A Code Implementation Guide to Advanced Human Pose Estimation using MediaPipe, OpenCV and Matplotlib
A Code Implementation Guide to Advanced Human Pose Estimation using MediaPipe, OpenCV and Matplotlib

Posted by Valentin Bazarevsky and Fan Zhang, Research Engineers, Google Research The ability to perceive the shape and motion of hands can be a v...
The surge in hand gesture recognition is not merely a novelty; it's a fundamental shift in how humans interact with machines.

Pixel-level dose correction improves the quality of masks written by multi-beam.

The GitHub repository includes up-to-date learning resources, research papers, guides, popular tools, tutorials, projects, and datasets.
Benchmarks & Tips for Big Data, Hadoop, AWS, Google Cloud, PostgreSQL, Spark, Python & More...

In this article, I'll take you through the essential image data preprocessing techniques you should know with implementation using Python.
— Dimitris Papailiopoulos (@DimitrisPapail)

Experiments with optical illusions have revealed surprising similarities between human and AI perception

Vision-language models (VLMs), capable of processing both images and text, have gained immense popularity due to their versatility in solving a wide range of tasks, from information retrieval in scanned documents to code generation from screenshots. However, the development of these powerful models has been hindered by a lack of understanding regarding the critical design choices that truly impact their performance. This knowledge gap makes it challenging for researchers to make meaningful progress in this field. To address this issue, a team of researchers from Hugging Face and Sorbonne Université conducted extensive experiments to unravel the factors that matter the

Author: Jacob Marks (Machine Learning Engineer at Voxel51) Run and Evaluate Monocular Depth...

**Monocular Depth Estimation** is the task of estimating the depth value (distance relative to the camera) of each pixel given a single (monocular) RGB image. This challenging task is a key prerequisite for determining scene understanding for applications such as 3D scene reconstruction, autonomous driving, and AR. State-of-the-art methods usually fall into one of two categories: designing a complex network that is powerful enough to directly regress the depth map, or splitting the input into bins or windows to reduce computational complexity. The most popular benchmarks are the KITTI and NYUv2 datasets. Models are typically evaluated using RMSE or absolute relative error. Source: [Defocus Deblurring Using Dual-Pixel Data ](https://arxiv.org/abs/2005.00305)

When you start using YOLO8 you loose a lot of time to find the basics codes to get the bounding...

Israeli intelligence sources reveal use of ‘Lavender’ system in Gaza war and claim permission given to kill civilians in pursuit of low-ranking militants
Learn the basics of this advanced computer vision task of object detection in an easy to understand multi-part beginner’s guide

Today I want to tell a little image processing algorithm story related to my post last week about the new bwconvhull function in the Image Processing Toolbox. The developer (Brendan) who worked on this function came to see me sometime last year to find out how the 'ConvexImage' measurement offered by regionprops

Developing large-scale datasets has been critical in computer vision and natural language processing. These datasets, rich in visual and textual information, are fundamental to developing algorithms capable of understanding and interpreting images. They serve as the backbone for enhancing machine learning models, particularly those tasked with deciphering the complex interplay between visual elements in images and their corresponding textual descriptions. A significant challenge in this field is the need for large-scale, accurately annotated datasets. These are essential for training models but are often not publicly accessible, limiting the scope of research and development. The ImageNet and OpenImages datasets, containing human-annotated
How to perform low quality images detection using Machine Learning and Deep Learning.

How can you get a computer to distinguish between different types of objects in an image? A step-by-step guide.
OpenAI's ChatGPT Vision is making waves in the world of artificial intelligence, but what exactly is it, and how can

Large-scale pre-trained Vision and language models have demonstrated remarkable performance in numerous applications, allowing for the replacement of a fixed set of supported classes with zero-shot open vocabulary reasoning over (nearly arbitrary) natural language queries. However, recent research has revealed a fundamental flaw in these models. For instance, their inability to comprehend Visual Language Concepts (VLC) that extend 'beyond nouns,' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or their difficulty with compositional reasoning, such as comprehending the significance of the word order in a sentence. Vision and language models, powerful machine-learning algorithms that learn

eBay's new generative AI tool, rolling out on iOS first, can write a product listing from a single photo -- or so the company claims.

MIT CSAIL researchers claim PhotoGuard can detect image irregularities invisible to the human eye through its AI's architectural prowess.

