pytorch


We’re excited to reveal our brand new PyTorch Landscape. The PyTorch Landscape helps researchers, developers, and organizations easily locate useful, curated, community-built tools that augment the PyTorch core framework.

PyTorch has emerged as a top choice for researchers and developers due to its relative ease of use and continuing improvement in performance.

In this article, we dive into how PyTorch’s Autograd engine performs automatic differentiation.
The Triton open-source programming language and compiler offers a high-level, python-based approach to create efficient GPU code. In this blog, we highlight the underlying details of how a triton program is compiled and the intermediate representations. For an introduction to Triton, we refer readers to this blog.

The PyTorch community has continuously been at the forefront of advancing machine learning frameworks to meet the growing needs of researchers, data scientists, and AI engineers worldwide. With the latest PyTorch 2.5 release, the team aims to address several challenges faced by the ML community, focusing primarily on improving computational efficiency, reducing start up times, and enhancing performance scalability for newer hardware. In particular, the release targets bottlenecks experienced in transformer models and LLMs (Large Language Models), the ongoing need for GPU optimizations, and the efficiency of training and inference for both research and production settings. These updates help PyTorch
Attention, as a core layer of the ubiquitous Transformer architecture, is a bottleneck for large language models and long-context applications. FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is now used by most libraries to accelerate Transformer training and inference. This has contributed to a massive increase in LLM context length in the last two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), or even 1M (Llama 3). However, despite its success, FlashAttention has yet to take advantage of new capabilities in modern hardware, with FlashAttention-2 achieving only 35% utilization of theoretical max FLOPs on the H100 GPU. In this blogpost, we describe three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for FP8 low-precision.

These six tips will help you significantly accelerate your model training.

The full guide to creating custom datasets and dataloaders for different models in PyTorch


When discussing GenAI, the term "GPU" almost always enters the conversation and the topic often moves toward performance and access. Interestingly, the word "GPU" is assumed to mean "Nvidia" products. (As an aside, the popular Nvidia hardware used in GenAI are not technically...
Use 3D to visualize matrix multiplication expressions, attention heads with real weights, and more.
How to Identify and Analyze Performance Issues in the Backward Pass with PyTorch Profiler, PyTorch Hooks, and TensorBoard

