
In this article, we'll walk through the process of aggregating claims data to create meaningful provider features, visualize patterns using Yellowbrick's Parallel Coordinates, and explore other visualization tools available for feature analysis.
In this article, we'll walk through the process of aggregating claims data to create meaningful provider features, visualize patterns using Yellowbrick's Parallel Coordinates, and explore other visualization tools available for feature analysis.

Dataset distillation is an innovative approach that addresses the challenges posed by the ever-growing size of datasets in machine learning. This technique focuses on creating a compact, synthetic dataset that encapsulates the essential information of a larger dataset, enabling efficient and effective model training. Despite its promise, the intricacies of how distilled data retains its utility and information content have yet to be fully understood. Let’s delve into the fundamental aspects of dataset distillation, exploring its mechanisms, advantages, and limitations. Dataset distillation aims to overcome the limitations of large datasets by generating a smaller, information-dense dataset. Traditional data compression methods

Analytics, management, and business intelligence (BI) procedures, such as data cleansing, transformation, and decision-making, rely on data profiling. Content and quality reviews are becoming more important as data sets grow in size and variety of sources. In addition, organizations that rely on data must prioritize data quality review. Analysts and developers can enhance business operations by analyzing the dataset and drawing significant insights from it. Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling? Examining

Types of Functions > Basis functions (called derived features in machine learning) are building blocks for creating more complex functions. In other
Understanding the importance of permutations in the field of explainable AI
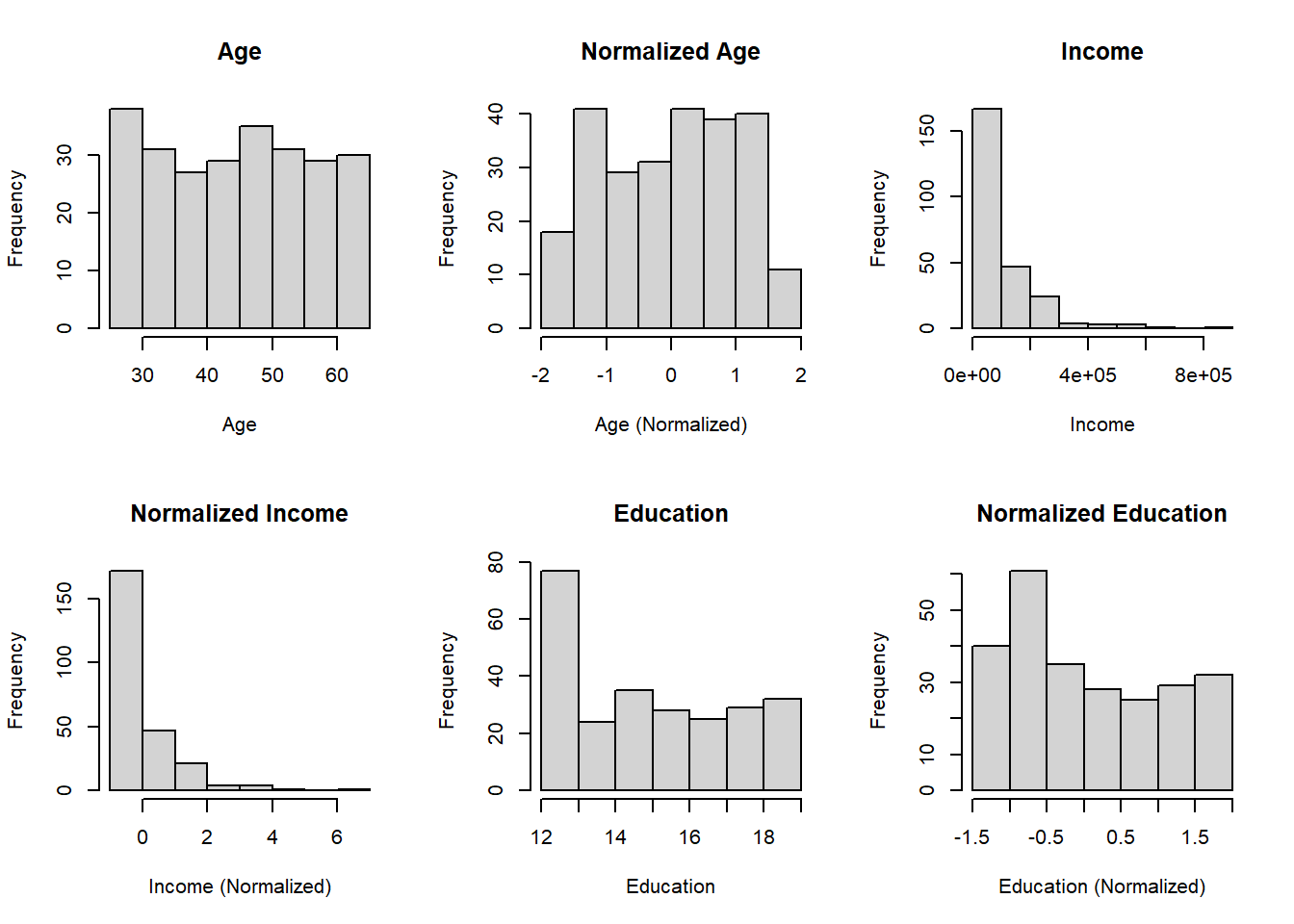
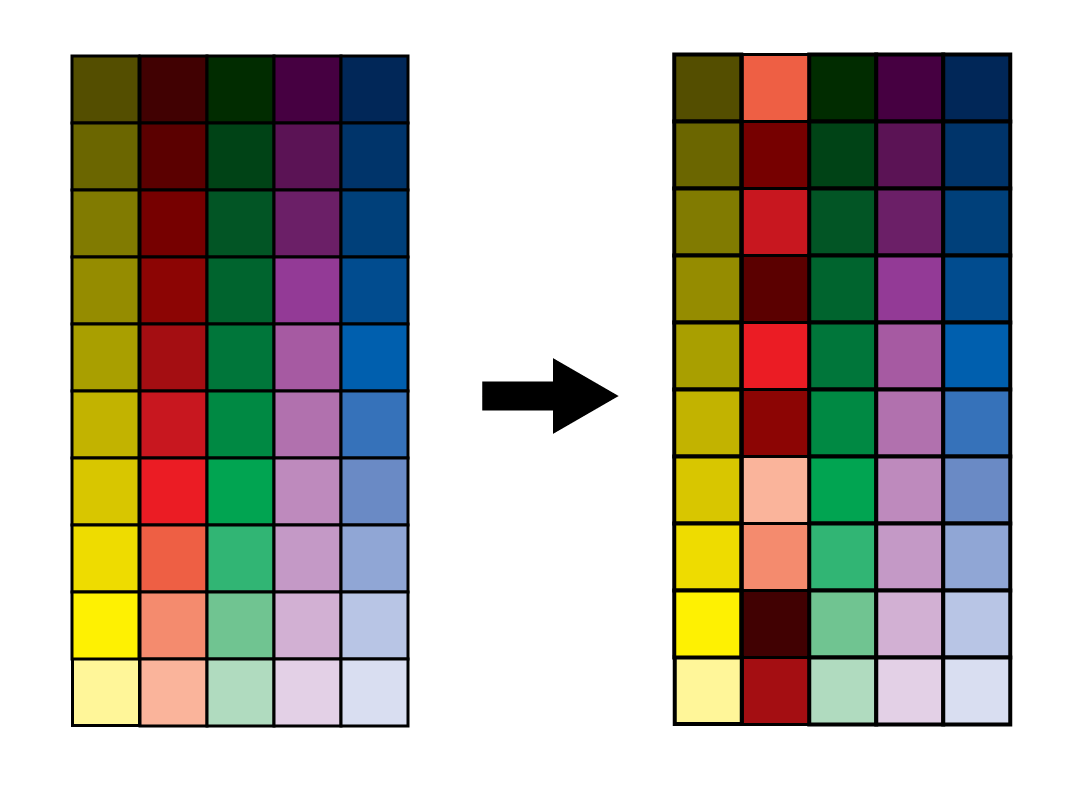
Introduction Data normalization is a crucial preprocessing step in data analysis and machine learning workflows. It helps in standardizing the scale of numeric features, ensuring fair treatment to all variables regardless of their magnitude. In ...

