svm

Support Vector Machines (SVM) are supervised learning algorithms used for classification and regression by finding optimal decision boundaries between data classes.
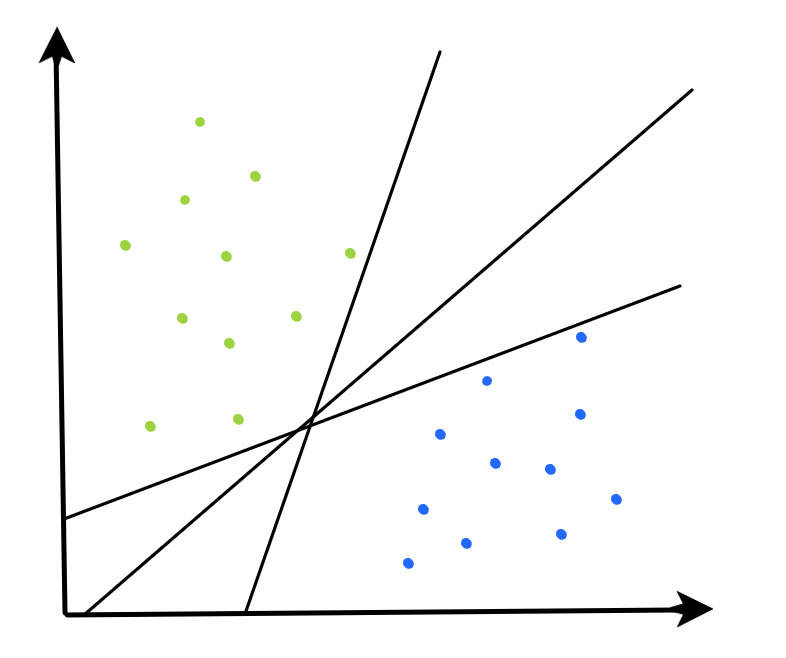
MMC, SVC, SVM: What’s the difference?

Support Vector Machines (SVMs) are a powerful and versatile supervised machine learning algorithm primarily used for classification and regression tasks. They excel in high-dimensional spaces and are particularly effective when dealing with complex datasets. The core principle behind SVM is to identify the optimal hyperplane that effectively separates data points into different classes while maximizing the margin between them. SVMs have gained significant popularity due to their ability to handle both linear and non-linear classification problems. By employing kernel functions, SVMs can map data into higher-dimensional feature spaces, capturing intricate patterns and relationships that may not be apparent in the

Imagine you're at a party separating people who love pizza (yum!) from those who...well, have...

A guide to understanding support vector machines for classification: from theory to scikit-learn implementation.
based on "Hands-On Machine Learning with Scikit-Learn & TensorFlow" (O'Reilly, Aurelien Geron) - bjpcjp/scikit-and-tensorflow-workbooks

A complete explanation of the inner workings of Support Vector Machines (SVM) and Radial Basis Function (RBF) kernel
An intuitive visual explanation
In this post, we will try to gain a high-level understanding of how SVMs work. I’ll focus on developing intuition rather than rigor. What that essentially means is we will skip as much of the math as possible and develop a strong intuition of the working principle.