
Explore the Google vs OpenAI AI ecosystem battle post-o3. Deep dive into Google's huge cost advantage (TPU vs GPU), agent strategies & model risks for enterprise
Explore the Google vs OpenAI AI ecosystem battle post-o3. Deep dive into Google's huge cost advantage (TPU vs GPU), agent strategies & model risks for enterprise

The Future of AI Accelerators: A Roadmap of Industry Leaders The AI hardware race is heating up, with major players like NVIDIA, AMD, Intel, Google, Amazon, and more unveiling their upcoming AI accelerators. Here’s a quick breakdown of the latest trends: Key Takeaways: NVIDIA Dominance: NVIDIA continues to lead with a robust roadmap, extending from H100 to future Rubin and Rubin Ultra chips with HBM4 memory by 2026-2027. AMD’s Competitive Push: AMD’s MI300 series is already competing, with MI350 and future MI400 models on the horizon. Intel’s AI Ambitions: Gaudi accelerators are growing, with Falcon Shores on track for a major memory upgrade. Google & Amazon’s Custom Chips: Google’s TPU lineup expands rapidly, while Amazon’s Trainium & Inferentia gain traction. Microsoft & Meta’s AI Expansion: Both companies are pushing their AI chip strategies with Maia and MTIA projects, respectively. Broadcom & ByteDance Join the Race: New challengers are emerging, signaling increased competition in AI hardware. What This Means: With the growing demand for AI and LLMs, companies are racing to deliver high-performance AI accelerators with advanced HBM (High Bandwidth Memory) configurations. The next few years will be crucial in shaping the AI infrastructure landscape. $NVDA $AMD $INTC $GOOGL $AMZN $META $AVGO $ASML $BESI
Parallel thread execution (PTX) is a virtual machine instruction set architecture that has been part of CUDA from its beginning. You can think of PTX as the…

AMD acquired ATI in 2006, hoping ATI's GPU expertise would combine with AMD's CPU know-how to create integrated solutions worth more than the sum of their parts.

Apple's latest machine learning research could make creating models for Apple Intelligence faster, by coming up with a technique to almost triple the rate of generating tokens when using Nvidia GPUs.

Intel's first Arc B580 GPUs based on the Xe2 "Battlemage" architecture have been leaked & they look quite compelling.
No matter how elegant and clever the design is for a compute engine, the difficulty and cost of moving existing – and sometimes very old – code from the

H100s used to be $8/hr if you could get them. Now there's 7 different places sometimes selling them under $2. What happened?

NVIDIA's "Blackwell" series of GPUs, including B100, B200, and GB200, are reportedly sold out for 12 months or an entire year. This directly means that if a new customer is willing to order a new Blackwell GPU now, there is a 12-month waitlist to get that GPU. Analyst from Morgan Stanley Joe Moore c...

Large Language Models (LLMs) have gained significant prominence in recent years, driving the need for efficient GPU utilization in machine learning tasks. However, researchers face a critical challenge in accurately assessing GPU performance. The commonly used metric, GPU Utilization, accessed through nvidia-smi or integrated observability tools, has proven to be an unreliable indicator of actual computational efficiency. Surprisingly, 100% GPU utilization can be achieved merely by reading and writing to memory without performing any computations. This revelation has sparked a reevaluation of performance metrics and methodologies in the field of machine learning, prompting researchers to seek more accurate ways to

AI won't replace you, but someone using AI will — so it’s time to embrace AI, and it’s possible to do so even on a low budget.

NVIDIA's Blackwell AI servers to witness a massive shipment volume in Q4 2024, with Microsoft being the most "aggressive" acquirer.

Speed and efficiency are crucial in computer graphics and simulation. It can be challenging to create high-performance simulations that can run smoothly on various hardware setups. Traditional methods can be slow and may not fully utilize the power of modern graphics processing units (GPUs). This creates a bottleneck for real-time or near-real-time feedback applications, such as video games, virtual reality environments, and scientific simulations. Existing solutions for this problem include using general-purpose computing on graphics processing units (GPGPU) frameworks like CUDA and OpenCL. These frameworks allow developers to write programs that can run on GPUs, but they often require a

Attention, as a core layer of the ubiquitous Transformer architecture, is a bottleneck for large language models and long-context applications. FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is now used by most libraries to accelerate Transformer training and inference. This has contributed to a massive increase in LLM context length in the last two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), or even 1M (Llama 3). However, despite its success, FlashAttention has yet to take advantage of new capabilities in modern hardware, with FlashAttention-2 achieving only 35% utilization of theoretical max FLOPs on the H100 GPU. In this blogpost, we describe three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for FP8 low-precision.

