nlp


The BAIR Blog

In this article, we discuss five cutting-edge NLP trends that will shape 2026.
💫 Industrial-strength Natural Language Processing (NLP) in Python - explosion/spaCy

The mathematician Tai-Danae Bradley is using category theory to try to understand both human and AI-generated language.
METEOR Score is a metric used to evaluate the quality of machine translation based on precision, recall, word alignment, and linguistic flexibility.
Stemming is the linguistic process of reducing words to their base form, ignoring prefixes and suffixes, to enhance clarity and information retrieval.

A Step by Step Guide to Build a Trend Finder Tool with Python: Web Scraping, NLP (Sentiment Analysis & Topic Modeling), and Word Cloud Visualization

In this article, we’ll focus on how to prepare text data for machine learning and statistical modeling using spaCy.
This is a standalone notebook implementing the popular byte pair encoding (BPE) tokenization algorithm, which is used in models like GPT-2 to GPT-4, Llama 3,...

We picked 50 paper/models/blogs across 10 fields in AI Eng: LLMs, Benchmarks, Prompting, RAG, Agents, CodeGen, Vision, Voice, Diffusion, Finetuning. If you're starting from scratch, start here.

BM25 is a widely used algorithm for full text search. I wanted to understand how it works, so here is my attempt at understanding by re-explaining.

Natural Language Processing (NLP) has rapidly evolved in the last few years, with transformers emerging as a game-changing innovation. Yet, there are still notable challenges when using NLP tools to develop applications for tasks like semantic search, question answering, or document embedding. One key issue has been the need for models that not only perform well but also work efficiently on a range of devices, especially those with limited computational resources, such as CPUs. Models tend to require substantial processing power to yield high accuracy, and this trade-off often leaves developers choosing between performance and practicality. Additionally, deploying large models

Sentiment analysis, i.e., determining the emotional tone of a text, has become a crucial tool for researchers, developers, and businesses to comprehend social media trends, consumer feedback, and other topics. With its robust library ecosystem, Python provides a vast choice of tools to improve and streamline sentiment analysis processes. Through the use of these libraries, data scientists can easily create precise sentiment models using pre-trained models and sophisticated machine learning frameworks. In this post, the top 12 Python sentiment analysis libraries have been discussed, emphasizing their salient characteristics, advantages, and uses. TextBlob A popular Python sentiment analysis toolkit, TextBlob is

As part of data preparation for an NLP model, it’s common to need to clean up your data prior to passing it into the model. If there’s unwanted content in your output, for example, it could impact the quality of your NLP model. To help with this, the `unstructured` library includes cleaning functions to help users sanitize output before sending it to downstream applications.

The inference method is crucial for NLP models in subword tokenization. Methods like BPE, WordPiece, and UnigramLM offer distinct mappings, but their performance differences must be better understood. Implementations like Huggingface Tokenizers often need to be clearer or limit inference choices, complicating compatibility with vocabulary learning algorithms. Whether a matching inference method is necessary or optimal for tokenizer vocabularies is uncertain. Previous research focused on developing vocabulary construction algorithms such as BPE, WordPiece, and UnigramLM, exploring optimal vocabulary size and multilingual vocabularies. Some studies examined the effects of vocabularies on downstream performance, information theory, and cognitive plausibility. Limited work on
A deep dive into the internals of a small transformer model to learn how it turns self-attention calculations into accurate predictions for the next token.
Aman's AI Journal | Course notes and learning material for Artificial Intelligence and Deep Learning Stanford classes.
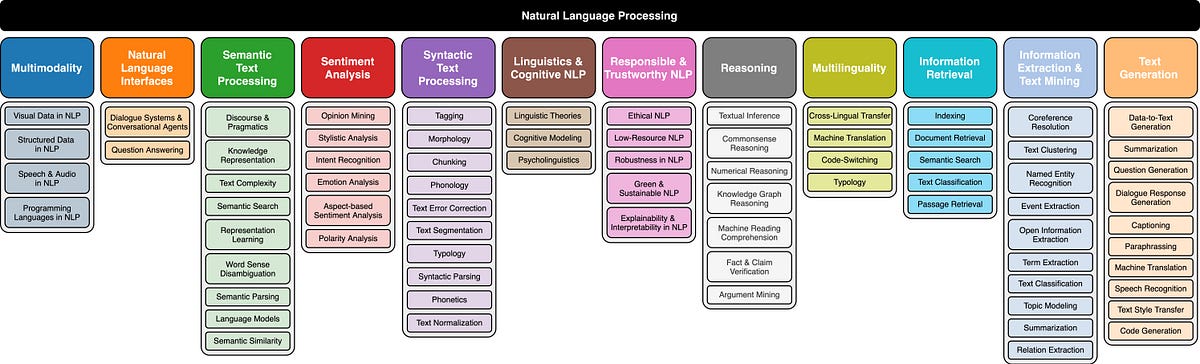
An overview of different fields of study and recent developments in NLP

Learn what vector search is and the metrics pertinent to decide the distance (or similarity) between objects.

