
Model architectures, data generation, training paradigms, and unified frameworks inspired by LLMs.
Model architectures, data generation, training paradigms, and unified frameworks inspired by LLMs.

In this article, I'll take you through the recommendation algorithms you should know and how to implement them using Python.

When we turn to algorithms for recommendations instead of asking friends or going down hard-won cultural rabbit holes, what do we give up?
Best Practices on Recommendation Systems.
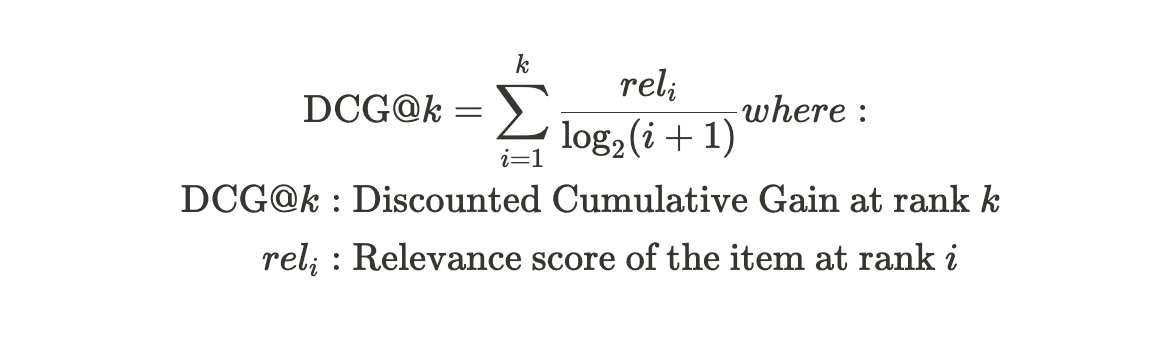
Understanding the purpose and functionality of common metrics in ML packages
Here's a small thought experiment that explores an alternative approach to ranking posts on HackerNews.

Understanding the most underrated trick in applied Machine Learning
Covers how to choose the similarity measure when item embeddings are available
Dive into the inner workings of TikTok’s awesome real-time recommendation system and learn what makes it one of the best in the field!
I built a recommender system for Amazon’s electronics category
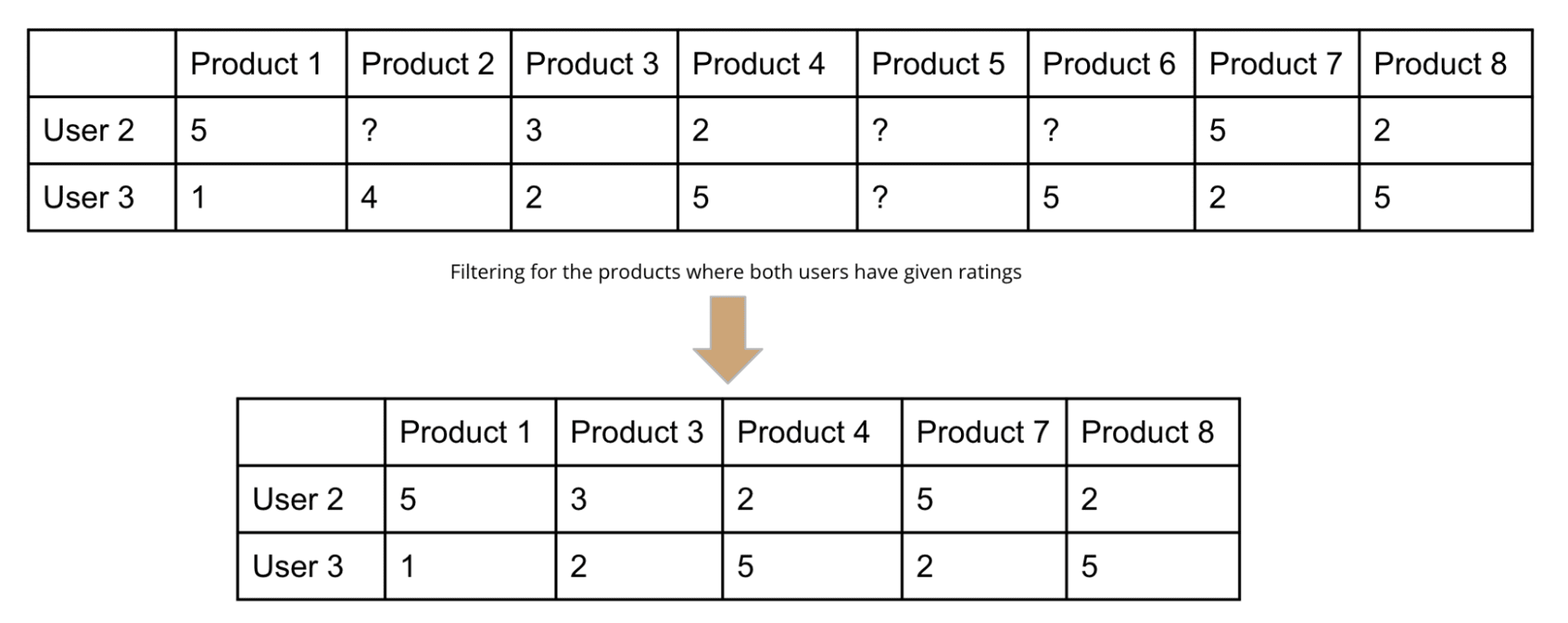
The post introduces one of the most popular recommendation algorithms, i.e., collaborative filtering. It focuses on building an intuitive understanding of the algorithm illustrated with the help of an example.