Numerous human-centric perception, comprehension, and creation tasks depend on whole-body pose estimation, including 3D whole-body mesh recovery, human-object interaction, and posture-conditioned human image and motion production. Furthermore, using user-friendly algorithms like OpenPose and MediaPipe, recording human postures for virtual content development and VR/AR has significantly increased in popularity. Although these tools are convenient, their performance still needs to improve, which limits their potential. Therefore, more developments in human pose assessment technologies are essential to realizing the promise of user-driven content production. Comparatively speaking, whole-body pose estimation presents more difficulties than human pose estimation with body-only key points detection due to

Real-time image processing is a resource-intensive task that often requires specialized hardware. With that in mind, let's explore processors that are designed specifically for photo and video applications.
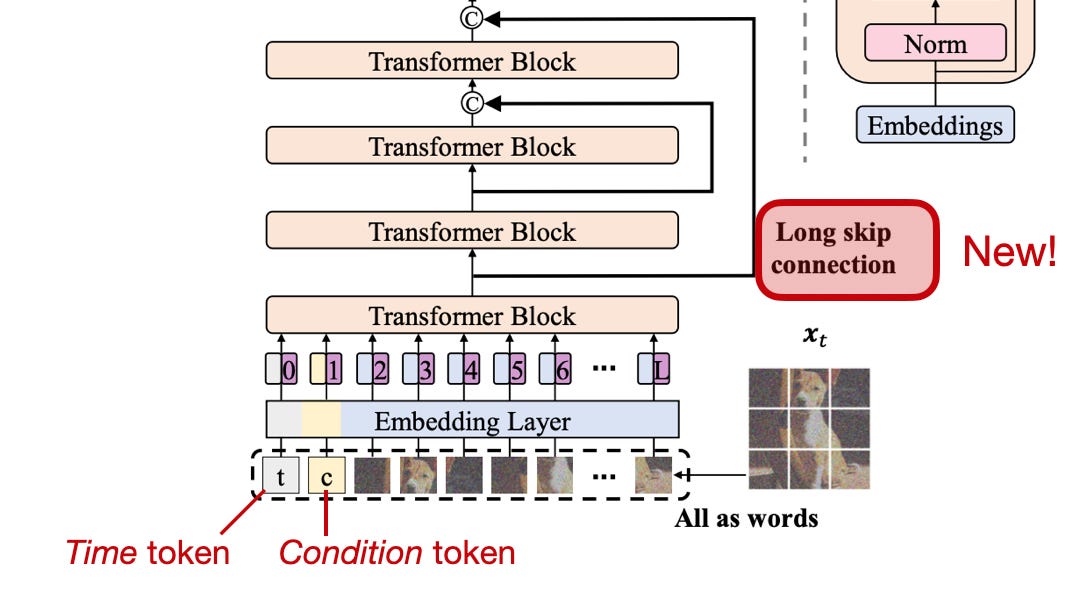
Large language model development (LLM) development is still happening at a rapid pace.
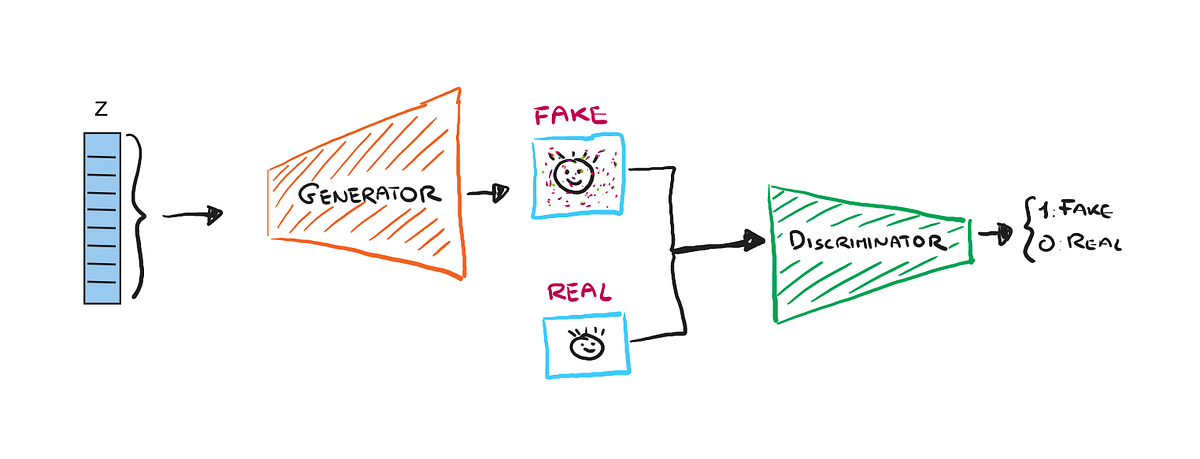
Learn how to implement GANs with PyTorch to generate synthetic images

How AR and VR are reshaping apparel e-commerce.