Chat with your long PDF docs: load_qa_chain, RetrievalQA, VectorstoreIndexCreator, ConversationalRetrievalChain
I explain what is so unique about the RWKV language model.
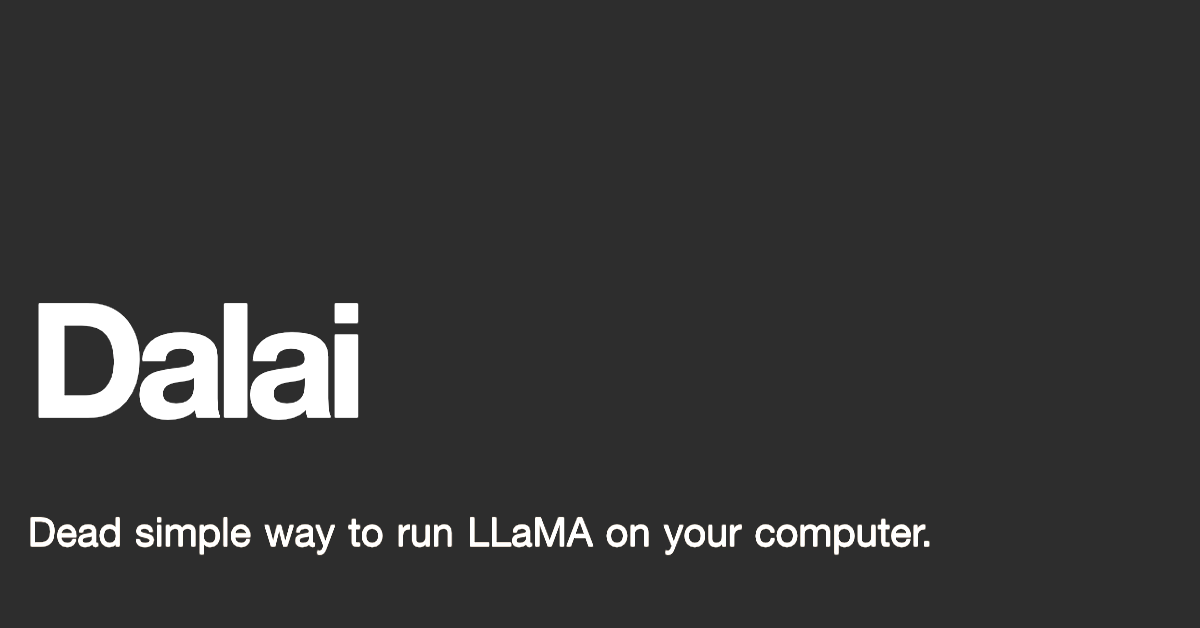
Dead simple way to run LLaMA on your computer

LLaMA-13B reportedly outperforms ChatGPT-like tech despite being 10x smaller.

I was playing around with OpenAI (GPT-3) today, building a reasonably complicated email parser for a...

The wave of enthusiasm around generative networks feels like another Imagenet moment - a step change in what ‘AI’ can do that could generalise far beyond the cool demos. What can it create, and where are the humans in the loop?

The first obvious casualty of large language models is homework: the real training for everyone, though, and the best way to leverage AI, will be in verifying and editing information.

An intuitive understanding of how AI-generated art is made by Stable Diffusion, Midjourney, or DALL-E

The intuition behind LDA and its limitations, along with python implementation using Gensim.

This collection of 5 courses is intended to help NLP practitioners or hopefuls acquire some of their lacking linguistics knowledge.

The post explains the significance of CountVectorizer and demonstrates its implementation with Python code.

Scientist Gary Marcus argues that “deep learning” is not the only path to true artificial intelligence.
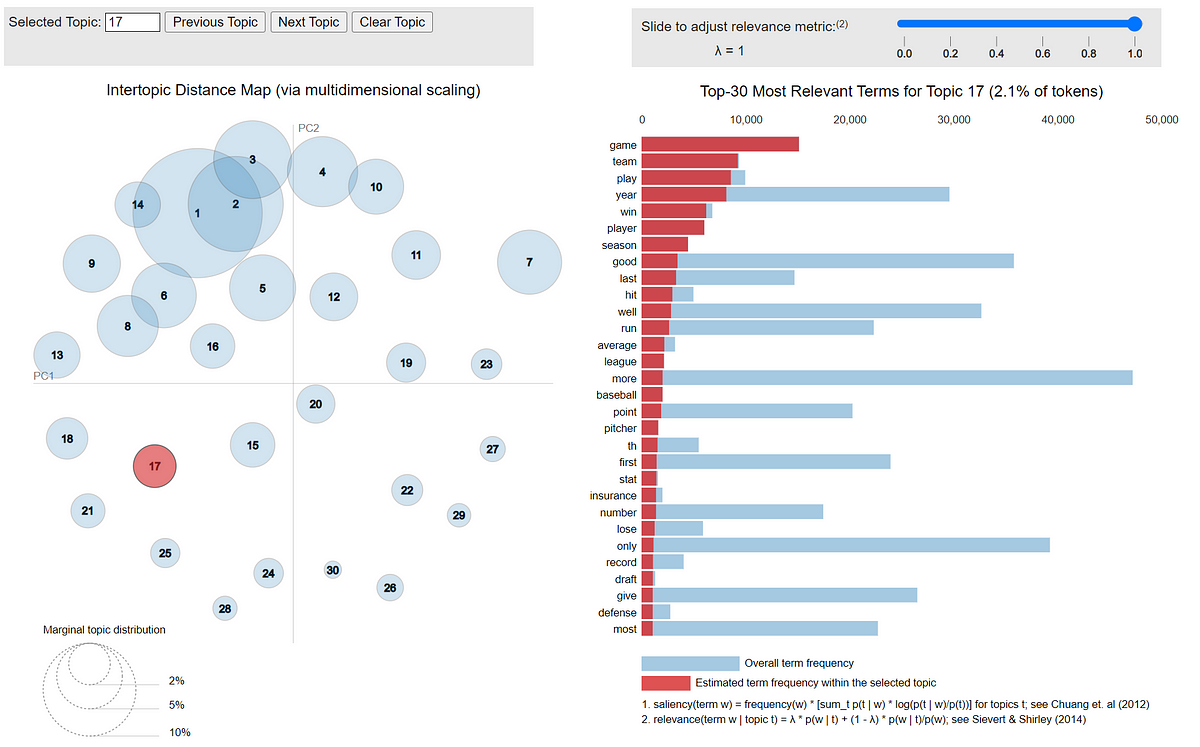
A comparison between different topic modeling strategies including practical Python examples
I’ve never used spaCy beyond simple named entity recognition tasks. Boy was I wrong.
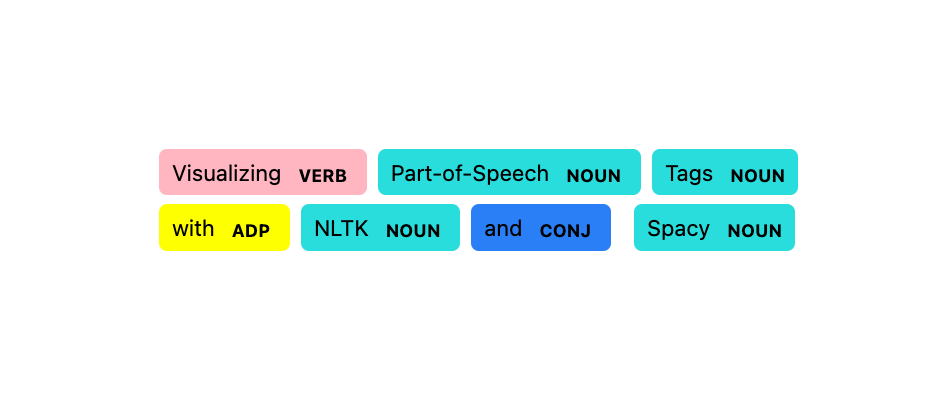
Customizing displaCy’s entity visualizer