Patience and empathy are the basis of good documentation, much as they are the basis for being a decent person. Here's a how-to for creating better open source project docs, which can help your users and grow your community.
Making the best recommendations to anonymous audiences
A List of Recommender Systems and Resources.

Without driving yourself crazy

Buyers reveal a whole range of behaviors and interests when they browse our pages, so we decided to incorporate these additional purchase intent signals into our machine learning model to improve the relevance of our recommended items.

A preview into one of the most prominent data science applications

Under the new machine learning model, buyers are recommended items that are more aligned to their shopping interests on eBay.
We are excited to announce TorchRec, a PyTorch domain library for Recommendation Systems. This new library provides common sparsity and parallelism primitives, enabling researchers to build state-of-the-art personalization models and deploy them in production.

Speech and natural language processing (NLP) have become the foundation for most of the AI development in the enterprise today, as textual data represents a significant portion of unstructured content.
The memory capacity of embedding tables in deep learning recommendation models (DLRMs) is increasing dramatically from tens of GBs to TBs across the industry. Given the fast growth in DLRMs, novel...
Your daily dose of data science
How many different ways we can evaluate RecSys?
Physics Meets Recommendations

A couple years ago, Stephen Malkmus walked into a shop and didn’t recognize himself. He was with one of his daughters, stopping at a gluten-free bakery (“Very Portland,” Malkmus jokes) when the Pavement song “Harness Your Hopes” came on — a song he had written and recorded more than two decades prior while leading the band. The guitar-playing that was choogling over the speakers was partially his own, but in the few moments before the vocals kicked in, his brain couldn’t place it. “At first I thought, ‘Oh, they’re playing “Tumbling Dice” by Rolling Stones,’” he remembers now, over the phone. “Then it was playing and I thought, ‘Well, this is a cool place.’ Little did I know it was just on Spotify or something.” At that point, the track was still a deep cut — a B-side recorded during the sessions for 1997’s Brighten The Corners, but not released until 1999, when it was thrown onto the CD-only Spit On A Stranger EP, a detail so remote that even Malkmus had forgotten about it until he was reminded. The song remained one that only the real heads knew until 2008, when it was included on Matador’s expanded reissue of Brighten The Corners, alongside a large amount of the extra material recorded for that album by producer/engineers Mitch Easter and Bryce Goggin. It was then that the castoff song began its new life, slowly becoming a minor fan favorite — a single-worthy non-album track that indicated just how rich the band’s discography was. A curveball to put on a mix and raise an eyebrow. The type that a bakery employee might sneak onto the work playlist as a subtle way to class the joint up. But then something bizarre happened: In the last few years, the song has rocketed up to become number one on Pavement’s Spotify page, ending up with over 28 million plays to date, seven million more than “Cut Your Hair,” a legitimate and enduring ’90s hit. Quickly, and without any obvious reason, it stopped being a rarity and started to become a standard, appearing in coffee shops and bars and gluten-free bakeries. So how did this happen, exactly? And better yet, should this have happened? Online, people have been casually wondering this on places like Reddit and Twitter, with a prevailing theory being that the song must have been featured on a prominent Spotify playlist, and then simply snowballed from there. Malkmus himself was under this impression, too: “I heard it was on a playlist or something,” he says, nonchalant. “I’m not an expert on Spotify but, you know, one of those ‘Monday Moods’ or whatever the fuck they do.” It’s a reasonable enough explanation. But looking at a similar situation of his own, Damon Krukowski wasn’t so sure. The musician and writer was fascinated with the question of how “Strange” became his former band Galaxie 500’s top Spotify track — by a significant margin — even though it was not a single, was never particularly popular in the past, and wasn’t being picked up on any prominent playlists. In June of 2018, Krukowski laid out the conundrum on his blog, and soon he received a possible explanation from a Spotify employee. Glenn McDonald, who holds the title of “data alchemist” at Spotify, had taken an interest in the case, and decided to look into it. What he found is that the sudden jump in plays for “Strange” began in January of 2017, which was “the same time Spotify switched the ‘Autoplay’ preset in every listener’s preference panel from off, to on,” as Krukowski recounted on a follow-up blog post. McDonald explained to Krukowski that the Autoplay feature actually cues up music that “resembles” what you’ve just been listening to, based on a series of sonic signifiers too complex to describe. In this case, “Strange” had been algorithmically determined to sound similar to a lot of other music, and was frequently being Autoplayed to the point that it took on a life of its own, and eventually eclipsed the band’s other tracks. It continues to do so to this day. “He called me up because of that blog post,” Krukowski explains, on the phone from his home in Cambridge, Massachusetts, “and said he got really interested in it as an engineering problem, ’cause he thought I had pinpointed something they hadn’t realized. Like, because you switch these things in the program, it’s the butterfly effect — who knows what’s gonna result?” More simply put, Spotify appears to have the capacity to create “hits” without even realizing it. When it comes to Galaxie 500, “there’s just no way this would have happened before this flip in the Spotify plays,” Krukowksi notes. “And now we’re becoming identified as a band with that song, because if they learn about the band through Spotify, that’s what they’re hearing. So it becomes, like, our emblem.” Krukowski was convinced, but for his part, McDonald wanted to remain clinical in his diagnosis, waiting to look at more information before making any final judgment as to what was going on with the Autoplay feature at large. If he’s still looking for fresh examples to consider, anyway, “Harness Your Hopes” would be an ideal place to start. Beyond it being a similar situation, broadly speaking — another touchstone alternative rock band from the ’80s/’90s with an inexplicable #1 song — the story also features a detail likely too specific to be coincidental: Using the Wayback Machine, it can be confirmed that “Harness Your Hopes” was nowhere to be seen on the popular tracks section of Pavement’s Spotify page until — you guessed it — 2017, when it suddenly jumped to the top. (Spotify doesn’t disclose more detailed information about artists’ streaming numbers beyond the playcount that’s publicly visible.) When requested, Spotify declined to provide an interview with McDonald, nor with anyone else who would be able to speak to the Autoplay function and how it may or may not be fueling a phenomenon like this. But they did confirm “the accuracies of Glenn’s statements” as they appear on Krukowski’s blog, and left it at that. Speaking from Switzerland, where she’s a visiting scholar at Basel University, Dr. Maria Eriksson is used to not getting much hard information to work with from Spotify. She co-authored a book on the company, 2019’s Spotify Teardown, which investigated the streaming giant and their algorithms to the degree that Spotify’s legal department eventually sent them a cease-and-desist notice. After logging on to a Zoom call, she listens to the “Harness Your Hopes”/”Strange” saga with enthusiasm, but no surprise. “What I find interesting about this story is that, from my research perspective, it really shows the power and influence that these music recommendation systems have,” she says. “But it is also extremely difficult to know how these systems work, and I think the only people who can answer that would be the engineers working at these companies, like Spotify. We’re not even sure if these people could answer why or how a recommendation system works as well, because they’re usually pretty complex things we’re dealing with here.” Krukowski, who is one of the organizers of Justice At Spotify — a new protest campaign demanding a higher artist royalty rate, among other things — isn’t all that concerned with the Autoplay situation, at least in the ways that it might be screwing with artists’ top songs. But he is concerned with the ways that incidental algorithmic designs have industry-wide power: “It’s just kind of stifling to have that amount of control, and have it in one company,” he says. “And then not only that, but to have it made by engineering decisions. This is very consistent with a lot of our culture right now, that we’re willing to surrender to Facebook and Google engineers very important decisions.” Today we are launching our campaign to demand justice at Spotify. Join us and hundreds of musicians and music workers that have already signed on to our demands! https://t.co/8BhohF88q5 pic.twitter.com/zRFGs6nAfZ — Union of Musicians and Allied Workers (@UMAW_) October 26, 2020 In this specific instance, there’s certainly a case to be made that Autoplay might actually be doing a service to the songs that it unintentionally favors — that it might be providing something valuable and unprecedented by plucking tracks from the depths and giving them the possibility of a second chance. Optimistically speaking, the algorithm could be mathematically figuring out which songs people are prone to like, regardless of how well they fared commercially in the first place. And that squares up with the case of “Harness Your Hopes,” since it was a song that was left off Brighten The Corners for no good reason, according to Malkmus. He says that after the band recorded it, they spliced out a bit of tape to shorten the waltzing part that ends the chorus (when Malkmus sings, “Minds wide open, truly”) — a change that ultimately soured him on including the track on the album. “It’s better, I like it, it’s cool that we did that, it’s old-school or whatever,” he says of the analog adjustment. “But it sounded wrong to me or something, and I was like, ‘That’s a B-side.’ It’s terrible, too — nobody told me! I guess I was such a boss, and maybe nobody thought I would listen. Usually Scott [‘Spiral Stairs’] Kannberg or something was really good at telling me, ‘That’s a good song,’ [like he did with the Slanted And Enchanted single] ‘Summer Babe.’ So it should have been on the record. I’m just saying that’s my mistake.” Now, and likely forever, “Harness Your Hopes” has moved beyond the Spotify phenomenon to become one of the definitive Pavement tracks across all platforms — Apple Music, YouTube, etc. It’s even been having a moment on TikTok lately, to the degree that Malkmus’s 15-year-old daughter recently saw it in a post and gave him the news that it was blowing up, kinda. “She was like, ‘It’s trending, but in a certain way, not in a big way,’” he laughs, dryly. It’s hard not to see the zombified success of the song as being anything but for the best, because in this case it really ...
It’s time to bring together recent breakthroughs in AI to help solve information overload when you need quality recommendations the most.

