hbm

Google published a research blog post on Tuesday about a new compression algorithm for AI models. Within hours, memory stocks were falling. Micron dropped 3 per cent, Western Digital ...
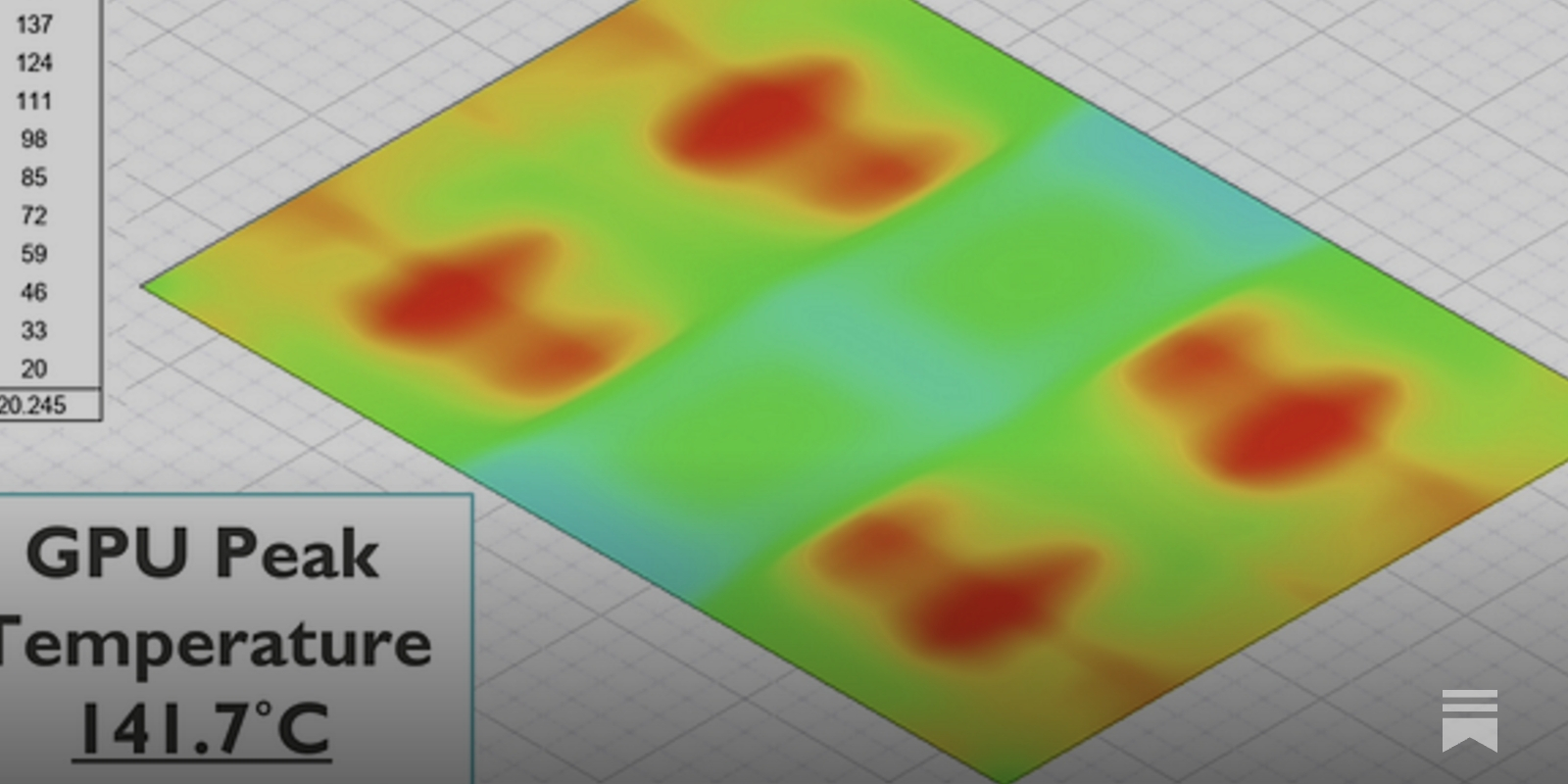
Future AI Accelerators Might Need To Be Slower To Be Faster

Bump technologies are being pushed beyond what was thought to be their physical and performance limits.

Nvidia announced the Rubin CPX, a solution that is specifically designed to be optimized for the prefill phase, with the single-die Rubin CPX heavily emphasizing compute FLOPS over memory bandwidth…

Timing is increasingly dependent on vectors. Can static techniques continue to deliver the necessary results? Maybe.

NVIDIA has surprisingly unveiled a rather 'new class' of AI GPUs, featuring the Rubin CPX AI chip that offers immense inferencing power.