Posted by Ethan Dyer and Guy Gur-Ari, Research Scientists, Google Research, Blueshift Team Language models have demonstrated remarkable performance...

We used GPT-3 and DALL·E to generate a children's storybook about Ash and Pikachu vs. Team Rocket. Read the story and marvel at the AI-generated visuals!

GitHub Copilot works alongside you directly in your editor, suggesting whole lines or entire functions for you.
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Share your videos with friends, family, and the world

They can help you get an appointment or order a pizza, find the best ticket deals and bring your...

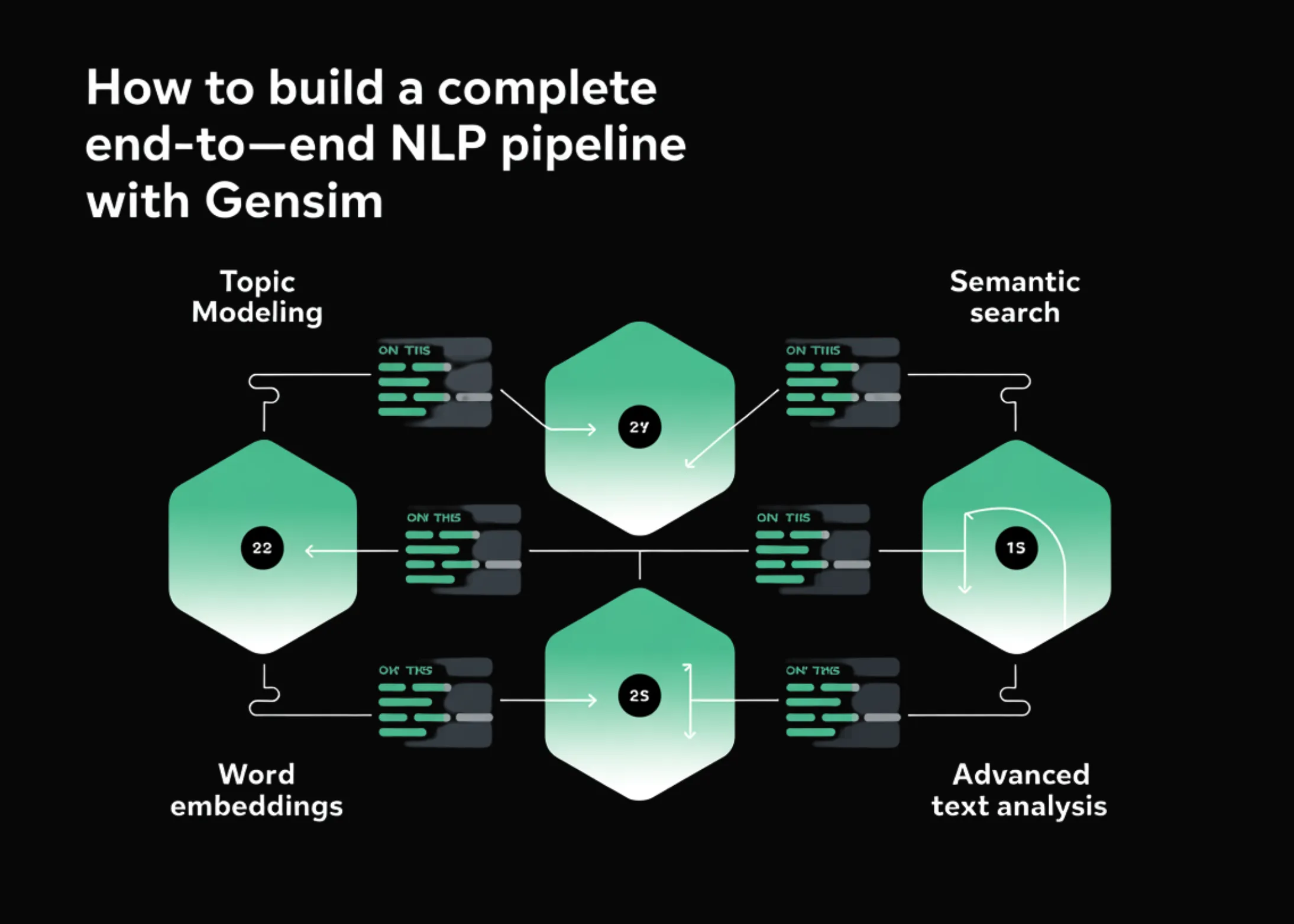
Natural Language Processing with Python, Gensim, Tensorflow, Transformers

Topic modeling can bring NLP to the next level. Here’s how.
NLP demo code, largely based on https://github.com/hundredblocks/concrete_NLP_tutorial - bjpcjp/NLP_workshop
Working files for gensim NLP tutorials.
Beginner's tour of spaCy v2.0.