New modeling approach increases accuracy of recommendations by an average of 7%.

Introduction on Stacked Auto-encoder and Technical Walk-through on Model Creation using Pytorch
Bringing Neural Architecture into Recommendations

This guide will show in detail how item based recommendation system works and how to implement it in real work environment.

Going above and beyond state-of-the-art with confidence!
Categories of Deep Recommendation Systems

Behind every recommender system lies a bevy of metrics.
Many of us are bombarded with various recommendations in our day to day life, be it on e-commerce sites or social media sites. Some of the recommendations look relevant but some create range of emotions in people, varying from confusion to anger. There are basically two types of recommender systems, Content based and Collaborative filtering.… Read More »Recommender Engine – Under The Hood

Summary: There are five basic styles of recommenders differentiated mostly by their core algorithms. You need to understand what’s going on inside the box in order to know if you’re truly optimizing this critical tool. In our first article, “Understanding and Selecting Recommenders” we talked about the broader business considerations and issues for recommenders as… Read More »5 Types of Recommenders

Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.
While we commonly associate recommendation systems with e-commerce, their application extends to any decision-making problem which requires pairing two types of things together. To understand why recommenders don’t always work as well as we’d like them to, we set out to build some basic recommendation systems using publicly available data. Data The first ingredient for building a recommendation system is user interaction data. We experimented with two different datasets, one from Flickr and one from Amazon.
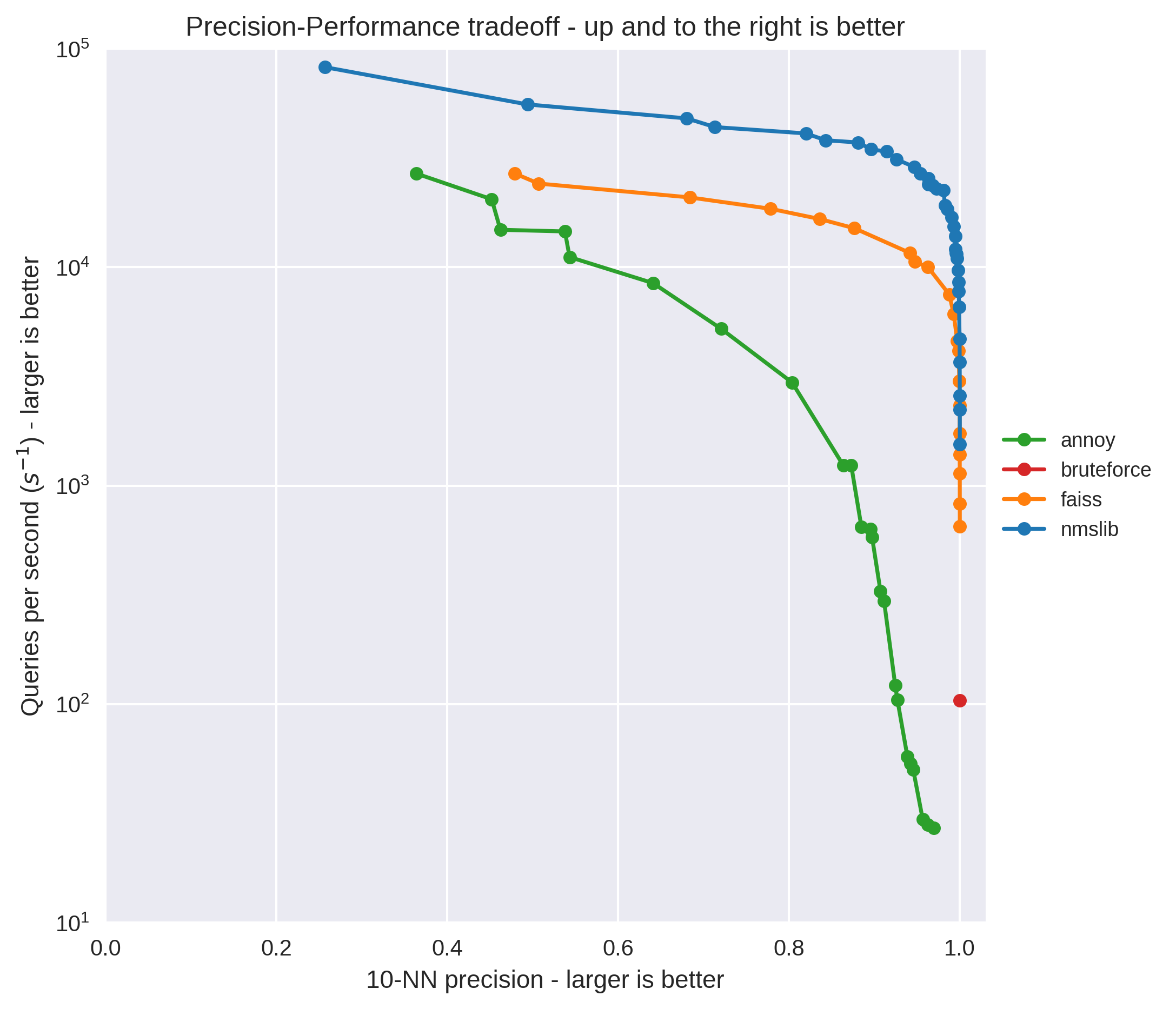
This post is about evaluating a couple of different approximate nearest neighbours libraries to speed up making recommendations made by matrix factorization models. In particular, the libraries I'm looking at are Annoy, NMSLib and Faiss.