Nscale has tested AMD's flagship Instinct MI300X AI accelerator utilizing the GEMM tuning framework, achieving 7x faster performance.

GPU maker tops new MLPerf benchmarks on graph neural nets and LLM fine-tuning
It is not a coincidence that the companies that got the most “Hopper” H100 allocations from Nvidia in 2023 were also the hyperscalers and cloud builders,

Datacenter GPUs and some consumer cards now exceed performance limits

Beijing will be thrilled by this nerfed silicon

Today is the ribbon-cutting ceremony for the “Venado” supercomputer, which was hinted at back in April 2021 when Nvidia announced its plans for its first

Intel claims 50% more speed when running AI language models vs. the market leader.

GPT-4 Profitability, Cost, Inference Simulator, Parallelism Explained, Performance TCO Modeling In Large & Small Model Inference and Training
While a lot of people focus on the floating point and integer processing architectures of various kinds of compute engines, we are spending more and more

AMD plans to open-source portions of its ROCm software stack and hardware documentation in a future update to refine its ecosystem.

Lenovo, the firm emerging as a driving force behind AI computing, has expressed tremendous optimism about AMD's Instinct MI300X accelerator.
We like datacenter compute engines here at The Next Platform, but as the name implies, what we really like are platforms – how compute, storage,
While there have been efforts by AMD over the years to make it easier to port codebases targeting NVIDIA's CUDA API to run atop HIP/ROCm, it still requires work on the part of developers.

Chafing at their dependence, Amazon, Google, Meta and Microsoft are racing to cut into Nvidia’s dominant share of the market.

When discussing GenAI, the term "GPU" almost always enters the conversation and the topic often moves toward performance and access. Interestingly, the word "GPU" is assumed to mean "Nvidia" products. (As an aside, the popular Nvidia hardware used in GenAI are not technically...

AMD, Nvidia, and Intel have all diverged their GPU architectures to separately optimize for compute and graphics.
We’re releasing Triton 1.0, an open-source Python-like programming language which enables researchers with no CUDA experience to write highly efficient GPU code—most of the time on par with what an expert would be able to produce.
In this article we will learn about its definition, differences and how to calculate FLOPs and MACs using Python packages.
Quarterly Ramp for Nvidia, Broadcom, Google, AMD, AMD Embedded (Xilinx), Amazon, Marvell, Microsoft, Alchip, Alibaba T-Head, ZTE Sanechips, Samsung, Micron, and SK Hynix

Though it'll arrive just in time for mid-cycle refresh from AMD, Nvidia, and Intel, it's unclear if there will be any takers just yet.

The great thing about the Cambrian explosion in compute that has been forced by the end of Dennard scaling of clock frequencies and Moore’s Law lowering
Editor’s Note (6/14/2023): We have a new article that reevaluates the cache latency of Navi 31, so please refer to that article for some new latency data.

GPUs may dominate, but CPUs could be perfect for smaller AI models

Google's new machines combine Nvidia H100 GPUs with Google’s high-speed interconnections for AI tasks like training very large language models.

Earlier this week a letter from an activist imprisoned in France was posted to the internet. Contained within Ivan Alococo’s dispatch from the Villepinte prison
As computing system become more complex, it is becoming harder for programmers to keep their codes optimized as the hardware gets updated. Autotuners try to alleviate this by hiding as many archite…