In this article, I will present a tutorial on how to add labels to a dataset for sentiment analysis using Python. Adding labels to a dataset.
An end-to-end practical guide to implementing NLP applications using the Python ecosystem. 1 customer review. Instant delivery. Top rated Mobile Application Development products.
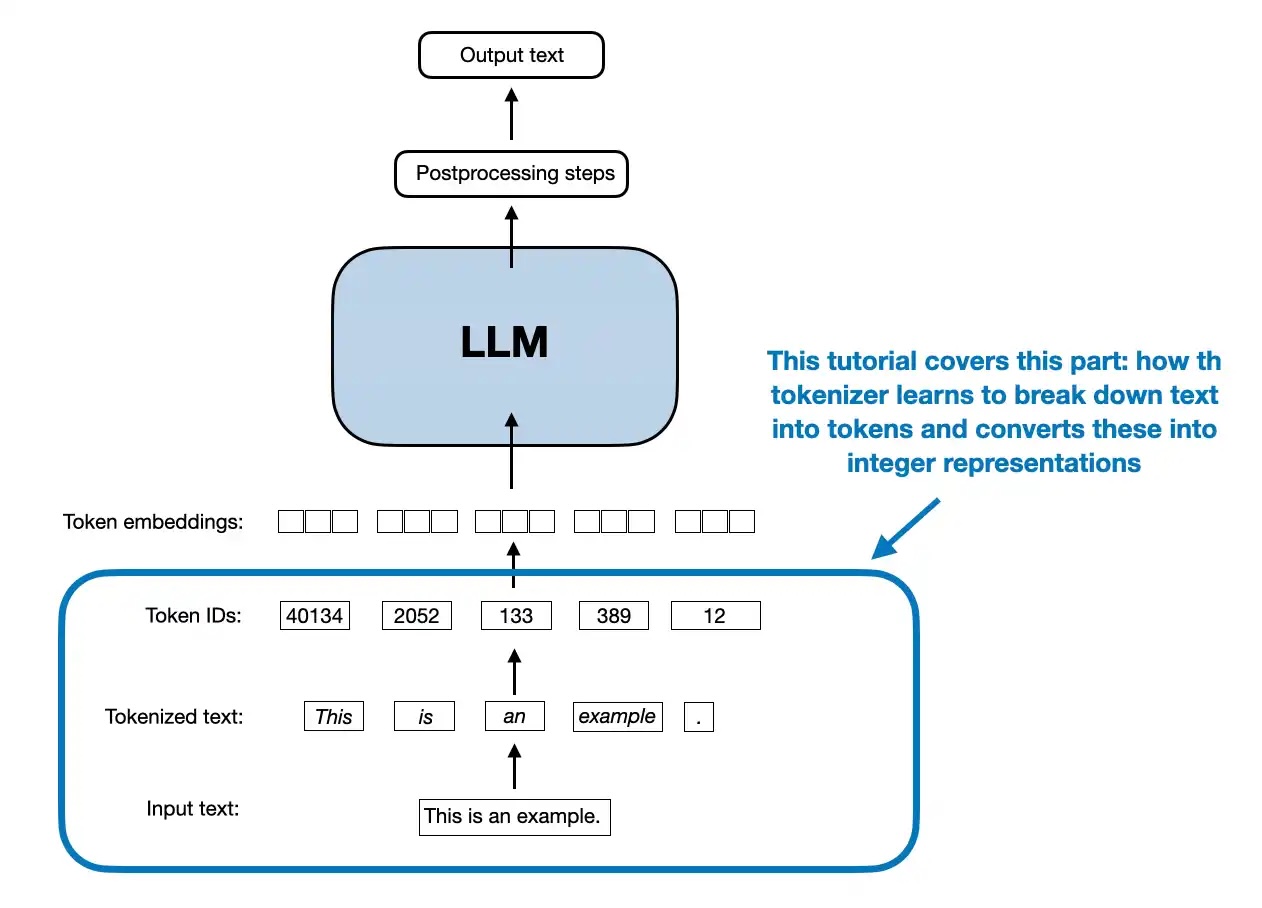
A one-stop-shop for all your tokenization needs
Similarity search is one of the fastest-growing domains in AI and machine learning. At its core, it is the process of matching relevant pieces of information together.
BAAI conference presented Wu Dao 2.0. The most powerful AI to date.

Sentiment Analysis, or Opinion Mining, is a subfield of NLP (Natural Language Processing) that aims to extract attitudes, appraisals, opinions, and emotions from text. Inspired by the rapid migration…

How this novel neural network architecture changes the way we analyze complex data types, and powers revolutionary models like GPT-3 and BERT.

The way we search online hasn’t changed in decades. A new idea from Google researchers could make it more like talking to a human expert
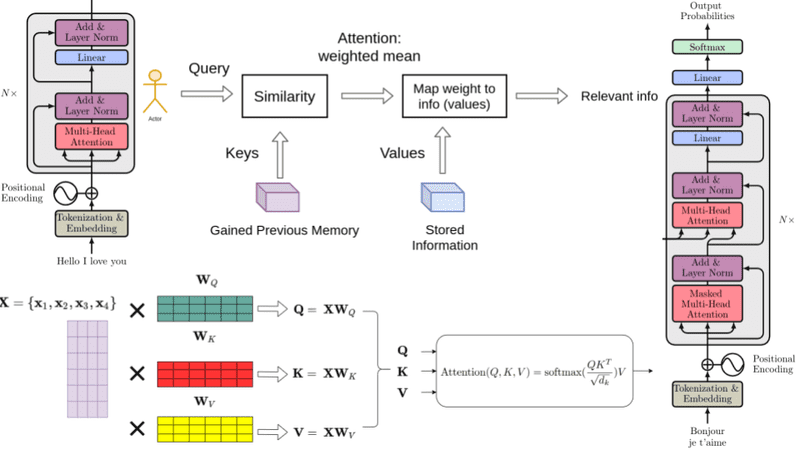
An intuitive understanding on Transformers and how they are used in Machine Translation. After analyzing all subcomponents one by one such as self-attention and positional encodings , we explain the principles behind the Encoder and Decoder and why Transformers work so well

A simple quick solution for deploying an NLP project and challenges you may faced during the process.

