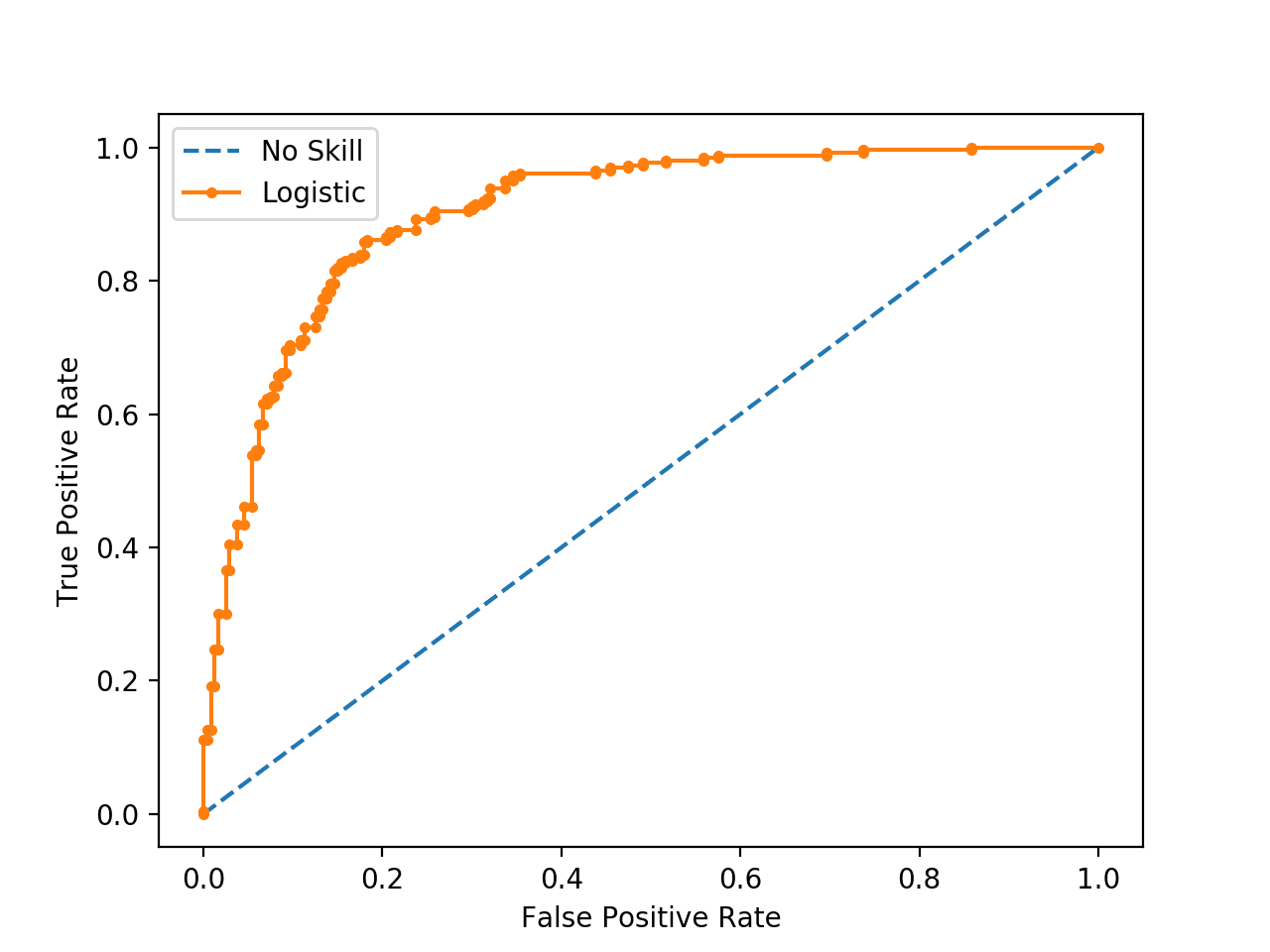
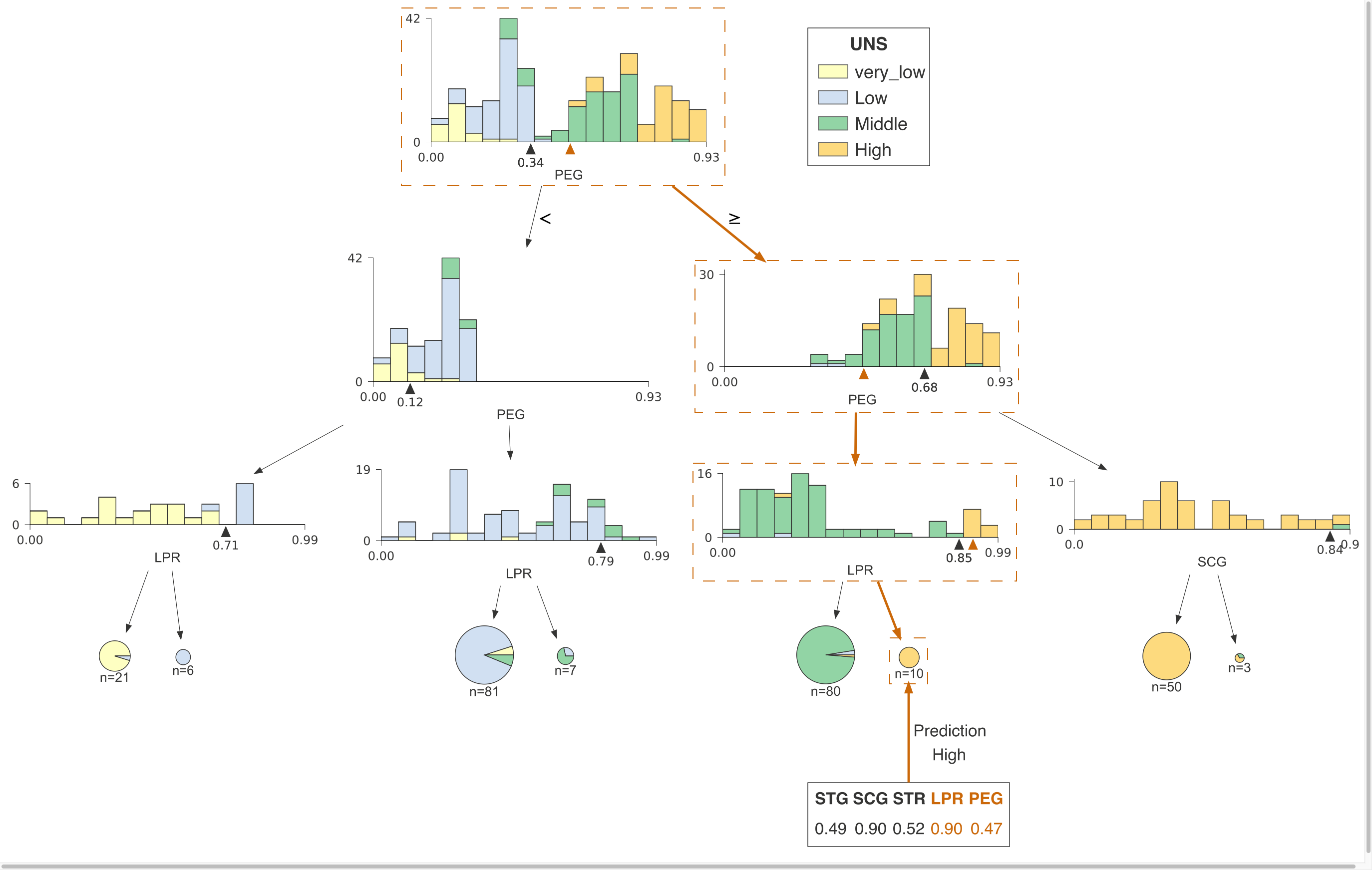
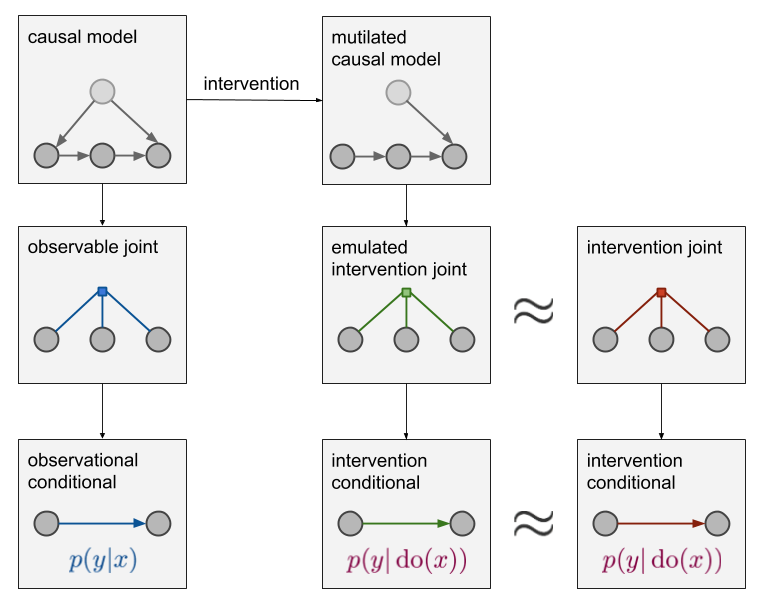
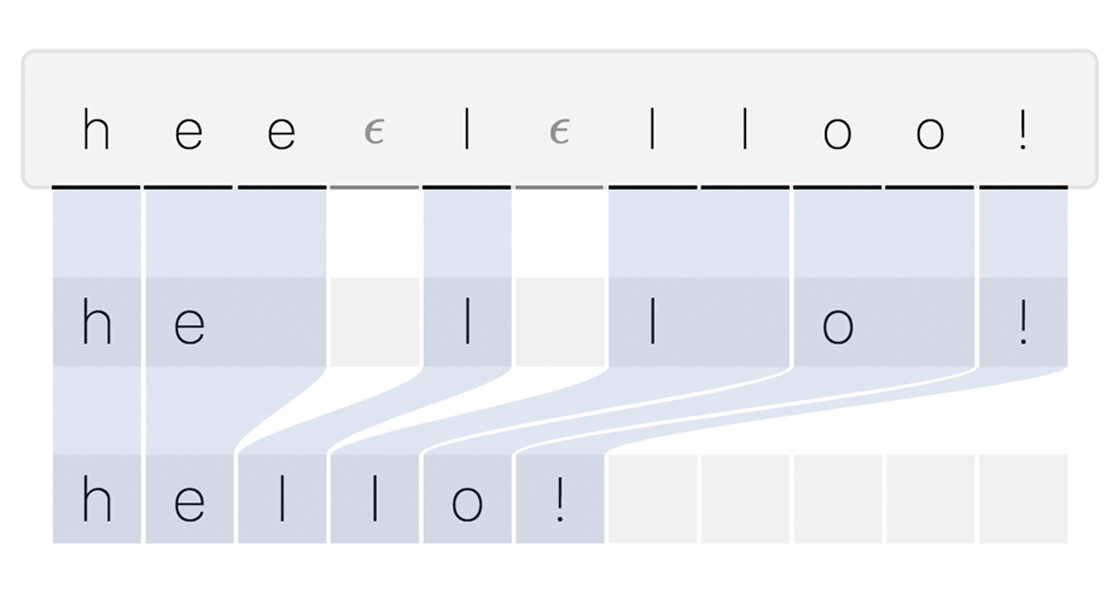
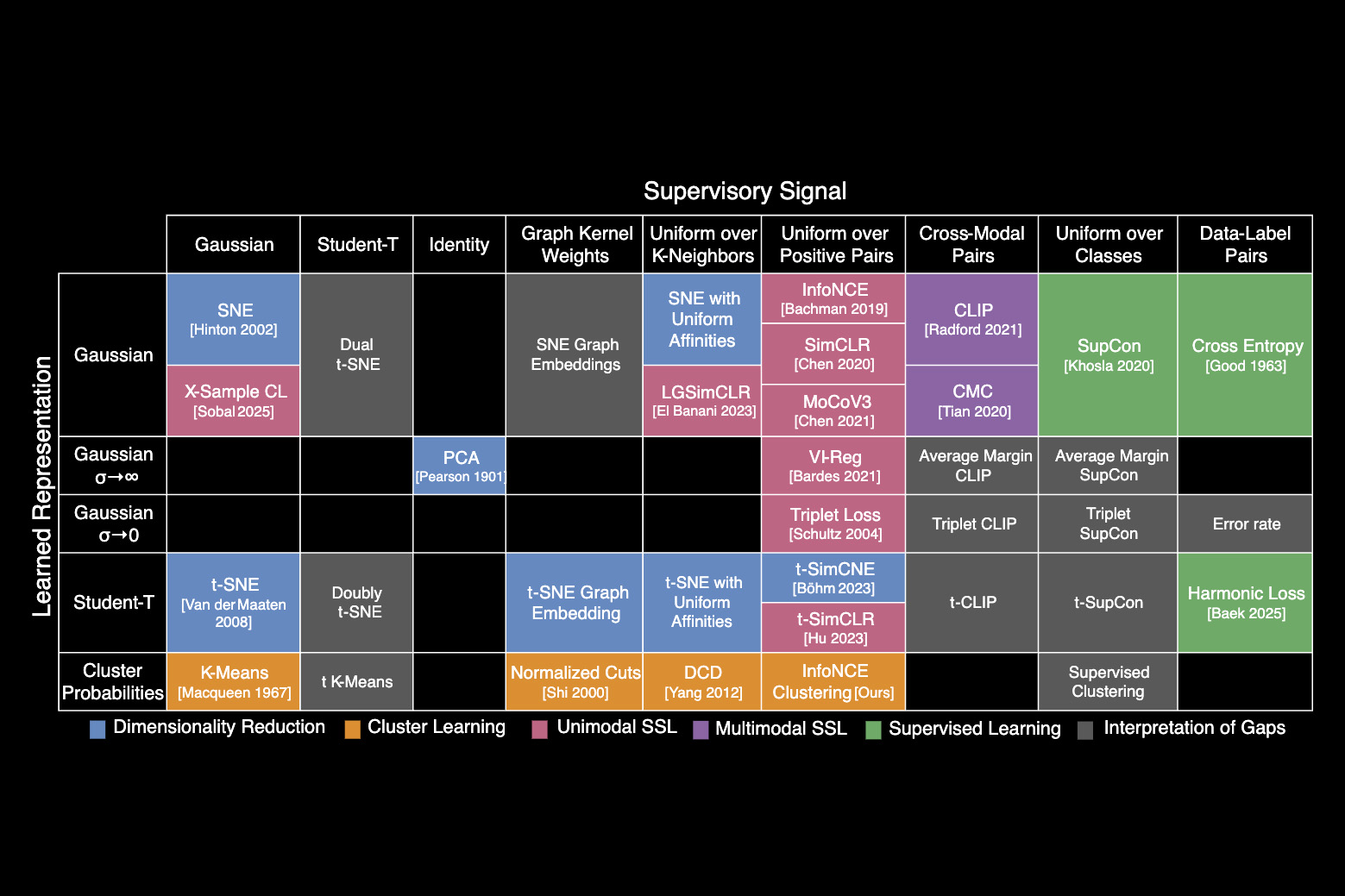
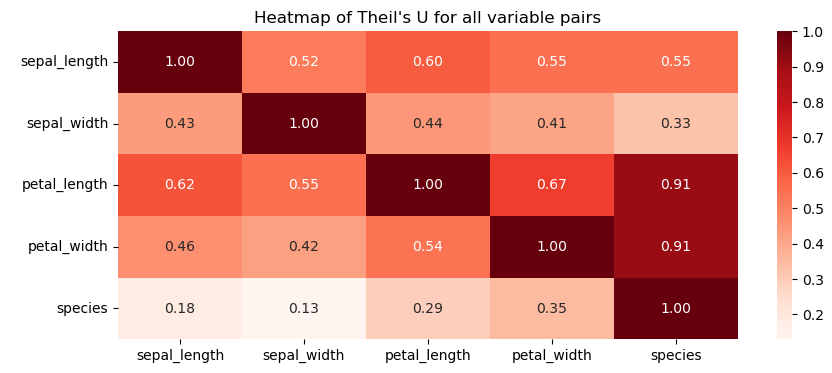
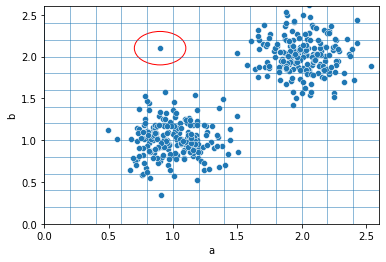
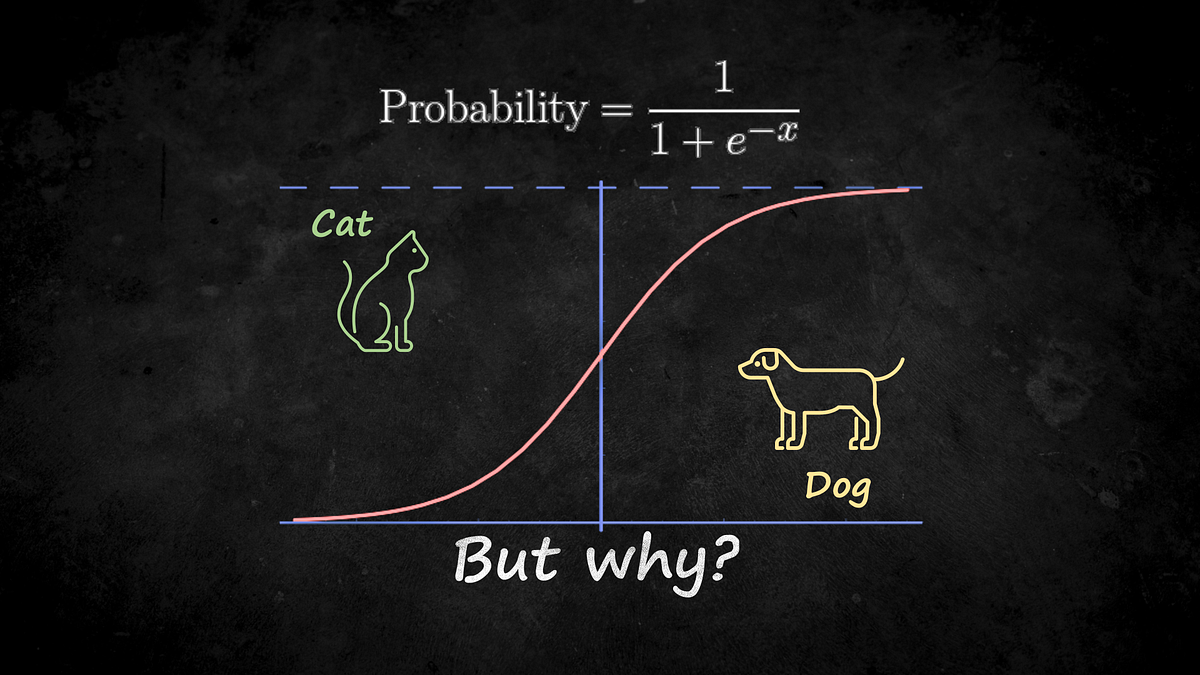
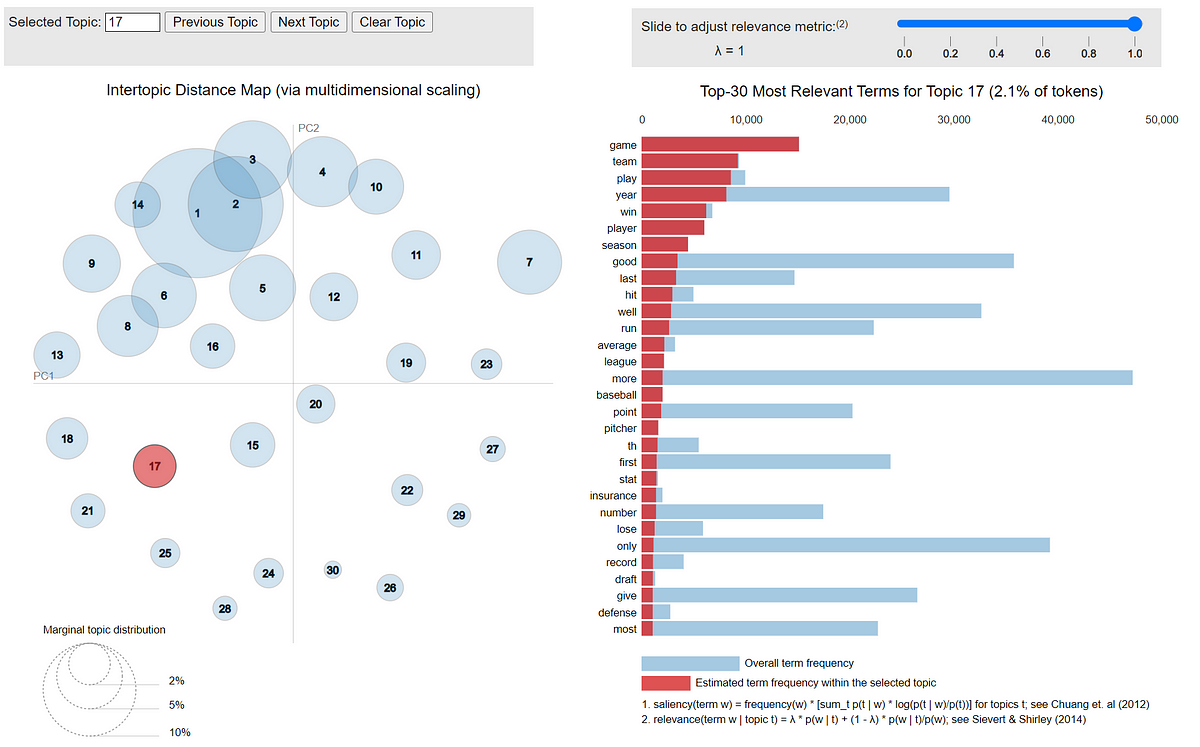
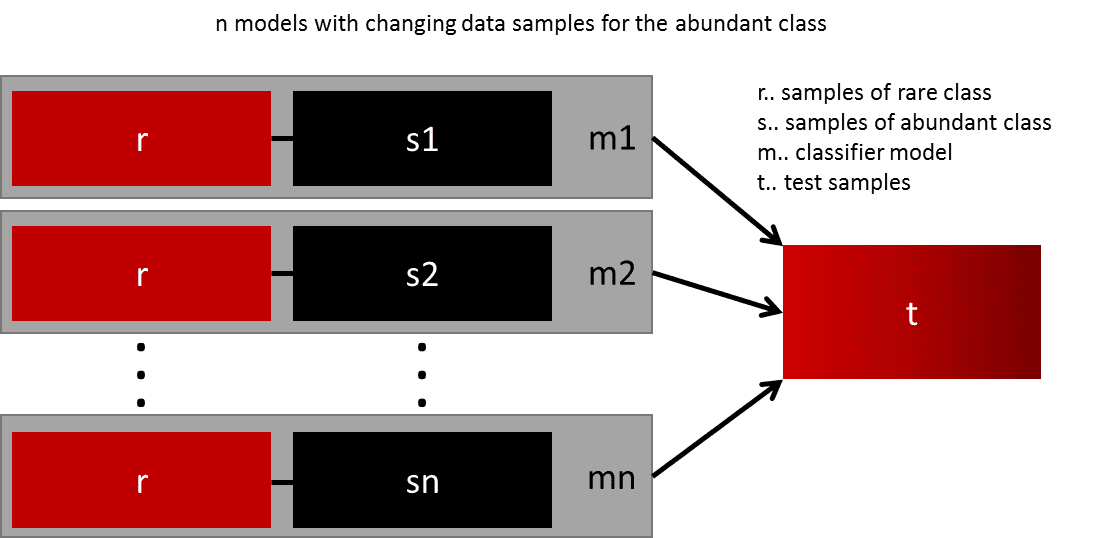
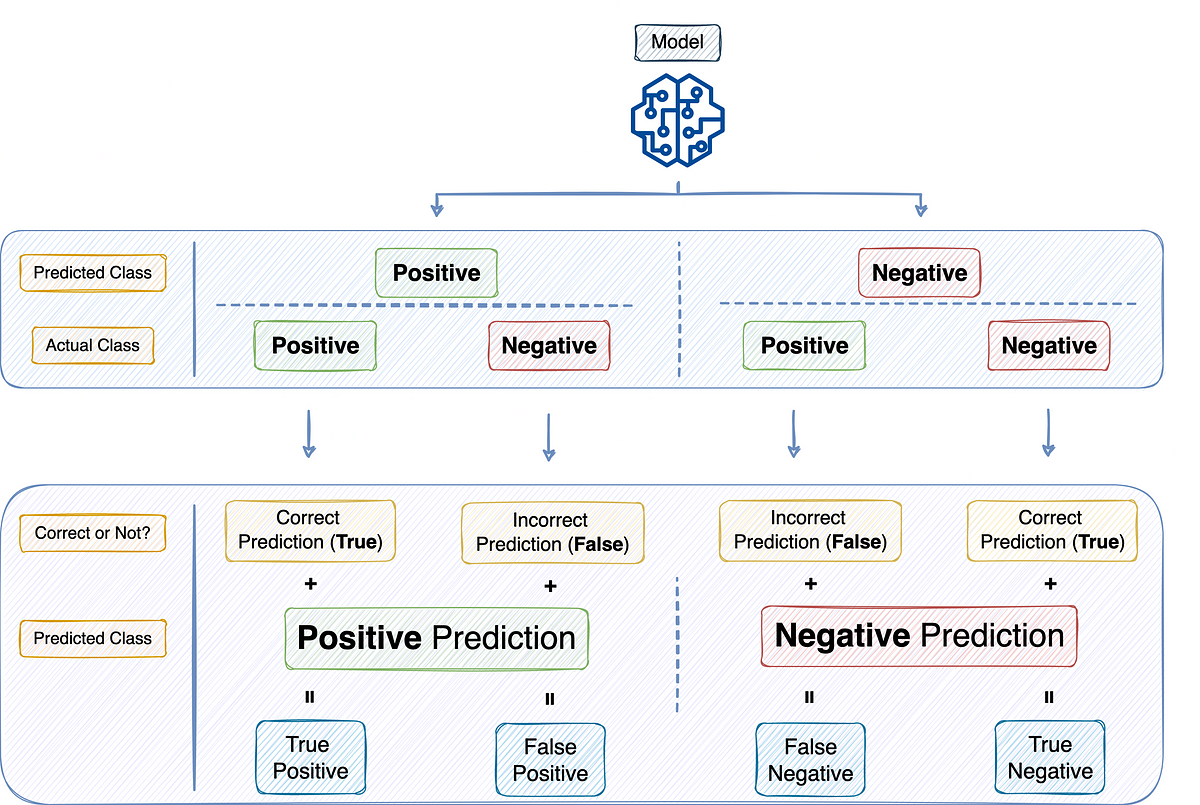
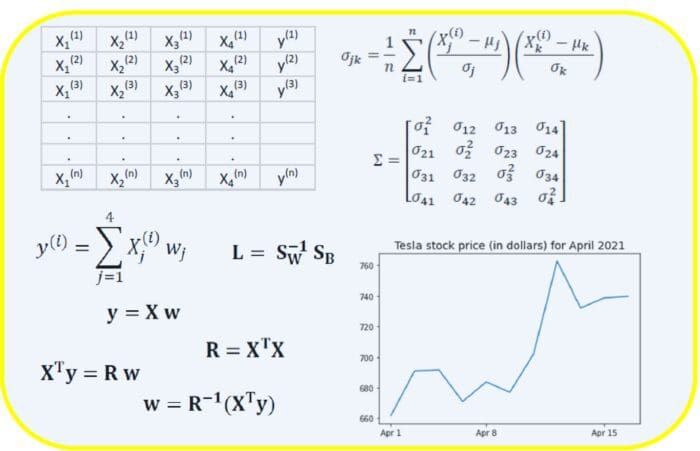