Learn how to build a surveillance system using WebRTC for low-latency and YOLO for object detection. This tutorial will guide you through the process of using computer vision and machine learning techniques to detect and track objects in real-time video streams. With this knowledge, you can create a surveillance system for security or other applications. However, there are challenges to consider when using cameras for object detection, including data privacy and security concerns, as well as technical limitations such as low image quality and lighting conditions. This article will teach you how to overcome some of these challenges and build a reliable surveillance system.
A team of researchers at MIT CSAIL, in collaboration with Cornell University and Microsoft, have developed STEGO, an algorithm able to identify images down to the individual pixel.
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch

Everything you need to know to use YOLOv7 in custom training scripts

An introduction to the field, its applications, and current issues

A review of popular techniques and remaining challenges
Overview of how object detection works, and where to get started
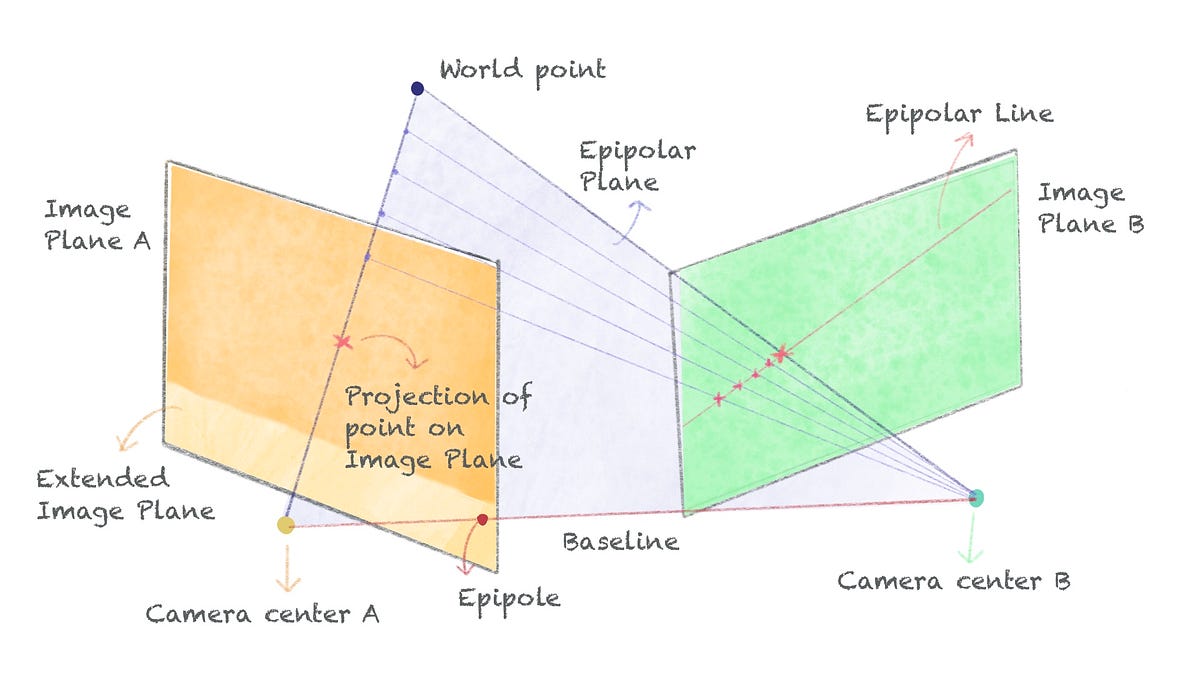
Everything you need to know about Stereo Geometry

How the Dead Internet Theory is fast becoming reality thanks to zero, marginal-cost content generated at infinite scale