Pre-processing Arabic text for machine-learning using the camel-tools Python package
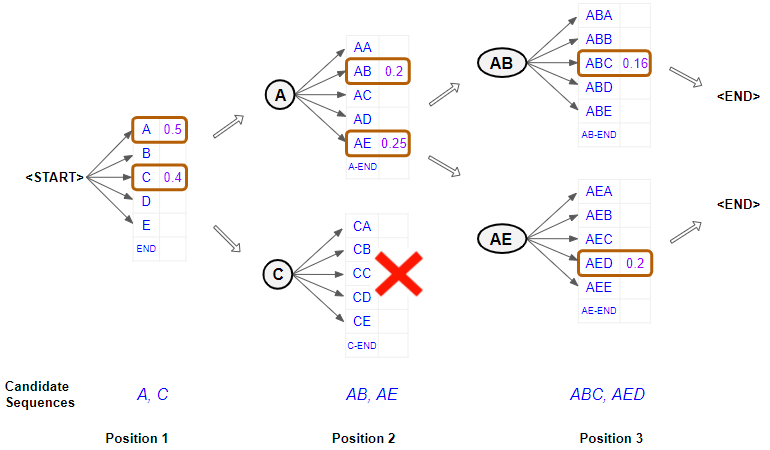
A Gentle Guide to how Beam Search enhances predictions, in Plain English
See how to build end-to-end NLP pipelines in a fast and scalable way on GPUs — from feature engineering to inference.
/cdn.vox-cdn.com/uploads/chorus_asset/file/20790706/acastro_200730_1777_ai_0001.jpg)
Text-generation is the next big thing in AI.

blog.md · GitHub

The NLP application ecosystem is in its earliest stages, and it's not yet clear whether GPT-3 or a different model will be the foundation.
A journalist’s attempt at introducing math to the newsroom while analyzing QAnon
Knowing the terminology is essential to understanding any tutorial.

Speech and natural language processing (NLP) have become the foundation for most of the AI development in the enterprise today, as textual data represents a significant portion of unstructured content.

12 sentiment analysis algorithms were compared on the accuracy of tweet classification. The fasText deep learning system was the winner.
📣 NEW: Want to make the transition from spaCy v2 to spaCy v3 as smooth as possible for you and your organization? We're now offering commercial migration support for your spaCy pipelines! We...
Classifying cross-topic natural language texts based on their argumentative structure using deep learning
Towards more efficient natural language processing

**Sentiment Analysis** is the task of classifying the polarity of a given text. For instance, a text-based tweet can be categorized into either "positive", "negative", or "neutral". Given the text and accompanying labels, a model can be trained to predict the correct sentiment. **Sentiment Analysis** techniques can be categorized into machine learning approaches, lexicon-based approaches, and even hybrid methods. Some subcategories of research in sentiment analysis include: multimodal sentiment analysis, aspect-based sentiment analysis, fine-grained opinion analysis, language specific sentiment analysis. More recently, deep learning techniques, such as RoBERTa and T5, are used to train high-performing sentiment classifiers that are evaluated using metrics like F1, recall, and precision. To evaluate sentiment analysis systems, benchmark datasets like SST, GLUE, and IMDB movie reviews are used. Further readings: - [Sentiment Analysis Based on Deep Learning: A Comparative Study](https://paperswithcode.com/paper/sentiment-analysis-based-on-deep-learning-a)
From predicting single sentence to fine-tuning using custom dataset to finding the best hyperparameter configuration.
Algorithms for text analytics must model how language works to incorporate meaning in language—and so do the people deploying these algorithms. Bender & Lascarides 2019 is an accessible overview of what the field of linguistics can teach NLP about how meaning is encoded in human languages.

Determining the optimal architectural parameters reduces network size by 84% while improving performance on natural-language-understanding tasks.
Introduction to tokenization methods, including subword, BPE and SentencePiece

Amazon said it shifted part of the computing for its Alexa voice assistant to its own custom-designed chips.

A review of 20+ deep learning NLP models and how to use them well

Comparison of two known engines for optical character recognition (OCR) and Naturtal Language Processing

AI researchers from the Ludwig Maximilian University (LMU) of Munich have developed a bite-sized text generator capable of besting OpenAI’s state of the art GPT-3 using only a tiny fraction of its parameters. GPT-3 is a monster of an AI sys

What does Microsoft getting an "exclusive license" to GPT-3 mean for the future of AI democratization?

Photo by Eric Krull on Unsplash. Parsing and processing documents can provide a lot of value for alm...
Hedonometer.org is an instrument that measures the happiness of large populations in real time. The hedonometer is based on people’s online expressions, capitalizing on data-rich social media, and measures how people present themselves to the outside world.

Identifying Change Points in Time Series Data with FLUSS and FLOSS
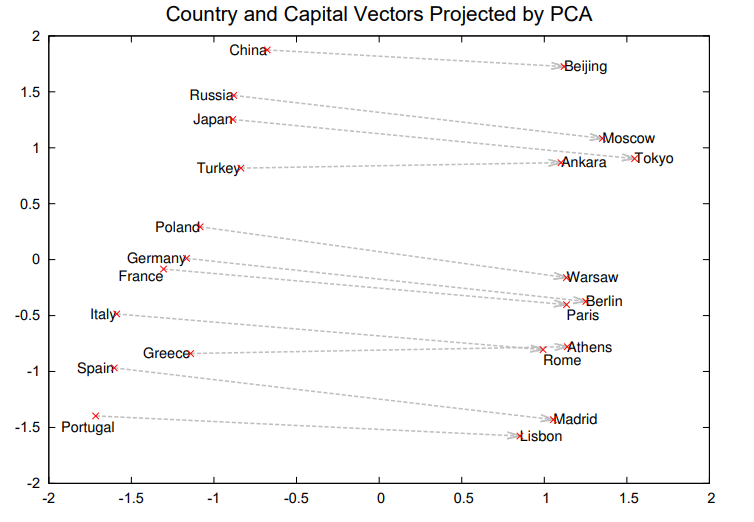
This post collates research on the advancements of Natural Language Processing (NLP) over the years.

