arxiv

In June, I shared a bonus article with my curated and bookmarked research paper lists to the paid subscribers who make this Substack possible.

A curated list of LLM research papers from July–December 2025, organized by reasoning models, inference-time scaling, architectures, training efficiency, and...
Multisets are sets that allow repetition of elements. As such, multisets pave the way to a number of interesting possibilities of theoretical and applied nature. In the present work, after revising the main aspects of traditional sets, we introduce some of the main concepts and characteristics of multisets, followed by their generalization to take into account vectors and matrices. An approach is also proposed in which the real, negative multiplicities are allowed, implying the multiset universe to become finite and well-defined, corresponding to the multiset with null multiplicities. The complement operation in multisets is then defined, which allows properties involving complement -- including the De Morgan theorem -- to be recovered in multisets. In addition, it becomes possible to extend multisets to functions (which become multifunctions), scalar fields and other continuous mathematical structure, therefore achieving an enhanced space endowed with all algebraic operations plus set theoretical operations including union, intersection, and complementation. The possibility to define a set operation between mfunctions, namely the common product, that is analogous to the traditional inner product is also proposed, paving the way to obtaining respective mfunction transformations, and it is argued that the Walsh functions provide an orthogonal basis for the mfunctions space under the common product. This result also allowed the proposal of performing integrated signal processing operations on mset mfunctions, including filtering and enhanced template matching. Relationships between the cosine similarity index and the Jaccard index are also identified, including the presentation of an intersection-based variation of the cosine index. The potential of multisets in pattern recognition and deep learning is also briefly characterized and illustrated.
Compute-in-SRAM architectures offer a promising approach to achieving higher performance and energy efficiency across a range of data-intensive applications. However, prior evaluations have largely relied on simulators or small prototypes, limiting the understanding of their real-world potential. In this work, we present a comprehensive performance and energy characterization of a commercial compute-in-SRAM device, the GSI APU, under realistic workloads. We compare the GSI APU against established architectures, including CPUs and GPUs, to quantify its energy efficiency and performance potential. We introduce an analytical framework for general-purpose compute-in-SRAM devices that reveals fundamental optimization principles by modeling performance trade-offs, thereby guiding program optimizations. Exploiting the fine-grained parallelism of tightly integrated memory-compute architectures requires careful data management. We address this by proposing three optimizations: communication-aware reduction mapping, coalesced DMA, and broadcast-friendly data layouts. When applied to retrieval-augmented generation (RAG) over large corpora (10GB--200GB), these optimizations enable our compute-in-SRAM system to accelerate retrieval by 4.8$\times$--6.6$\times$ over an optimized CPU baseline, improving end-to-end RAG latency by 1.1$\times$--1.8$\times$. The shared off-chip memory bandwidth is modeled using a simulated HBM, while all other components are measured on the real compute-in-SRAM device. Critically, this system matches the performance of an NVIDIA A6000 GPU for RAG while being significantly more energy-efficient (54.4$\times$-117.9$\times$ reduction). These findings validate the viability of compute-in-SRAM for complex, real-world applications and provide guidance for advancing the technology.