A new technical paper titled “On the Thermal Vulnerability of 3D-Stacked High-Bandwidth Memory Architectures” was published by researchers at North Carolina A&T State University and New Mexico State University. Abstract “3D-stacked High Bandwidth Memory (HBM) architectures provide high-performance memory interactions to address the well-known performance challenge, namely the memory wall. However, these architectures are susceptible... » read more
Memory latency, bandwidth, capacity, and energy increasingly limit performance. In this paper, we reconsider proposed system architectures that consist of huge (many-terabyte to petabyte scale) memories shared among large numbers of CPUs. We argue two practical engineering challenges, scaling and signaling, limit such designs. We propose the opposite approach. Rather than create large, shared, homogenous memories, systems explicitly break memory up into smaller slices more tightly coupled with compute elements. Leveraging advances in 2.5D/3D integration, this compute-memory node provisions private local memory, enabling accesses of node-exclusive data through micrometer-scale distances, and dramatically reduced access cost. In-package memory elements support shared state within a processor, providing far better bandwidth and energy-efficiency than DRAM, which is used as main memory for large working sets and cold data. Hardware making memory capacities and distances explicit allows software to efficiently compose this hierarchy, managing data placement and movement.
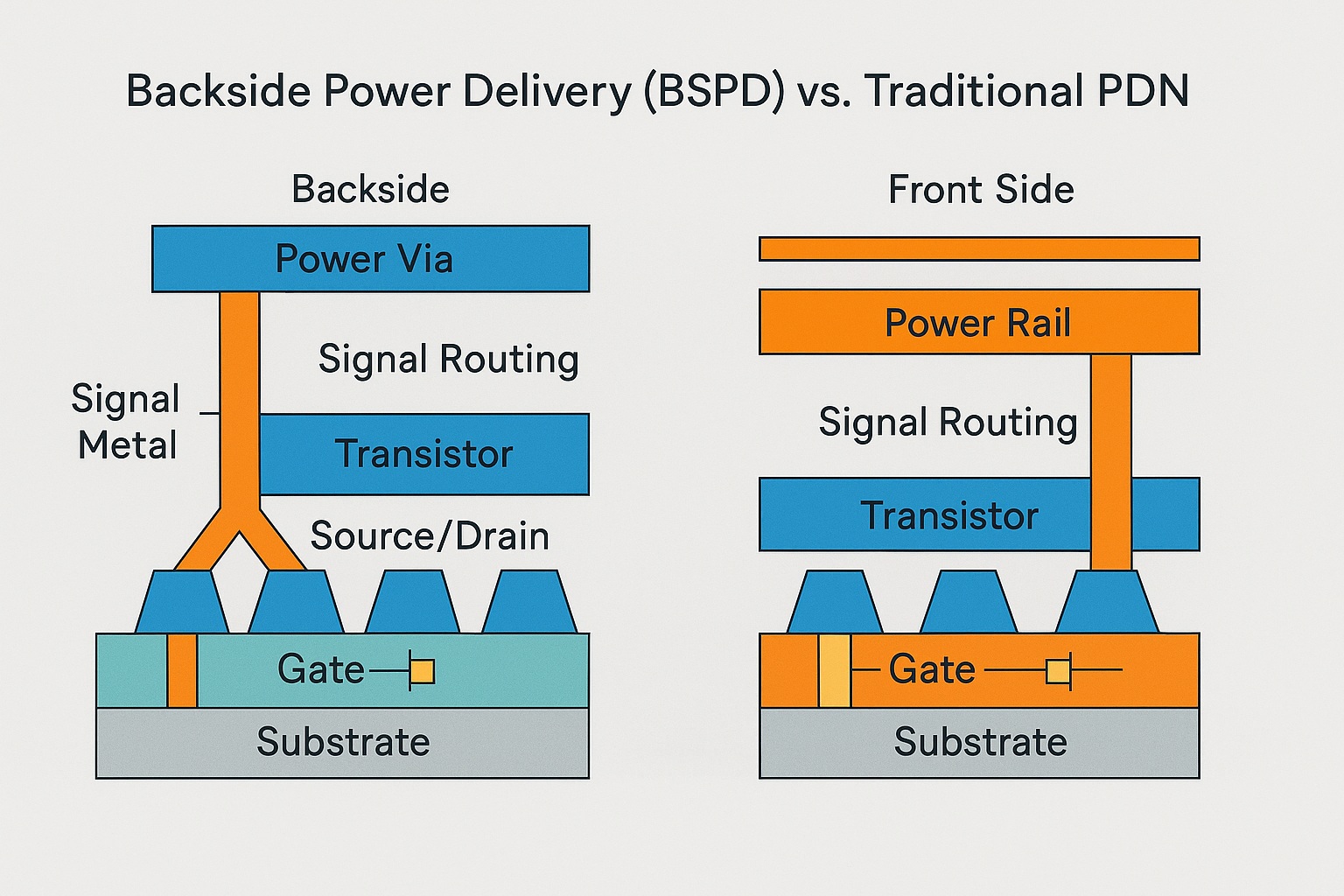
Backside Power Delivery (BSPD), also called Backside Power Delivery Network (BSPDN) or backside power via (BPV) technology, is a semiconductor manufacturing innovation in which the chip’s primary power distribution network … Continue reading "Backside Power Delivery (BSPD) Wiki"

NVIDIA has provided an in-depth look at its fastest chip for AI, the Blackwell GB300, which is 50% faster than GB200 & packs 288 GB memory.

Generative AI is arguably the most complex application that humankind has ever created, and the math behind it is incredibly complex even if the results

Thin lines and limited ground planes keep RDL interconnects short.

Four more HBM generations have been outlined by KAIST and its Terabyte Interconnection and Package Laboratory research group.


