pdfs

Countless digital documents hold valuable info, and the AI industry is attempting to set it free.

Large language models work particularly well with raw text. Companies that want to create their own AI workflow know that it has become extremely

You cannot share Jupter Notebook's ipynb files with everyone. However, if you convert it to PDF, sharing becomes easier. Here's how to do it.

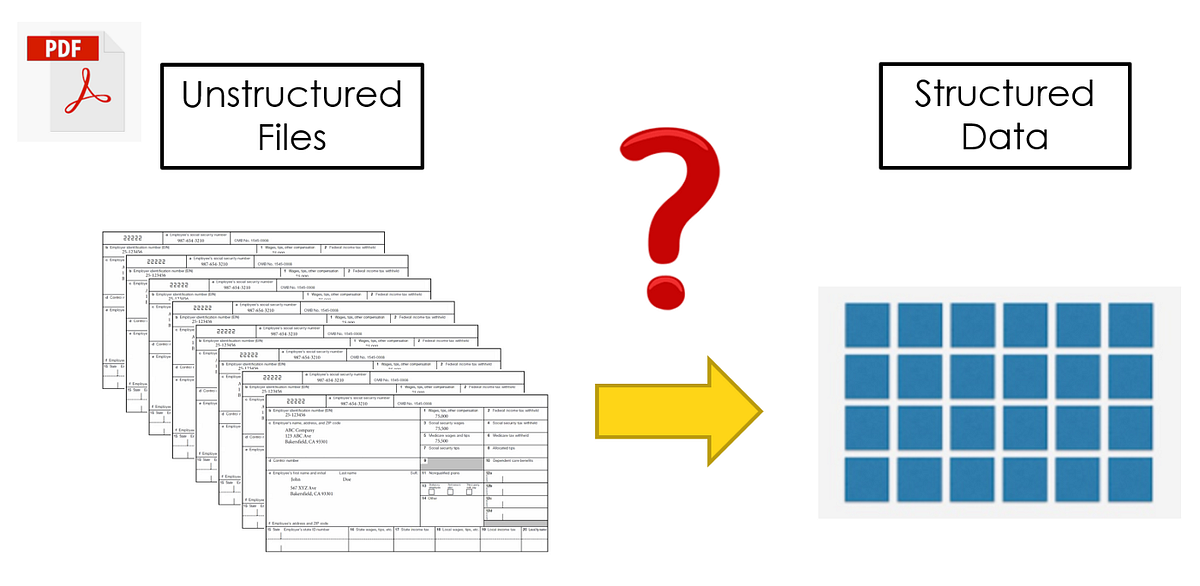
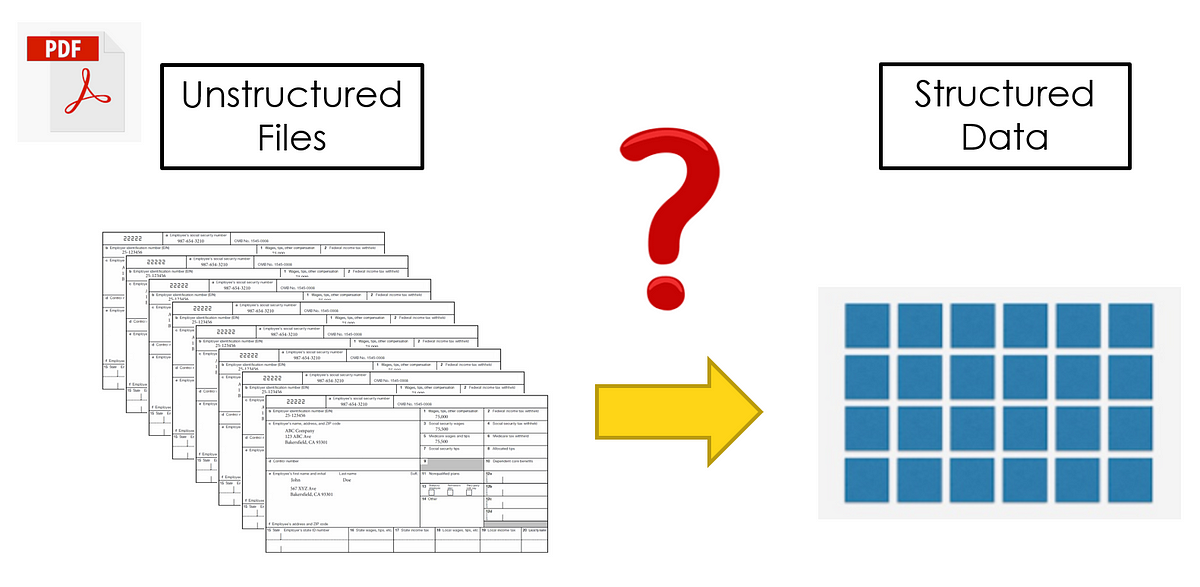
Extracting structured data from unstructured sources like PDFs, webpages, and e-books is a significant challenge. Unstructured data is common in many fields, and manually extracting relevant details can be time-consuming, prone to errors, and inefficient, especially when dealing with large amounts of data. As unstructured data continues to grow exponentially, traditional manual extraction methods have become impractical and error-prone. The complexity of unstructured data in various industries that rely on structured data for analysis, research, and content creation. Current methods for extracting data from unstructured sources, including regular expressions and rule-based systems, are often limited by their inability to maintain
rga: ripgrep, but also search in PDFs, E-Books, Office documents, zip, tar.gz, etc. - phiresky/ripgrep-all
The Artifex blog covers the latest news and updates regarding Ghostscript, MuPDF, and SmartOffice. Subjects cover PDF and Postscript, open source, office productivity, new releases, and upcoming events.
Convert PDF to markdown quickly with high accuracy - VikParuchuri/marker