The $10,000 Nvidia A100has become one of the most critical tools in the artificial intelligence industry,
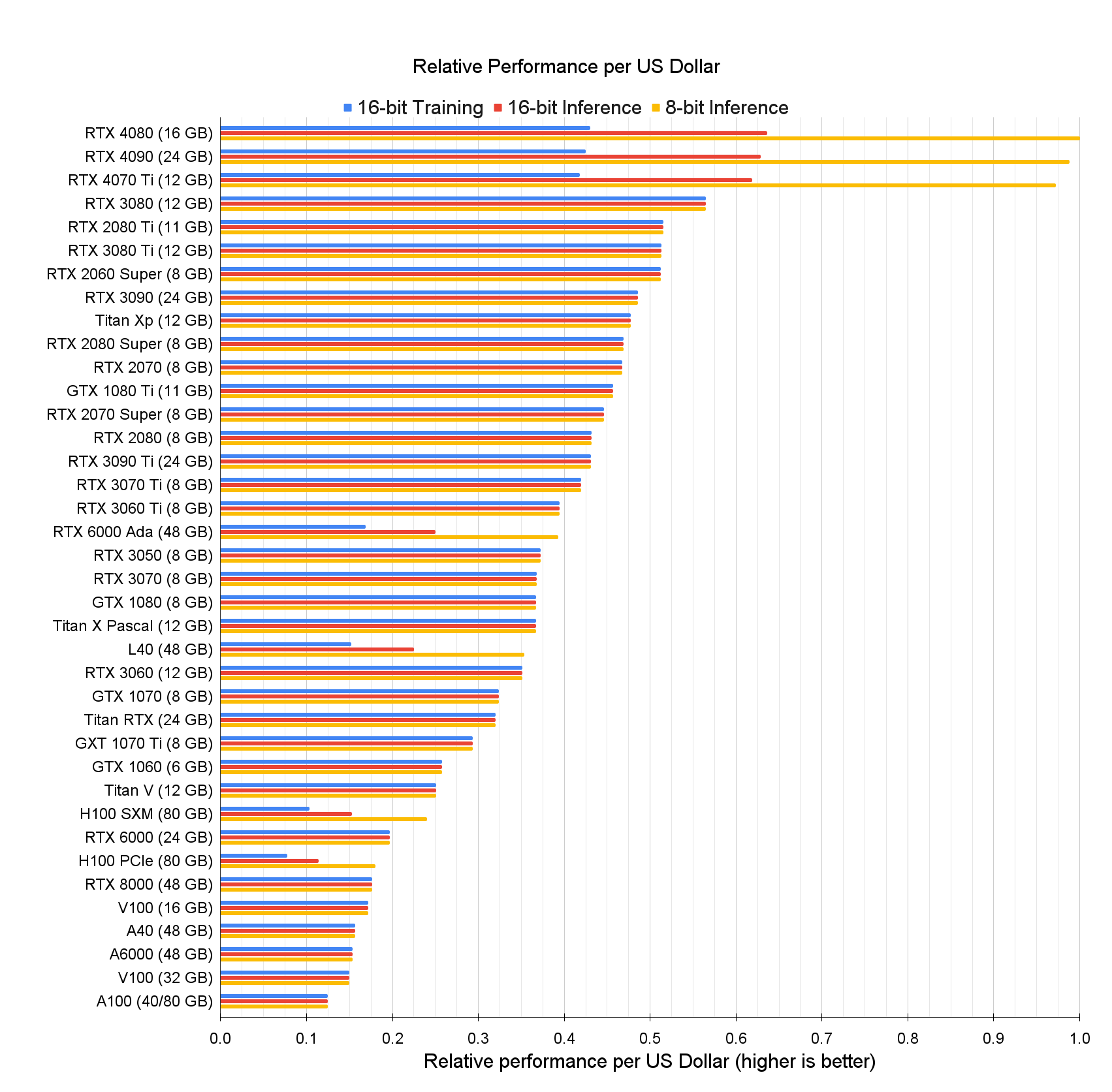
Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.
NVIDIA announces the newest CUDA Toolkit software release, 12.0. This release is the first major release in many years and it focuses on new programming models and CUDA application acceleration…
The Power of PyTorch/XLA and how Amazon SageMaker Training Compiler Simplifies its use

A new video making the rounds purports to show Vietnamese crypto miners preparing used GPUs for resale by blasting them with a pressure washer.
There are two types of packaging that represent the future of computing, and both will have validity in certain domains: Wafer scale integration and

Nvidia has staked its growth in the datacenter on machine learning. Over the past few years, the company has rolled out features in its GPUs aimed neural

Nallatech doesn't make FPGAs, but it does have several decades of experience turning FPGAs into devices and systems that companies can deploy to solve
In this work, we analyze the performance of neural networks on a variety of heterogenous platforms. We strive to find the best platform in terms of raw benchmark performance, performance per watt a…
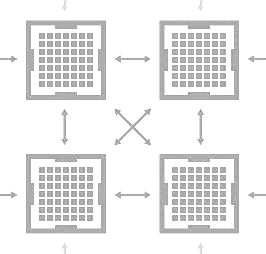
One of the breakthrough moments in computing, which was compelled by necessity, was the advent of symmetric multiprocessor, or SMP, clustering to make two