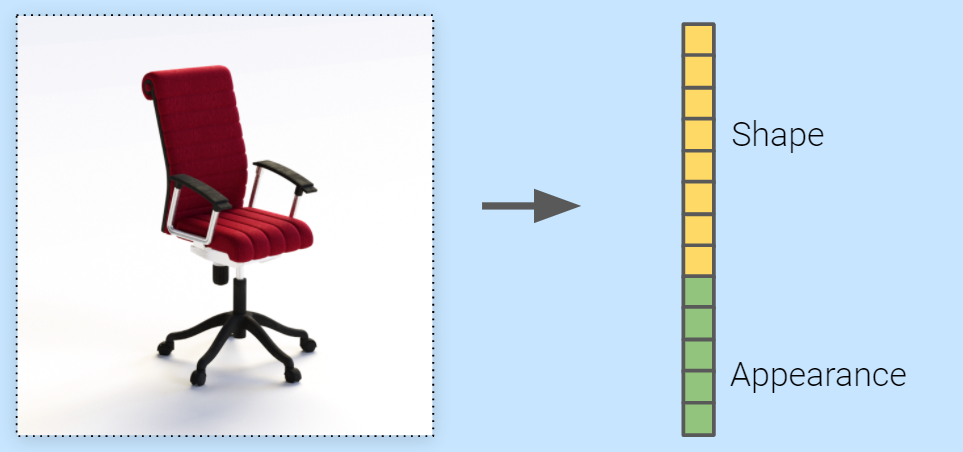
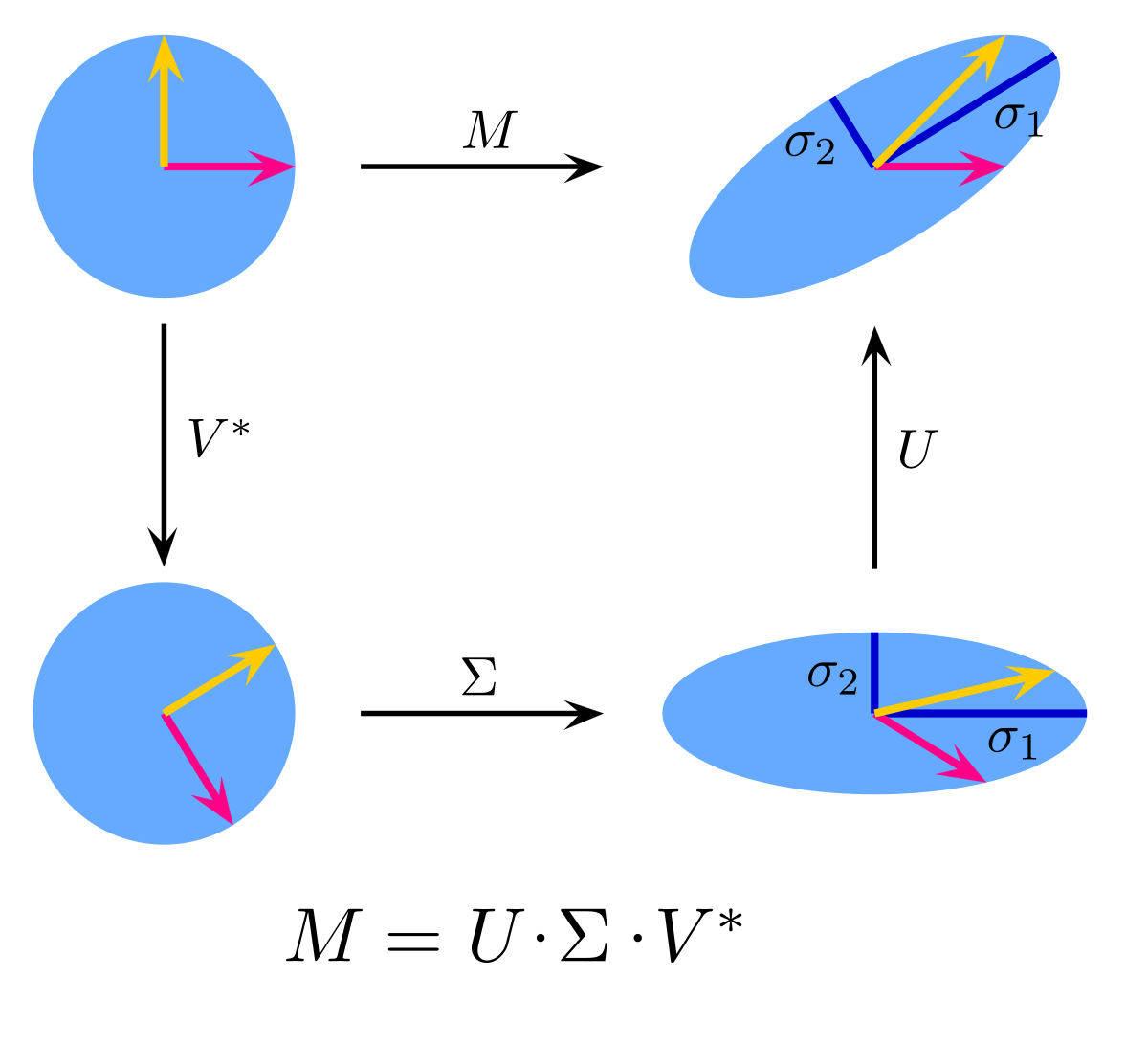
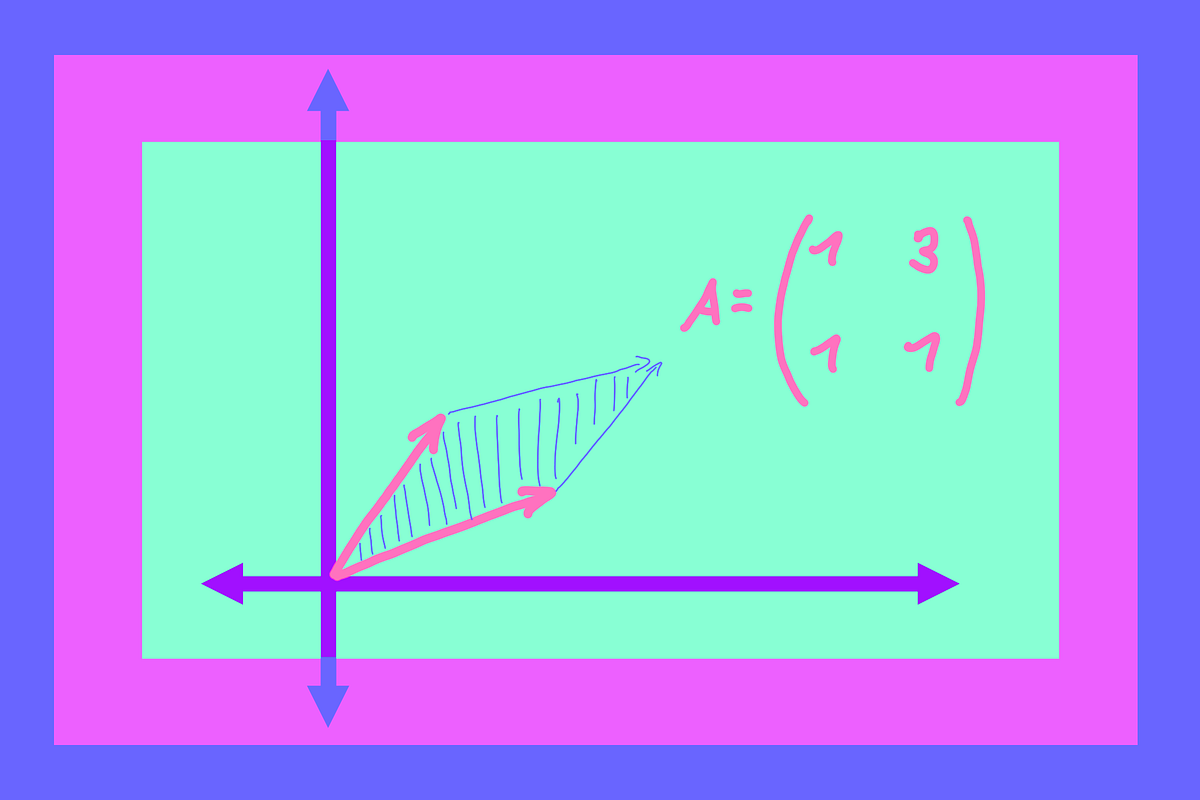
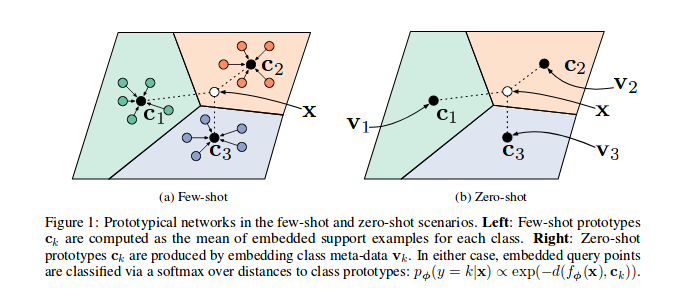
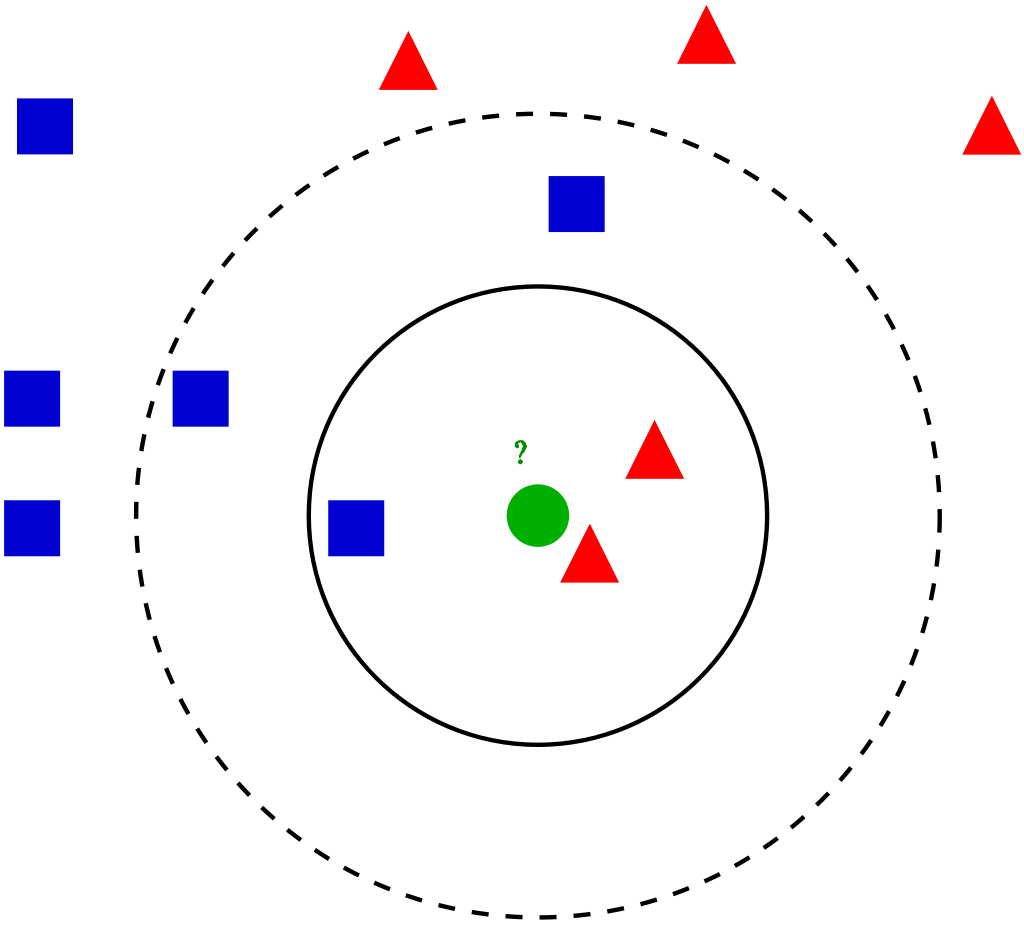
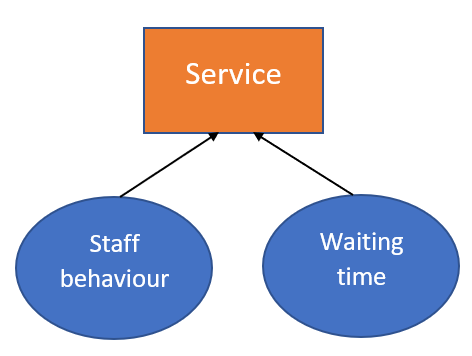
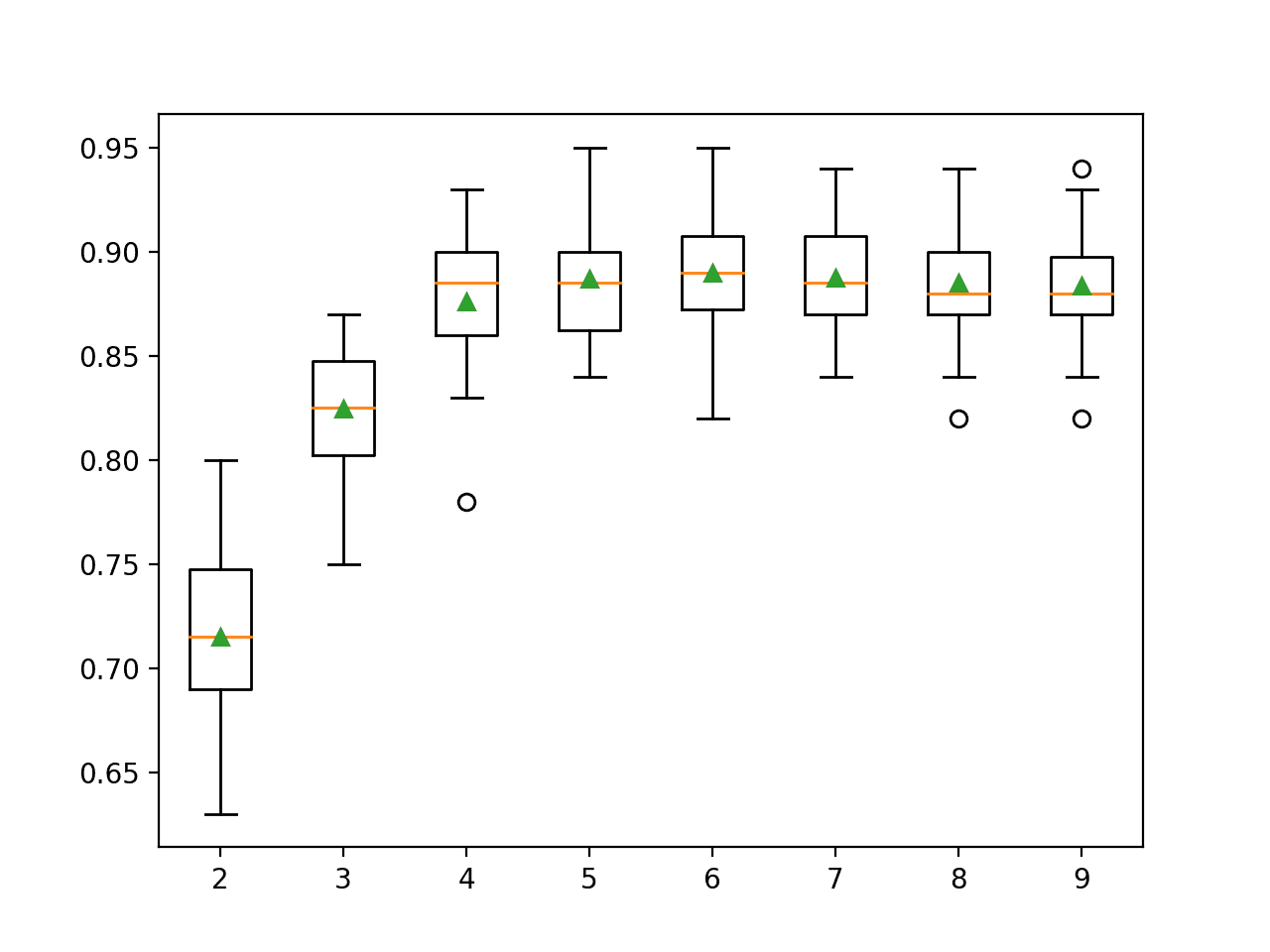
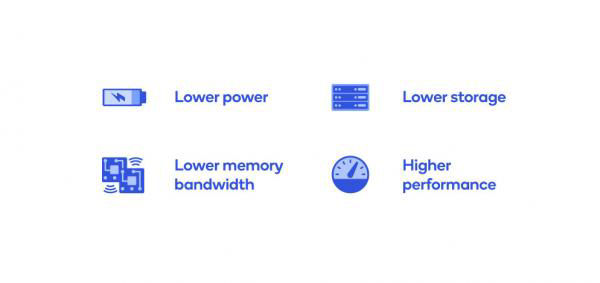
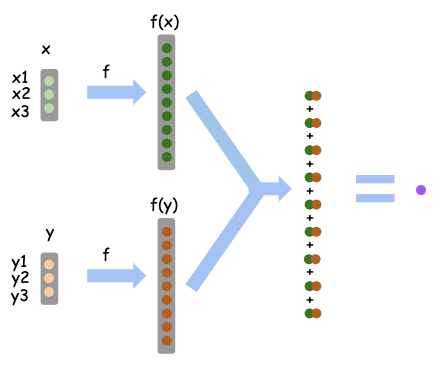
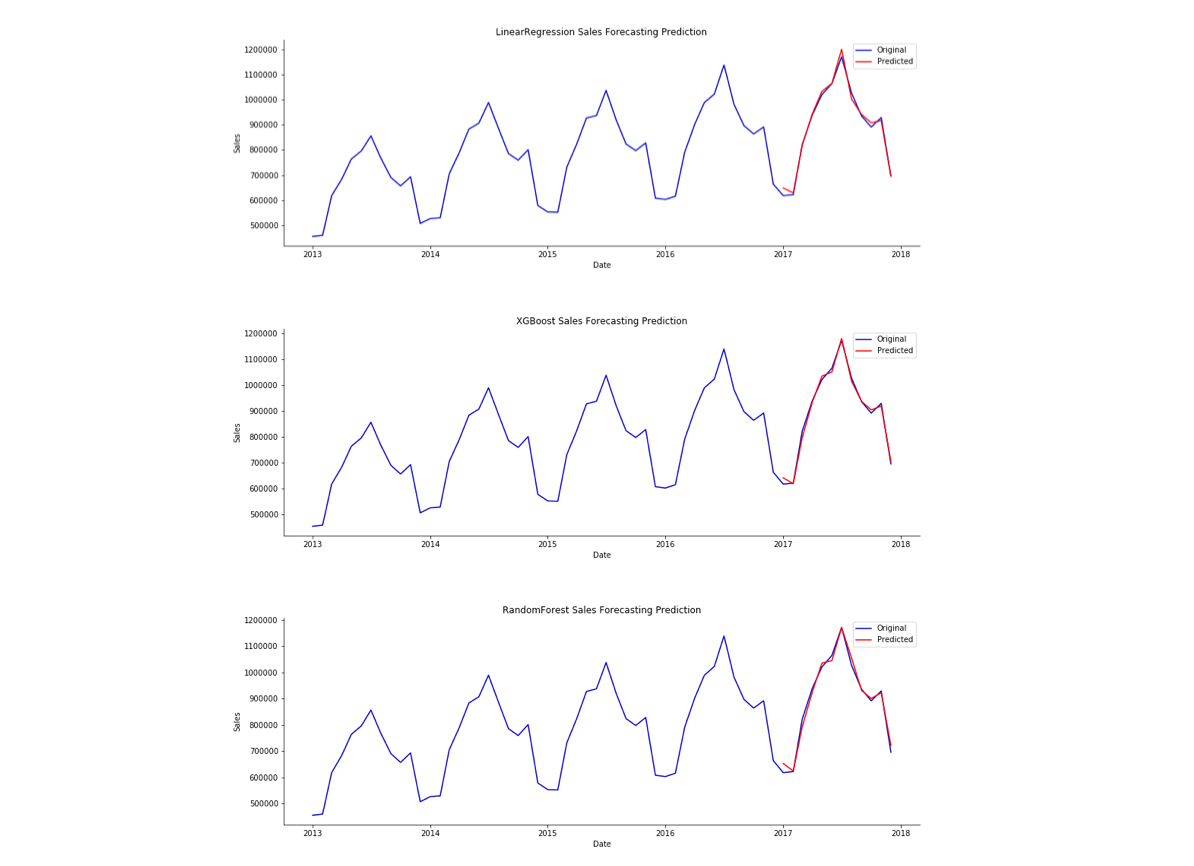
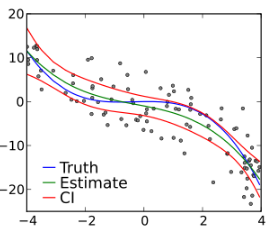
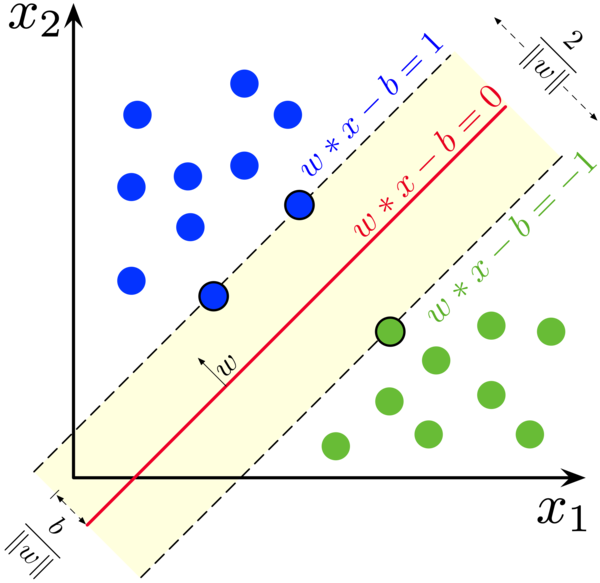