A slide deck revealing the plans (and expectations) for next-generation High Bandwidth Memory (HBM) technology was published by Korea Advanced Institute of Science and Technology and TERA (Terabyte Interconnection and Package Laboratory). Starting with HBM4. This will be the go-to standard for next-gen data centers and AI GPUs that are launching in 2026. Both AMD and NVIDIA have confirmed the use of HBM for their MI400 and Rubin offerings. Next-gen memory will continue to scale in stacked layers, but each layer will become thinner. HBM thickness is expected not to exceed 720 micrometers, with HBM5 targeting 36µm per DRAM die. Given the increase in power consumption, KAIST and TERA expect that HBM5 (100W) and HBM6 (120W) will already require immersion cooling, while HBM7 (160W) and HBM8 (180W) could feature embedded cooling solutions. With the arrival of glass-based silicon interposers, the research firm highlights the use of embedded cooling as the standard approach, which will go through the interposer and offer direct-cooling to the HBM, HBF, and GPU IPs. Read more by Wccftech: https://lnkd.in/d--5qUwx #HBM #HighBandwidthMemory #Semiconductors #AdvancedPackaging #MemoryTechnology #AIHardware #GPU #ChipDesign #ImmersionCooling #ThermalManagement #TechInnovation #FutureOfComputing #NVIDIA #AMD #HighPerformanceComputing #DeepTech #DataCenterTechnology #KAIST #KoreaTech #TERA | 15 comments on LinkedIn

Many features of UCIe 2.0 seen as “heavy” are optional, causing confusion.

TSMC also revealed developments in advanced packaging technologies at the NA Technology Symposium, and they look interesting.

High-end xPUs (GPUs, TPUs, and other AI processors) use HBM memories to get the absolute highest memory bandwidth for training the Large Language Models (LLMs) used in today's generative AI systems. These processors, used in the thousands by hyperscale datacenters, can consume a kilowatt each. As a result, they must dissipate a phenomenal quantity of

The Future of AI Accelerators: A Roadmap of Industry Leaders The AI hardware race is heating up, with major players like NVIDIA, AMD, Intel, Google, Amazon, and more unveiling their upcoming AI accelerators. Here’s a quick breakdown of the latest trends: Key Takeaways: NVIDIA Dominance: NVIDIA continues to lead with a robust roadmap, extending from H100 to future Rubin and Rubin Ultra chips with HBM4 memory by 2026-2027. AMD’s Competitive Push: AMD’s MI300 series is already competing, with MI350 and future MI400 models on the horizon. Intel’s AI Ambitions: Gaudi accelerators are growing, with Falcon Shores on track for a major memory upgrade. Google & Amazon’s Custom Chips: Google’s TPU lineup expands rapidly, while Amazon’s Trainium & Inferentia gain traction. Microsoft & Meta’s AI Expansion: Both companies are pushing their AI chip strategies with Maia and MTIA projects, respectively. Broadcom & ByteDance Join the Race: New challengers are emerging, signaling increased competition in AI hardware. What This Means: With the growing demand for AI and LLMs, companies are racing to deliver high-performance AI accelerators with advanced HBM (High Bandwidth Memory) configurations. The next few years will be crucial in shaping the AI infrastructure landscape. $NVDA $AMD $INTC $GOOGL $AMZN $META $AVGO $ASML $BESI
It is often said that companies – particularly large companies with enormous IT budgets – do not buy products, they buy roadmaps. No one wants to go to

By 2030, leading AI labs will need data centers so massive they will require the power equivalent of some of America’s largest cities. Will they be able to find it?

AMD acquired ATI in 2006, hoping ATI's GPU expertise would combine with AMD's CPU know-how to create integrated solutions worth more than the sum of their parts.

Discover how SK hynix’s switch to the advanced 6-phase RDQS scheme helped create the world’s best-performing HBM3E with enhanced capacity and reliability.

Lumai's breakthrough in AI acceleration with free-space optics promises energy cuts and faster processing.

It hasn’t achieved commercial success, but there is still plenty of development happening; analog IMC is getting a second chance.
No matter how elegant and clever the design is for a compute engine, the difficulty and cost of moving existing – and sometimes very old – code from the
According to rumors, Nvidia is not expected to deliver optical interconnects for its GPU memory-lashing NVLink protocol until the “Rubin Ultra” GPU

As awareness of environmental, social, and governance (ESG) issues grows, companies are adopting strategies for sustainable operations.
According to rumors, Nvidia is not expected to deliver optical interconnects for its GPU memory-lashing NVLink protocol until the “Rubin Ultra” GPU

Foundry competition heats up in three dimensions and with novel technologies as planar scaling benefits diminish.

Attention, as a core layer of the ubiquitous Transformer architecture, is a bottleneck for large language models and long-context applications. FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is now used by most libraries to accelerate Transformer training and inference. This has contributed to a massive increase in LLM context length in the last two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), or even 1M (Llama 3). However, despite its success, FlashAttention has yet to take advantage of new capabilities in modern hardware, with FlashAttention-2 achieving only 35% utilization of theoretical max FLOPs on the H100 GPU. In this blogpost, we describe three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for FP8 low-precision.

HBM4 is going to double the bandwidth of HBM3, but not through the usual increase in clock rate.
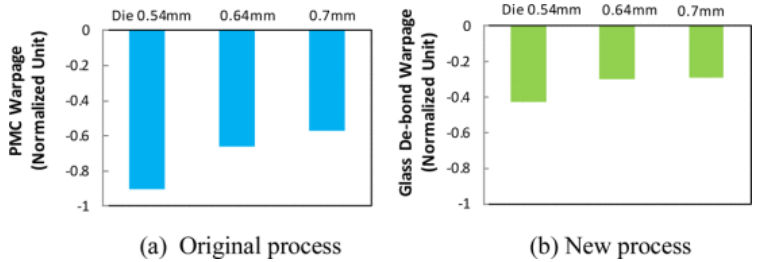
Mechanical stresses increase with larger sizes and heterogeneous materials.

