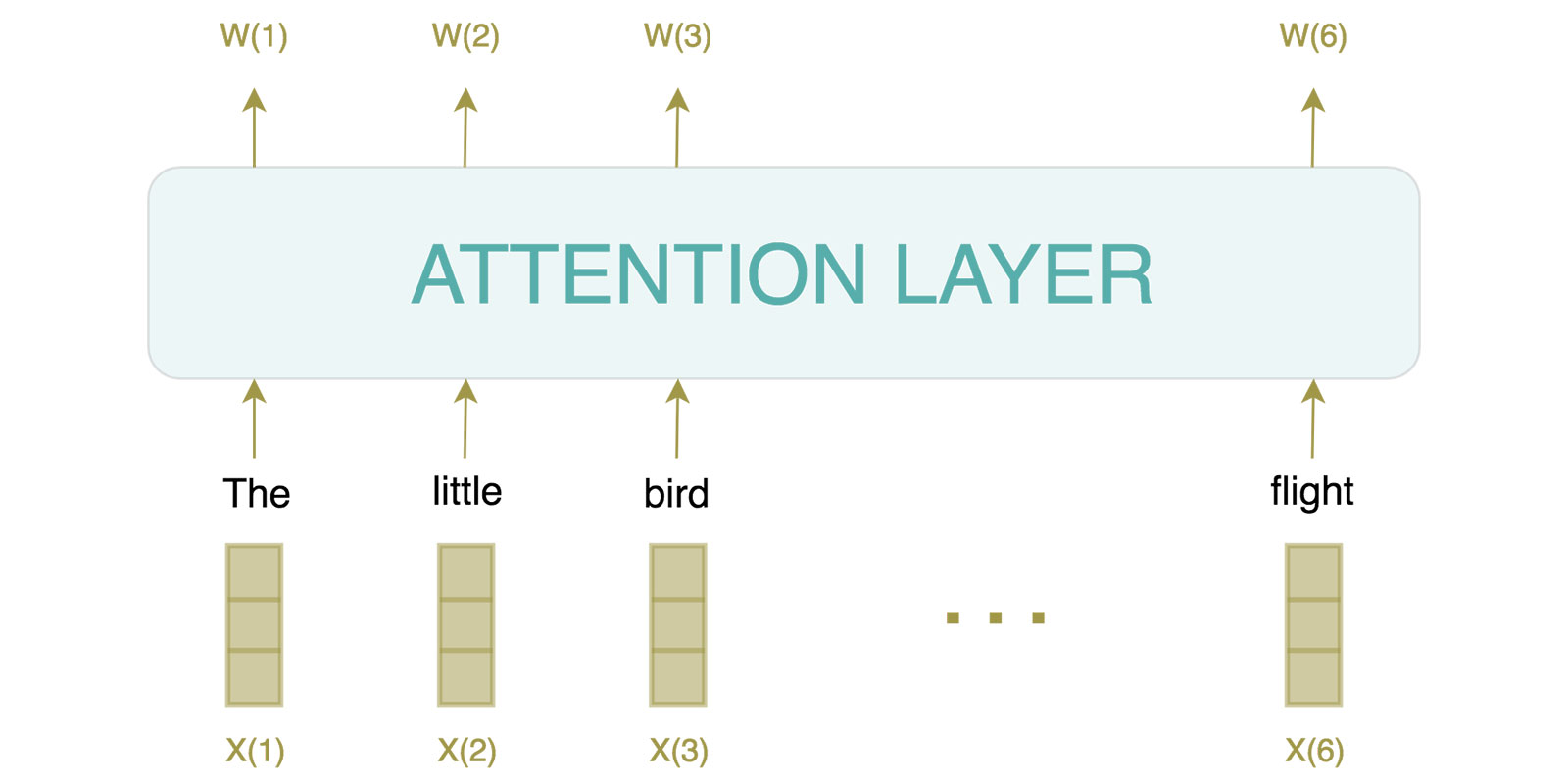
We saw how attention works and how it improved neural machine translation systems (see the previous blogpost), we are going to unveil the secrets behind the power of the most famous NLP models nowadays (a.k.a BERT and friends), the transformer. In this second part, we are going to dive into the details of this architecture with the aim of […]

This little-known method could very well be the answer to the greatest obstacle facing artificial intelligence's adoption in health care. (from March)

What can we do when we don't have a substantial amount of varied training data? This is a quick intro to using data augmentation in TensorFlow to perform in-memory image transformations during model training to help overcome this data impediment.