In this article, we will specifically take a look at motion detection using a webcam of a laptop or computer and will create a code script to work on our computer and see its real-time example.
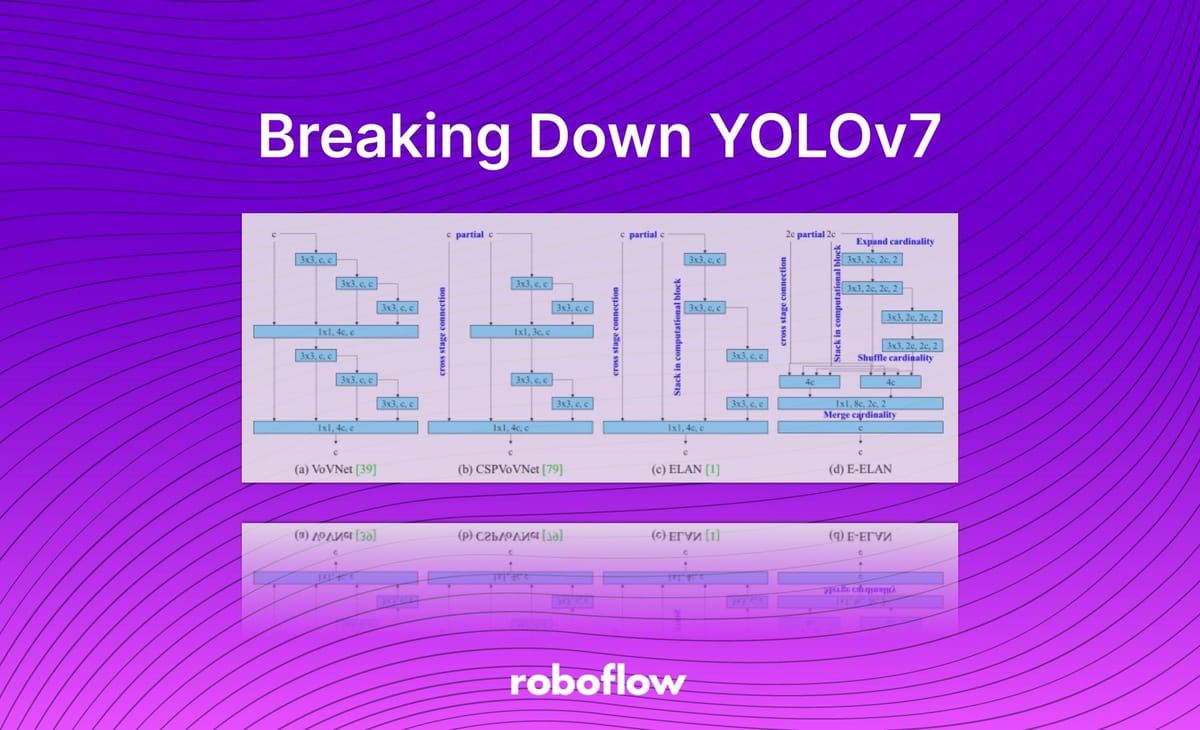
In this guide, we discuss what YOLOv7 is, how the model works, and the novel model architecture changes in YOLOv7.
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30...

eview and comparison of the next generation object detection

It takes a human being around 0.1 to 0.4 seconds to blink. In even less time, an AI-based inverse rendering process developed by NVIDIA can generate a 3D scene from 2D photos.

New research shows that detecting digital fakes generated by machine learning might be a job best done with humans still in the loop.
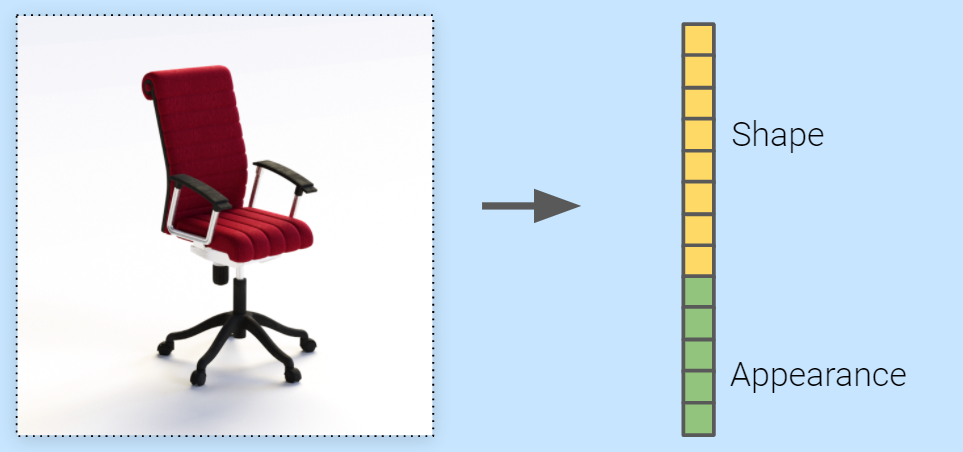
How we used NeRF to embed our entire 3D object catalogue to a shared latent space, and what it means for the future of graphics
Best-practices to follow when building datasets from large pools of image and video data and tools that make it straightforward.