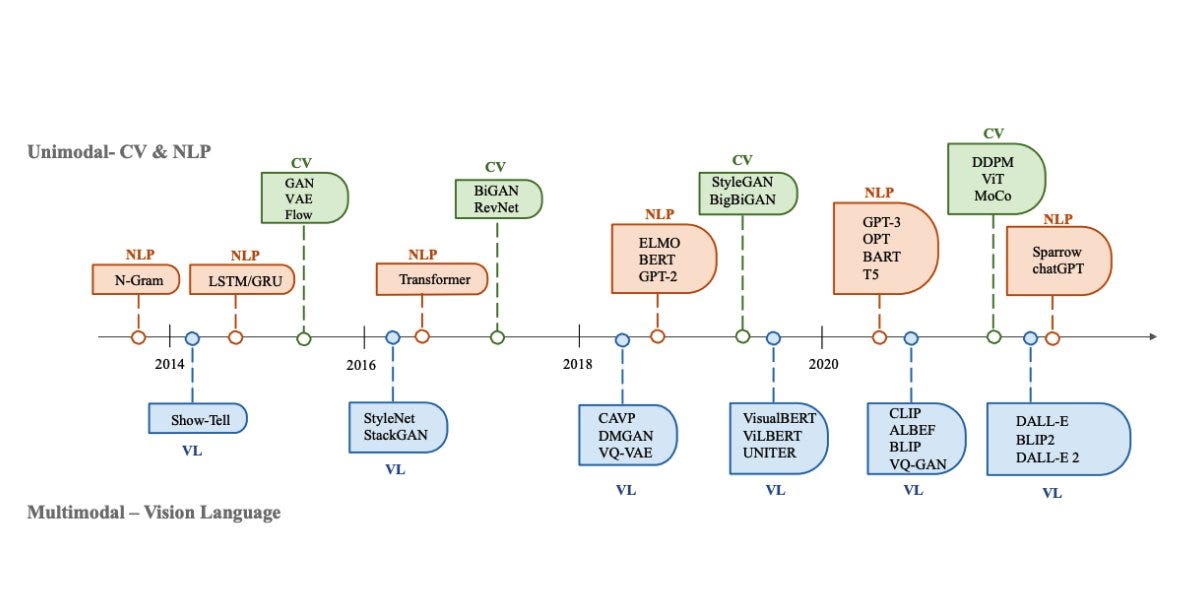
The last decade has witnessed an experimental revolution in data science and machine learning, epitomised by deep learning methods. Indeed, many high-dimensional learning tasks previously thought to be beyond reach -- such as computer vision, playing Go, or protein folding -- are in fact feasible with appropriate computational scale. Remarkably, the essence of deep learning is built from two simple algorithmic principles: first, the notion of representation or feature learning, whereby adapted, often hierarchical, features capture the appropriate notion of regularity for each task, and second, learning by local gradient-descent type methods, typically implemented as backpropagation. While learning generic functions in high dimensions is a cursed estimation problem, most tasks of interest are not generic, and come with essential pre-defined regularities arising from the underlying low-dimensionality and structure of the physical world. This text is concerned with exposing these regularities through unified geometric principles that can be applied throughout a wide spectrum of applications. Such a 'geometric unification' endeavour, in the spirit of Felix Klein's Erlangen Program, serves a dual purpose: on one hand, it provides a common mathematical framework to study the most successful neural network architectures, such as CNNs, RNNs, GNNs, and Transformers. On the other hand, it gives a constructive procedure to incorporate prior physical knowledge into neural architectures and provide principled way to build future architectures yet to be invented.
Memory latency, bandwidth, capacity, and energy increasingly limit performance. In this paper, we reconsider proposed system architectures that consist of huge (many-terabyte to petabyte scale) memories shared among large numbers of CPUs. We argue two practical engineering challenges, scaling and signaling, limit such designs. We propose the opposite approach. Rather than create large, shared, homogenous memories, systems explicitly break memory up into smaller slices more tightly coupled with compute elements. Leveraging advances in 2.5D/3D integration, this compute-memory node provisions private local memory, enabling accesses of node-exclusive data through micrometer-scale distances, and dramatically reduced access cost. In-package memory elements support shared state within a processor, providing far better bandwidth and energy-efficiency than DRAM, which is used as main memory for large working sets and cold data. Hardware making memory capacities and distances explicit allows software to efficiently compose this hierarchy, managing data placement and movement.
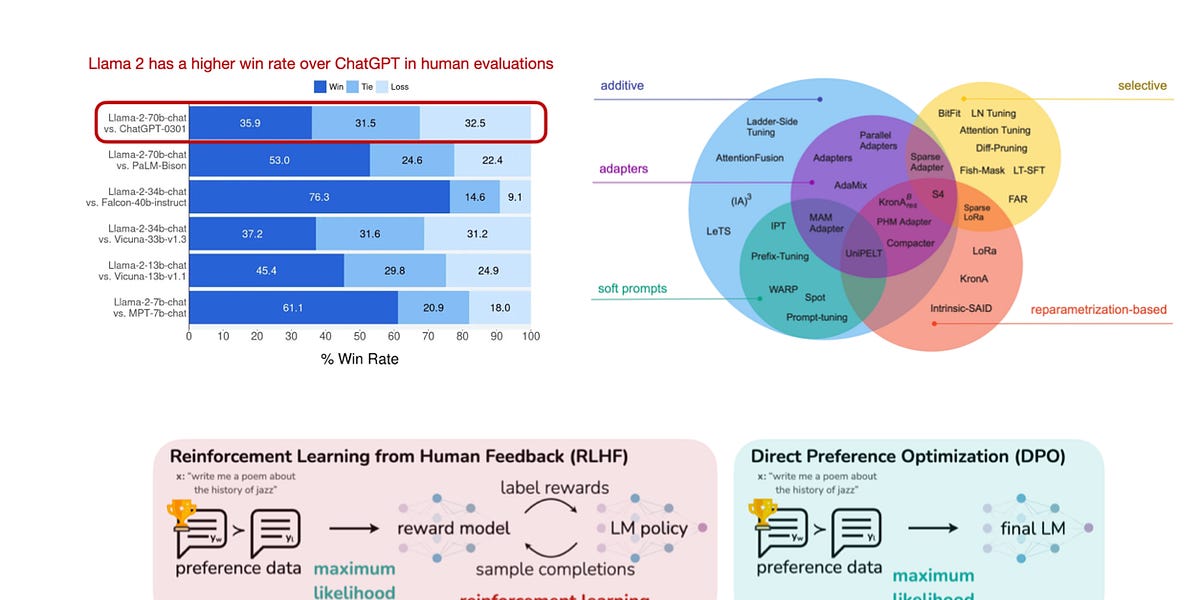
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency. HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes. Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities. These results underscore HRM's potential as a transformative advancement toward universal computation and general-purpose reasoning systems.