Planning poker, also called Scrum poker, is a consensus-based, gamified technique for estimating, mostly used for timeboxing in Agile principles. In planning poker, members of the group make estimates by playing numbered cards face-down to the table, instead of speaking them aloud. The cards are revealed, and the estimates are then discussed. By hiding the figures in this way, the group can avoid the cognitive bias of anchoring, where the first number spoken aloud sets a precedent for subsequent estimates.

Standardization, Normalization, Robust Scaling, Mean Normalization, Maximum Absolute Scaling and Vector Unit Length Scaling

A gentle dive into this unusual feature selection technique
Python Feature Engineering Cookbook Second Edition, published by Packt - PacktPublishing/Python-Feature-Engineering-Cookbook-Second-Edition
Sourced from O'Reilly ebook of the same name.
Updates in progress. Jupyter workbooks will be added as time allows. - bjpcjp/scikit-learn

Bonus: What makes a good footballer great?

A simple technique for boosting accuracy on ANY model you use
The ability of the Generative Adversarial Networks (GANs) framework to learn generative models mapping from simple latent distributions to arbitrarily complex data distributions has been...
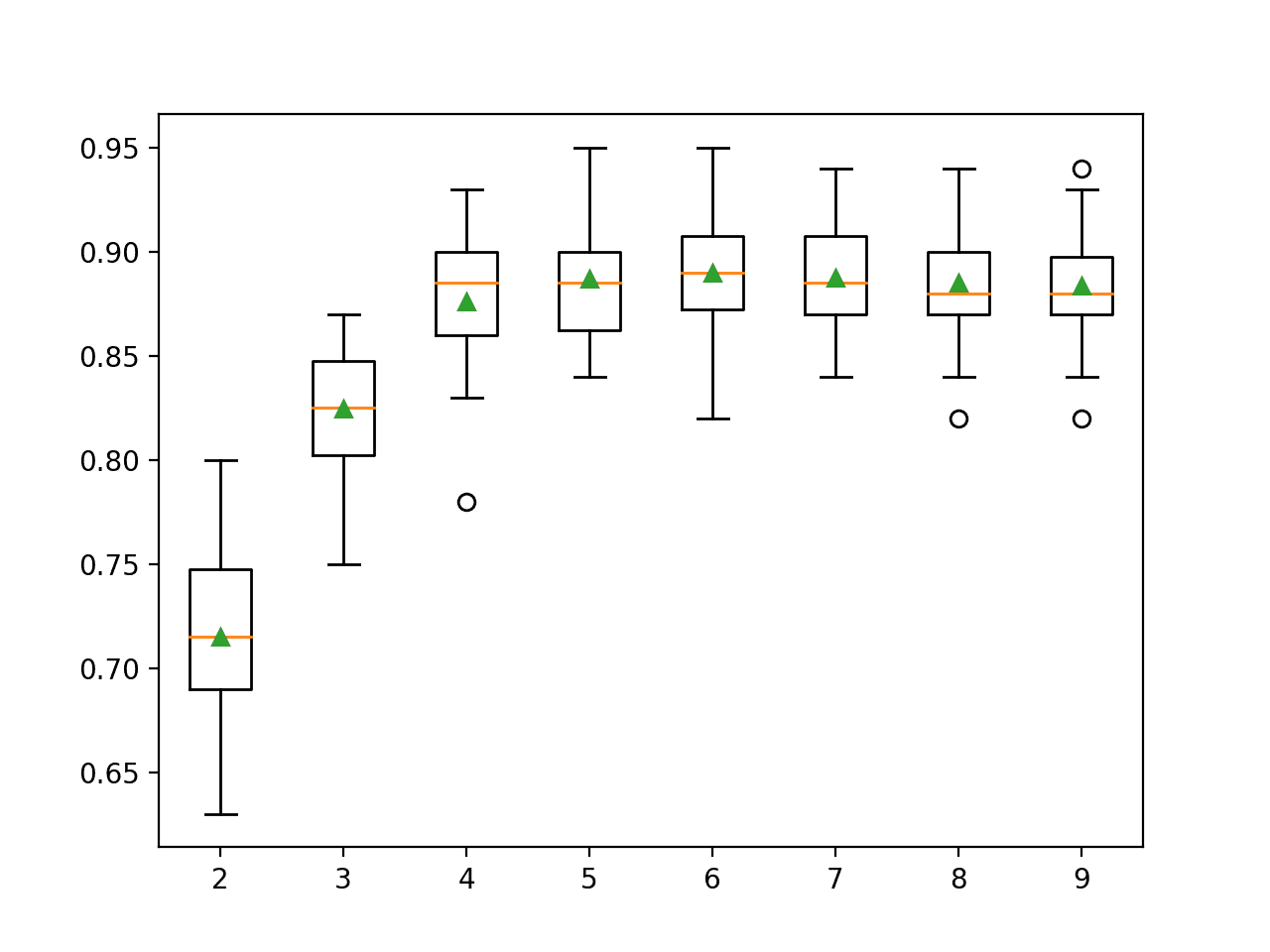
Recursive Feature Elimination, or RFE for short, is a popular feature selection algorithm. RFE is popular because it is easy to configure and use and because it is effective at selecting those features (columns) in a training dataset that are more or most relevant in predicting the target variable. There are two important configuration options when using RFE: the choice…
originally posted by the author on Linkedin : Link It is very tempting for data science practitioners to opt for the best known algorithms for a given problem.However It’s not the algorithm alone , which can provide the best solution ; Model built on carefully engineered and selected features can provide far better results. “Any intelligent… Read More »Feature Engineering: Data scientist's Secret Sauce !
This article will introduce the different type of data sets, data object and attributes.

Permutation Importance as a feature selection method

The O’Reilly Data Show Podcast: Alex Ratner on how to build and manage training data with Snorkel.

This post is about some of the most common feature selection techniques one can use while working with data.
168 votes, 13 comments. 2.2M subscribers in the datascience community. A space for data science professionals to engage in discussions and debates on…

Using the FeatureSelector for efficient machine learning workflows

Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.

Unsure how to perform feature engineering? Here are 20 best practices and heuristics that will help you engineer great features for machine learning.

Traditional strategies for taming unstructured, textual data

Strategies for working with discrete, categorical data

Strategies for working with continuous, numerical data

Data Engineering: The Close Cousin of Data Science

2.9M subscribers in the MachineLearning community. Beginners -> /r/mlquestions , AGI -> /r/singularity, career advices -> /r/cscareerquestions…