I will use {ordinal} clm() (and other cool R packages such as {text2vec} as well) here to develop a hybrid content-based, collaborative filtering, and (obivously) model-based approach to solve the recommendation problem on the MovieLens 100K dataset in R. All R code used in this project can be obtained from the respective GitHub repository; the chunks of code present in the body of the post illustrate the essential steps only. The MovieLens 100K dataset can be obtained from the GroupLens research laboratory of the Department of Computer Science and Engineering at the University of Minnesota. The first part of the study introduces the new approach and refers to the feature engineering steps that are performed by the OrdinalRecommenders_1.R script (found on GitHub). The second part, to be published soon, relies on the R code in OrdinalRecommenders_3.R and presents the model training, cross-validation, and analyses steps. The OrdinalRecommenders_2.R script encompasses some tireless for-looping in R (a bad habbit indeed) across the dataset only in order to place the information from the dataset in the format needed for the modeling phase. The study aims at (a) the demonstration of the improvement in predicted ratings for recommending on a well-known dataset, and (b) attempts to shedd light on the importance of various types of information in the work of recommendation engines. Consequently, the code is not suited for use in production; additional optimizations are straightforward, simple, and necessary as well.IntroductionAvoiding the formal exposition of the problem altogether, the recommendation problem in the context of contemporary online markets can expressed in the following way: given (A) the information on the user’s past ratings of various items (i.e. the user-item ratings; for example, the ratings on a 5-point Likert type scale of the movies or TV shows that she or he has watched in the past, the ratings on similar scales of the items purchased, and similar), (B) the information on the user-item ratings of other users, © the attributes of users and/or items (c.f. the user’s gender, geographical location, age, occupation, and similar; the genre of the movie, product type, and similar for items), provide a prediction of the user’s rating of a novel, previously unassessed item. The predictions are then used to select the novel items (or lists of items) that a particular user would - by assumption - enjoy to assess, and eventualy purchase, in the future. The cognitive systems used for making such predictions are known as recommendation engines, or recommender systems, and are widely used nowadays across the Internet business.It is generally recognized that recommendation engines can be grouped in two broad categories: (1) content-based systems, or (2) collaborative filtering systems, with the later additionally described as (1.1) neighborhood or (1.2) model-based methods [1]. Content based systems (CF) rely on a typical description of items over feature vectors, and then recommend novel items to users by computing some similarity metric between them and the items that the user has already rated. Collaborative filtering systems, on the other hand, rely on the assumption that the covariations between the ratings (a) from different users over the same set of items, or (b) to different items from the same set of users, implicitly carry the information on item and user attributes. The information about the true user and item attributes are thus latent in CF. In the neighborhood (or memory) variant of CF, these approaches use the user-item ratings directly and proceed by aggregating the ratings of similar users (user-based CF) and/or similar items (item-based CF) in order to provide an estimate of the user’s rating of a novel item, typically weighting the known ratings of similar users/items by the respective proximity/similarity measures. In the model-based variant of CF, the systems tries to discover the structure of the latent factors from the observed behavioral measures (ie. known user-item ratings), and then a myriad of machine learning algortihms and statistical approaches can be used to train a predictive model for the novel