reasoning


Mistral's Small 4 combines reasoning, multimodal analysis and agentic coding in a single open-source model with configurable inference effort, offering enterprises a lower-cost alternative to running separate models for each task.
OpenAI has indicated that a new version of its large language model, GPT-5.4, is in development following a post on

Nvidia researchers developed dynamic memory sparsification (DMS), a technique that compresses the KV cache in large language models by up to 8x while maintaining reasoning accuracy — and it can be retrofitted onto existing models in hours.

While standard models suffer from context rot as data grows, MIT’s new Recursive Language Model (RLM) framework treats prompts like code variables, unlocking infinite context without the retraining costs.

In this article, I’ll walk you through a guided project to add reasoning skills to your LLM apps. Add Reasoning Skills to Your LLM Apps.

Understanding GRPO and New Insights from Reasoning Model Papers

Understand LLM reasoning by creating your own reasoning model–from scratch! LLM reasoning models have the power to tackle truly challenging problems that require finding the right path through multiple steps. In Build A Reasoning Model (From Scratch) you’ll learn how to build a working reasoning model from the ground up. You will start with an existing pre-trained LLM and then implement reasoning-focused improvements from scratch. Sebastian Raschka, the bestselling author of Build a Large Language Model (From Scratch), is your guide on this exciting journey. Sebastian mentors you every step of the way with clear explanations, practical code, and a keen focus on what really matters. In Build A Reasoning Model (From Scratch) you’ll learn how to: Implement core reasoning improvements for LLMs Evaluate models using judgment-based and benchmark-based methods Improve reasoning without updating model weights Use reinforcement learning to integrate external tools like calculators Apply distillation techniques to learn from larger reasoning models Understand the full reasoning model development pipeline Reasoning models break problems into steps, producing more reliable answers in math, logic, and code. These improvements aren’t just a curiosity–they’re already integrated into top models like Grok 4 and GPT-5. Build A Reasoning Model (From Scratch) demystifies these complex models with a simple philosophy: the best way to learn how something works is to build it yourself! You’ll begin with a pre-trained LLM, adding and improving its reasoning capabilities in ways you can see, test, and understand.
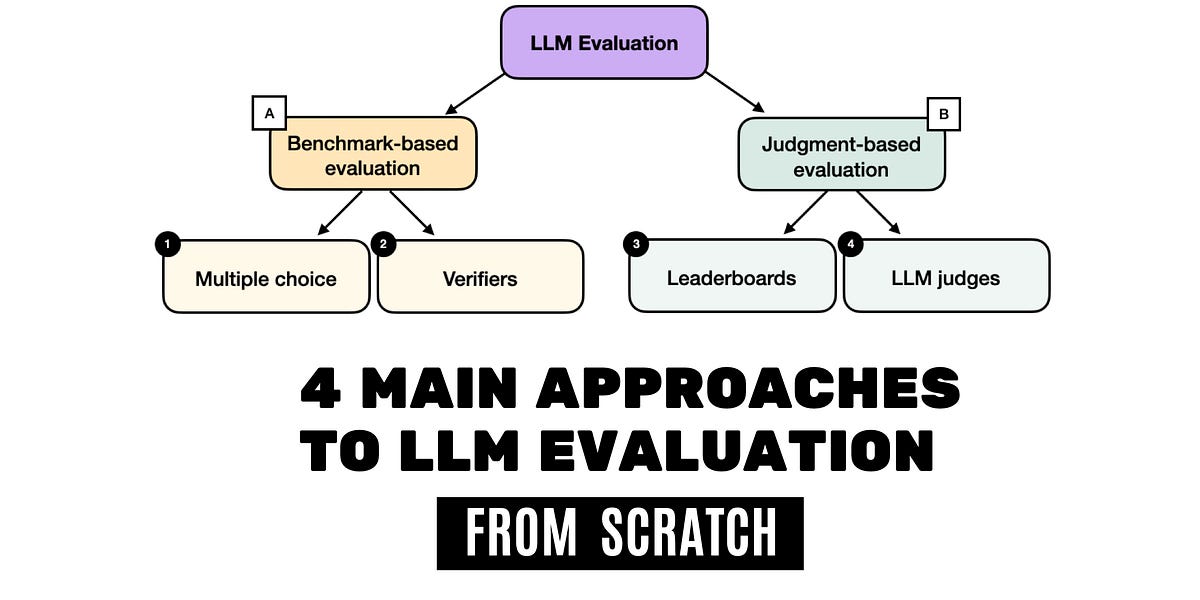
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency. HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes. Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities. These results underscore HRM's potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining - XiaomiMiMo/MiMo

