inference


Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inference

A new technical paper titled “Prefill vs. Decode Bottlenecks: SRAM-Frequency Tradeoffs and the Memory-Bandwidth Ceiling” was published by researchers at Uppsala University. Abstract “Energy consumption dictates the cost and environmental impact of deploying Large Language Models. This paper investigates the impact of on-chip SRAM size and operating frequency on the energy efficiency and performance of... » read more

What is Artificial Intelligence AI Inference? A Technical Deep Dive and Top 9 AI Inference Providers (2025 Edition)

Startup Groq has developed an machine learning processor that it claims blows GPUs away in large language model workloads – 10x faster than an Nvidia GPU at 10 percent of the cost, and needing a tenth of the electricity. Update: Groq model compilation time and time from access to getting it up and running clarified. […]

Faster than Nvidia? Dissecting the economics

Free books, lectures, blogs, papers, and more for a causal inference crash course
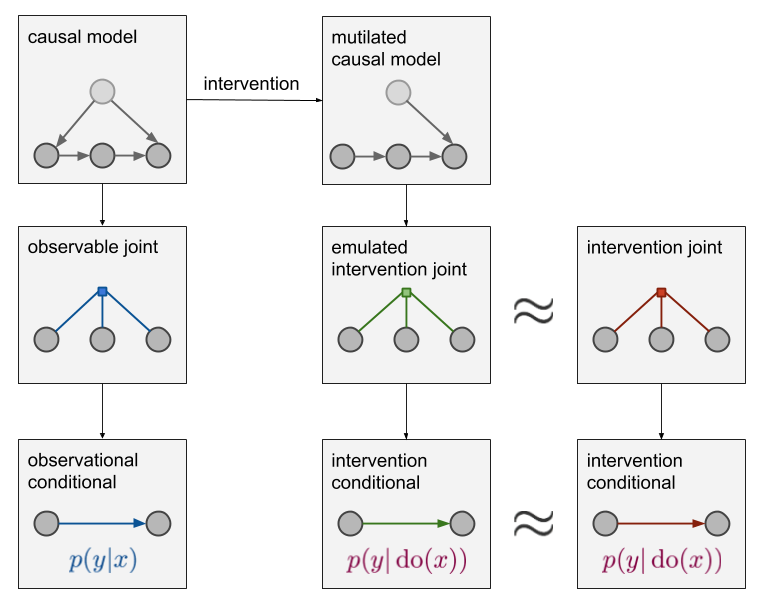
Since writing this post back in 2018, I have extended this to a 4-part series on causal inference: * ➡️️ Part 1: Intro to causal inference and do-calculus [https://www.inference.vc/untitled] * Part 2: Illustrating Interventions with a Toy Example [https://www.inference.vc/causal-inference-2-illustrating-interventions-in-a-toy-example/] * Part 3: Counterfactuals [https://www.inference.