Figuring out what words are predictive for your problem is easy!
Here is an overview of another great natural language processing resource, this time from Microsoft, which demonstrates best practices and implementation guidelines for a variety of tasks and scenarios.

An Overview Of popular python libraries for Natural Language Processing
We review the cost of training large-scale language models, and the drivers of these costs. The intended audience includes engineers and scientists budgeting their model-training experiments, as...

How people are talking about your brand

Extracting topics is a good unsupervised data-mining technique to discover the underlying relationships between texts. There are many…

TLDR This is a Free online text summarizing tool that automatically condenses long articles, documents, essays, or papers into key summary paragraphs using state-of-the-art AI.
TensorFlow code and pre-trained models for BERT.
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessible video intro to BERT The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving. Moreover, the NLP community has been putting forward incredibly powerful components that you can freely download and use in your own models and pipelines (It’s been referred to as NLP’s ImageNet moment, referencing how years ago similar developments accelerated the development of machine learning in Computer Vision tasks).
219 votes, 26 comments. Hello. This is my first post in reddit I created nlp-tutoral repository who is studying NLP(Natural Language Processing)…

BERT can get you state-of-the-art results on many NLP tasks and it only takes a few lines of code.

Arguably more famous today than Michael Bay’s Transformers, the transformer architecture and transformer-based models have been breaking all kinds of state-of-the-art records. They are (rightfully) getting the attention of a big portion of the deep learning community and researchers in Natural Language Processing (NLP) since their introduction in 2017 by the Google Translation Team. This architecture has set […]

By popular demand, I’ve updated this article with the latest tutorials from the past 12 months. Check it out here
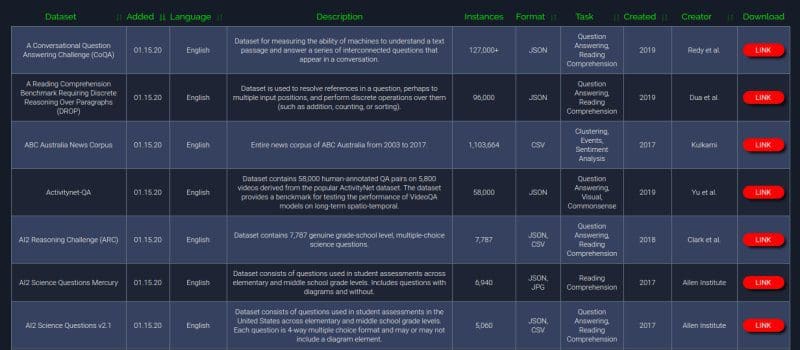
Check out this database of nearly 300 freely-accessible NLP datasets, curated from around the internet.

Pre-training SmallBERTa - A tiny model to train on a tiny dataset An end to end colab notebook that allows you to train your own LM (using HuggingFace…

What is sentiment analysis, how to perform it, and how it can help your business.
Follow this overview of Natural Language Generation covering its applications in theory and practice. The evolution of NLG architecture is also described from simple gap-filling to dynamic document creation along with a summary of the most popular NLG models.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Build software with machine learning — no math required.
This year’s annual meeting of the Association for Computational Linguistics (ACL 2019) was bigger than ever. Although the conference received 75% more submissions than last year, the quality of the research papers remained high, and so the acceptance rates are almost the same. It is becoming more and more challenging to keep track of the […]
336 votes, 25 comments. Huggingface, the NLP research company known for its transformers library, has just released a new open-source library for…
Data Scientists work with tons of data, and many times that data includes natural language text. This guide reviews 7 common techniques with code examples to introduce you the essentials of NLP, so you can begin performing analysis and building models from textual data.

Explore NLP EDA with Python tools: learn about text statistics, ngrams, topic modeling with pyLDAvis, sentiment analysis, and more

This figure was adapted from a similar image published in DistilBERT. Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics […]

Today, one of the most popular tasks in Data Science is processing information presented in the text form. Exactly this is text representation in the form of mathematical equations, formulas, paradigms, patterns in order to understand the text semantics (content) for its further processing: classification, fragmentation, etc. The general area which solves the described problems… Read More »Top NLP Algorithms & Concepts

If you’re relatively new to the NLP and Text Analysis world, you’ll more than likely have come across some pretty technical terms and acronyms, that are challenging to get your head around, especially, if you’re relying on scientific definitions for a plain and simple explanation. We decided to put together a list of 10 common… Read More »10 Common NLP Terms Explained for the Text Analysis Novice

A CloudOps Journey
Natural Language Processing Best Practices & Examples - microsoft/nlp-recipes

In this tutorial we learn to quickly train Huggingface BERT using PyTorch Lightning for transfer learning on any NLP task

We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Unless you have been out of touch with the Deep Learning world, chances are that you have heard about BERT — it has been the talk of the town for the last one year. At the end of 2018 researchers …

Machines work with words by embedding their relationships with other words in a string of numbers.

