semantic-search


Success in modern UX isn’t about having the most content. It’s about having the most findable content. Yet even with more data and better tools than ever, internal search often fails, leaving users to rely on global search engines to find a single page on a local site. Why does the “Big Box” still win, and how can we bring users back?
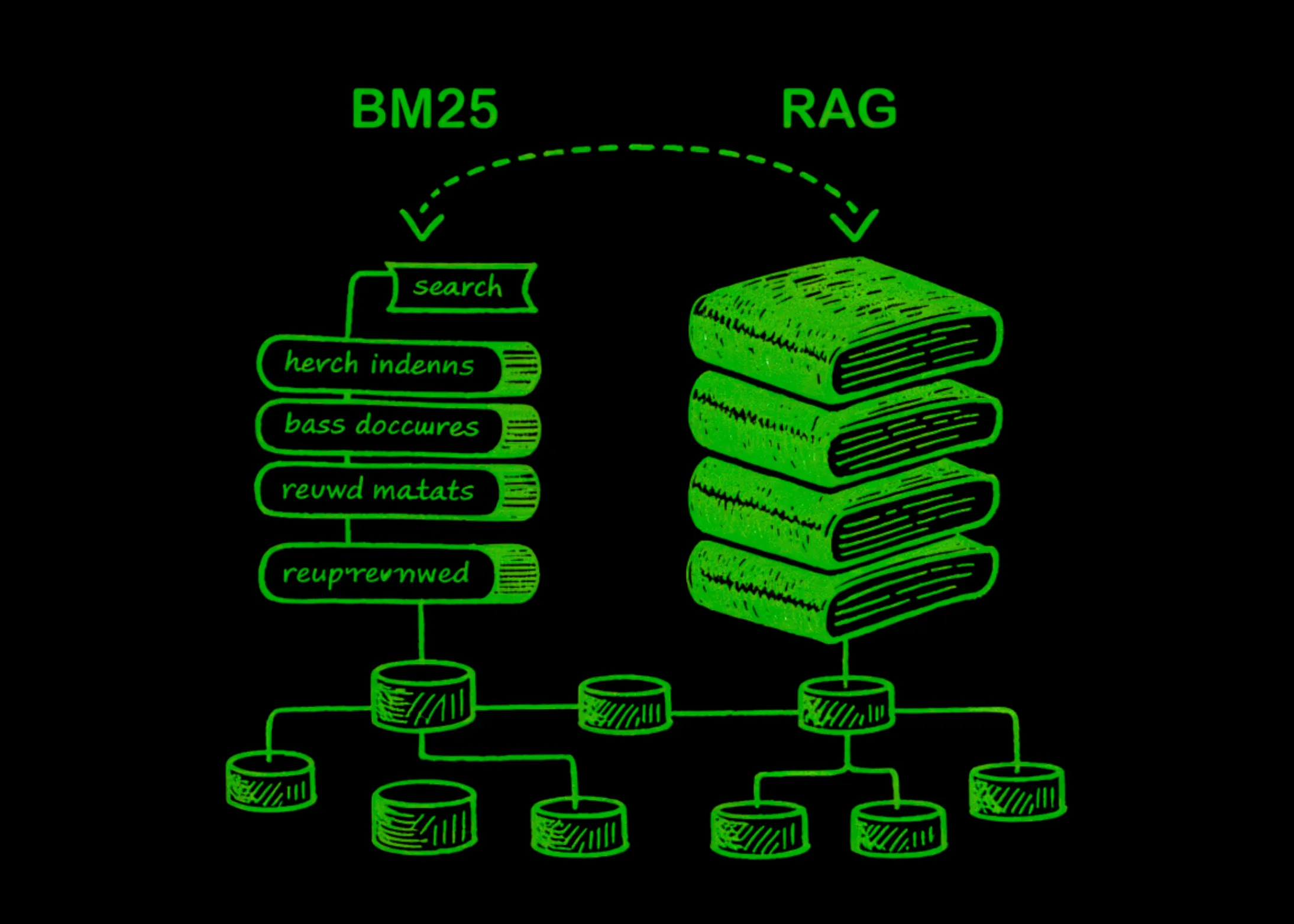
When you type a query into a search engine, something has to decide which documents are actually relevant — and how to rank them. BM25 (Best Matching 25), the algorithm powering search engines like Elasticsearch and Lucene, has been the dominant answer to that question for decades. It scores documents by looking at three things: […]


Government organizations love to distribute documents as PDF files. They are easy to forward and to print. The problem is when you want to find and access them later among millions of other files. …
Semantic search and document parsing tools for the command line - run-llama/semtools
From BM25 to RAG: Everything I learned about vector databases, embedding models, and vector search - and everything in between.
Discover Vector Databases: How They Work, Examples, Use Cases, Pros & Cons, Selection and Implementation. They have combined capabilities of traditional databases and standalone vector indexes while specializing for vector embeddings.
Dive into an end-to-end demo of a high-performance semantic search engine leveraging GPU acceleration, efficient indexing techniques, and…

Jianmin “Jamie” Tan, PhD ’90
Similarity search is one of the fastest-growing domains in AI and machine learning. At its core, it is the process of matching relevant pieces of information together.