Generative AI and High Bandwidth Memory (HBM) fuel DRAM market growth. OUTLINE The HBM market has the potential to grow to US$14 billion in 2024. Yole Group expects HBM revenue growth to continue with a CAGR23-29 of ~38%, reaching about US$37.7 billion in 2029. 4F2 cell designs, hybrid bonding, and monolithic 3D DRAM will enable […]

Tech makes millions of connections in a square millimeter of silicon

Demand for high-bandwidth memory is driving competition -- and prices -- higher

Rambus has unveiled its next-gen GDDR7 memory controller IP, featuring PAM3 Signaling, and up to 48 Gbps transfer speeds.
While a lot of people focus on the floating point and integer processing architectures of various kinds of compute engines, we are spending more and more

The SemiAnalysis AI accelerator model is used to gauge historical and future accelerator production by company and type.

Explore HBM3E and GDDR6 memory capabilities, including the benefits and design considerations for each

Startup Groq has developed an machine learning processor that it claims blows GPUs away in large language model workloads – 10x faster than an Nvidia GPU at 10 percent of the cost, and needing a tenth of the electricity. Update: Groq model compilation time and time from access to getting it up and running clarified. […]

Machine learning is the study and application of algorithms that learn from and make predictions on data. From search results to self-driving cars, it has manifested itself in all areas of our lives and is one of the most exciting and fast-growing fields of research in the world of data science. The caret package, maintained by Max Kuhn, is the go-to package in the R community for predictive modeling and supervised learning. This widely used package provides a consistent interface to all of R's most powerful machine learning facilities. Need some more convincing? In this post, we explore 3 reasons why you should learn the caret package. Afterward, you can take DataCamp's Machine Learning Toolbox course taught by Zachary Deane-Mayer & Max Kuhn, co-authors of the caret package! 1. It can help you get a data science job Ever read through data science job postings and see words like "predictive modeling", "classification", "regression," or "machine learning"? Chances are if you are seeking a data science position, you will be expected to have experience and knowledge about all of these topics. Luckily, the caret package has you covered. The caret package is known as the "Swiss Army Knife" for machine learning with R; capable of performing many tasks with an intuitive, consistent format. Check out these recent data scientist job postings from Kaggle which are all seeking candidates with knowledge of R and machine learning: Data Scientist Analytics at Booking.com Data Scientist at Amazon.com Data Scientist at CVS Health 2. It's one of the most popular R packages The caret package receives over 38,000 direct downloads monthly making it one of the most popular packages in the R community. With that comes significant benefits including an abundant amount of documentation and helpful tutorials. You can install the Rdocumentation package to access helpful documentation and community examples directly in your R console. Simply copy and paste the following code: # Install and load RDocumentation for comprehensive help with R packages and functions install.packages("RDocumentation") library("RDocumentation") Of course, another benefit of learning a widely used package is that your colleagues are also likely using caret in their work - meaning you can collaborate on projects more easily. Additionally, caret is a dependent package for a large amount of additional machine learning and modeling packages as well. Understanding how caret works will make it easier and more fluid to learn even more helpful R packages. 3. It's easy to learn, but very powerful If you are a beginner R user, the caret package provides an easy interface for performing complex tasks. For example, you can train multiple different types of models with one easy, convenient format. You can also monitor various combinations of parameters and evaluate performance to understand their impact on the model you are trying to build. Additionally, the caret package helps you decide the most suitable model by comparing their accuracy and performance for a specific problem. Complete the code challenge below to see just how easy it is to to build models and predict values with caret. We've already gone ahead and split the mtcars dataset into a training set, train, and a test set,test. Both of these objects are available in the console. Your goal is to predict the miles per gallon of each car in the test dataset based on their weight. See for yourself how the caret package can handle this task with just two lines of code! eyJsYW5ndWFnZSI6InIiLCJwcmVfZXhlcmNpc2VfY29kZSI6IiAgICAgICAgIyBMb2FkIGNhcmV0IHBhY2thZ2VcbiAgICAgICAgICBsaWJyYXJ5KGNhcmV0KVxuICAgICAgICAjIHNldCBzZWVkIGZvciByZXByb2R1Y2libGUgcmVzdWx0c1xuICAgICAgICAgIHNldC5zZWVkKDExKVxuICAgICAgICAjIERldGVybWluZSByb3cgdG8gc3BsaXQgb246IHNwbGl0XG4gICAgICAgICAgc3BsaXQgPC0gcm91bmQobnJvdyhtdGNhcnMpICogLjgwKVxuXG4gICAgICAgICMgQ3JlYXRlIHRyYWluXG4gICAgICAgICAgdHJhaW4gPC0gbXRjYXJzWzE6c3BsaXQsIF1cblxuICAgICAgICAjIENyZWF0ZSB0ZXN0XG4gICAgICAgICAgdGVzdCA8LSBtdGNhcnNbKHNwbGl0ICsgMSk6bnJvdyhtdGNhcnMpLCBdIiwic2FtcGxlIjoiIyBGaW5pc2ggdGhlIG1vZGVsIGJ5IHJlcGxhY2luZyB0aGUgYmxhbmsgd2l0aCB0aGUgYHRyYWluYCBvYmplY3Rcbm10Y2Fyc19tb2RlbCA8LSB0cmFpbihtcGcgfiB3dCwgZGF0YSA9IF9fXywgbWV0aG9kID0gXCJsbVwiKVxuXG4jIFByZWRpY3QgdGhlIG1wZyBvZiBlYWNoIGNhciBieSByZXBsYWNpbmcgdGhlIGJsYW5rIHdpdGggdGhlIGB0ZXN0YCBvYmplY3RcbnJlc3VsdHMgPC0gcHJlZGljdChtdGNhcnNfbW9kZWwsIG5ld2RhdGEgPSBfX18pXG4gICAgICAgXG4jIFByaW50IHRoZSBgcmVzdWx0c2Agb2JqZWN0XG5yZXN1bHRzIiwic29sdXRpb24iOiIjIEZpbmlzaCB0aGUgbW9kZWwgYnkgcmVwbGFjaW5nIHRoZSBibGFuayB3aXRoIHRoZSBgdHJhaW5gIG9iamVjdFxubXRjYXJzX21vZGVsIDwtIHRyYWluKG1wZyB+IHd0LCBkYXRhID0gdHJhaW4sIG1ldGhvZCA9IFwibG1cIilcblxuIyBQcmVkaWN0IHRoZSBtcGcgb2YgZWFjaCBjYXIgYnkgcmVwbGFjaW5nIHRoZSBibGFuayB3aXRoIHRoZSBgdGVzdGAgb2JqZWN0XG5yZXN1bHRzIDwtIHByZWRpY3QobXRjYXJzX21vZGVsLCBuZXdkYXRhID0gdGVzdClcbiAgICAgICBcbiMgUHJpbnQgdGhlIGByZXN1bHRzYCBvYmplY3RcbnJlc3VsdHMiLCJzY3QiOiJ0ZXN0X2V4cHJlc3Npb25fb3V0cHV0KFwibXRjYXJzX21vZGVsXCIsIGluY29ycmVjdF9tc2cgPSBcIlRoZXJlJ3Mgc29tZXRoaW5nIHdyb25nIHdpdGggYG10Y2Fyc19tb2RlbGAuIEhhdmUgeW91IHNwZWNpZmllZCB0aGUgcmlnaHQgZm9ybXVsYSB1c2luZyB0aGUgYHRyYWluYCBkYXRhc2V0P1wiKVxuXG50ZXN0X2V4cHJlc3Npb25fb3V0cHV0KFwicmVzdWx0c1wiLCBpbmNvcnJlY3RfbXNnID0gXCJUaGVyZSdzIHNvbWV0aGluZyB3cm9uZyB3aXRoIGByZXN1bHRzYC4gSGF2ZSB5b3Ugc3BlY2lmaWVkIHRoZSByaWdodCBmb3JtdWxhIHVzaW5nIHRoZSBgcHJlZGljdCgpYCBmdW5jdGlvbiBhbmQgdGhlIGB0ZXN0YCBkYXRhc2V0P1wiKVxuXG5zdWNjZXNzX21zZyhcIkNvcnJlY3Q6IFNlZSBob3cgZWFzeSB0aGUgY2FyZXQgcGFja2FnZSBjYW4gYmU/XCIpIn0= Want to learn it for yourself? You're in luck! DataCamp just released a brand new Machine Learning Toolbox course. The course is taught by co-authors of the caret package, Max Kuhn and Zachary Deane-Mayer. You'll be learning directly from the people who wrote the package through 24 videos and 88 interactive exercises. The course also includes a customer churn case study that let's you put your caret skills to the test and gain practical machine learning experience. What are you waiting for? Take the course now!

