vision


Did you know some people can’t see images in their minds? It’s a real issue—and it has a name: aphantasia.
This is a visual guide (scroll story) to Vision Transformers (ViTs), a class of deep learning models that have achieved state-of-the-art performance on image classification tasks.

Eye blinks aren't just a mechanism to keep our eyes moist. Research finds that blinking plays a key role in processing visual information.

Recalling items from scratch is harder than recognizing the correct option in a list of choices because the extra context helps users retrieve information from memory.

Vox is a general interest news site for the 21st century. Its mission: to help everyone understand our complicated world, so that we can all help shape it. In text, video and audio, our reporters explain politics, policy, world affairs, technology, culture, science, the climate crisis, money, health and everything else that matters. Our goal is to ensure that everyone, regardless of income or status, can access accurate information that empowers them.

The goal is not to expose the “slipups” of the masters but to understand the human brain.
Over the past three years Pinterest has experimented with several visual search and recommendation services, including Related Pins (2014), Similar Looks (2015), Flashlight (2016) and Lens (2017)....

The color debate that broke the internet raised new questions about the relationship between perception and consciousness.

Your pupils may be dilating when you see images like this one as your brain tries to anticipate the near future.
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F7493%2F1643860013_ScreenShot2022-02-02at7.42.07PM.png)
The brain is basically a time machine that ensures what we see is stable and continuous.

Semantic segmentation is the task of predicting the class of each pixel in an image. This problem is more difficult than object detection…

Interactive article explaining how cameras and lenses work.

What are these new YOLO releases in 2020? How do they differ? Which one should I use?
Scientists have developed an Artificial Intelligence (AI) system that recognises hand gestures by combining skin-like electronics with computer vision.

Welcome to Feedly — the platform where businesses and curious minds stay ahead of the curve! We're passionate about helping teams track competitors, discover new trends, and research emerging security threats. Feedly AI is a collection of machine learning models that automatically collect, analyze, and help you share actionable insights from millions of sources in real-time.
This is an overview of a great computer vision resource from Microsoft, which demonstrates best practices and implementation guidelines for a variety of tasks and scenarios.


A step-by-step guide to apply perspective transformation on images
Machine learning is often fueled by image data. In this guide, learn the basics about image annotation, common techniques, and key workforce considerations.

In this post, we’ll create an end to end pipeline for image multiclass classification using Pytorch.This will include training the model, putting the model’s results in a form that can be shown to business partners, and functions to help deploy the model easily. As an added feature we will look at Test Time Augmentation using Pytorch also.
Use a pre-trained neural network for feature extraction and cluster images using K-means.

Visual vocabulary advances novel object captioning by breaking free of paired sentence-image training data in vision and language pretraining. Discover how this method helps set new state of the art on the nocaps benchmark and bests CIDEr scores of humans.

Tesla's Autopilot system relies on vision rather than LIDAR, which means it can be tricked by messages on billboards and projections created by hackers.


To recognise a chair or a dog, our brain separates objects into their individual properties and then puts them back together. Until recently, it has remained unclear what these properties are. Scientists at the Max Planck Institute for Human Cognitive and Brain Sciences in Leipzig have now identified them - from "fluffy” to “valuable” - and found that all it takes is 49 properties to recognise almost any object.
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F5732%2F1600778827_Dynamical-Vision_2500_Lede.jpg)
Mathematicians and neuroscientists have created the first anatomically accurate model that explains how vision is possible.

Recognition of Oil Storage Tanks in satellite images using the Yolov3 object detection model from scratch using Tensorflow 2.x and…

A brief introduction to CenterNet (Objects as Points), TTFNet and their implementation in TensorFlow 2.2+.
:extract_focal()/https%3A%2F%2Fpocket-syndicated-images.s3.amazonaws.com%2Farticles%2F4877%2F1593177446_ezgif.com-webp-to-jpg153.jpg)
To researchers’ surprise, deep learning vision algorithms often fail at classifying images because they mostly take cues from textures, not shapes.
We present MocapNET, a real-time method that estimates the 3D human pose directly in the popular Bio Vision Hierarchy (BVH) format, given estimations of the 2D body joints originating from monocula...

Less than 50 days after the release YOLOv4, YOLOv5 improves accessibility for realtime object detection. June 29, YOLOv5 has released the first official version of the repository. We wrote a new deep dive on YOLOv5. June 12, 8:08 AM CDT Update: In response to to community feedback, we have
Dimensionality Reduction Techniques for Hyperspectral Images.

Smooth python codes to augment your image datasets by yourself.