Posted by Shreeyak Sajjan, Research Engineer, Synthesis AI and Andy Zeng, Research Scientist, Robotics at Google Optical 3D range sensors, like R...

By popular demand, I’ve updated this article with the latest tutorials from the past 12 months. Check it out here
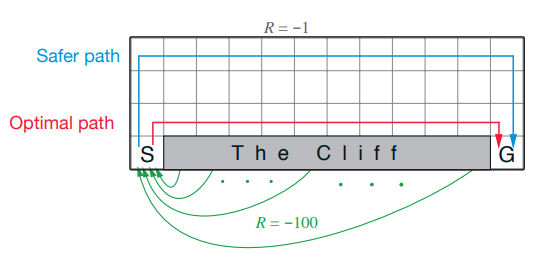
An early breakthrough in reinforcement learning — Off-policy Temporal-Difference control methods

What is sentiment analysis, how to perform it, and how it can help your business.
VAE and where to find them

Transformers are a type of neural network architecture that have been gaining popularity. Transformers were recently used by OpenAI in…
443K subscribers in the learnmachinelearning community. A subreddit dedicated to learning machine learning

What research caught the public imagination in 2019? Check out our annual list of papers with the most attention.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
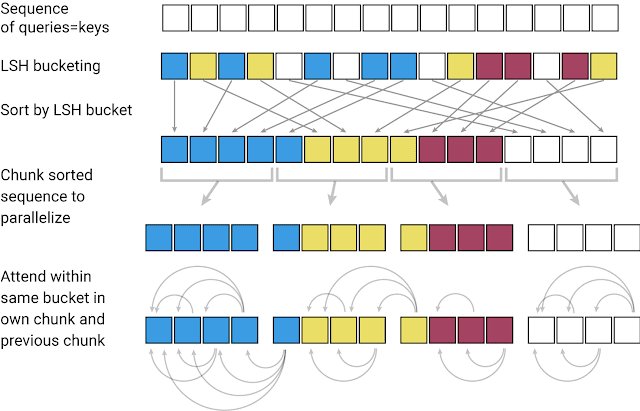
Posted by Nikita Kitaev, Student Researcher, UC Berkeley and Łukasz Kaiser, Research Scientist, Google Research Understanding sequential data — s...
In this paper, a feature boosting network is proposed for estimating 3D hand pose and 3D body pose from a single RGB image. In this method, the features learned by the convolutional layers are boosted with a new long short-term dependence-aware (LSTD) module, which enables the intermediate convolutional feature maps to perceive the graphical long short-term dependency among different hand (or body) parts using the designed Graphical ConvLSTM. Learning a set of features that are reliable and discriminatively representative of the pose of a hand (or body) part is difficult due to the ambiguities, texture and illumination variation, and self-occlusion in the real application of 3D pose estimation. To improve the reliability of the features for representing each body part and enhance the LSTD module, we further introduce a context consistency gate (CCG) in this paper, with which the convolutional feature maps are modulated according to their consistency with the context representations. We evaluate the proposed method on challenging benchmark datasets for 3D hand pose estimation and 3D full body pose estimation. Experimental results show the effectiveness of our method that achieves state-of-the-art performance on both of the tasks.
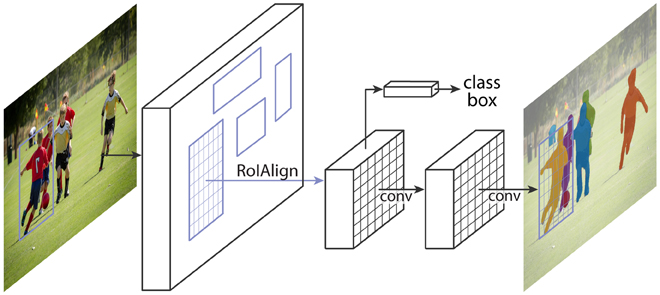
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition. Code has been made available at: https://github.com/facebookresearch/Detectron.
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. Code is at: https://github.com/facebookresearch/Detectron.

Machine learning provides an entirely new way to tackle one of the classic problems of applied mathematics.

Extract table from image with Nanonets table detection OCR. Learn OCR table Deep Learning methods to detect tables in images or PDF documents.