Theory and PyTorch Implementation

This article provides a series of techniques that can lower memory consumption in PyTorch (when training vision transformers and LLMs) by approximately 20x without sacrificing modeling performance and prediction accuracy.
We are excited to announce the release of PyTorch® 2.0 which we highlighted during the PyTorch Conference on 12/2/22! PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood with faster performance and support for Dynamic Shapes and Distributed.
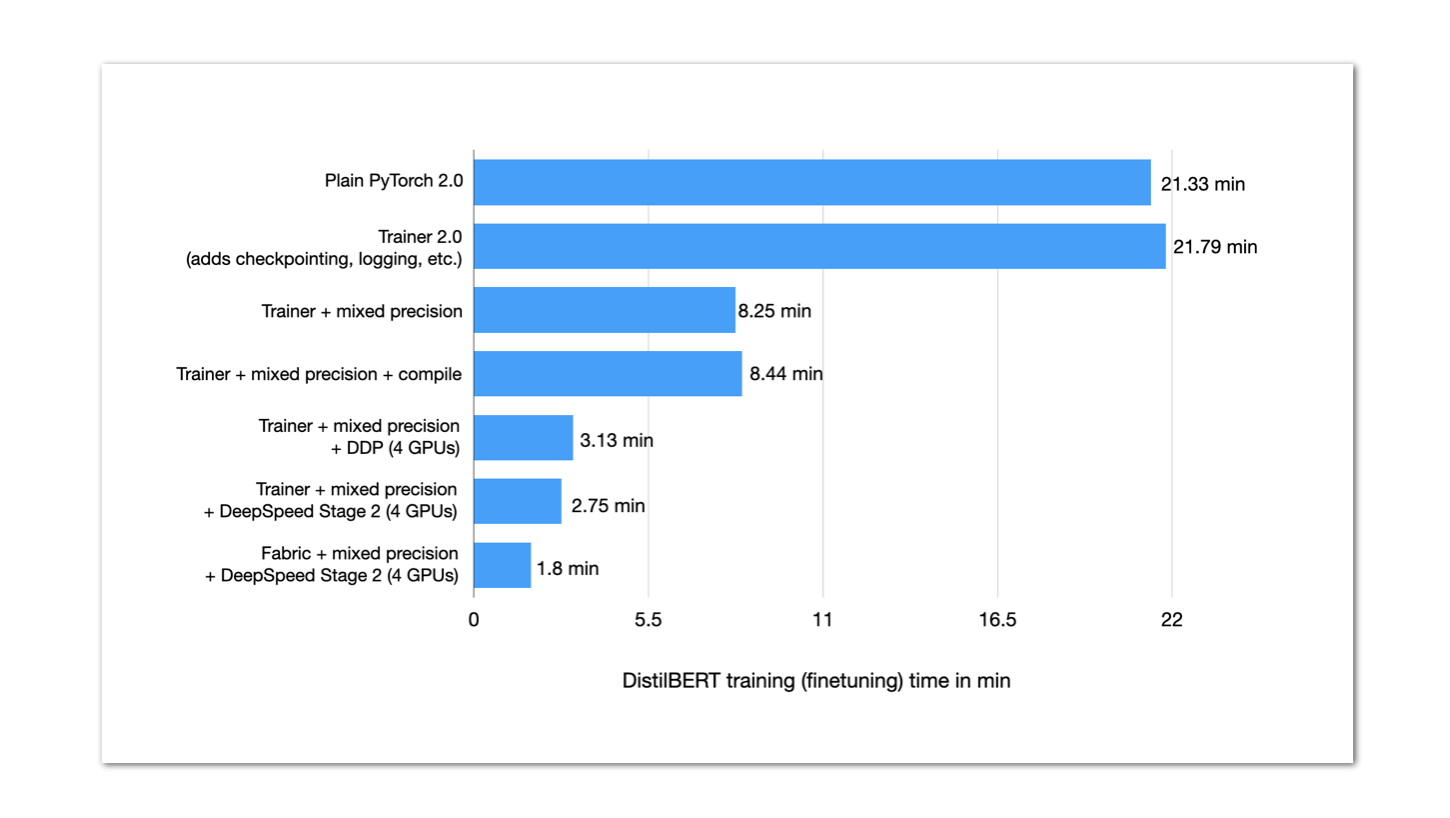
This blog post outlines techniques for improving the training performance of your PyTorch model without compromising its accuracy. To do so, we will wrap a P...
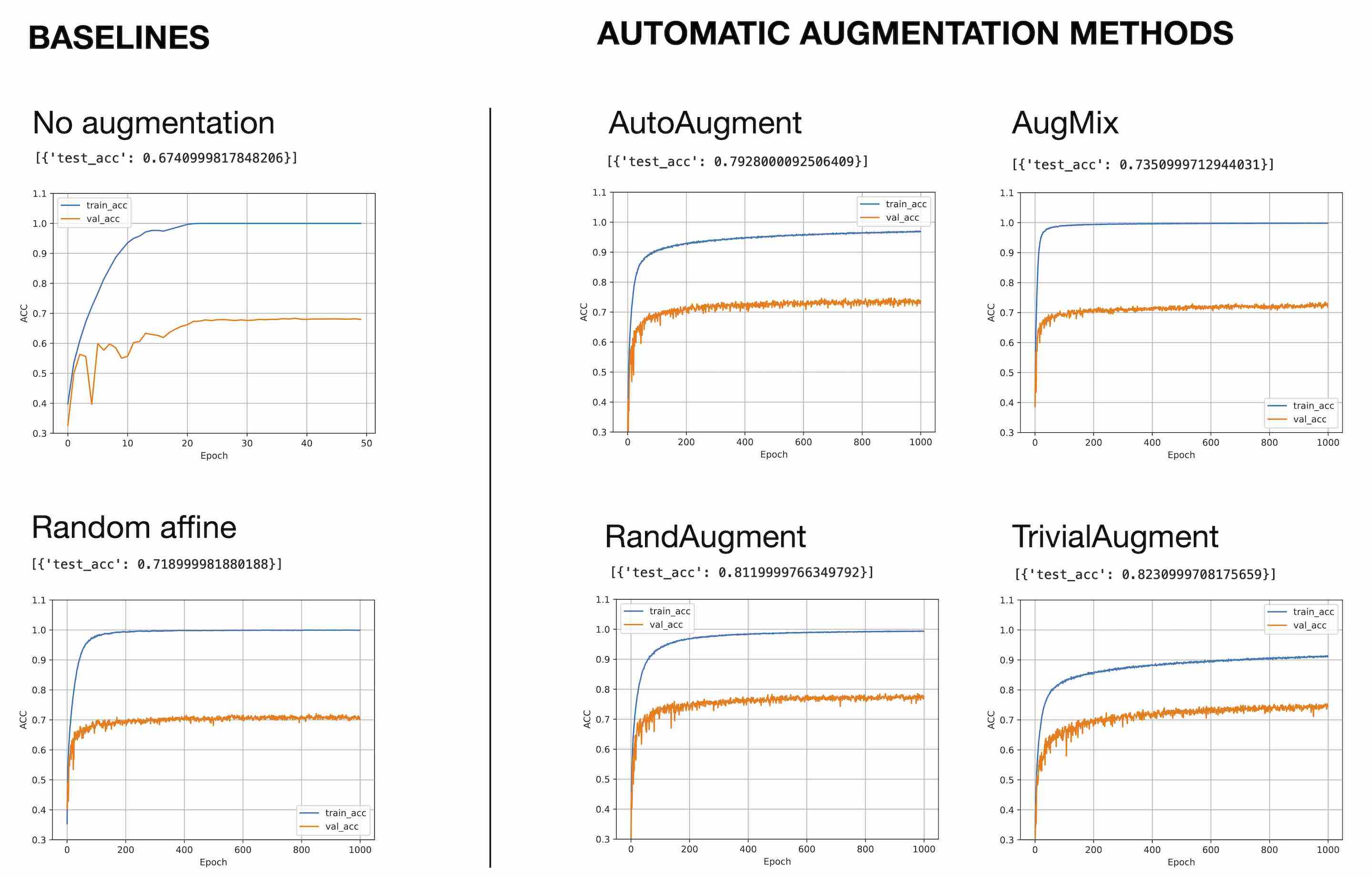
Data augmentation is a key tool in reducing overfitting, whether it's for images or text. This article compares three Auto Image Data Augmentation techniques...

Example debugging RoIAlign from Torchvision

Many developers who use Python for machine learning are now switching to PyTorch. Find out why and what the future could hold for TensorFlow.
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch
An end-to-end deep learning geospatial segmentation project using Pytorch and TorchGeo packages

The YOLO algorithm offers high detection speed and performance through its one-forward propagation capability. In this tutorial, we will focus on YOLOv5.
The Power of PyTorch/XLA and how Amazon SageMaker Training Compiler Simplifies its use
The fastai book, published as Jupyter Notebooks.
Welcome to the last entry into understanding the autograd engine of PyTorch series! If you haven’t read parts 1 & 2 check them now to understand how PyTorch creates the computational graph for the backward pass!
A detailed step-by-step explanation of how to build an image-captioning model in Pytorch
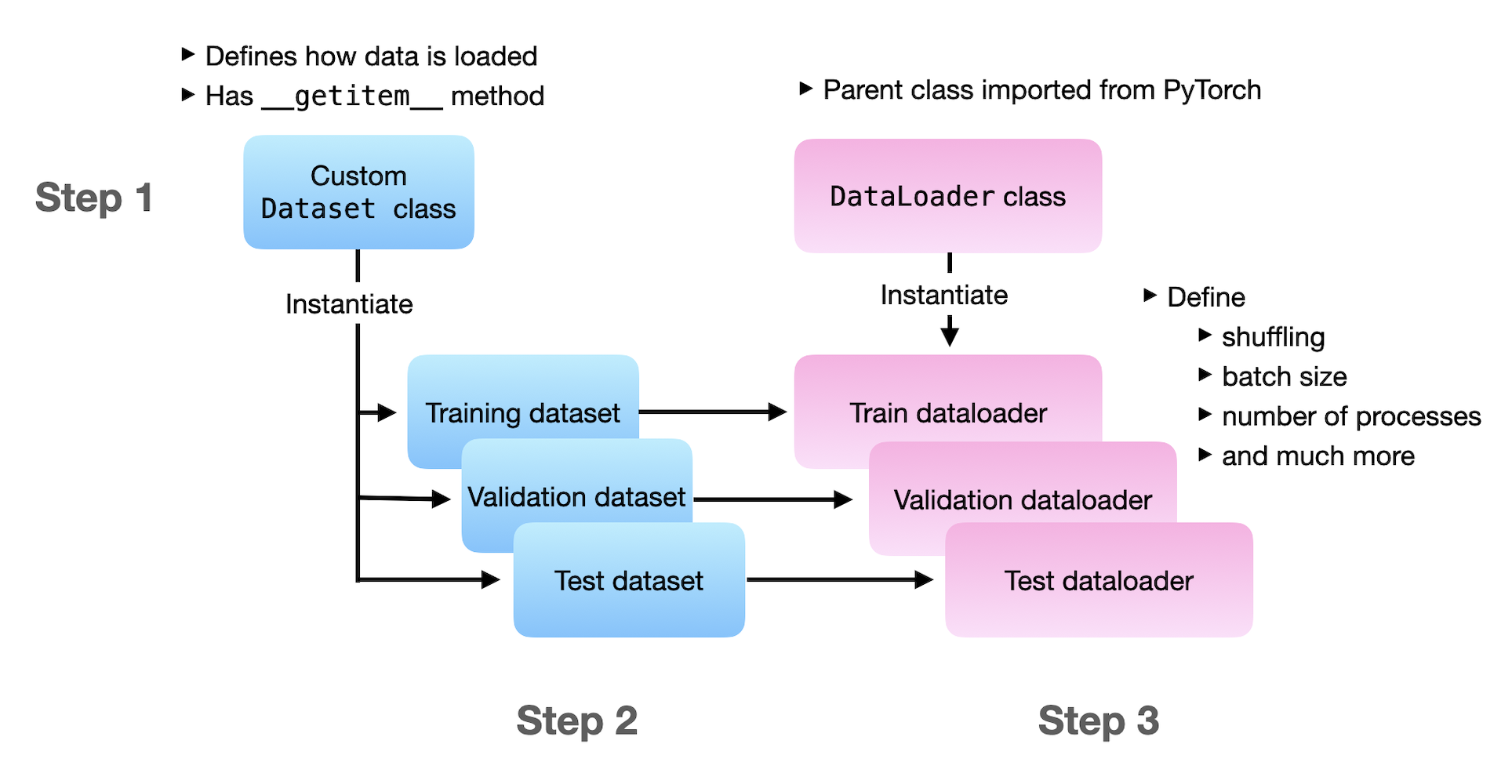
The PyTorch team recently announced TorchData, a prototype library focused on implementing composable and reusable data loading utilities for PyTorch. I hone...
A way to increase the amount of data and make the model more robust
We are excited to announce TorchRec, a PyTorch domain library for Recommendation Systems. This new library provides common sparsity and parallelism primitives, enabling researchers to build state-of-the-art personalization models and deploy them in production.
To understand the differences between automatic differentiation libraries, let’s talk about the engineering trade-offs that were made. I would personally say that none of these libraries are “better” than another, they simply all make engineering trade-offs based on the domains and use cases they were aiming to satisfy. The easiest way to describe these trade-offs is to follow the evolution and see how each new library tweaked the trade-offs made of the previous. Early TensorFlow used a graph building system, i.e. it required users to essentially define variables in a specific graph language separate from the host language. You had to define “TensorFlow variables” and “TensorFlow ops”, and the AD would then be performed on this static graph. Control flow constructs were limited to the constructs that could be represented statically. For example, an `ifelse` function statement is very different from ... READ MORE

Should you use PyTorch vs TensorFlow in 2023? This guide walks through the major pros and cons of PyTorch vs TensorFlow, and how you can pick the right framework.