A lot has happened this month, especially with the releases of new flagship models like GPT-4.5 and Llama 4. But you might have noticed that reactions to these releases were relatively muted. Why? One reason could be that GPT-4.5 and Llama 4 remain conventional models, which means they were trained without explicit reinforcement learning for reasoning. However, OpenAI's recent release of the o3 reasoning model demonstrates there is still considerable room for improvement when investing compute strategically, specifically via reinforcement learning methods tailored for reasoning tasks. While reasoning alone isn't a silver bullet, it reliably improves model accuracy and problem-solving capabilities on challenging tasks (so far). And I expect reasoning-focused post-training to become standard practice in future LLM pipelines. So, in this article, let's explore the latest developments in reasoning via reinforcement learning.
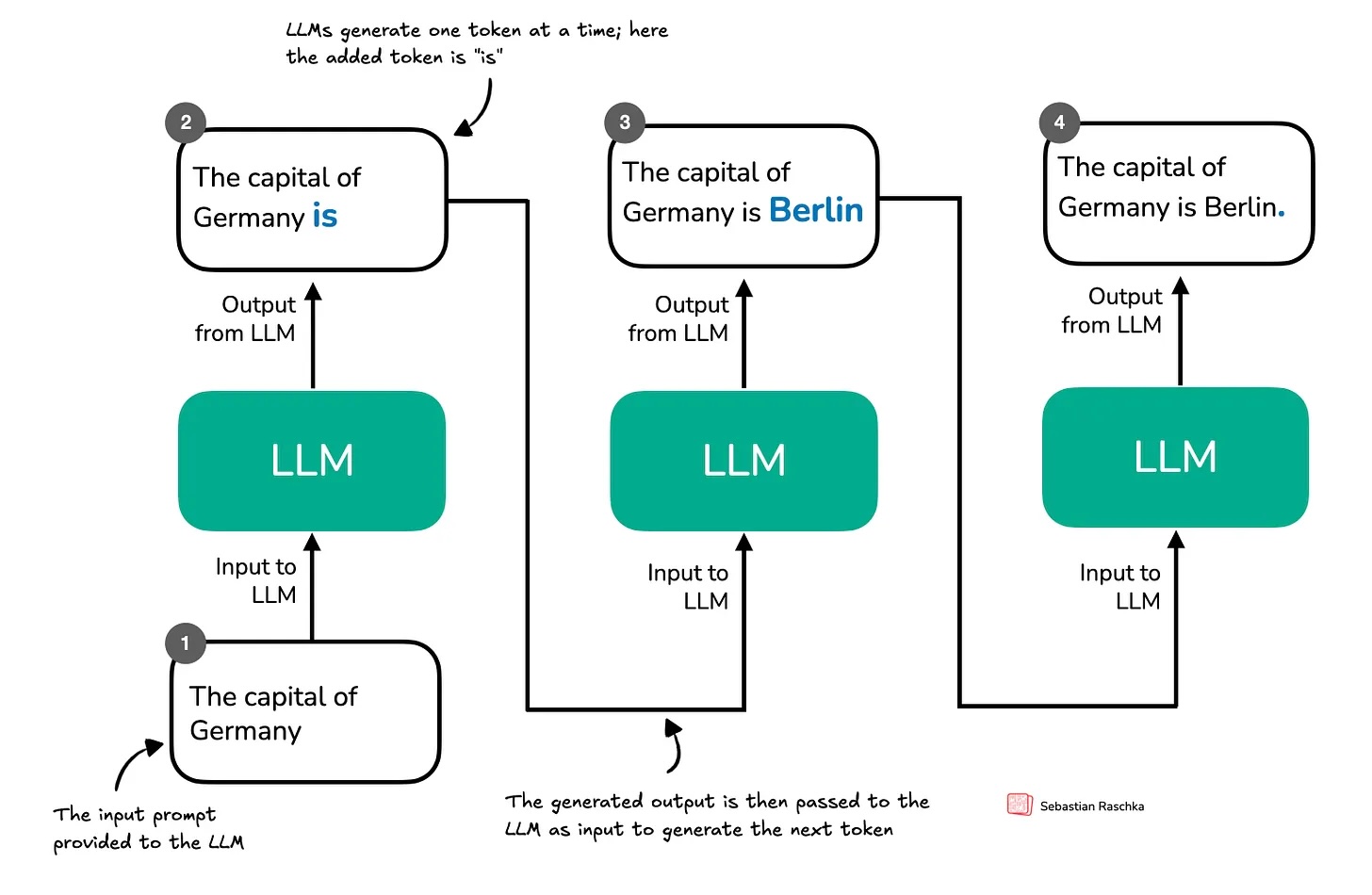
As you know, I've been writing a lot lately about the latest research on reasoning in LLMs. Before my next research-focused blog post, I wanted to offer something special to my paid subscribers as a thank-you for your ongoing support. So, I've started writing a new book on how reasoning works in LLMs, and here I'm sharing the first Chapter 1 with you. This ~15-page chapter is an introduction reasoning in the context of LLMs and provides an overview of methods like inference-time scaling and reinforcement learning. Thanks for your support! I hope you enjoy the chapter, and stay tuned for my next blog post on reasoning research!
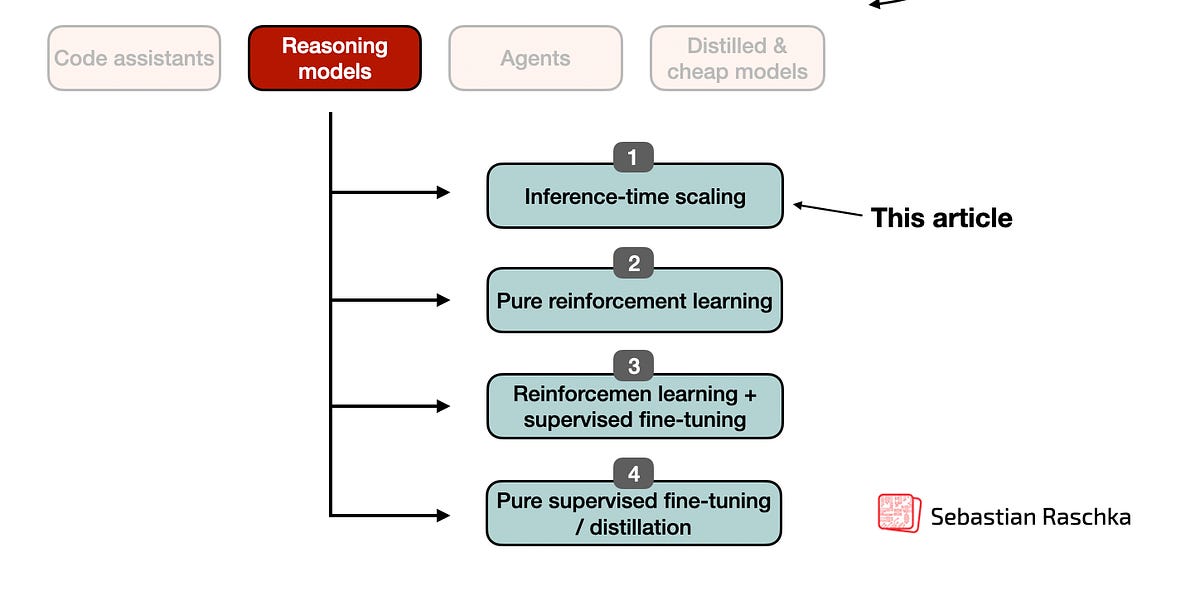
Part 1: Inference-Time Compute Scaling Methods
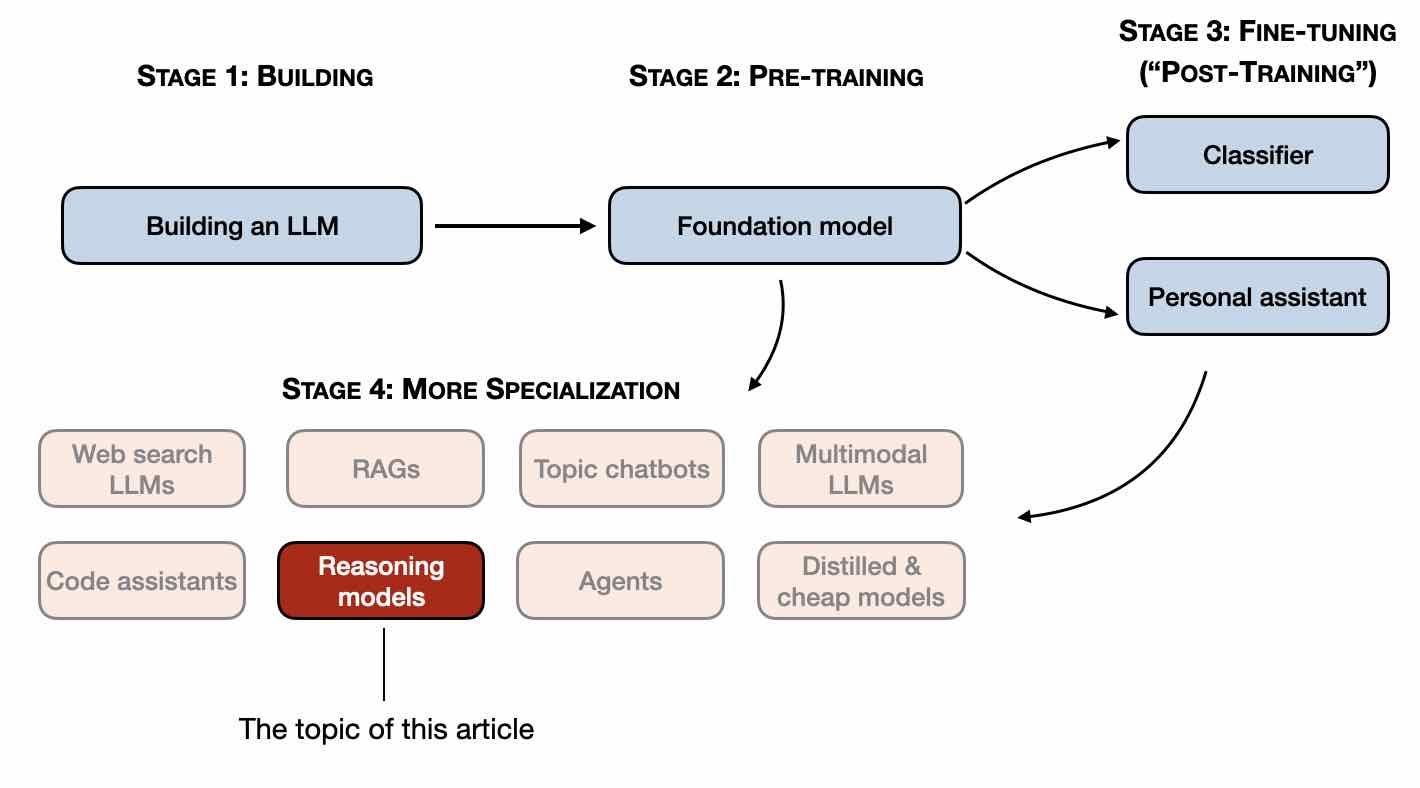
In this article, I will describe the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this p...