user-item ratings of novel items.I will here introduce a new hybrid approach to recommender systems with the following characteristics. First, the system is both content-based and CF. The content-based component of the system encompasses two matrices: the user-user and the item-item proximity matrices, both obtained from applying the relevant distance metric over a set of features that characterize users and items, respectively. The CF component of the system, relies on the typical user-user and item-item similarity matrices computed from the known, past user-item ratings, providing for a memory component of the recommender. Second, the system is model-based in the sense that it combines the information from these four matrices in an ordinal logistic regression model to predict the ratings of novel items on a 5-point Likert scale. The underlying logic of this approach is to try to express the recommendation problem as a discrete choice problem, where the alternatives are provided by ordinal information from a 5-point Likert scale, while the decision makers and the choice context are described by a set of content-based and memory-based features, all referring to some degree of closeness between the unknown user/item combination with the known user/item in two spaces: the attribute (feature) space and the neighborhood (memory) space. Because the CF approaches rely on users-user (or item-item) proximity, the question of how many users (or items) that are similar to the context of the present, novel user-item rating should be used in prediction arises naturally. By expressing the recommender problem as a regression problem essentially, we become able to judge the significance of additional user-user and/or item-item similarity information from the change in regression coefficients obtained by progressively adding more and more information to nested ordinal logistic models and training them. Thus the new approach also provides and excellent opportunity for a comparison between content-based information and memory-based information (the later as being typically used in CF): which one is more important? Given the assumption that the former is implicitly present in the later, i.e. that it presents latent information in the CF approach, does the usage of manifest memory-based information on user-item ratings completelly eliminates the need for a content-based description? If not, how the two should be combined? I will demonstrate how the present approach resolves this dilemma while resulting in highly improved recommendations on a well-known and widely used MovieLens dataset, at the same time reducing drastically the number of features that are needed to build the relevant prediction model.MotivationConsider the following user-item ratings matrix, encompassing 10 items (columns) and three users (rows):In this rating matrix, the ratings of user1 and user2 have a maximal Pearson correlation of 1; however, the ratings of user2 and user3 have a linear correlation of .085, sharing around .007 % of variance only. Upon a closer look, user1 and user2 have only three common ratings (for items i1, i4, and i5), while user2 and user3 have rated exactly the same items (i1, i3, i4, i5, i8, i9, and i10). Imagine that the items rated by user2 and user 3 are all Sci-Fi movies; we can imagine these two users chating and challenging each other’s views on the contemporary Sci-Fi production on online forums or fan conferences, right? They do not have to have perfectly similar tastes, right, but in fact they are similar: simply because they both enjoy Sci-Fi. The Jaccard distance measures the proximity of two vectors A and B, both given over binary features (e.g. present vs. not present), by computing the ratio of (a) the difference between the union of A and B and the intersection of A and B to the (b) union of A and B; it ranges from zero to one and can be viewed as a proportion of common features that the two vectors share in the total number of features present in both. The Jaccard similarity coefficient is given by one minus the Jaccard distance; we will use the {proxy} dist() function to compute these from our ratings matrix:### --- Illustrationuser1

