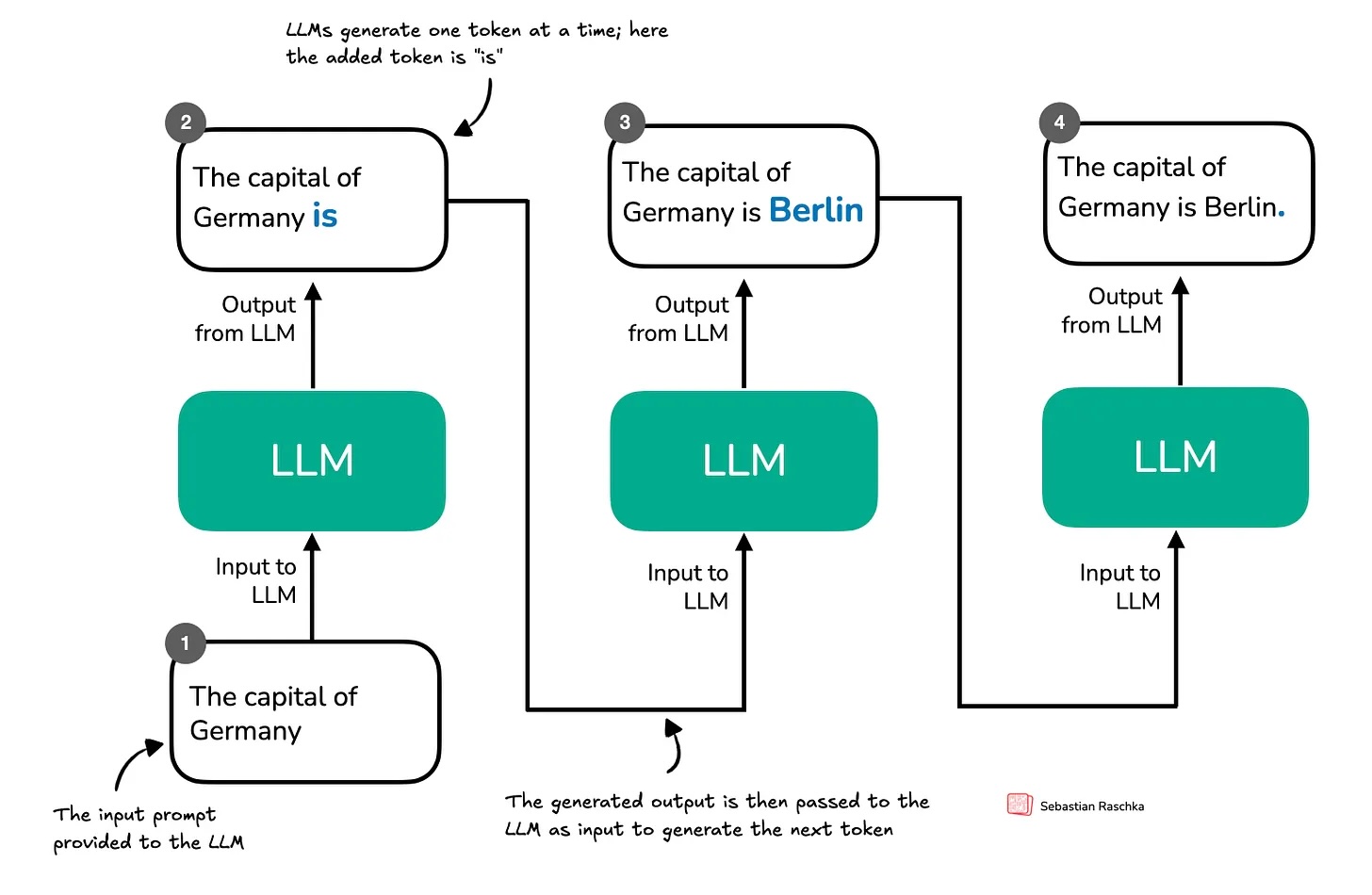
A lot has happened this month, especially with the releases of new flagship models like GPT-4.5 and Llama 4. But you might have noticed that reactions to these releases were relatively muted. Why? One reason could be that GPT-4.5 and Llama 4 remain conventional models, which means they were trained without explicit reinforcement learning for reasoning. However, OpenAI's recent release of the o3 reasoning model demonstrates there is still considerable room for improvement when investing compute strategically, specifically via reinforcement learning methods tailored for reasoning tasks. While reasoning alone isn't a silver bullet, it reliably improves model accuracy and problem-solving capabilities on challenging tasks (so far). And I expect reasoning-focused post-training to become standard practice in future LLM pipelines. So, in this article, let's explore the latest developments in reasoning via reinforcement learning.