A recipe for reasoning LLMs

Large language models (LLMs) can understand and generate human-like text by encoding vast knowledge repositories within their parameters. This capacity enables them to perform complex reasoning tasks, adapt to various applications, and interact effectively with humans. However, despite their remarkable achievements, researchers continue to investigate the mechanisms underlying the storage and utilization of knowledge in these systems, aiming to enhance their efficiency and reliability further. A key challenge in using large language models is their propensity to generate inaccurate, biased, or hallucinatory outputs. These problems arise from a limited understanding of how such models organize and access knowledge. Without clear

The advent of LLMs has propelled advancements in AI for decades. One such advanced application of LLMs is Agents, which replicate human reasoning remarkably. An agent is a system that can perform complicated tasks by following a reasoning process similar to humans: think (solution to the problem), collect (context from past information), analyze(the situations and data), and adapt (based on the style and feedback). Agents encourage the system through dynamic and intelligent activities, including planning, data analysis, data retrieval, and utilizing the model's past experiences. A typical agent has four components: Brain: An LLM with advanced processing capabilities, such as

Large language models do better at solving problems when they show their work. Researchers are beginning to understand why.

This article delves into the concept of Chain-of-Thought (CoT) prompting, a technique that enhances the reasoning capabilities of large language models (LLMs). It discusses the principles behind CoT prompting, its application, and its impact on the performance of LLMs.