
By Matteo Wong / The Atlantic. View the full context on Techmeme.
By Matteo Wong / The Atlantic. View the full context on Techmeme.
METEOR Score is a metric used to evaluate the quality of machine translation based on precision, recall, word alignment, and linguistic flexibility.
Triplet loss is a machine learning function that minimizes distances between similar data points while maximizing distances between dissimilar ones.

The key challenge lies in finding the right balance: How cautious should our model be when making classifications?

The advent of LLMs has propelled advancements in AI for decades. One such advanced application of LLMs is Agents, which replicate human reasoning remarkably. An agent is a system that can perform complicated tasks by following a reasoning process similar to humans: think (solution to the problem), collect (context from past information), analyze(the situations and data), and adapt (based on the style and feedback). Agents encourage the system through dynamic and intelligent activities, including planning, data analysis, data retrieval, and utilizing the model's past experiences. A typical agent has four components: Brain: An LLM with advanced processing capabilities, such as

Continuous Improvement sounds simple, even obvious. And yet there's a profound secret at its heart that doesn't seem to get talked about.

In the world of LLMs, there is a phenomenon known as "hallucinations." These hallucinations are...
Goodhart's law is an adage often stated as, "When a measure becomes a target, it ceases to be a good measure".[1] It is named after British economist Charles Goodhart, who is credited with expressing the core idea of the adage in a 1975 article on monetary policy in the United Kingdom:[2]
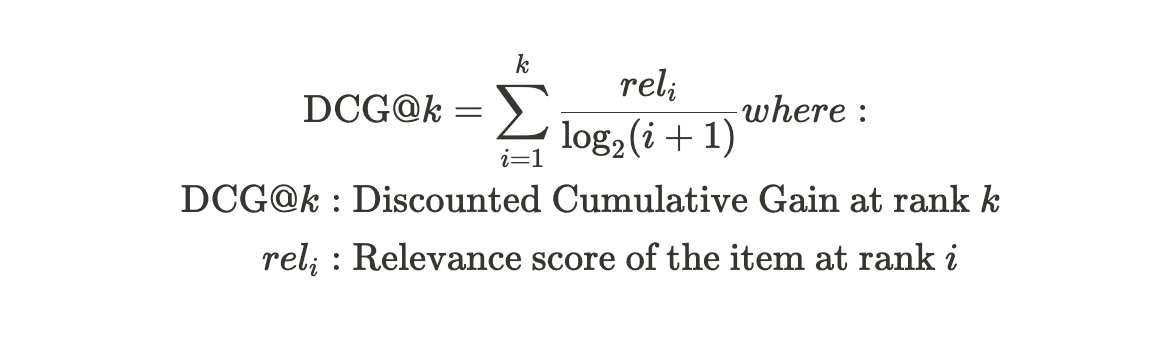
Understanding the purpose and functionality of common metrics in ML packages
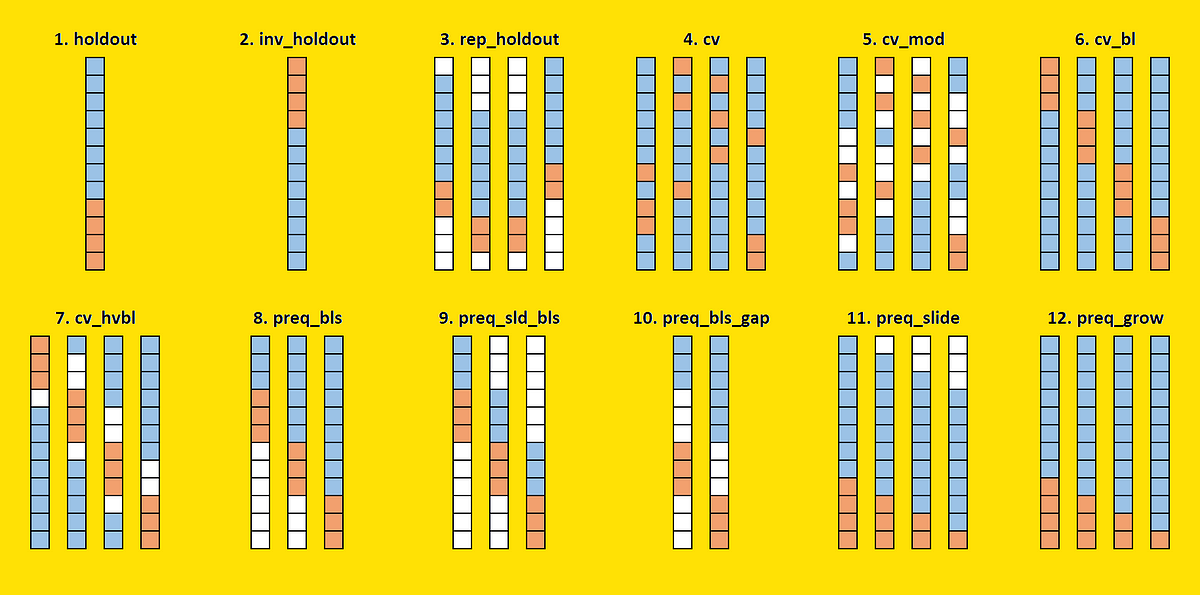
How to find the best performance estimation approach for time-series forecasts among 12 strategies proposed in the literature. With Python…

The Jaccard index, also known as the Jaccard similarity coefficient, is a statistic used for gauging the similarity and diversity of sample sets. It is defined in general taking the ratio of two sizes, the intersection size divided by the union size, also called intersection over union (IoU).

Photo by Carl Heyerdahl on Unsplash Productivity in software development has always been tricky to...
How to compress and fit a humongous set of vectors in memory for similarity search with asymmetric distance computation (ADC)

I recently rewatched "The Wire". The show's central theme is about counter-productive metrics and their corrupting influence on institutions. I've noticed hints of this pattern in software engineering, too

A few weeks ago, we shared some key startup metrics (16 of them, to be exact) that help investors gauge the health of a business when investing in it. But to repeat ourselves for a moment: Good metrics aren’t just about raising money from VCs … they’re about running the business in a way where...

In working with a number of SaaS portfolio companies, I have found that there are two causes of churn that occur more frequently than any others. They are: Failure to successfully onboard the customer Loss of the champion who drove the purchase Looking at these in order: Failure to successfully onboard It’s easy to understand […]

Two proven sales experts on how to build a process and team from the ground up to consistently boost revenue month over month.
In "Email Marketing Metrics, Part 1: The Basics," my article last month, I addressed the primary measurements for email marketing: delivery rate, open

We have the privilege of meeting with thousands of entrepreneurs every year, and in the course of those discussions are presented with all kinds of numbers, measures, and metrics that illustrate the promise and health of a particular company. Sometimes, however, the metrics may not be the best gauge of what’s actually happening in the...

Startup Metrics, a love story. All slides of an 6h Lean Analytics workshop. - Download as a PDF or view online for free
Which metric should be used to evaluate the clustering results if the ground truth labels are not available? In this post, I’m introducing…
Manual Calculation From a Confusion Matrix and the Syntax of sklearn Library
