
At OpenAI, we have long believed image generation should be a primary capability of our language models. That’s why we’ve built our most advanced image generator yet into GPT‑4o. The result—image generation that is not only beautiful, but useful.
At OpenAI, we have long believed image generation should be a primary capability of our language models. That’s why we’ve built our most advanced image generator yet into GPT‑4o. The result—image generation that is not only beautiful, but useful.

AI art generation has entered an era of evolution over revolution

Google has launched a new AI image generation tool called Whisk, which allows users to create visual outputs from existing

In this tutorial, we’ll build an AI image-generation app with JavaScript. Users will enter text describing the image they want, then behind the scenes we’ll call the DALL-E 3 API to generate it!

This article was co-authored by @makkukuma Introduction The proliferation of Artificial...

In a significant technological leap, OpenAI has announced the launch of DALL·E 3, the latest iteration in their groundbreaking text-to-image generation technology. With an unprecedented capacity to understand nuanced and detailed descriptions, DALL·E 3 promises to revolutionize the creative landscape by allowing users to translate their textual ideas into astonishingly accurate images effortlessly. DALL·E 3 is currently in research preview, offering a tantalizing glimpse into its capabilities. However, the broader availability of this cutting-edge technology is set for early October, when it will be accessible to ChatGPT Plus and Enterprise customers through the API and Labs later in the fall.

DALL-E 3, the latest version of OpenAI's ground-breaking generative AI visual art platform, was just announced with groundbreaking features, including

Video and audio recordings of people saying or doing things they never said or did can be created using AI deepfake generators and software tools that use artificial intelligence to make convincing fakes. A neural network is trained using a massive collection of authentic media featuring the target individual to accomplish this. The web is trained to recognize individuals and imitate their appearance, speech, and behavior. There is a wide range of potential good and bad uses for AI deepfake generators. You can use them to make comedic videos or instructional materials. Here are some AI deepfake generators for photos

Navigating the maze of pricing plans for digital services can sometimes be a daunting task. Today, we are unveiling Midjourney

Looking at the sample sets of generated images that Meta has shared in its blog post about CM3leon, the results are impressive.

Midjourney now offers the ability to manifest the evolution of your AI-generated images into a concise Midjourney video. This captivating

Do you want to generate Midjourney images, but don't you know what to do and what you can do exactly

We found the best new creative tools using generative AI, so you don't have to. This week's big news? The new Stable Diffusion XL is now available.

AI-generated images have never been more popular, and Midjourney is one of the best tools. Here's how to access the AI and what to know about using it.

Learn how to use the text-to-image service, Midjourney on Discord or the web to create custom images from simple text prompts.

Stability AI, a startup that helped develop popular open-source image generator Stable Diffusion, is in serious trouble, Semafor reports.
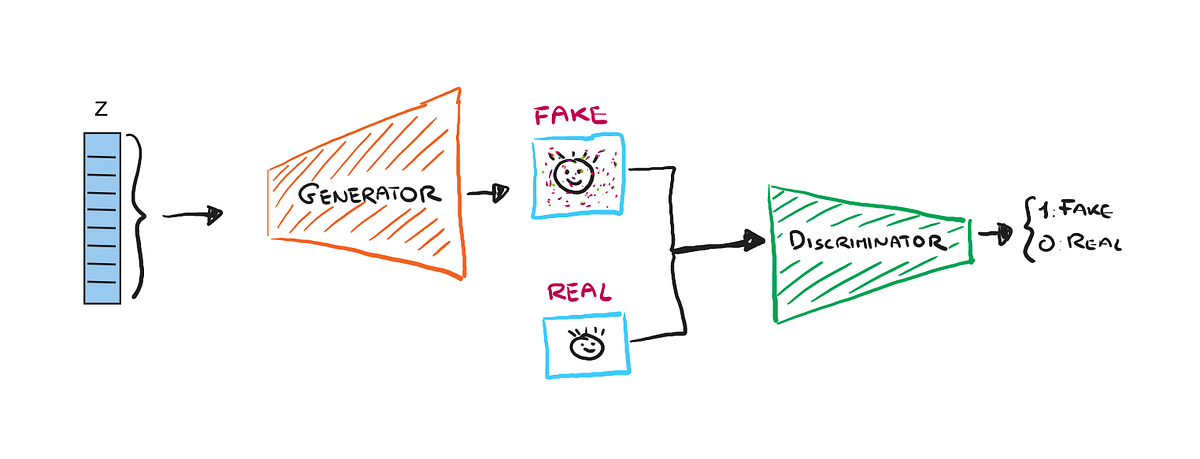
Learn how to implement GANs with PyTorch to generate synthetic images

Generative AI is a hot topic in the tech startup world, and the ongoing advancement of latent diffusion models only expands its use cases.
A critical analysis of Google’s impressive new text-to-image generation tool

The regurgitation of training data exposes image diffusion models to a number of privacy and copyright risks.

AI tech makes it trivial to generate harmful fake photos from a few social media pictures.

An overview of DCGAN architecture with a step-by-step guide to building it yourself

Dall-E can illustrate just about anything using a short text prompt. Should it?

It takes a human being around 0.1 to 0.4 seconds to blink. In even less time, an AI-based inverse rendering process developed by NVIDIA can generate a 3D scene from 2D photos.

Reconstructing Images using Reinforcement Learning and Genetic Algorithms

I have aggregated some of the SotA image generative models released recently, with short summaries, visualizations and comments. The overall development is summarized, and the future trends are spe…

**Image Generation** (synthesis) is the task of generating new images from an existing dataset. - **Unconditional generation** refers to generating samples unconditionally from the dataset, i.e. $p(y)$ - **[Conditional image generation](/task/conditional-image-generation)** (subtask) refers to generating samples conditionally from the dataset, based on a label, i.e. $p(y|x)$. In this section, you can find state-of-the-art leaderboards for **unconditional generation**. For conditional generation, and other types of image generations, refer to the subtasks. ( Image credit: [StyleGAN](https://github.com/NVlabs/stylegan) )

Nvidia's GauGAN tool has been used to create more than 500,000 images, the company announced at the SIGGRAPH 2019 conference in Los Angeles.

Through a human’s eyes, the world is much more than just the images reflected in our corneas. For example, when we look at a building and admire the intricacies of its design, we can appreciate...