PyTorch Lightning has opened many new possibilities in deep learning and machine learning with a high level interface that makes it quicker to work with PyTorch.
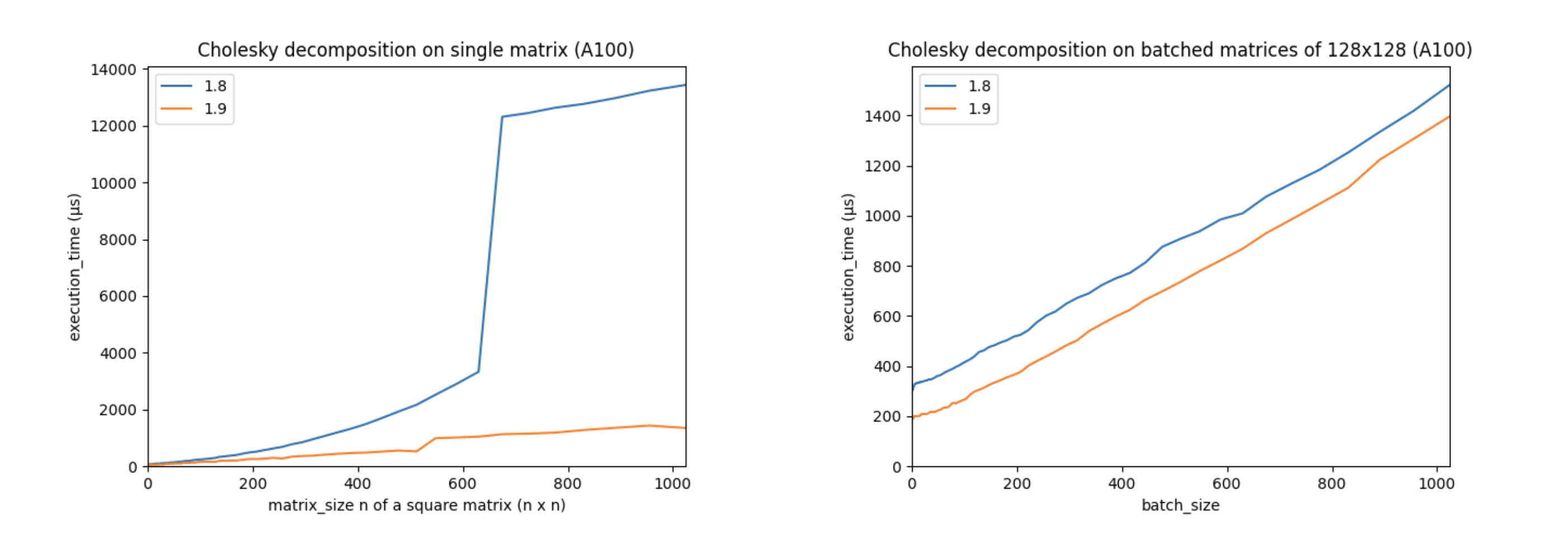
Linear algebra is essential to deep learning and scientific computing, and it’s always been a core part of PyTorch. PyTorch 1.9 extends PyTorch’s support for linear algebra operations with the torch.linalg module. This module, documented here, has 26 operators, including faster and easier to use versions of older PyTorch operators, every function from NumPy’s linear algebra module extended with accelerator and autograd support, and a few operators that are completely new. This makes the torch.linalg immediately familiar to NumPy users and an exciting update to PyTorch’s linear algebra support.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
From creating tensors to writing neural networks
Word on the street is that PyTorch lightning is a much better version of normal PyTorch. But what could it possibly have that it brought such consensus in our world? Well, it helps researchers scale…
This blog post is part of a mini-series that talks about the different aspects of building a PyTorch Deep Learning project using Variational Autoencoders. In Part 1, we looked at the variational…
A bug that plagues thousands of open-source ML projects.

A library for state-of-the-art self-supervised learning from images


In this post we take a look at how to use cuDF, the RAPIDS dataframe library, to do some of the preprocessing steps required to get the mortgage data in a format that PyTorch can process so that we…

Semantic segmentation is the task of predicting the class of each pixel in an image. This problem is more difficult than object detection…

PyTorch has sort of became one of the de facto standards for creating Neural Networks now, and I love its interface.

Delve into the comprehensive comparison of PyTorch and TensorFlow, two leading machine learning frameworks. This article covers vital differences in ease of use, graph definition, and deployment capabilities, including insights on transitioning from PyTorch to TensorFlow Lite.
As the ever-growing demand for deep learning continues to rise, more developers and data scientists are joining the deep-learning…

Application of different PyTorch functions on tensors

PyTorch Lightning will automate your neural network training while staying your code simple, clean and flexible. If you’re a researcher you

A gentle introduction to federated learning using PyTorch and PySyft with the help of a real life example.
torchlayers aims to do what Keras did for TensorFlow, providing a higher-level model-building API and some handy defaults and add-ons useful for crafting PyTorch neural networks.
249 votes, 21 comments. pytorch-optimizer -- collections of ready to use optimization algorithms for PyTorch, includes: AccSGD, AdaBound, AdaMod…

Facebook released the PyTorch3D framework that supports deep learning in 3D environments. Find out what it is.
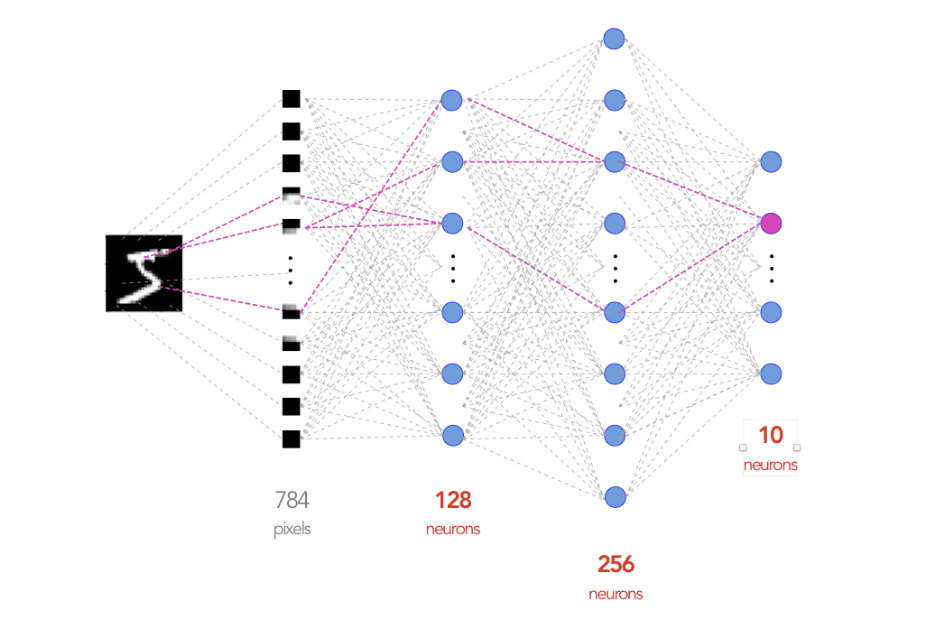
This post walks through a side-by-side comparison of MNIST implemented using both PyTorch and PyTorch Lightning.
PyTorch extensions for fast R&D prototyping and Kaggle farming - BloodAxe/pytorch-toolbelt
A set of jupyter notebooks on pytorch functions with examples - Tessellate-Imaging/Pytorch_Tutorial
Geometric Computer Vision Library for Spatial AI.

In recent years, techniques such as 16-bit precision, accumulated gradients and distributed training have allowed models to train in record times. In this talk William Falcon goes through the implementation details of the 10 most useful of these techniques, including DataLoaders, 16-bit precision, accumulated gradients and 4 different ways of distributing model training across hundreds of GPUs. We’ll also show how to use these already built-in in PyTorch Lightning, a Keras-like framework for ML researchers. William is the creator of PyTorch-Lightning and an AI PhD student at Facebook AI Research and NYU CILVR lab advised by Kyunghyun Cho. Before his PhD, he Co-founded AI startup NextGenVest (acquired by Commonbond). He also spent time at Goldman Sachs and Bonobos. He received his BA in Stats/CS/Math from Columbia University. Every month the deep learning community of New York gathers at the AWS loft to share discoveries and achievements and describe new techniques. https://github.com/williamFalcon/pytorch-lightning
PyTorch has emerged as a major contender in the race to be the king of deep learning frameworks. What makes it really luring is it’s dynamic computation graph paradigm.
This is an introduction to PyTorch's Tensor class, which is reasonably analogous to Numpy's ndarray, and which forms the basis for building neural networks in PyTorch.
Collection of generative models, e.g. GAN, VAE in Pytorch and Tensorflow. - wiseodd/generative-models

A blog about Compressive Sensing, Computational Imaging, Machine Learning. Using priors to avoid the curse of dimensionality arising in Big Data.
PyTorch Tutorial for Deep Learning Researchers.