Faster than Nvidia? Dissecting the economics
Embracing emerging approaches is essential for crafting packages that address the evolving demands of sustainability, technology, and consumer preferences.

A conference schedule has revealed that Samsung's next-gen graphics memory is bonkers fast.

China's Countermove: How Beijing is Dodging New Semiconductor Restrictions

We're getting a first glimpses of Samsung's next-generation HBM3E and GDDR7 memory chips.
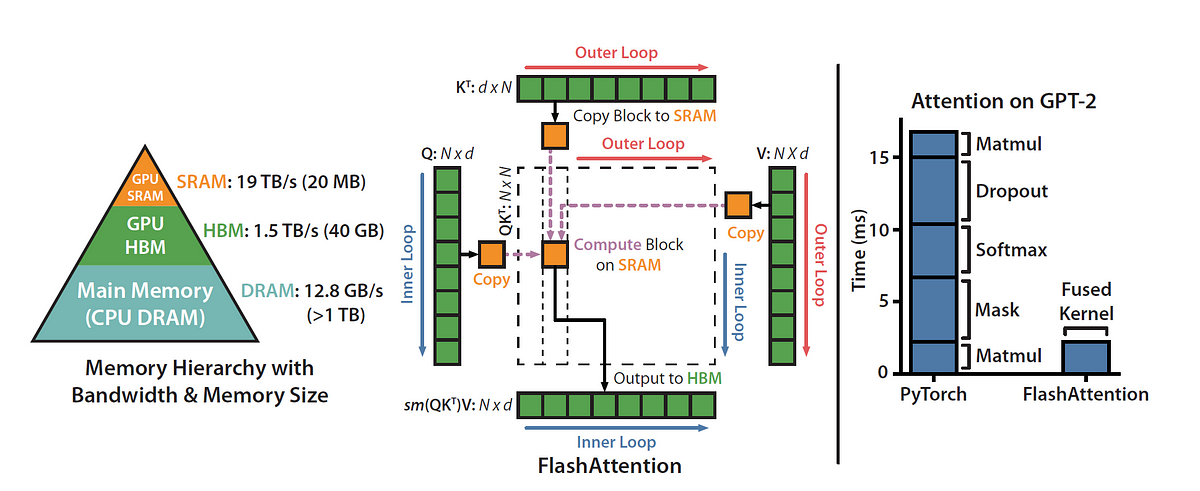
Step by step explanation of how one of the most important MLSys breakthroughs work — in gory detail.

tldr; techniques to speed up training and inference of LLMs to use large context window up to 100K input tokens during training and…