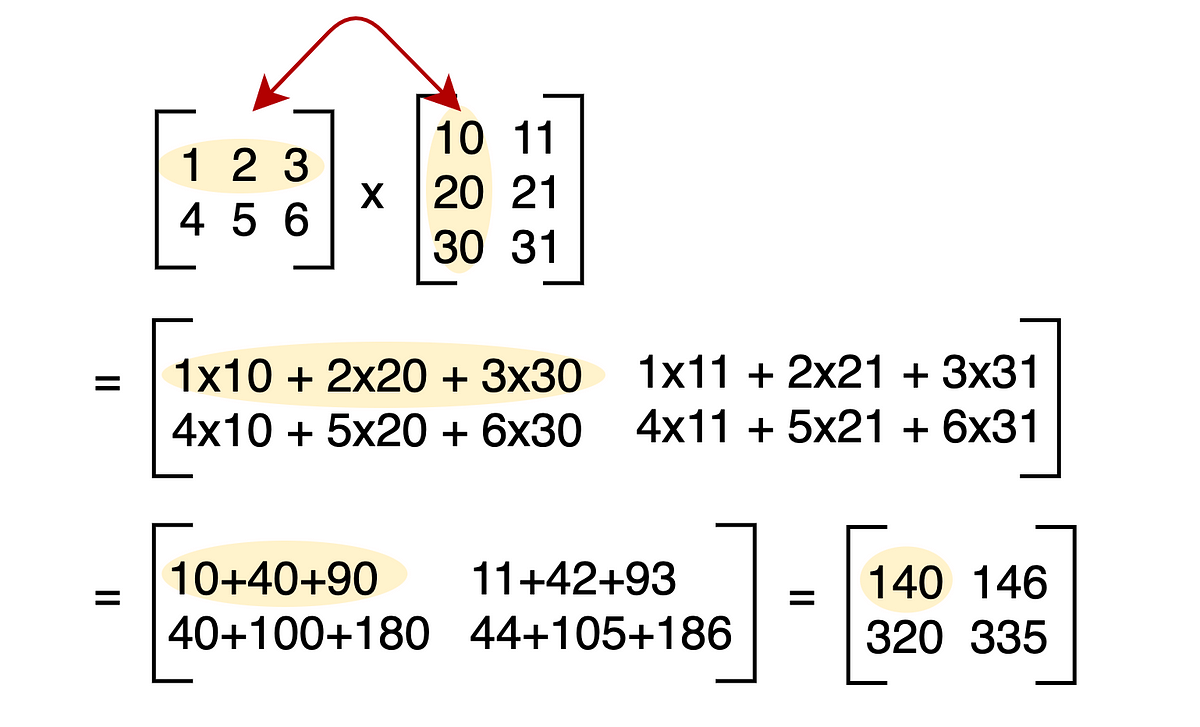
Discussions: Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments) Translations: Chinese (Simplified), French, Korean, Portuguese, Russian “There is in all things a pattern that is part of our universe. It has symmetry, elegance, and grace - those qualities you find always in that which the true artist captures. You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. We try to copy these patterns in our lives and our society, seeking the rhythms, the