From BERT’s tangled web of attention, some intuitive patterns emerge.

spaCy is a modern Python library for industrial-strength Natural Language Processing. In this free and interactive online course, you'll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches.
Medallia's text analytics software tool provides actionable insights via customer and employee experience sentiment data analysis from reviews & comments.
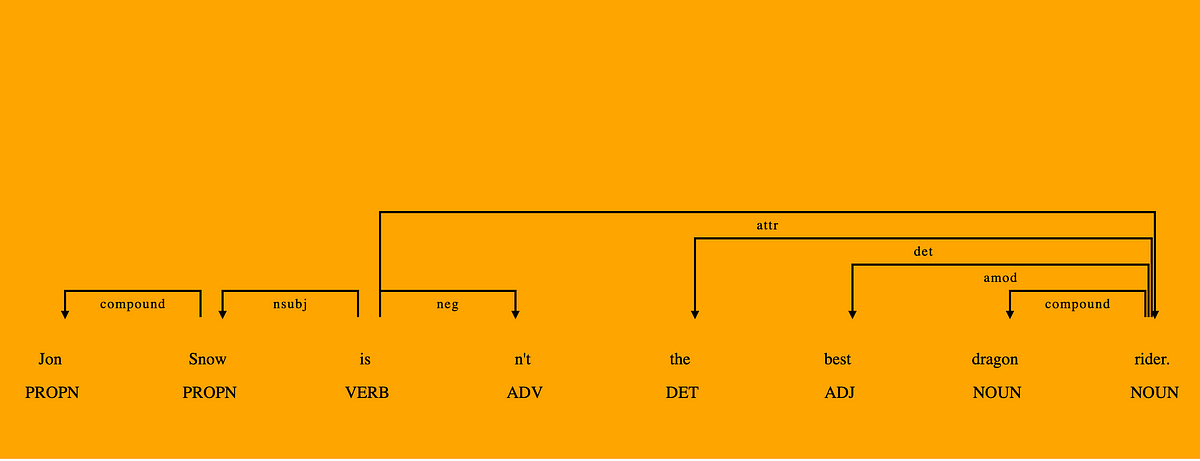
A few weeks ago I started working on a text summarisation project and I needed a Natural Language Processing library with comprehensive…
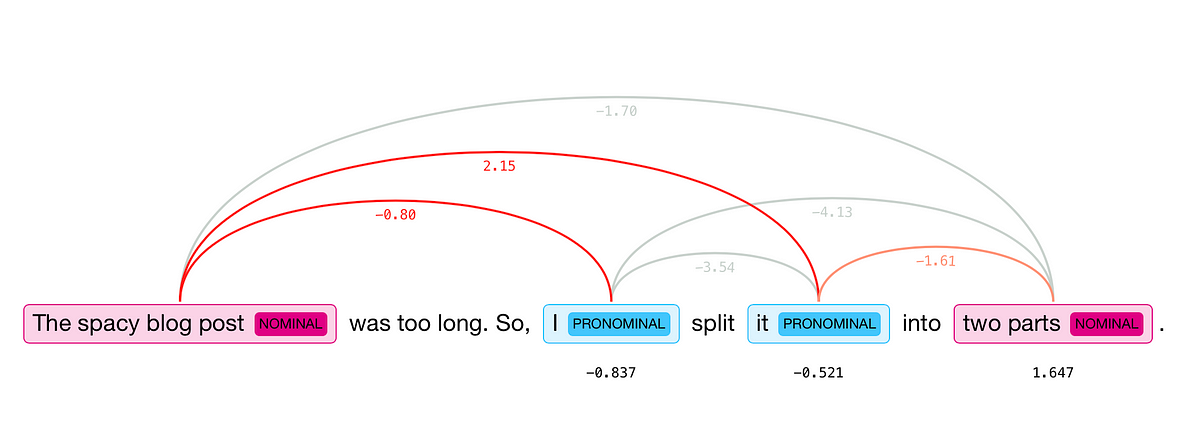
In the first part of this overview of spaCy we went over the features of the large English pretrained model that spaCy comes with. In this…

Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
Discussions: Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments) Translations: Chinese (Simplified), French, Korean, Portuguese, Russian “There is in all things a pattern that is part of our universe. It has symmetry, elegance, and grace - those qualities you find always in that which the true artist captures. You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. We try to copy these patterns in our lives and our society, seeking the rhythms, the dances, the forms that comfort. Yet, it is possible to see peril in the finding of ultimate perfection. It is clear that the ultimate pattern contains it own fixity. In such perfection, all things move toward death.” ~ Dune (1965) I find the concept of embeddings to be one of the most fascinating ideas in machine learning. If you’ve ever used Siri, Google Assistant, Alexa, Google Translate, or even smartphone keyboard with next-word prediction, then chances are you’ve benefitted from this idea that has become central to Natural Language Processing models. There has been quite a development over the last couple of decades in using embeddings for neural models (Recent developments include contextualized word embeddings leading to cutting-edge models like BERT and GPT2). Word2vec is a method to efficiently create word embeddings and has been around since 2013. But in addition to its utility as a word-embedding method, some of its concepts have been shown to be effective in creating recommendation engines and making sense of sequential data even in commercial, non-language tasks. Companies like Airbnb, Alibaba, Spotify, and Anghami have all benefitted from carving out this brilliant piece of machinery from the world of NLP and using it in production to empower a new breed of recommendation engines. In this post, we’ll go over the concept of embedding, and the mechanics of generating embeddings with word2vec. But let’s start with an example to get familiar with using vectors to represent things. Did you know that a list of five numbers (a vector) can represent so much about your personality?