With the release of PyTorch 2.0 and ROCm 5.4, we are excited to announce that LLM training works out of the box on AMD MI250 accelerators with zero code changes and at high performance!
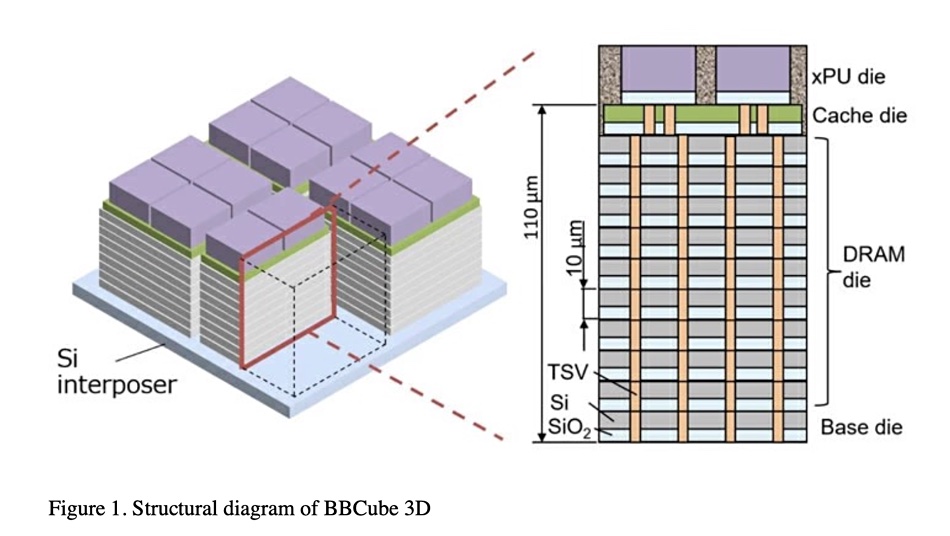
Tokyo Institute of Technology scientists have devised a 3D DRAM stack topped by a processor to provide four times more bandwidth than HBM.
Quarterly Ramp for Nvidia, Broadcom, Google, AMD, AMD Embedded (Xilinx), Amazon, Marvell, Microsoft, Alchip, Alibaba T-Head, ZTE Sanechips, Samsung, Micron, and SK Hynix