dances, the forms that comfort. Yet, it is possible to see peril in the finding of ultimate perfection. It is clear that the ultimate pattern contains it own fixity. In such perfection, all things move toward death.” ~ Dune (1965) I find the concept of embeddings to be one of the most fascinating ideas in machine learning. If you’ve ever used Siri, Google Assistant, Alexa, Google Translate, or even smartphone keyboard with next-word prediction, then chances are you’ve benefitted from this idea that has become central to Natural Language Processing models. There has been quite a development over the last couple of decades in using embeddings for neural models (Recent developments include contextualized word embeddings leading to cutting-edge models like BERT and GPT2). Word2vec is a method to efficiently create word embeddings and has been around since 2013. But in addition to its utility as a word-embedding method, some of its concepts have been shown to be effective in creating recommendation engines and making sense of sequential data even in commercial, non-language tasks. Companies like Airbnb, Alibaba, Spotify, and Anghami have all benefitted from carving out this brilliant piece of machinery from the world of NLP and using it in production to empower a new breed of recommendation engines. In this post, we’ll go over the concept of embedding, and the mechanics of generating embeddings with word2vec. But let’s start with an example to get familiar with using vectors to represent things. Did you know that a list of five numbers (a vector) can represent so much about your personality?
























































































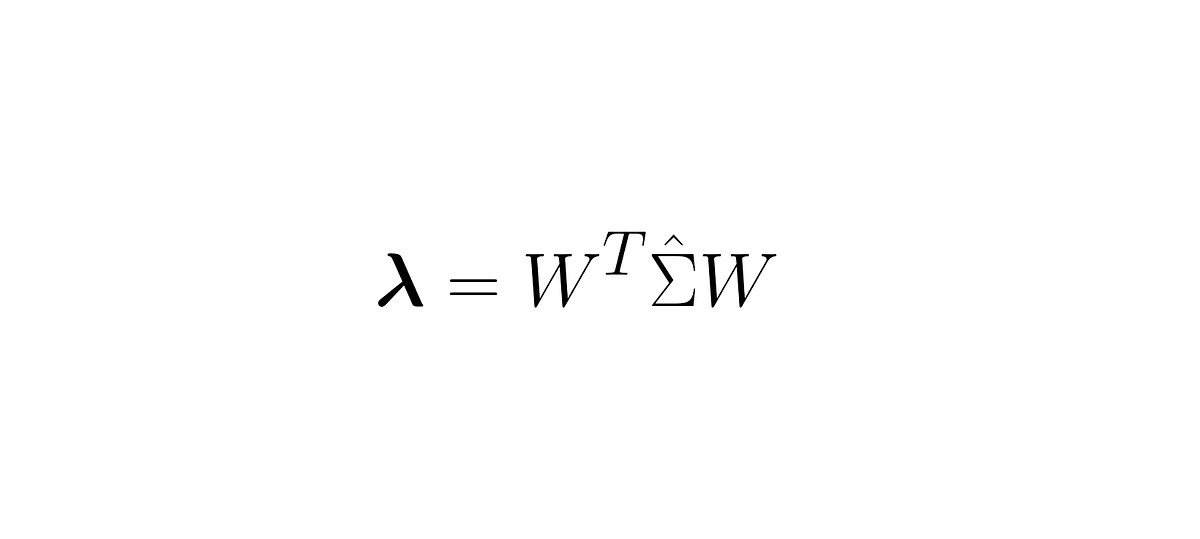
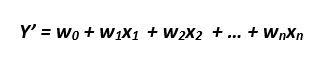







































:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F7399%2F1640135569_61c27b582ea87.png)
















