The latest in LLM research with a hand-curated, topic-organized list of over 200 research papers from 2025.

Our paper, Beyond Human Intervention: Algorithmic Collusion through Multi-Agent Learning Strategies, with Suzie Grondin and Philipp Ratz is now available online Collusion in market pricing is a concept associated with human actions to raise market prices through artificially limited supply. Recently, the idea of algorithmic collusion was put forward, where the human action in the … Continue reading Beyond Human Intervention: Algorithmic Collusion through Multi-Agent Learning Strategies →
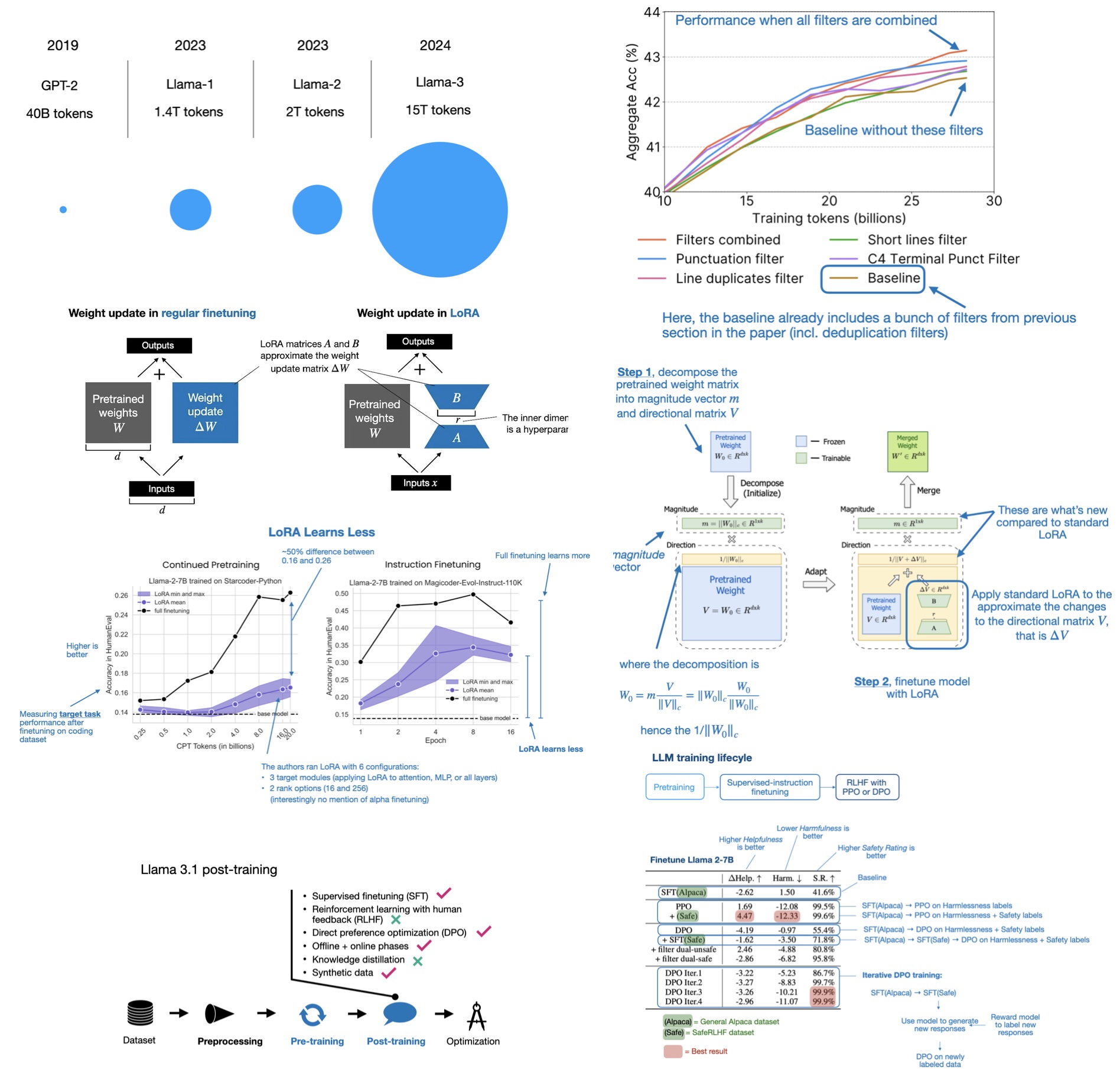
This article covers 12 influential AI research papers of 2024, ranging from mixture-of-experts models to new LLM scaling laws for precision..