The modern GPU compute engine is a microcosm of the high performance computing datacenter at large. At every level of HPC – across systems in the
The rise of deep-learning (DL) has been fuelled by the improvements in accelerators. GPU continues to remain the most widely used accelerator for DL applications. We present a survey of architectur…
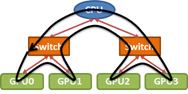
Today many servers contain 8 or more GPUs. In principle then, scaling an application from one to many GPUs should provide a tremendous performance boost. But in practice, this benefit can be difficult…

GPU Computing for Data Science - Download as a PDF or view online for free
Modeling data sharing in GPU programs is a challenging task because of the massive parallelism and complex data sharing patterns provided by GPU architectures. Better GPU caching efficiency can be...
Unified Memory on NVIDIA Pascal GPUs enables applications to run out-of-the-box with larger memory footprints and achieve great baseline performance.

Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As

Its second analog AI chip is optimized for different card sizes, but still aimed at computer vision workloads at the edge.

Current custom AI hardware devices are built around super-efficient, high performance matrix multiplication. This category of accelerators includes the

This post is the seventh installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform…

Rice University computer scientists have demonstrated artificial intelligence (AI) software that runs on commodity processors and trains deep neural networks 15 times faster than platforms based on graphics ...
See how to build end-to-end NLP pipelines in a fast and scalable way on GPUs — from feature engineering to inference.

What makes a GPU a GPU, and when did we start calling it that? Turns out that’s a more complicated question than it sounds.

AMD is one of the oldest designers of large scale microprocessors and has been the subject of polarizing debate among technology enthusiasts for nearly 50 years. Its...
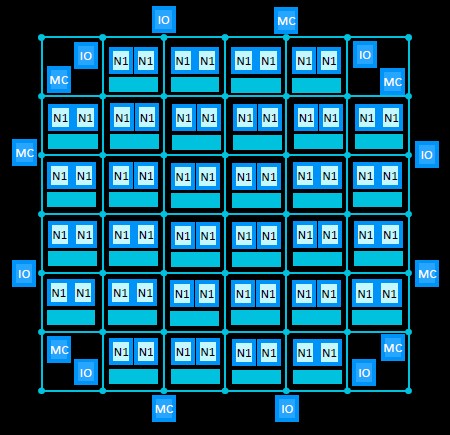
One of the main tenets of the hyperscalers and cloud builders is that they buy what they can and they only build what they must. And if they are building
AMD ROCm documentation

In this post we take a look at how to use cuDF, the RAPIDS dataframe library, to do some of the preprocessing steps required to get the mortgage data in a format that PyTorch can process so that we…

Historically speaking, processing large amounts of structured data has been the domain of relational databases. Databases, consisting of tables that can be joined together or aggregated…

This series on the RAPIDS ecosystem explores the various aspects that enable you to solve extract, transform, load (ETL) problems, build machine learning (ML) and deep learning (DL) models…

Long-time Slashdot reader UnknowingFool writes: AMD filed a patent on using chiplets for a GPU with hints on why it has waited this long to extend their CPU strategy to GPUs. The latency between chiplets poses more of a performance problem for GPUs, and AMD is attempting to solve the problem with a ...

Most of the modern Linux Desktop systems come with Nvidia driver pre-installed in a form of the Nouveau open-source graphics device driver for Nvidia video cards. Hence depending on your needs and in…
Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.

Micron's GDDR6X is one of the star components in Nvidia's RTX 3070, 3080, and 3080 video cards. It's so fast it should boost gaming past the 4K barrier.
When you have 54.2 billion transistors to play with, you can pack a lot of different functionality into a computing device, and this is precisely what
The new NVIDIA A100 GPU based on the NVIDIA Ampere GPU architecture delivers the greatest generational leap in accelerated computing. The A100 GPU has revolutionary hardware capabilities and we’re…

In this tutorial, you will learn how to get started with your NVIDIA Jetson Nano, including installing Keras + TensorFlow, accessing the camera, and performing image classification and object detection.
363 votes, 25 comments. This post has been split into a two-part series to work around Reddit’s per-post character limit. Please find Part 2 in the…

Answer (1 of 7): Lots. Definitions of the term "data centre" tend to vary. Some would label a small machine room with 2 or 3 racks a data centre, but that is not really a large facility by any stretch of the imagination. Most such installations are never going to hit the usual problems which dat...

Making Waves in Deep Learning How deep learning applications will map onto a chip.

A new crop of applications is driving the market along some unexpected routes, in some cases bypassing the processor as the landmark for performance and