Webcam background change is not limited to Zoom now, I just did it in the browser with tensorflow.js body-pix model


Computer vision is evolving on a daily basis. Popular computer vision techniques such as image classification and object detection have been used extensively to solve a lot of computer vision…

Explore and manipulate the COCO image dataset for Semantic Image Segmentation with PyCoco, Tensorflow Keras Python libraries

Create a data generator and train your model on the COCO image dataset for Semantic Image Segmentation with PyCoco, Tensorflow Keras py
/cdn.vox-cdn.com/uploads/chorus_asset/file/12162773/akrales_180816_2793_0073.jpg)
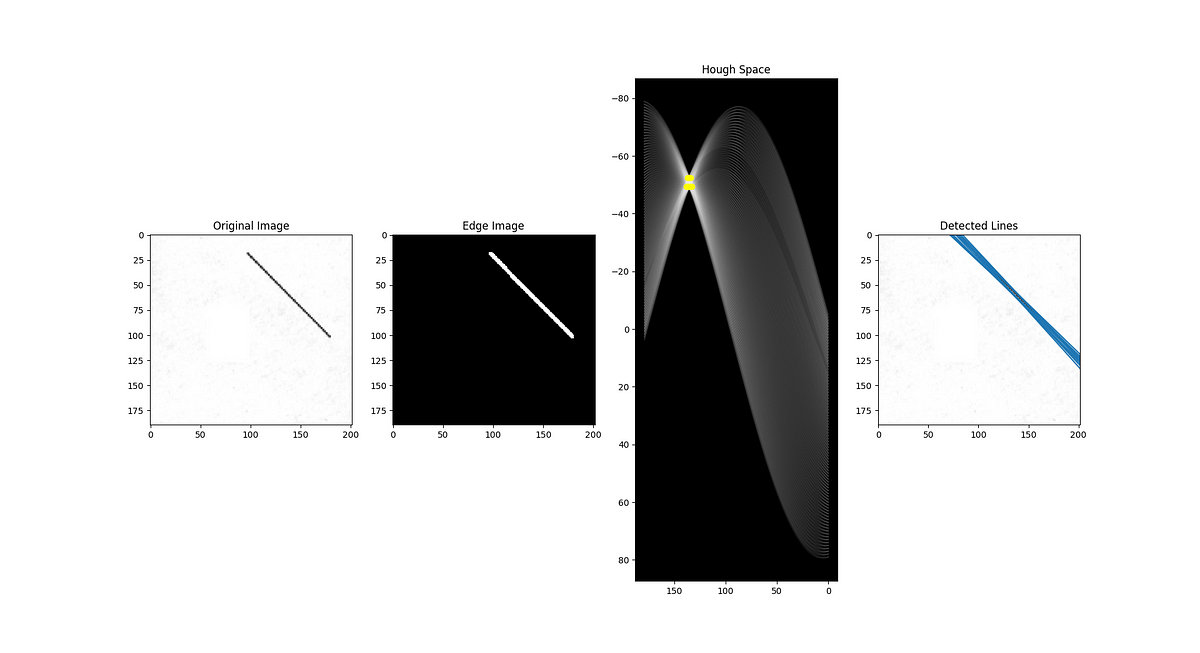

A detailed step-by-step guide to build a Lane Line Detection algorithm in OpenCV.

It’s theoretically possible to become invisible to cameras. But can it catch on?
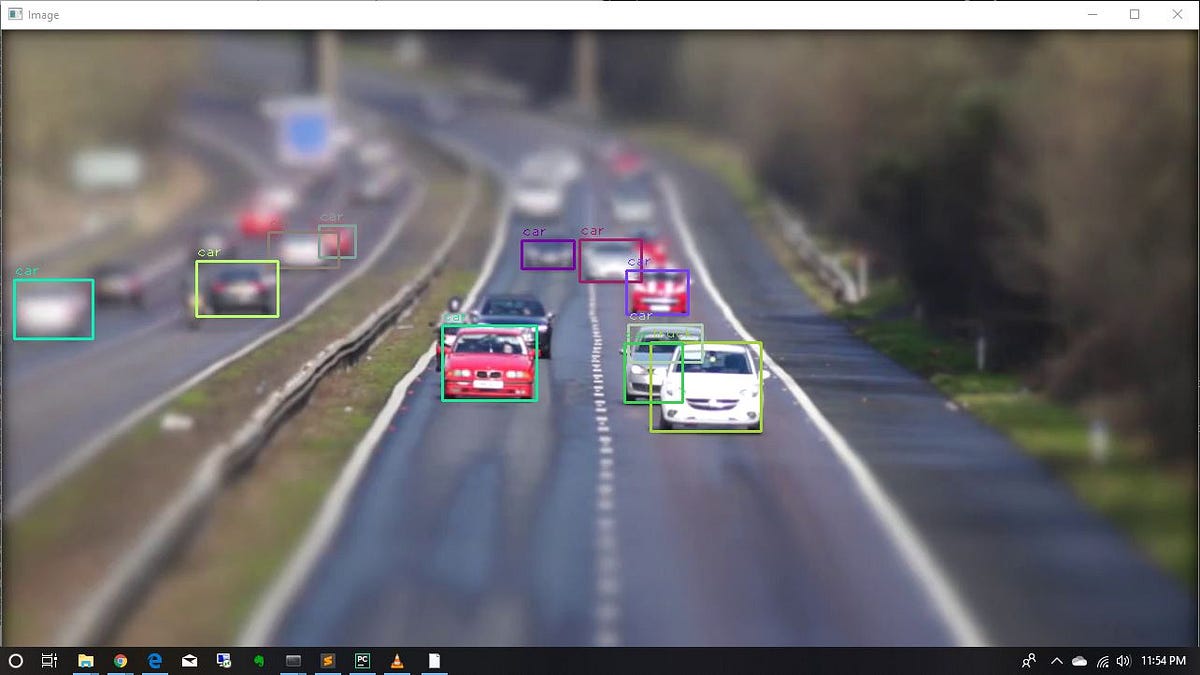
An Introduction to Object Detection with YoloV3 for beginners