In this blog, we'll explore a selection of top-notch plugins designed to simplify your invoicing and document creation processes. Whether you're running a


The need to convert PDF documents into more manageable and editable formats like markdowns is increasingly vital, especially for those dealing with academic and scientific materials. These PDFs often contain complex elements such as multi-language text, tables, code blocks, and mathematical equations. The primary challenge in converting these documents lies in accurately maintaining the original layout, formatting, and content, which standard text converters often need help to handle. There are already some solutions available aimed at extracting text from PDFs. Optical Character Recognition (OCR) tools are commonly used to interpret and digitize the text contained within these files. However, while

There are still some limitations when summarizing very large documents. Here are some ways to mitigate these effects.
A command-line application and Perl library for reading and writing EXIF, GPS, IPTC, XMP, makernotes and other meta information in image, audio and video files. For Windows, MacOS, and Unix systems.

Extracting text from a PDF file using GNU less or Python's pypdf. Why its not entirely clear just what a text extractor should do.
Document management — Electronic document file format for long-term preservation — Part 1: Use of PDF 1.4 (PDF/A-1)

The story of the PDF, the portable document format that’s become one of the internet’s defining information formats. It’ll be with us after we’re long gone.
LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
Use these text extraction techniques to get quality data for your LLM models

Using ChatGPT & OpenAI's GPT API, this code tutorial teaches how to chat with PDFs, automate PDF tasks, and build PDF chatbots.
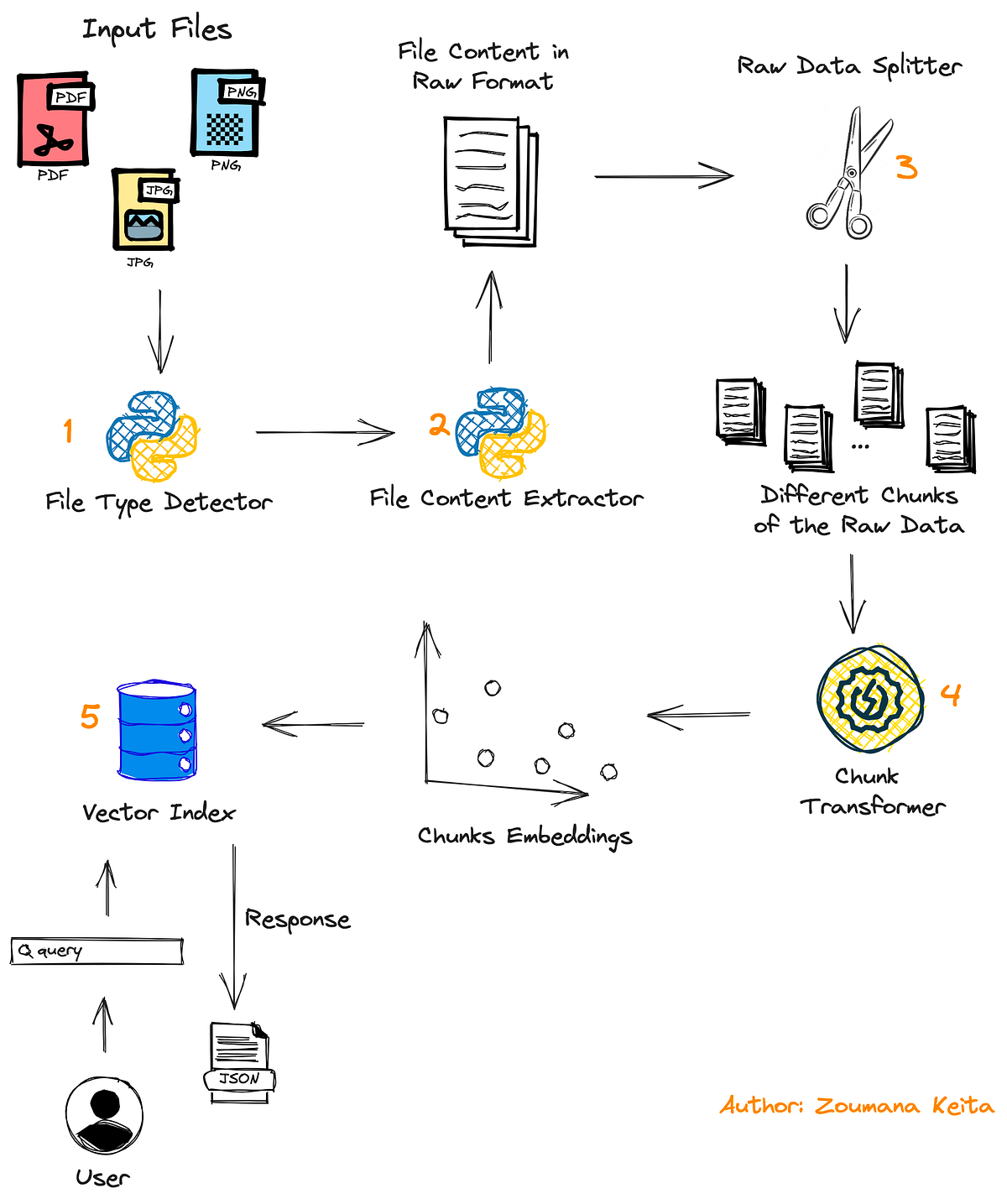
Complete guide to building an AI assistant that can answer questions about any file

#langchain #chatgpt #gpt4 #artificialintelligence #automation #python #notion #productivity #datascience #pdf #machinelearning In this tutorial, learn how to easily extract information from a PDF document using LangChain and ChatGPT. I'll walk you through installing dependencies, loading and processing a PDF file, creating embeddings, and querying the PDF with natural language questions. 00:00 - Introduction 00:21 - Downloading a sample PDF 00:49 - Importing required modules 01:21 - Setting up the PDF path and loading the PDF 01:38 - Printing the first page of the PDF 01:53 - Creating embeddings and setting up the Vector database 02:24 - Creating a chat database chain 02:49 - Querying the PDF with a question 03:27 - Understanding the query results 04:00 - Conclusion Remember to like and subscribe for more tutorials on learning, research and AI! - Source code: https://github.com/EnkrateiaLucca/talk_pdf - Link to the medium article: https://medium.com/p/e723337f26a6 - Subscribe!: https://www.youtube.com/channel/UCu8WF59Scx9f3H1N_FgZUwQ - Join Medium: https://lucas-soares.medium.com/membership - Tiktok: https://www.tiktok.com/@enkrateialucca?lang=en - Twitter: https://twitter.com/LucasEnkrateia - LinkedIn: https://www.linkedin.com/in/lucas-soares-969044167/ Music from [www.epidemicsound.com](http://www.epidemicsound.com/)

Chat with your long PDF docs: load_qa_chain, RetrievalQA, VectorstoreIndexCreator, ConversationalRetrievalChain