There was a survey a while back that asked people to provide a 0 to 100 percent value to probabilistic words like “usually” and “likely”. YouGov did something similar for wo…
2.9M subscribers in the MachineLearning community. Beginners -> /r/mlquestions , AGI -> /r/singularity, career advices -> /r/cscareerquestions…
A context-preserving word cloud generator.
Sentiment analysis is widely used, especially as a part of social media analysis for any domain, be it a business, a recent movie, or a product launch, to understand its reception by the people and what they think of it based on their opinions or, you guessed it, sentiment!
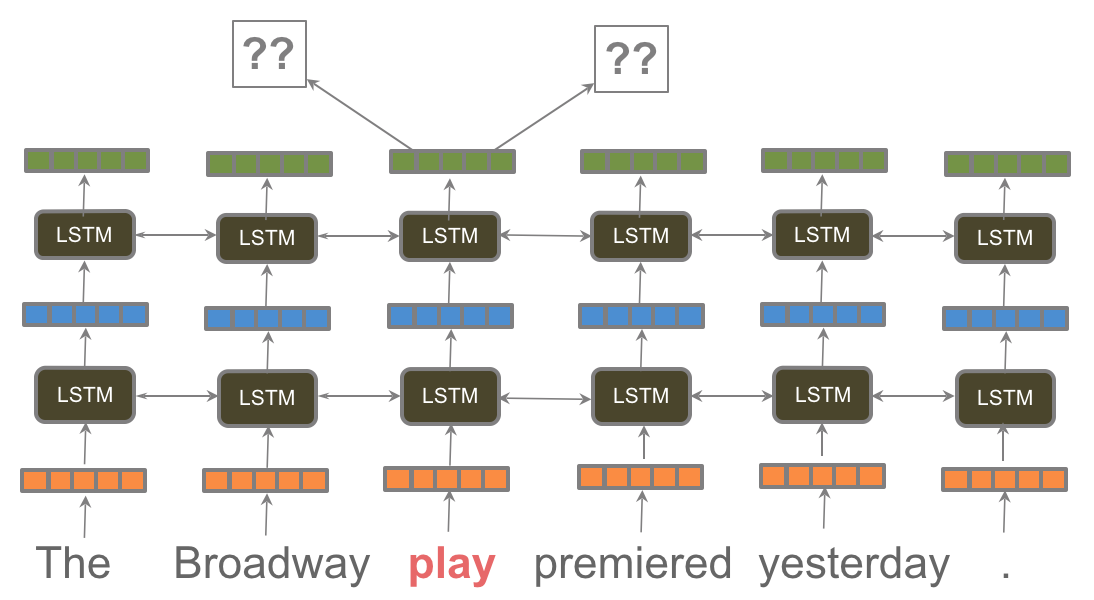
The time is ripe for practical transfer learning to make inroads into NLP.

I ended my last post by saying that I might write a follow-up post on current work that seems to exhibit progress toward natural language understanding. I am going to discuss a couple sampled pap…

Using Machine Learning to understand and leverage text.
Engineering at Forward | UCLA CS '19
NLP Concepts with spaCy. Code examples released under CC0 https://creativecommons.org/choose/zero/, other text released under CC BY 4.0 https://creativecommons.org/licenses/by/4.0/ · GitHub
Quantized word vectors that take 8x-16x less space than regular word vectors - agnusmaximus/Word2Bits
This post presents 5 practical resources for getting a start in natural language processing, covering a wide array of topics and approaches.
NLTK 3.3 has been released NLTK 3.3 includes the following: Support Python 3.6 New interface to CoreNLP Support synset retrieval by sense key Minor…

Topic Modeling is a technique to understand and extract the hidden topics from large volumes of text. Latent Dirichlet Allocation(LDA) is an algorithm for topic modeling, which has excellent implementations in the Python's Gensim package. This tutorial tackles the problem of finding the optimal number of topics.
Fine-tuning our sentiment classifier

Traditional strategies for taming unstructured, textual data

Efficient topic modelling in Python
An NLP workshop about concrete solutions to real problems - hundredblocks/concrete_NLP_tutorial
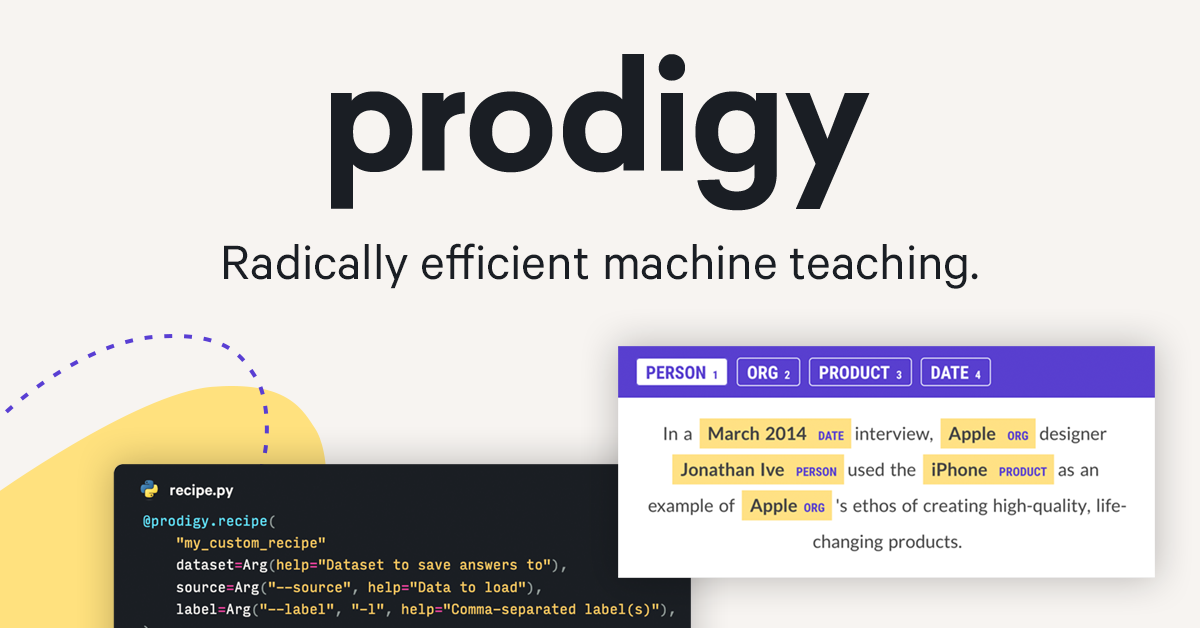
A downloadable annotation tool for LLMs, NLP and computer vision tasks such as named entity recognition, text classification, object detection, image segmentation, evaluation and more.
💫 Jupyter notebooks for spaCy examples and tutorials - explosion/spacy-notebooks
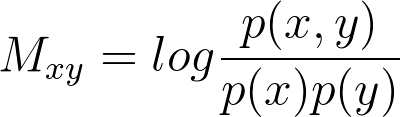
Counting and tensor decompositions are elegant and straightforward techniques. But these methods are grossly underepresented in business contexts. In this p...

Stay up-to-date on the latest data science and AI news in the worlds of artificial intelligence, machine learning, deep learning, implementation, and more.