A growing number of tools now let you stop facial recognition systems from training on your personal photos
Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets...

Revealing whats behind the state-of-the art algorithm HRNet

In this post, you will learn some cool command line tricks which can help you to speed up your day-to-day R&D.

A guide on object detection algorithms and libraries that covers use cases, technical details, and offers a look into modern applications.
The ten essential computer vision terminologies that everyone should learn to become more proficient at computer vision with sample codes

According to the paper, their findings imply that facial recognition systems are “extremely vulnerable.”

For all their triumphs, AI systems can’t seem to generalize the concepts of “same” and “different.” Without that, researchers worry, the quest to create truly intelligent machines may be hopeless.
Data Augmentation is one of the most important topics in Deep Computer Vision. When you train your neural network, you should do data augmentation like… ALWAYS. Otherwise, you are not using your…

On the 91st Martian day, or sol, of NASA’s Mars 2020 Perseverance rover mission, the Ingenuity Mars Helicopter performed its sixth flight. The flight was designed to expand the flight envelope and demonstrate aerial-imaging capabilities by taking stereo images of a region of interest to the west. Ingenuity was commanded to climb to an altitude of 33 feet (10 meters) before translating 492 feet (150 meters) to the southwest at a ground speed of 9 mph (4 meters per second). At that point, it was to translate 49 feet (15 meters) to the south while taking images toward the west, then fly another 164 feet (50 meters) northeast and land.
Linear algebra is foundational in data science and machine learning. Beginners starting out along their learning journey in data science--as well as established practitioners--must develop a strong familiarity with the essential concepts in linear algebra.

Computer vision is the field of computer science that focuses on replicating parts of the complexity...
:pencil2: Web-based image segmentation tool for object detection, localization, and keypoints - jsbroks/coco-annotator
Detailed tutorial on where to find a dataset, how to preprocess data, what model architecture and loss to use, and, finally, how to…
Data Augmentation is one of the most important yet underrated aspects of a machine learning system …

In 1970 robotics professor Masahiro Mori observed, "Bbukimi no tani genshō," which was later translated into "uncanny valley". This refers to an observed phenomenon (first in robots, but also applies to digital recreations) that the more human-like the robot the greater the emotional affinity of people. However, as imitation approaches complete imitation it takes a

Computer scientists from the University at Buffalo used the method to successfully detect Deepfakes taken from This Person Does Not Exist.

Deep Nostalgia AI brings your photos to life just like in the Harry Potter movies.

I have aggregated some of the SotA image generative models released recently, with short summaries, visualizations and comments. The overall development is summarized, and the future trends are spe…

Building an app for blood cell count detection.

How to use the Gaussian Distribution for Image Segmentation

**Object tracking** is the task of taking an initial set of object detections, creating a unique ID for each of the initial detections, and then tracking each of the objects as they move around frames in a video, maintaining the ID assignment. State-of-the-art methods involve fusing data from RGB and event-based cameras to produce more reliable object tracking. CNN-based models using only RGB images as input are also effective. The most popular benchmark is OTB. There are several evaluation metrics specific to object tracking, including HOTA, MOTA, IDF1, and Track-mAP. ( Image credit: [Towards-Realtime-MOT ](https://github.com/Zhongdao/Towards-Realtime-MOT) )

Emotional development is one of the largest and most productive areas of psychological research. For decades, researchers have been fascinated by how humans respond to, detect, and interpret emotional facial expressions. Much of the research in this area ...