From deepfakes and virtual celebrities to "fake news," we'll cover popular cases of media synthesis and the research publications detailing how it's done.

This figure was adapted from a similar image published in DistilBERT. Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics […]

In this article we explain what GauGANs are, and how their architecture and objective functions work. This is part of a series on Nvidia GauGANs.


I bet most of us have seen a lot of AI-generated people faces in recent times, be it in papers or blogs. We have reached a stage where it is becoming increasingly difficult to distinguish between actual human faces and faces that are generated by Artificial Intelligence. In this post, I will help the reader to understand how they can create and build such applications on their own. I will try to keep this post as intuitive as possible for starters while not dumbing it down too much. This post is about understanding how GANs work.

Marketing scientist Kevin Gray asks Dr. Anna Farzindar of the University of Southern California about Automatic Text Summarization and the various ways it is used.

In this article, I will present five techniques to prevent overfitting while training neural networks.

With new neural network architectures popping up every now and then, it’s hard to keep track of them all. Knowing all the abbreviations being thrown around (DCIGN, BiLSTM, DCGAN, anyone?) can be a bit overwhelming at first. So I decided to compose a cheat sheet containing many of those architectures. Most of these are neural networks, some are completely […]
Autoencoders can be a very powerful tool for leveraging unlabeled data to solve a variety of problems, such as learning a "feature extractor" that helps build powerful classifiers, finding anomalies, or doing a Missing Value Imputation.

Knowledge distillation is a model compression technique whereby a small network (student) is taught by a larger trained neural network (teacher). The smaller network is trained to behave like the large neural network. This enables the deployment of such models… Continue reading Research Guide: Model Distillation Techniques for Deep Learning
Detailed derivations and open-source code to analyze the receptive fields of convnets.

With recent developments in deep learning, neural networks are getting larger and larger. For example, in the ImageNet recognition challenge, the winning model, from 2012 to 2015, increased in size by 16 times. And in just one year, for Baidu’s… Continue reading The 5 Algorithms for Efficient Deep Learning Inference on Small Devices
Easy Explanation!!! I tried
Policy Gradient is all you need! A step-by-step tutorial for well-known PG methods. - MrSyee/pg-is-all-you-need
A new method that provides accurate, real-time, computer-aided diagnosis of colorectal cancer identified tumors with 100% accuracy in a new pilot study.

Researchers have shrunk state-of-the-art computer vision models to run on low-power devices. Growing pains: Visual recognition is deep learning’s strongest skill. Computer vision algorithms are analyzing medical images, enabling self-driving cars, and powering face recognition. But training models to recognize actions in videos has grown increasingly expensive. This has fueled concerns about the technology’s carbon…
This guide explores research centered on a variety of advanced loss functions for machine learning models.

Week Two - 100 Days of Code Challenge

In this tutorial you will learn how to use Keras, Mask R-CNN, and Deep Learning for instance segmentation (both with and without a GPU).
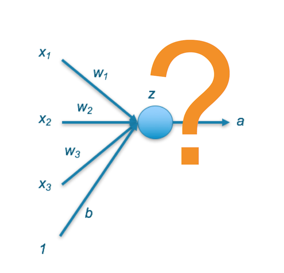
The purpose of this post is to provide guidance on which combination of final-layer activation function and loss function should be used in…

In this article, you will explore how you can leverage Kubernetes, Tensorflow and Kubeflow to scale your models without having to worry about scaling the infrastructure.


What we'd like to find out about GANs that we don't know yet.
You only look once (YOLO) is a state-of-the-art, real-time object detection system.
Medallia's text analytics software tool provides actionable insights via customer and employee experience sentiment data analysis from reviews & comments.

Nvidia's GauGAN tool has been used to create more than 500,000 images, the company announced at the SIGGRAPH 2019 conference in Los Angeles.
27K votes, 533 comments. 21M subscribers in the dataisbeautiful community. DataIsBeautiful is for visualizations that effectively convey information…
A technical report on convolution arithmetic in the context of deep learning - vdumoulin/conv_arithmetic
Learn how SymphonyAI’s financial crime prevention solutions quickly deploy to uncover your risks, improve investigations, and transform your operations.
Scientists are developing AI systems called deep neural nets that can read medical images and detect disease — with astonishing efficiency
Algorithms off the convex path.