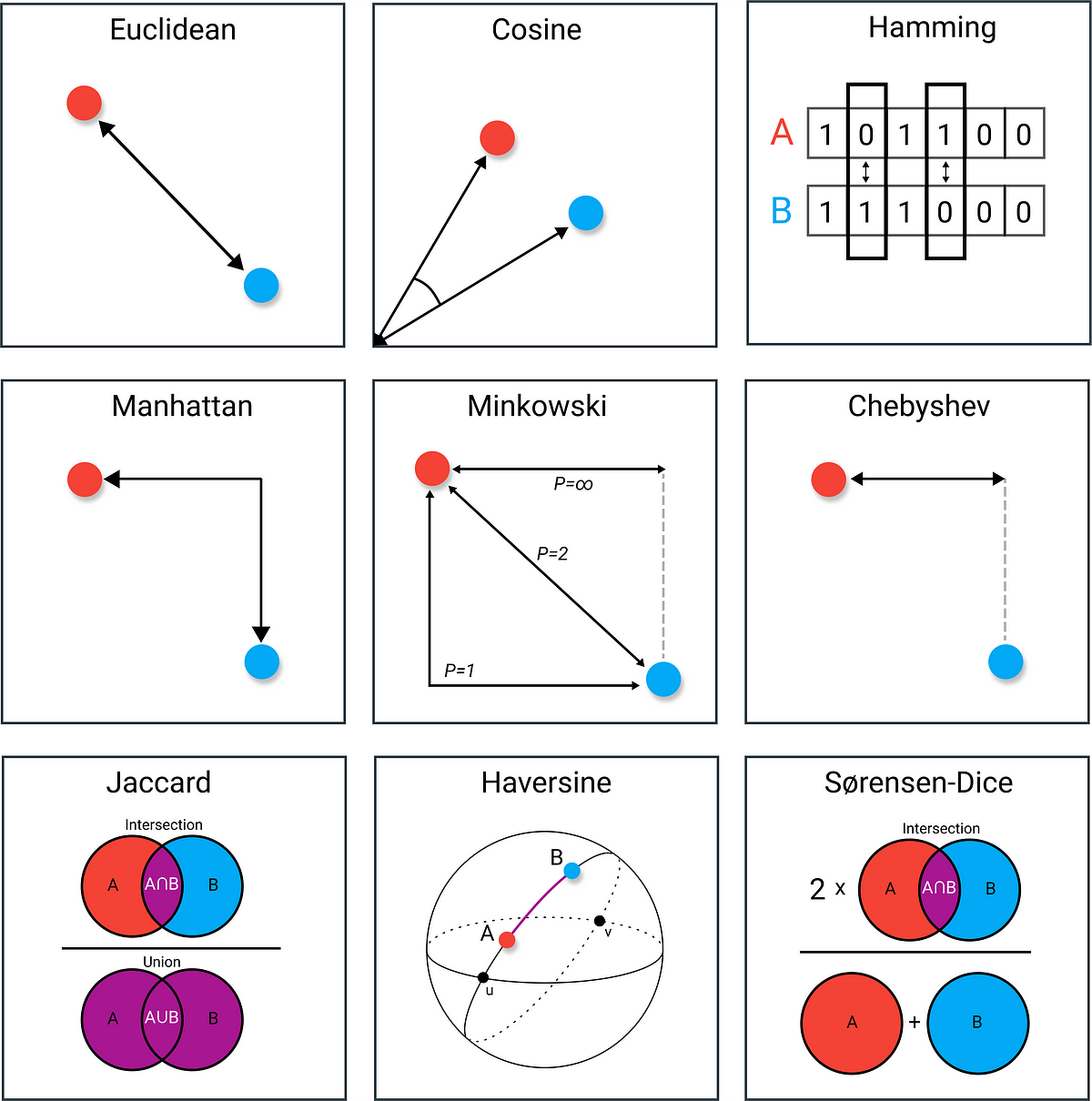


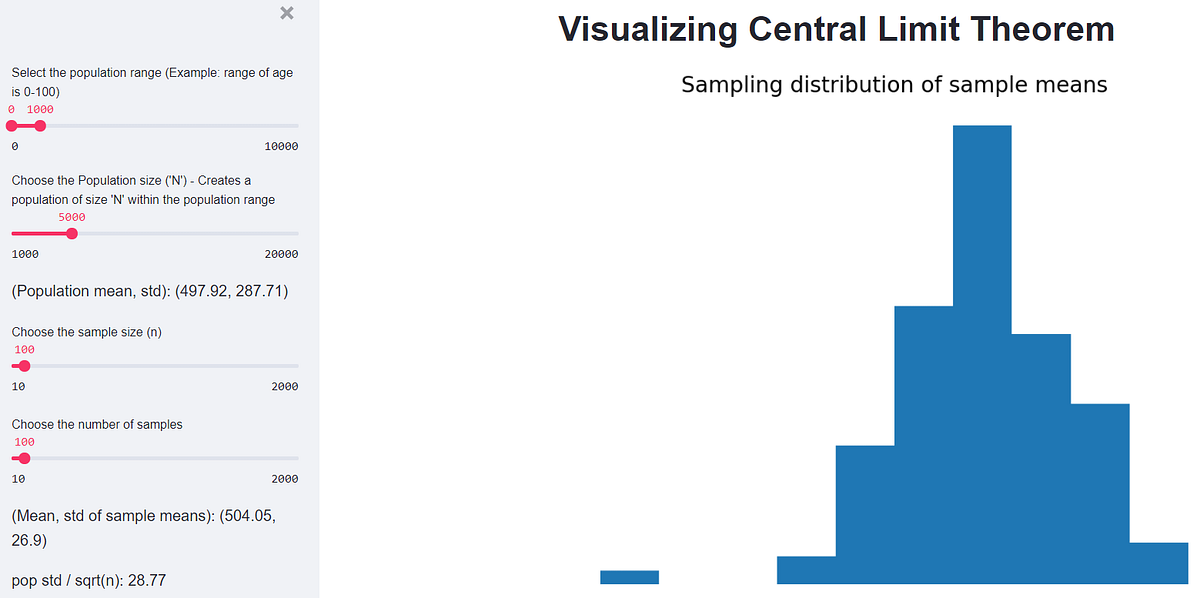


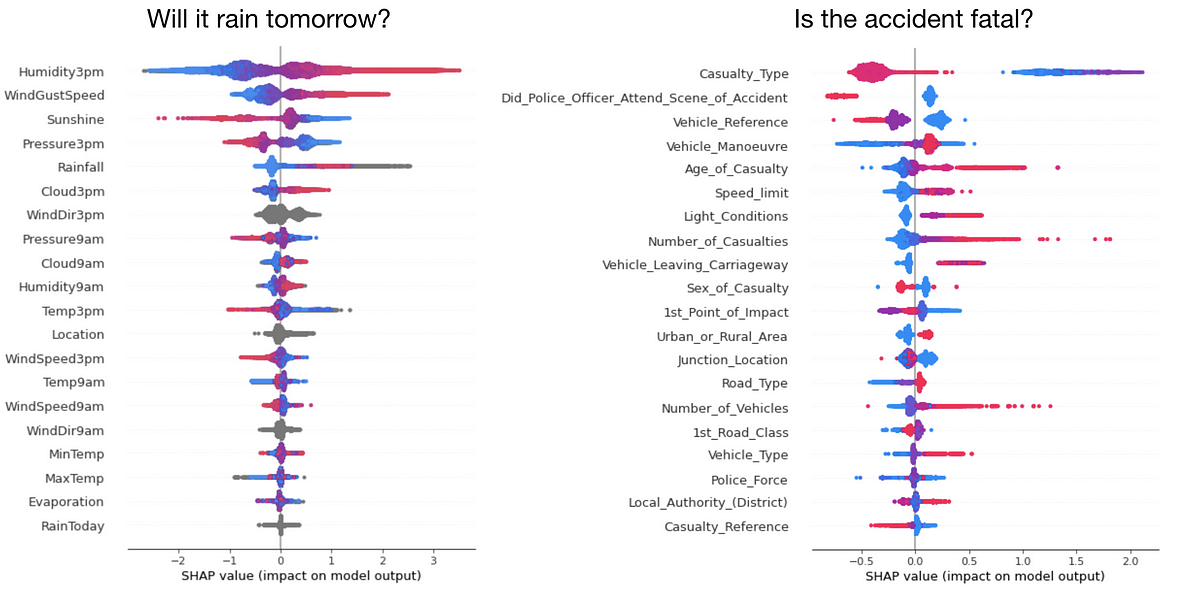
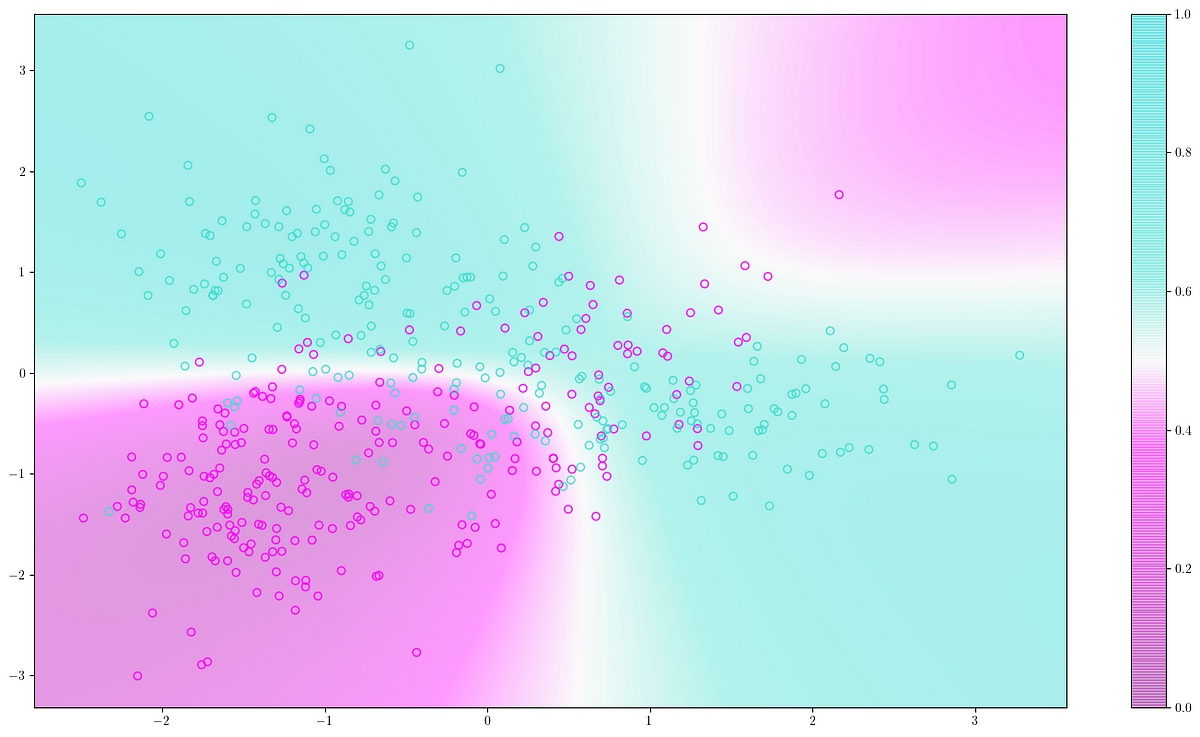






















:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F5796%2F1601055329_Graph_826_MHeule_5K.jpg)





















































































:extract_focal()/https%3A%2F%2Fs3.amazonaws.com%2Fpocket-syndicated-images%2Farticles%2F1644%2F1568747880_GettyImages-465645737.jpg)