Learn about different types of annotations, annotation formats and annotation tools
Object Detection using Yolo V3 and OpenCV .

Learn the basics of working with RGB and Lab images to boost your computer vision projects!
🔥🔥Defending Against Deepfakes Using Adversarial Attacks on Conditional Image Translation Networks - natanielruiz/disrupting-deepfakes

Explore the Real-World Applications of Your Model
Mask R-CNN has been the new state of the art in terms of instance segmentation. Here I want to share some simple understanding of it to give you a first look and then we can move ahead and build our model.


Posted by Shreeyak Sajjan, Research Engineer, Synthesis AI and Andy Zeng, Research Scientist, Robotics at Google Optical 3D range sensors, like R...

Convert images to a string with Google Tesseract and then into a static HTML site using python

How can digital signal processing help you equalize histograms for digital photography? Learn more here.
443K subscribers in the learnmachinelearning community. A subreddit dedicated to learning machine learning
Geometric Computer Vision Library for Spatial AI.

Extract table from image with Nanonets table detection OCR. Learn OCR table Deep Learning methods to detect tables in images or PDF documents.

Researchers have shrunk state-of-the-art computer vision models to run on low-power devices. Growing pains: Visual recognition is deep learning’s strongest skill. Computer vision algorithms are analyzing medical images, enabling self-driving cars, and powering face recognition. But training models to recognize actions in videos has grown increasingly expensive. This has fueled concerns about the technology’s carbon…

In this tutorial you will learn how to use Keras, Mask R-CNN, and Deep Learning for instance segmentation (both with and without a GPU).

You only look once (YOLO) is a state-of-the-art, real-time object detection system.

Image processing is performing some operations on images to get an intended manipulation. Think about what we do when we start a new data analysis. We do some data preprocessing and feature engineering. It’s the same with image processing.
Some Tricks and Code for Kaggle and Everyday work. This post is about useful feature engineering methods and tricks that I have learned and end up using often.
Tensorflow (Python API) implementation of Deep Photo Style Transfer - LouieYang/deep-photo-styletransfer-tf

Through a human’s eyes, the world is much more than just the images reflected in our corneas. For example, when we look at a building and admire the intricacies of its design, we can appreciate...
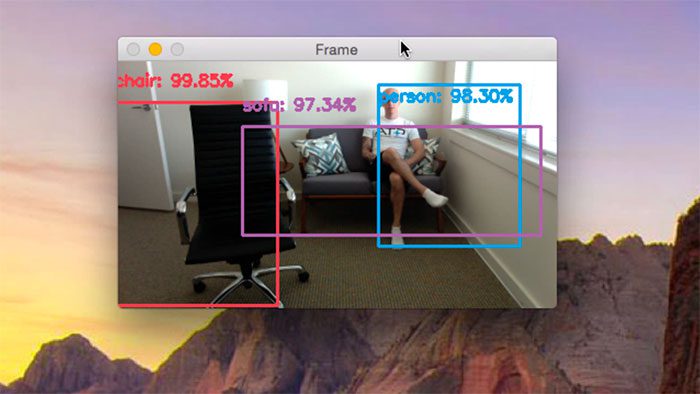
In this tutorial I demonstrate how to apply object detection with deep learning and OpenCV + Python to real-time video streams and video files.
GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.

Dive into our detailed explanation of what is Region of Interest (RoI) Pooling in deep learning. Enhance your skills. Discover more now!