Even if you use the Linux command line moderately, you must have come across the grep command. Grep is used to search for a pattern in a text file. It can do crazy powerful things, like search for new lines, search for lines where there are no uppercase characters, search
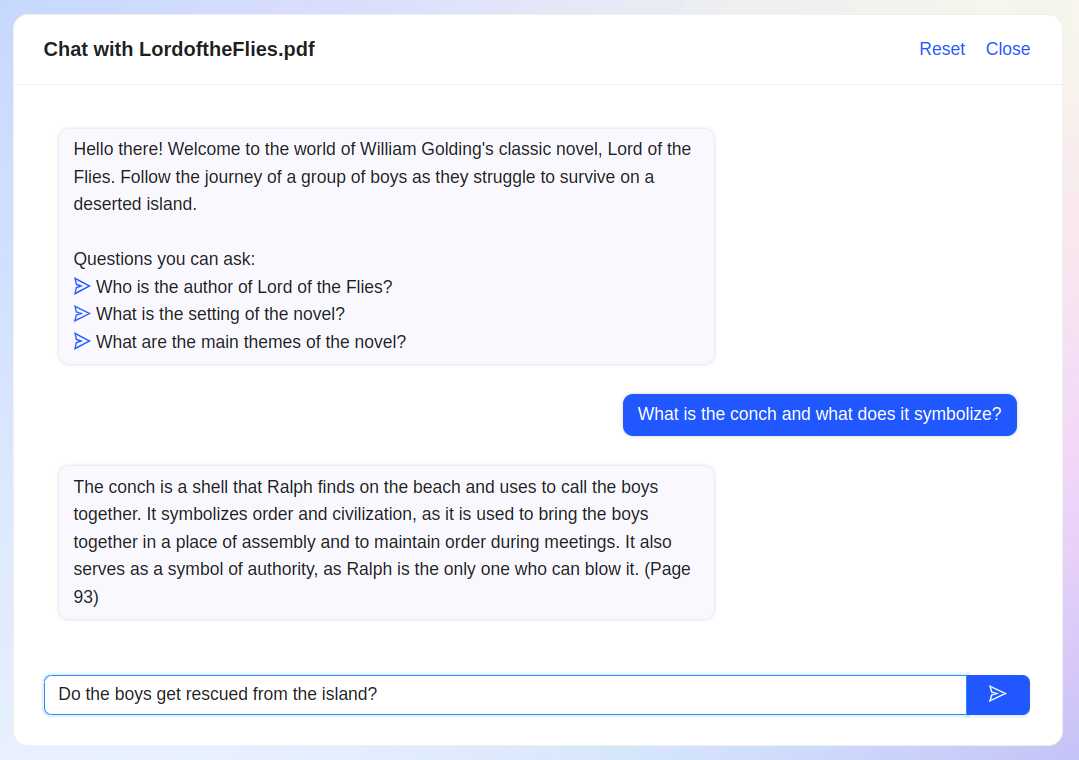
ChatPDF is the fast and easy way to chat with any PDF, free and without sign-in. Talk to books, research papers, manuals, essays, legal contracts, whatever you have! The intelligence revolution is here, ChatGPT was just the beginning!
Automate PDF generation with the FPDF library as part of your data analysis
You want to make friends with tabula-py and Pandas

This is a cross-post from my blog Arcadian.Cloud, go there to see the original post. I have some...
🐍🔥 — Mike Driscoll (@driscollis)

For bureaucratic reasons, a colleague of mine had to print, sign, scan and send by email a high number of pages. To save trees, ink, time, and to...

This article is a comprehensive overview of different open-source tools to extract text and tabular data from PDF Files

In this demo application we will demonstrate that how you can upload documents using active records and convert preview of PDF pages as images. We have also used action cable to display progress of PDF pages to image conversion inside bootstrap modal. Though this is a simple and basic example but you can learn different concepts here from the code base. Here you can find the repository for this demo application: https://github.com/RaviSys/pdf-preview-demo Hope you enjoy learning this.

This top-rated PDF tool is an Apple editors' choice winner and will revolutionize the way you work & collaborate with documents.