We picked 50 paper/models/blogs across 10 fields in AI Eng: LLMs, Benchmarks, Prompting, RAG, Agents, CodeGen, Vision, Voice, Diffusion, Finetuning. If you're starting from scratch, start here.
A comprehensive list of some of the most impactful generative papers from last year

A long reading list of evals papers with recommendations and comments by the evals team.

A curated list of interesting LLM-related research papers from 2024, shared for those looking for something to read over the holidays.
Notes from the Latent Space paper club. Follow along or start your own! - eugeneyan/llm-paper-notes

Your ultimate Paper Club Starter Kit, from your friends at the Latent Space Paper Club, where we have now read 100 papers. Also: Announcing Latent Space Paper Club LIVE! at Neurips 2024! Join us!
9 October 2024, Mathias Parisot, Jakub Zavrel.Even in the red hot global race for AI dominance, you publish and you perish, unless your peers pick up your work, build further on it, and you manage to drive real progress in the field. And of course, we are all very curious who is currently having that kind of impact. Are the billions of dollars spent on AI R&D paying off in the long run? So here is, in continuation of our popular publication impact analysis of last year, Zeta Alpha's ranking of t
Aman's AI Journal | Course notes and learning material for Artificial Intelligence and Deep Learning Stanford classes.
The linear representation hypothesis is the informal idea that semantic concepts are encoded as linear directions in the representation spaces of large language models (LLMs). Previous work has...
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a...
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results...
In-Memory Computing (IMC) introduces a new paradigm of computation that offers high efficiency in terms of latency and power consumption for AI accelerators. However, the non-idealities and...
Discussing AI Research Papers in March 2024
This year has felt distinctly different. I've been working in, on, and with machine learning and AI for over a decade, yet I can't recall a time when these fields were as popular and rapidly evolving as they have been this year. To conclude an eventful 2023 in machine learning and AI research, I'm excited to share 10 noteworthy papers I've read this year. My personal focus has been more on large language models, so you'll find a heavier emphasis on large language model (LLM) papers than computer vision papers this year.
In the past few years we have seen the meteoric appearance of dozens of foundation models of the Transformer family, all of which have memorable and sometimes funny, but not self-explanatory,...
Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific...
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of...
Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high...
The widespread public deployment of large language models (LLMs) in recent months has prompted a wave of new attention and engagement from advocates, policymakers, and scholars from many fields....
Chain-of-Thought (CoT) prompting can effectively elicit complex multi-step reasoning from Large Language Models~(LLMs). For example, by simply adding CoT instruction ``Let's think step-by-step''...
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and...

These curated papers would step up your machine-learning knowledge.

Who Is publishing the most Impactful AI research right now? With the breakneck pace of innovation in AI, it is crucial to pick up some signal as soon as possible. No one has the time to read everything, but these 100 papers are sure to bend the road as to where our AI technology is going. The real test of impact of R&D teams is of course how the technology appears in products, and OpenAI shook the world by releasing ChatGPT at the end of November 2022, following fast on their March 2022 paper “T
The top ML Papers of the Week (Mar 6 - Mar 12)
Music recommender systems are an integral part of our daily life. Recent research has seen a significant effort around black-box recommender based approaches such as Deep Reinforcement Learning...
Over the past three years Pinterest has experimented with several visual search and recommendation services, including Related Pins (2014), Similar Looks (2015), Flashlight (2016) and Lens (2017)....
Denizens of Silicon Valley have called Moore's Law "the most important graph in human history," and economists have found that Moore's Law-powered I.T. revolution has been one of the most...
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30...
The final goal of all industrial machine learning (ML) projects is to develop ML products and rapidly bring them into production. However, it is highly challenging to automate and operationalize...
We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board...

The researchers are considered a key to the company’s future. But they have had a hard time shaking infighting and controversy over a variety of issues.
We describe the new field of mathematical analysis of deep learning. This field emerged around a list of research questions that were not answered within the classical framework of learning...
Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets...

Runaway success and underfunding have led to growing pains for the preprint server
A curated list of the latest breakthroughs in AI (in 2021) by release date with a clear video explanation, link to a more in-depth article, and code. - louisfb01/best_AI_papers_2021
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental...