similarity-search


Success in modern UX isn’t about having the most content. It’s about having the most findable content. Yet even with more data and better tools than ever, internal search often fails, leaving users to rely on global search engines to find a single page on a local site. Why does the “Big Box” still win, and how can we bring users back?
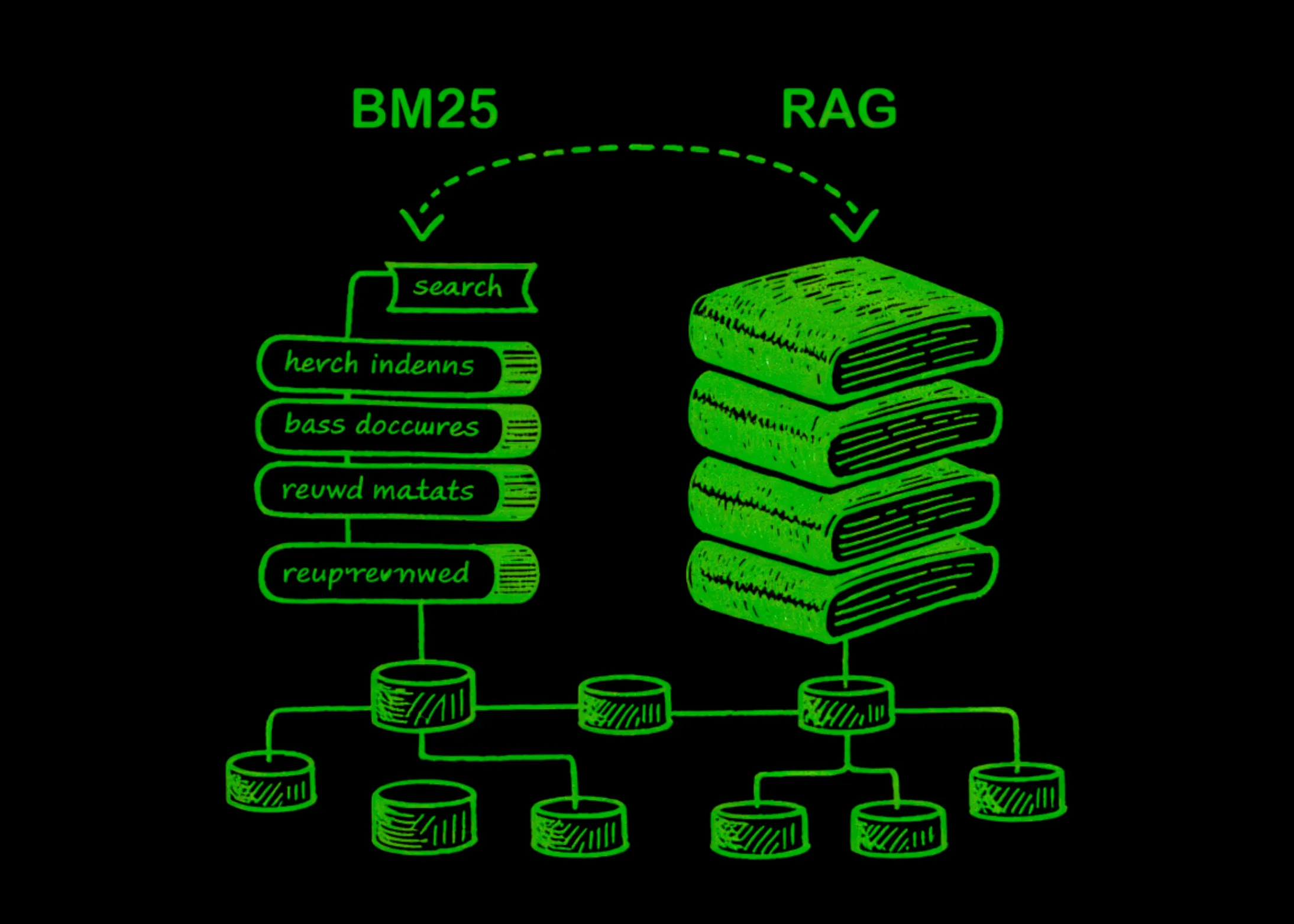
When you type a query into a search engine, something has to decide which documents are actually relevant — and how to rank them. BM25 (Best Matching 25), the algorithm powering search engines like Elasticsearch and Lucene, has been the dominant answer to that question for decades. It scores documents by looking at three things: […]

ANN — Approximate Nearest Neighbors — is at the core of fast vector search, itself central to GenAI, especially GPT and LLM. My new methodology, abbreviated as PANN, has many other app…
Visit the post for more.
In the first two parts of this series we have discussed two fundamental algorithms in information retrieval: inverted file index and…

Hierarchical Navigable Small World (HNSW) is a state-of-the-art algorithm used for an approximate search of nearest neighbours. Under the…
Hierarchical Navigable Small World graphs (HNSW) is an algorithm that allows for efficient nearest neighbor search, and the Sentence…
Similarity search is a popular problem where given a query Q we need to find the most similar documents to it among all the documents D.
Understand how to hash data and reflect its similarity by constructing random hyperplanes
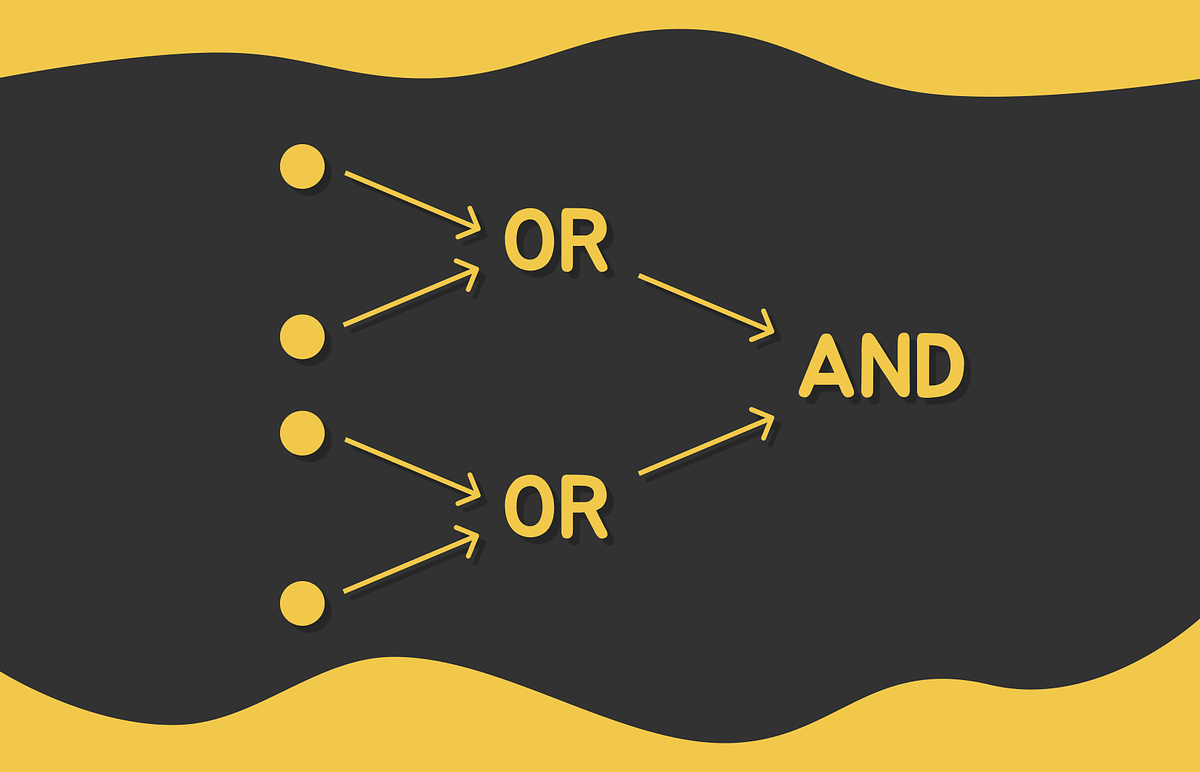
Dive into combinations of LSH functions to guarantee a more reliable search