Unlock the power of PDF.to – Your all-in-one converter for transforming PDFs into Word, JPEG, PNG, OCR, DOC, and more. Seamlessly compress PDFs, convert to PDF, and harness the potential with our versatile API. Explore the possibilities with PDF.to!
Leveraging automation to create dazzling PDF documents effortlessly

How to extract and convert tables from PDFs into Pandas Dataframe using Camelot

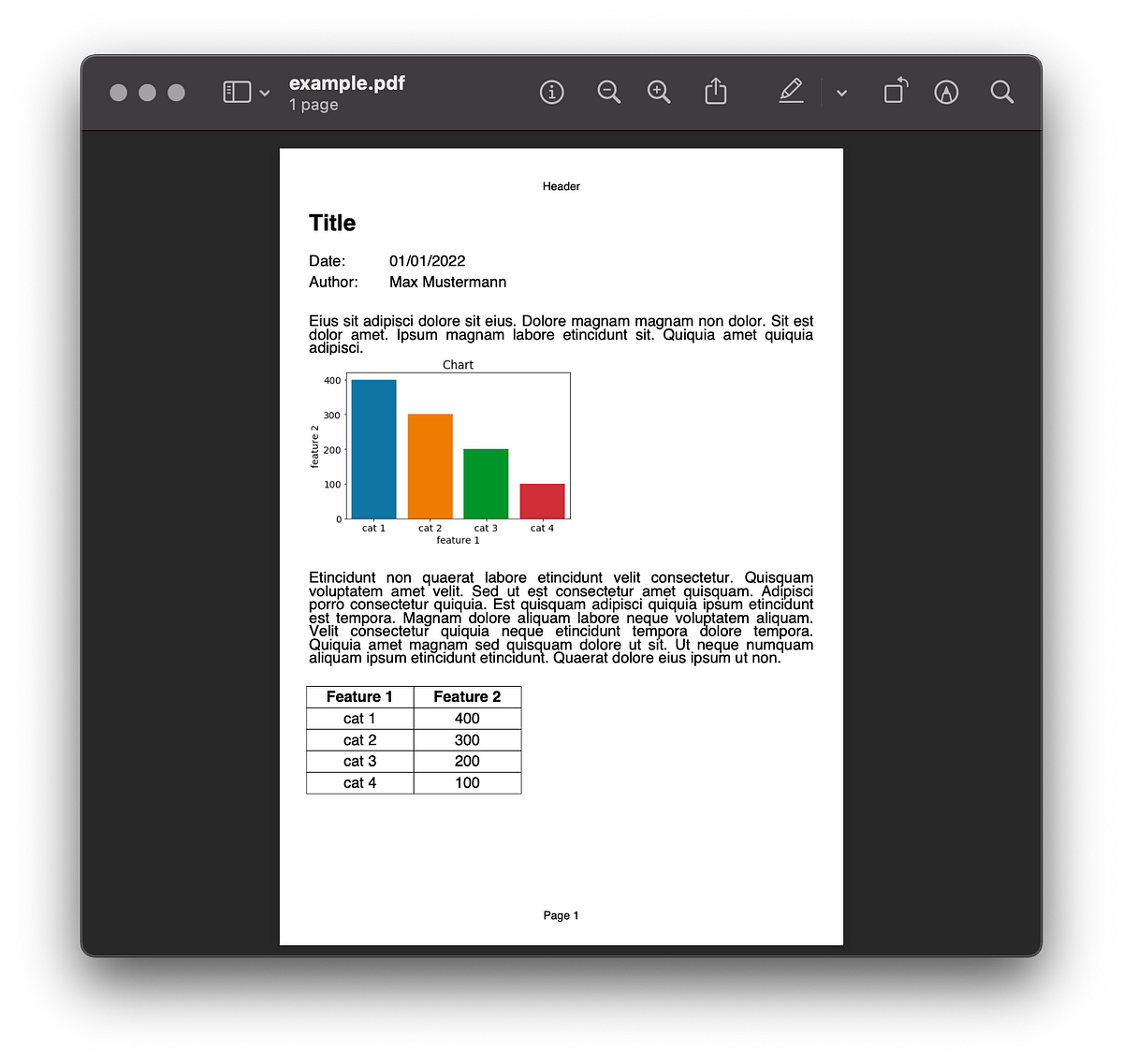
Create PDF reports with beautiful visualizations in 10 minutes or less.

Explains how to convert pdf to image or vice versa on Linux command line. Further describes how to add a border using Imagemagick.

PDFBEAR makes converting and sharing PDFs easy.
A quick guide for extracting the tables from PDF files in Python using Camelot library