Over the last few years we have detailed the explosion in new machine learning systems with the influx of novel architectures from deep learning chip
Here we are again! We already have four tutorials on financial forecasting with artificial neural networks where we compared different…
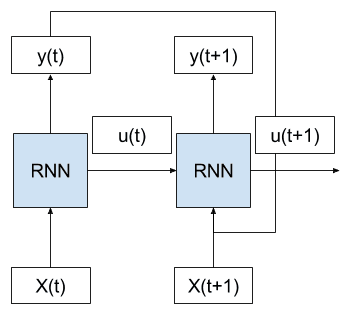
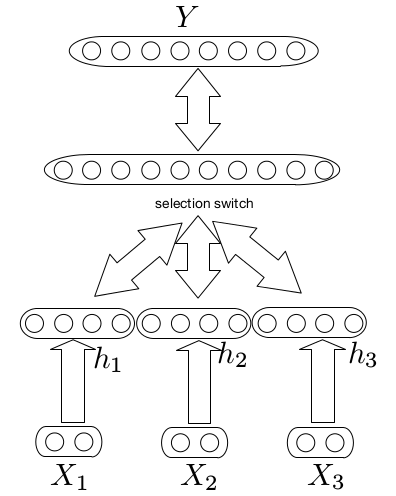
Recurrent neural networks are a type of neural network where the outputs from previous time steps are fed as input to the current time step. This creates a network graph or circuit diagram with cycles, which can make it difficult to understand how information moves through the network. In this post, you will discover the concept of unrolling or unfolding…
Most of us last saw calculus in school, but derivatives are a critical part of machine learning, particularly deep neural networks, which are trained by optimizing a loss function. This article is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed.
Quantized word vectors that take 8x-16x less space than regular word vectors - agnusmaximus/Word2Bits
Tensorflow (Python API) implementation of Deep Photo Style Transfer - LouieYang/deep-photo-styletransfer-tf
We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while...
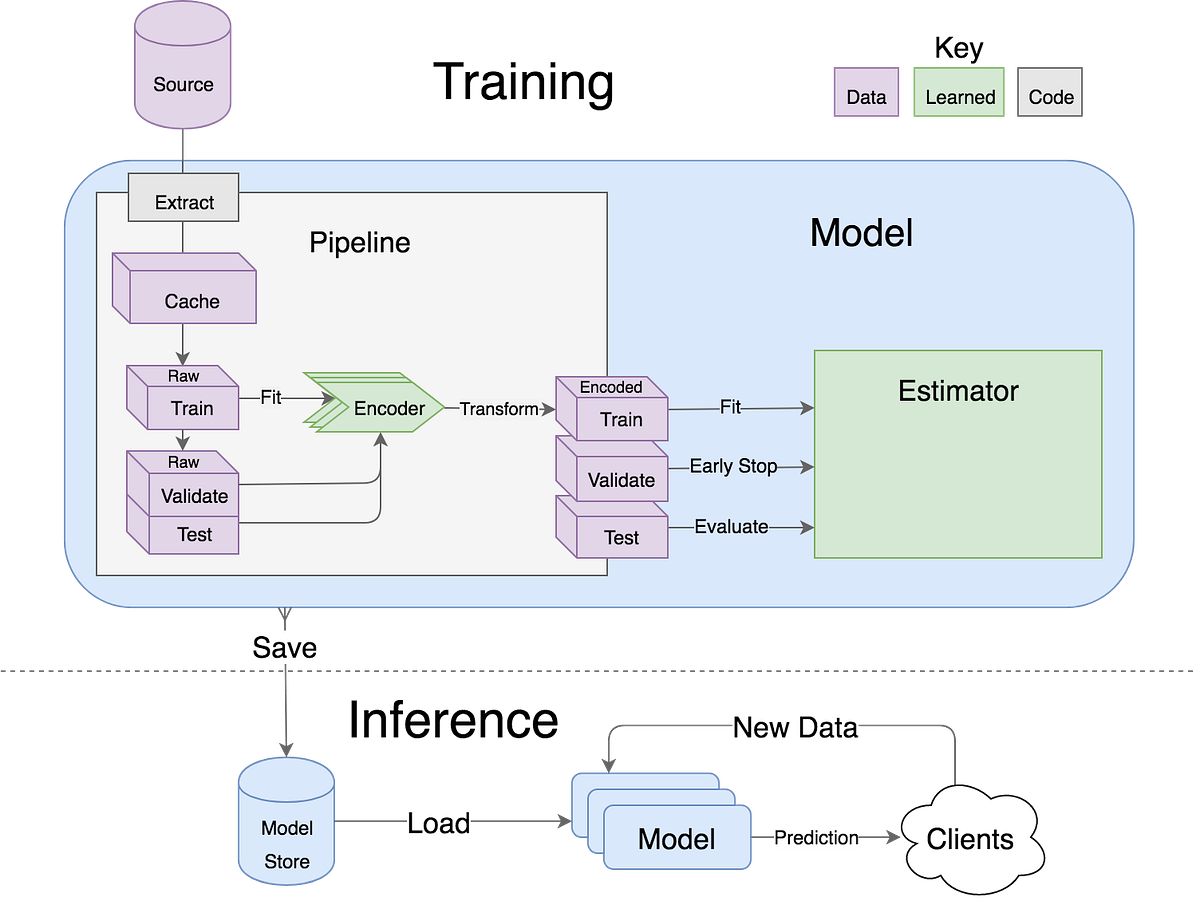
An open source framework for configuring, building, deploying and maintaining deep learning models in Python.

Generative adversarial networks (GANs) are a class of neural networks that are used in unsupervised machine learning. They help to solve such tasks as image generation from descriptions, getting high resolution images from low resolution ones, predicting which drug could treat a certain disease, retrieving images that contain a given pattern, etc. Our team asked… Read More »Generative Adversarial Networks (GANs): Engine and Applications

Through a human’s eyes, the world is much more than just the images reflected in our corneas. For example, when we look at a building and admire the intricacies of its design, we can appreciate...
Recurrent Neural Network - A curated list of resources dedicated to RNN - kjw0612/awesome-rnn

GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Scenarios, tutorials and demos for Autonomous Driving - microsoft/AutonomousDrivingCookbook
Google did its best to impress this week at its annual IO conference. While Google rolled out a bunch of benchmarks that were run on its current Cloud TPU

LightTag, a newly launched startup from a former NLP researcher at Citi, has built a "text annotation platform" designed to assist data scientists who

Google's new TPUs are here -- and they're quite a bit faster than last year's model.

Running large deep learning processes on Amazon Web Services EC2 is a cheap and effective way to learn and develop models. For just a few dollars you can get access to tens of gigabytes of RAM, tens of CPU cores, and multiple GPUs. I highly recommend it. If you are new to EC2 or the Linux command line, there are…

Baidu this Thursday announced the release of ApolloScape, billed as the world’s largest open-source dataset for autonomous driving…

China's tech titan Baidu just upgraded Deep Voice. The voice-cloning AI now works faster than ever and can swap a speaker's gender or change their accent.

Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.

Dive into our detailed explanation of what is Region of Interest (RoI) Pooling in deep learning. Enhance your skills. Discover more now!

There were many advances in Deep Learning and AI in 2017, but few generated as much publicity and interest as DeepMind’s AlphaGo Zero. This…
Deep Learning papers reading roadmap for anyone who are eager to learn this amazing tech! - floodsung/Deep-Learning-Papers-Reading-Roadmap

How and why do different Deep Learning models work? We provide an intuitive explanation for 3 very popular DL models: Resnet, Inception, and Xception.

The Long Short-Term Memory recurrent neural network was developed for sequence prediction. In addition to sequence prediction problems. LSTMs can also be used as a generative model In this post, you will discover how LSTMs can be used as generative models. After completing this post, you will know: About generative models, with a focus on generative models for text called…

Exploding gradients are a problem where large error gradients accumulate and result in very large updates to neural network model weights during training. This has the effect of your model being unstable and unable to learn from your training data. In this post, you will discover the problem of exploding gradients with deep artificial neural networks. After completing this post,…
Emil Mikhailov is the founder of XIX.ai [http://XIX.ai] (YC W17). Roman Trusov is a researcher at XIX.ai. Recent studies by Google Brain have shown that any machine learning classifier can be tricked to give incorrect predictions, and with a little bit of skill, you can get them to give pretty much any result you want. This fact steadily becomes worrisome as more and more systems are powered by artificial intelligence — and many of them are crucial for our safe and comfortable life. Banks, sur
Collection of generative models, e.g. GAN, VAE in Pytorch and Tensorflow. - wiseodd/generative-models
The most cited deep learning papers.

Making Waves in Deep Learning How deep learning applications will map onto a chip.