Micron $MU looks very weak in AI

We asked memory semiconductor industry analyst Jim Handy of Objective Analysis how he views 3D DRAM technology.
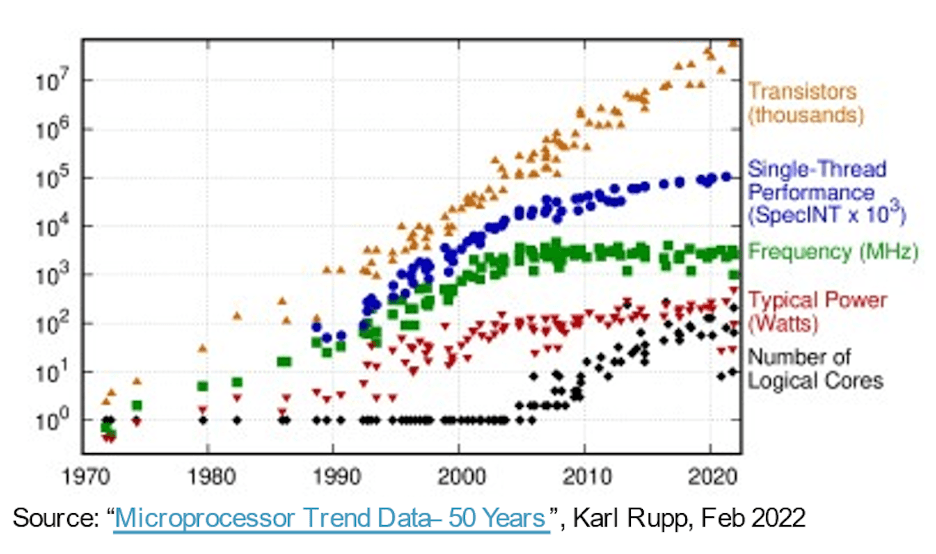
In the march to more capable, faster, smaller, and lower…
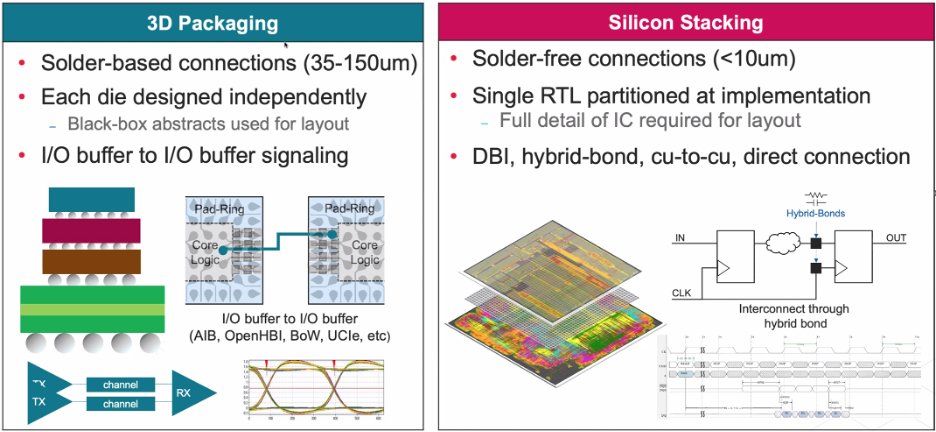
While terms often are used interchangeably, they are very different technologies with different challenges.
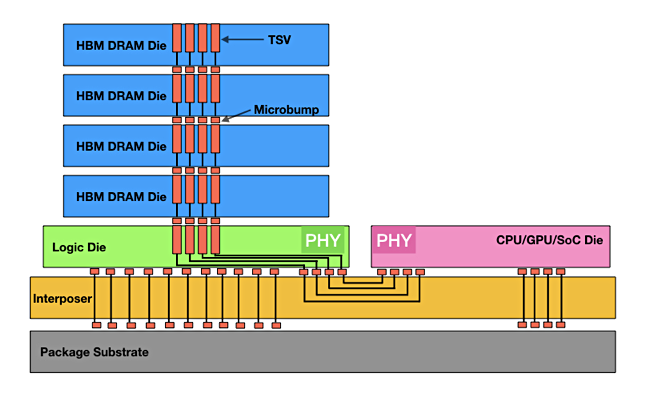
New applications require a deep understanding of the tradeoffs for different types of DRAM.
List of awesome open source hardware tools, generators, and reusable designs - aolofsson/awesome-opensource-hardware
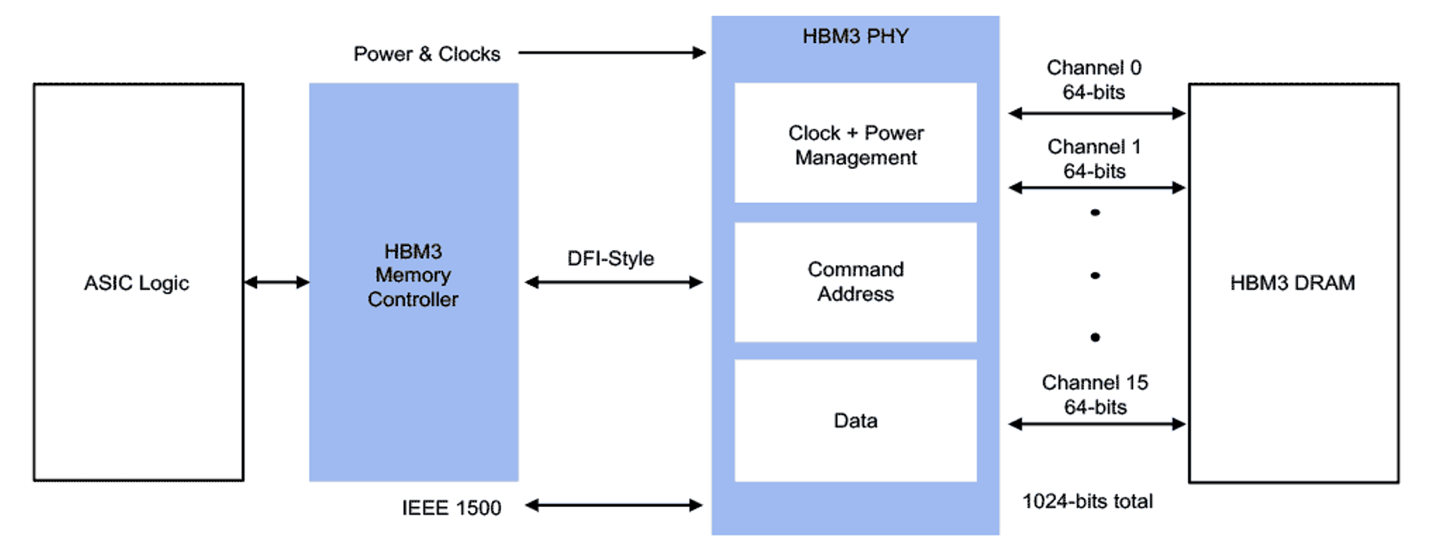
Changes are steady in the memory hierarchy, but how and where that memory is accessed is having a big impact.

Playing with reality

It's not clear when this mysterious memory will arrive, but SK Hynix is certainly talking a big game.

Increased transistor density and utilization are creating memory performance issues.

Let's learn more about the world's most important manufactured product. Meaningful insight, timely analysis, and an occasional investment idea.
There are two types of packaging that represent the future of computing, and both will have validity in certain domains: Wafer scale integration and

Google did its best to impress this week at its annual IO conference. While Google rolled out a bunch of benchmarks that were run on its current Cloud TPU

Explore Synopsys Blog for the latest insights and trends in EDA, IP, and Systems Design. Stay updated with expert articles and industry news.
This is a list of interface bit rates, is a measure of information transfer rates, or digital bandwidth capacity, at which digital interfaces in a computer or network can communicate over various kinds of buses and channels. The distinction can be arbitrary between a computer bus, often closer in space, and larger telecommunications networks. Many device interfaces or protocols (e.g., SATA, USB, SAS, PCIe) are used both inside many-device boxes, such as a PC, and one-device-boxes, such as a hard drive enclosure. Accordingly, this page lists both the internal ribbon and external communications cable standards together in one sortable table.

Experts at the Table: Which type of DRAM is best for different applications, and why performance and power can vary so much.

Over the last two years, there has been a push for novel architectures to feed the needs of machine learning and more specifically, deep neural networks.

Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As
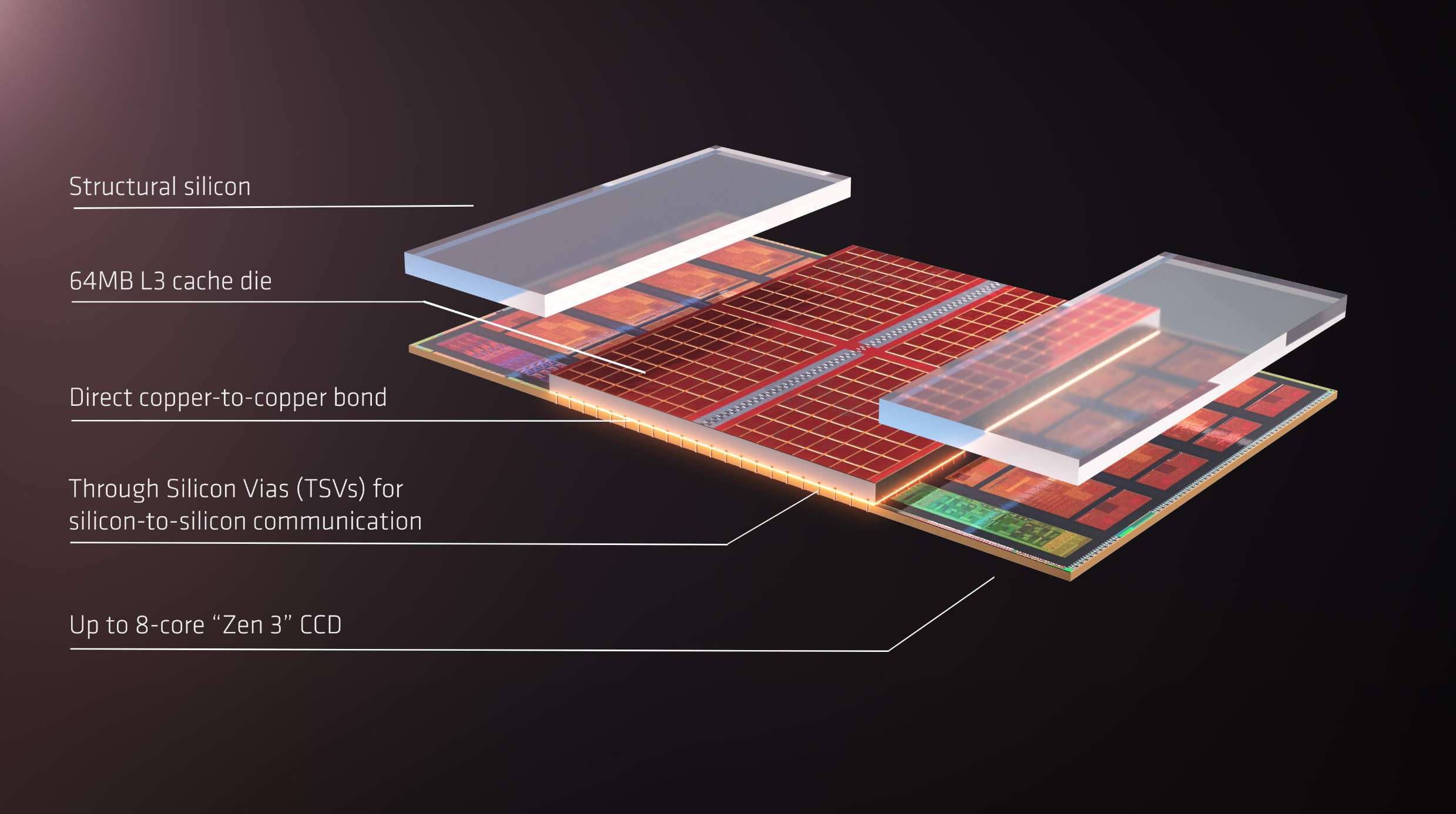
New interconnects offer speed improvements, but tradeoffs include higher cost, complexity, and new manufacturing challenges.

Sapphire Rapids, Intel's next server architecture, looks like a large leap over the just-launched Ice Lake SP.

The inception of Google’s effort to build its own AI chips is quite well known by now but in the interests of review, we’ll note that as early 2013 the

Engineers must keep pace with advanced IC packaging technology as it evolves rapidly, starting with understanding the basic terms.


China-based DRAM chipmaker ChangXin Memory Technologies (CXMT) is scaling up its 19nm chip output with better yield rates, with the monthly production likely to top 70,000 wafers by the end of 2020, according to industry sources.


TSMC details its 5-nanometer node for mobile and HPC applications. The process features the industry's highest density transistors with a high-mobility channel and highest-density SRAM cells.
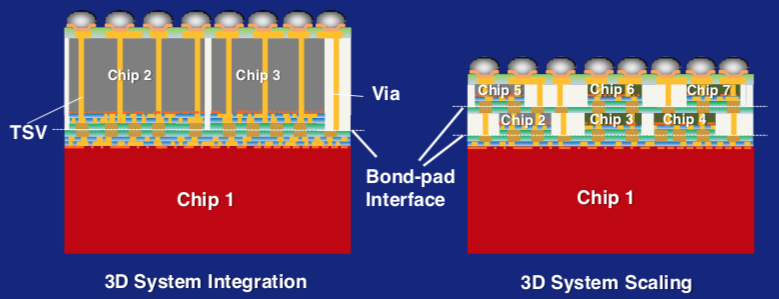
A dizzying array of choices and options pave the way for the next phase of scaling.

Why Chips Die Semiconductor devices face many hazards before and after manufacturing that can cause them to fail prematurely.

Processing In Memory Growing volume of data and limited improvements in performance create new opportunities for approaches that never got off the ground.
Google did its best to impress this week at its annual IO conference. While Google rolled out a bunch of benchmarks that were run on its current Cloud TPU

eBook: Nearly everything you need to know about memory, including detailed explanations of the different types of memory; how and where these are used today; what's changing, which memories are successful and which ones might be in the future; and the limitations of each memory type.

A new crop of applications is driving the market along some unexpected routes, in some cases bypassing the processor as the landmark for performance and